Llama Index is an orchestration framework for large language model (LLM) applications. LLMs like GPT-4 are pre-trained on massive public datasets, allowing for incredible natural language processing capabilities out of the box. However, their utility is limited without access to your own private or domain-specific data.
LlamaIndex solves this problem by providing a way to ingest, structure, and access your own data for use with LLMs. It supports a variety of data sources, including APIs, databases, and PDFs.

Once your data is indexed, it provides a number of ways to interact with it, including:
- Natural language querying: You can ask LlamaIndex questions about your data in plain English. For example, you could ask “What are the top 10 revenue-generating products?” or “What are the most common customer complaints?”
- Conversation with LLM-powered data agents: It can be used to create chatbots or other conversational interfaces that can access and process your data in real-time. This allows you to build applications that can provide personalized assistance to your users or answer their questions in a comprehensive and informative way.
- LLM-powered data analytics: It can also be used to power LLM-based data analytics applications. For example, you could use it to build a system that can automatically generate reports or insights from your data.
Tune in to our Future of Data and AI Podcast featuring Co-founder and CEO of LlamaIndex, Jerry Liu himself!
Key Components of Llama Index:
The key components of LlamaIndex are as follows:
- Data connectors: These components allow LlamaIndex to ingest data from a variety of sources, such as APIs, databases, and PDFs. The data is converted into a simple document format that is easy for LlamaIndex to process.
- Data index: A data structure that stores the data in a way that makes it easy for LlamaIndex to find the relevant information when a user asks a question or starts a conversation.
Also learn to simplify apps with LangChain and Llama Index
- Retrievers: Retrievers are responsible for finding the most relevant information in the data index based on the user’s query or chat message.
- Query engines: Allow users to ask questions about their data in natural language. They accept natural language queries and provide comprehensive and informative responses.
- Chat engines: Allow users to have interactive conversations with their data. They maintain a contextual understanding of the conversation history and can provide answers that consider the relevant past context.
In this tutorial, we will delve into the technical intricacies of constructing intelligent chatbots that leverage advanced technologies. Our example code will illustrate the development of a PDF Q&A chatbot that incorporates the OpenAI language model, VectorStoreIndex for document indexing and Streamlit for user interface design.

Furthermore, the chatbot will be equipped with the Llama Index’s Conversational Retrieval Chain, enabling it to furnish precise responses based on user queries. Let’s embark on this journey into the technical aspects of crafting a highly capable chatbot.
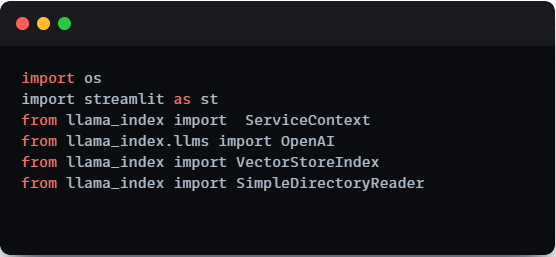
Importing Necessary Libraries
To commence our chatbot project, we need to import crucial libraries and functions. Here’s a breakdown of the libraries we will be utilizing:
- LlamaIndex: We harness the power of the Llama Index, a comprehensive framework tailored for developing applications enriched by language models.
- Streamlit: Streamlit, a Python library, serves as our toolkit for swiftly constructing web applications with an intuitive interface that facilitates user interaction.
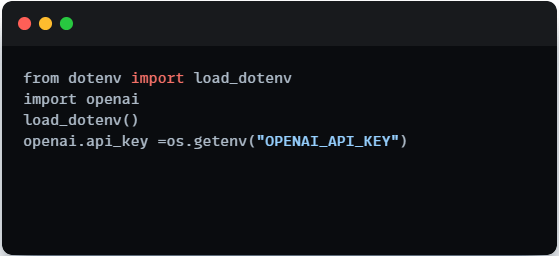
Setting OpenAI API Key
To access OpenAI’s language models effectively, it is imperative to configure our API key. Replace the placeholder with your actual OpenAI API key, obtainable from the OpenAI API platform. This key will act as our gateway to the powerful language models offered by OpenAI. Also you can use the dotenv route where you place your OPENAI key in the .env file.
Setting Up the User Interface:
This section delves into the creation of our user interface using Streamlit. The interface is meticulously designed to be clean, user-friendly, and feature-rich. It encompasses a title and a minimalist sidebar, providing an entry point for users to engage with our Q&A chatbot seamlessly.
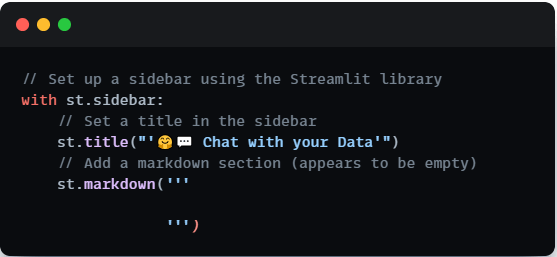
Follow Data Science Dojo on Medium to stay updated with LLM and Generative AI
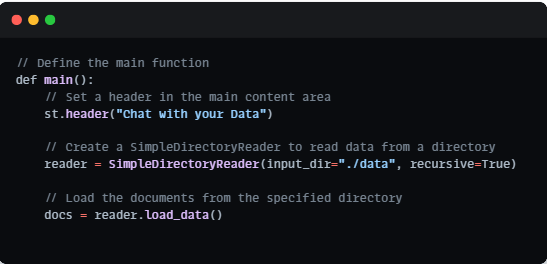
Main Function and Data Loading:
At the core of our chatbot lies the main function, which orchestrates the entire application logic. We initiate the process by loading data from a specified directory using a SimpleDirectoryReader. This data will serve as the knowledge repository from which our chatbot will draw answers to user inquiries.
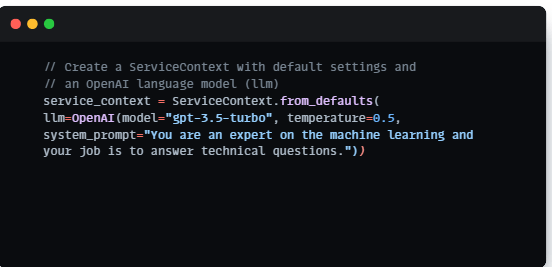
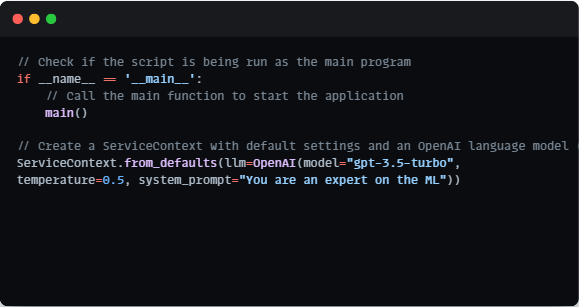
Creating a Service Context:
To enable the advanced natural language processing capabilities of our chatbot, we established a ServiceContext. This context is pre-configured with default settings and an OpenAI language model (llm). It lays the groundwork for our chatbot’s ability to understand and generate responses to user queries effectively.
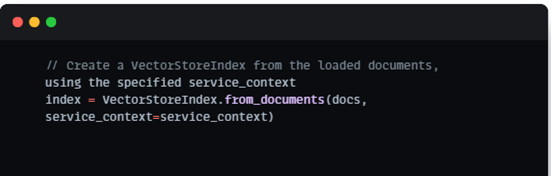
Building the LlamaIndex:
The pivotal component of our chatbot’s capabilities is the Llama Index. We construct this index using VectorStoreIndex, a versatile tool that optimizes the stored documents for efficient searching. This step ensures that our chatbot can rapidly retrieve pertinent information when faced with user queries.
User Input and Chat Engine:
Our user interface empowers users to input questions related to the provided data through a text input field. The chat engine processes these queries by harnessing the capabilities of the Llama Index. Subsequently, it generates responses based on the content indexed from the documents. This interaction constitutes the core functionality of our Q&A chatbot.
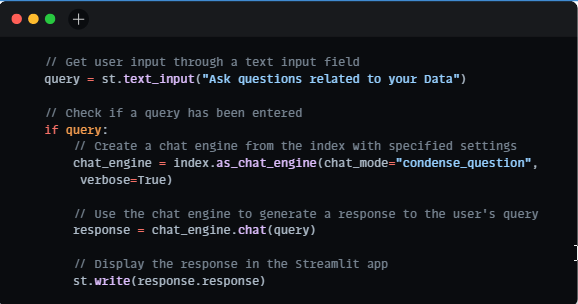
Running the Application:
With all the components in place, we culminate our code by executing the main function. This pivotal step transforms our project into an interactive chatbot. Users can seamlessly pose questions, and the chatbot, equipped with the Llama Index, responds with precise answers drawn from the indexed documents.
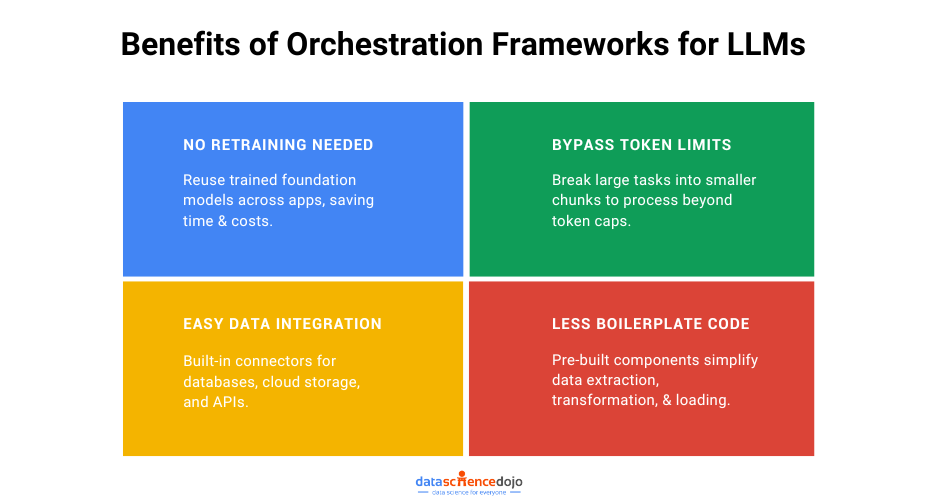
Benefits of Using LlamaIndex
There are a number of benefits to using LlamaIndex to create custom LLM applications:
- It is easy to use: Provides a simple and intuitive API for interacting with your data.
- It is flexible: Supports a variety of data sources and formats. It also provides a number of plugins and integrations that can be used to extend its functionality.
- It is scalable: Scaled to handle large datasets and high traffic volumes.

In conclusion, this guide has offered a comprehensive roadmap for creating personalized Q&A chatbots with the Llama Index at their core.
By integrating cutting-edge technologies such as OpenAI for language processing, VectorStoreIndex for efficient document indexing, and the Llama Index’s Conversational Retrieval Chain, we have unlocked the potential for engaging, informative, and highly interactive question-answering experiences.
Feel encouraged to explore and expand upon this chatbot project, extending its capabilities to tackle more intricate tasks and challenges within the realm of AI-driven conversational systems.