Artificial intelligence is evolving at an unprecedented pace, and large concept models (LCMs) represent the next big step in that journey. While large language models (LLMs) such as GPT-4 have revolutionized how machines generate and interpret text, LCMs go further: they are built to represent, connect, and reason about high-level concepts across multiple forms of data. In this blog, we’ll explore the technical underpinnings of LCMs, their architecture, components, and capabilities and examine how they are shaping the future of AI.
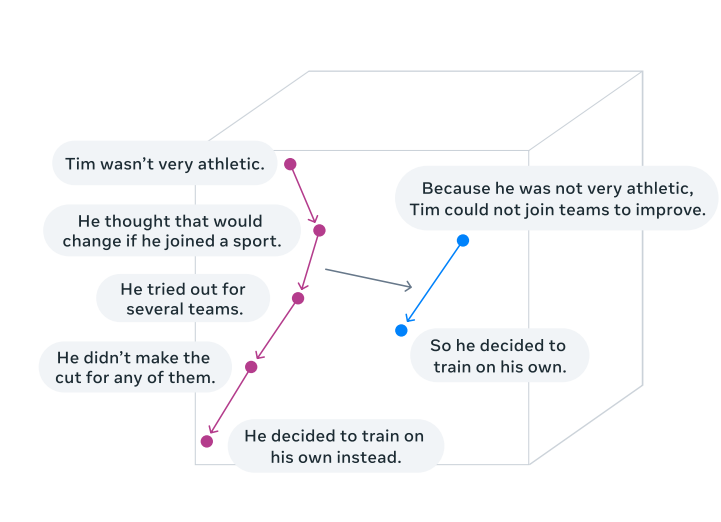
illustrated: visualization of reasoning in an embedding space of concepts (task of summarization) (source: https://arxiv.org/pdf/2412.08821)
Technical Overview of Large Concept Models
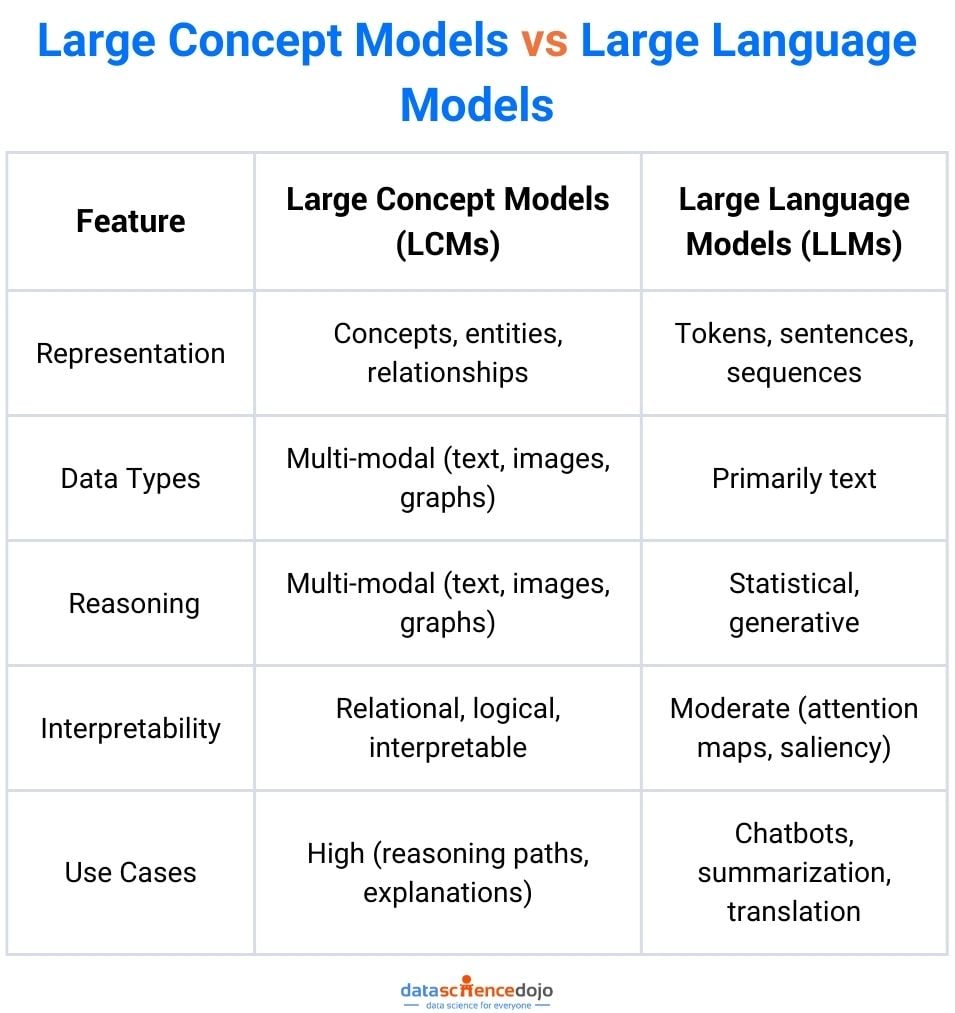
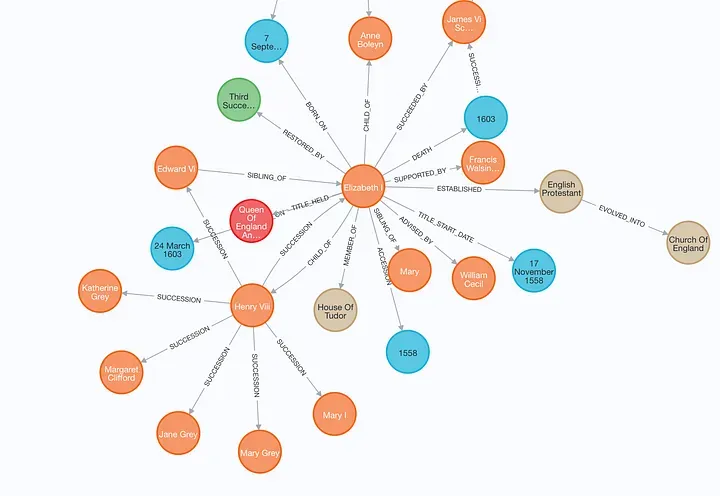
Large concept models (LCMs) are advanced AI systems designed to represent and reason over abstract concepts, relationships, and multi-modal data. Unlike LLMs, which primarily operate in the token or sentence space, LCMs focus on structured representations—often leveraging knowledge graphs, embeddings, and neural-symbolic integration.
Key Technical Features:
1. Concept Representation:
Large Concept Models encode entities, events, and abstract ideas as high-dimensional vectors (embeddings) that capture semantic and relational information.
2. Knowledge Graph Integration:
These models use knowledge graphs, where nodes represent concepts and edges denote relationships (e.g., “insulin resistance” —is-a→ “metabolic disorder”). This enables multi-hop reasoning and relational inference.
3. Multi-Modal Learning:
Large Concept Models process and integrate data from diverse modalities—text, images, structured tables, and even audio—using specialized encoders for each data type.
4. Reasoning Engine:
At their core, Large Concept Models employ neural architectures (such as graph neural networks) and symbolic reasoning modules to infer new relationships, answer complex queries, and provide interpretable outputs.
5. Interpretability:
Large Concept Models are designed to trace their reasoning paths, offering explanations for their outputs—crucial for domains like healthcare, finance, and scientific research.
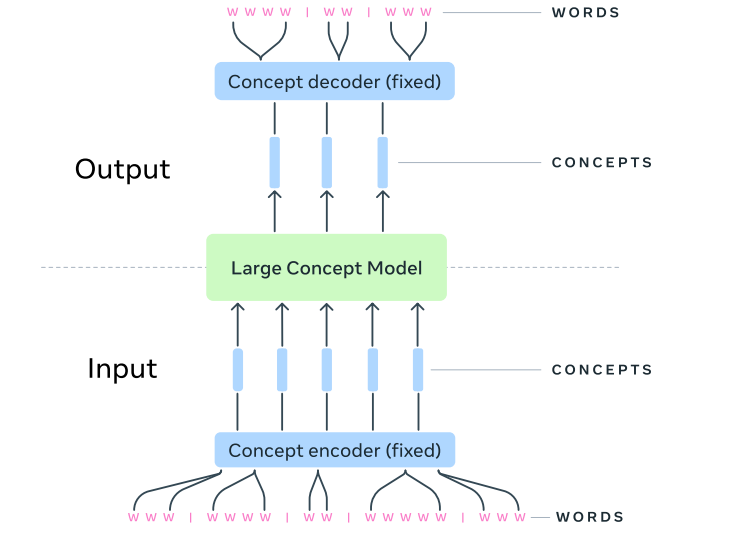
fundamental architecture of an Large Concept Model (LCM). source: https://arxiv.org/pdf/2412.08821
A large concept model (LCM) is not a single monolithic network but a composite system that integrates multiple specialized components into a reasoning pipeline. Its architecture typically blends neural encoders, symbolic structures, and graph-based reasoning engines, working together to build and traverse a dynamic knowledge representation.
Core Components
1. Input Encoders
Text Encoder: Transformer-based architectures (e.g., BERT, T5, GPT-like) that map words and sentences into semantic embeddings.
Vision Encoder: CNNs, vision transformers (ViTs), or CLIP-style dual encoders that turn images into concept-level features.
Structured Data Encoder: Tabular encoders or relational transformers for databases, spreadsheets, and sensor logs.
Audio/Video Encoders: Sequence models (e.g., conformers) or multimodal transformers to process temporal signals.
These encoders normalize heterogeneous data into a shared embedding space where concepts can be compared and linked.
2. Concept Graph Builder
Constructs or updates a knowledge graph where nodes = concepts and edges = relations (hierarchies, causal links, temporal flows).
May rely on graph embedding techniques (e.g., TransE, RotatE, ComplEx) or schema-guided extraction from raw text.
Handles dynamic updates, so the graph evolves as new data streams in (important for enterprise or research domains).
Aligns embeddings across modalities into a unified concept space.
Often uses cross-attention mechanisms (like in CLIP or Flamingo) to ensure that, for example, an image of “insulin injection” links naturally with the textual concept of “diabetes treatment.”
May incorporate contrastive learning to force consistency across modalities.
4. Reasoning and Inference Module
The “brain” of the Large Concept Model, combining graph neural networks (GNNs), differentiable logic solvers, or neural-symbolic hybrids.
Capabilities:
Multi-hop reasoning (chaining concepts together across edges).
This layered architecture allows LCMs to scale across domains, adapt to new knowledge, and explain their reasoning—three qualities where LLMs often fall short.
Think of an Large Concept Model as a super-librarian. Instead of just finding books with the right keywords (like a search engine), this librarian understands the content, connects ideas across books, and can explain how different topics relate. If you ask a complex question, the librarian doesn’t just give you a list of books—they walk you through the reasoning, showing how information from different sources fits together.
Combining structured and unstructured data from multiple sources is complex and requires robust data engineering.
Model Complexity:
Building and maintaining large, dynamic concept graphs demands significant computational resources and expertise.
Bias and Fairness:
Ensuring that Large Concept Models provide fair and unbiased reasoning requires careful data curation and ongoing monitoring.
Evaluation:
Traditional benchmarks may not fully capture the reasoning and interpretability strengths of Large Concept Models.
Scalability:
Deploying LCMs at enterprise scale involves challenges in infrastructure, maintenance, and user adoption.
Conclusion & Further Reading
Large concept models represent a significant leap forward in artificial intelligence, enabling machines to reason over complex, multi-modal data and provide transparent, interpretable outputs. By combining technical rigor with accessible analogies, we can appreciate both the power and the promise of Large Concept Models for the future of AI.
Graph rag is rapidly emerging as the gold standard for context-aware AI, transforming how large language models (LLMs) interact with knowledge. In this comprehensive guide, we’ll explore the technical foundations, architectures, use cases, and best practices of graph rag versus traditional RAG, helping you understand which approach is best for your enterprise AI, research, or product development needs.
Why Graph RAG Matters
Graph rag sits at the intersection of retrieval-augmented generation, knowledge graph engineering, and advanced context engineering. As organizations demand more accurate, explainable, and context-rich AI, graph rag is becoming essential for powering next-generation enterprise AI, agentic AI, and multi-hop reasoning systems.
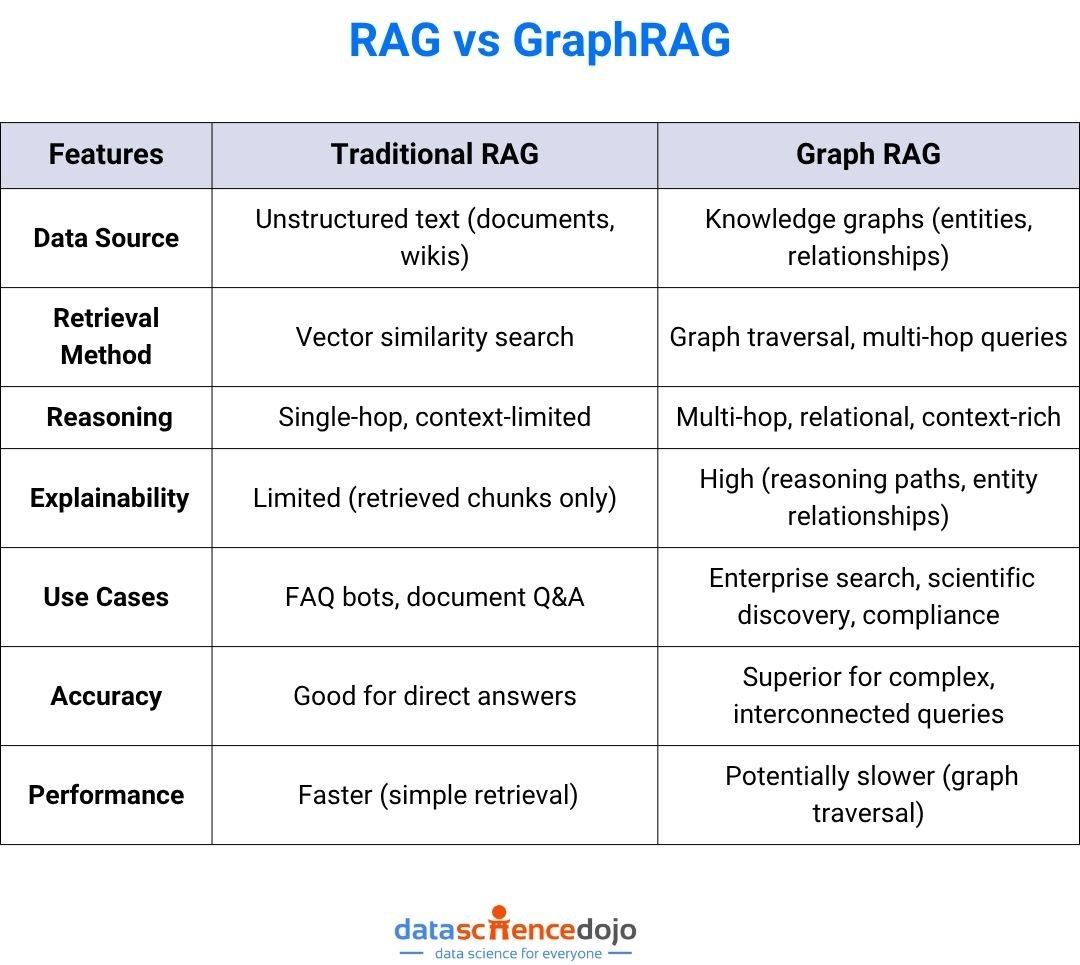
Traditional RAG systems have revolutionized how LLMs access external knowledge, but they often fall short when queries require understanding relationships, context, or reasoning across multiple data points. Graph rag addresses these limitations by leveraging knowledge graphs—structured networks of entities and relationships—enabling LLMs to reason, traverse, and synthesize information in ways that mimic human cognition.
For organizations and professionals seeking to build robust, production-grade AI, understanding the nuances of graph rag is crucial. Data Science Dojo’s LLM Bootcamp and Agentic AI resources are excellent starting points for mastering these concepts.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a foundational technique in modern AI, especially for LLMs. It bridges the gap between static model knowledge and dynamic, up-to-date information by retrieving relevant data from external sources at inference time.
How RAG Works
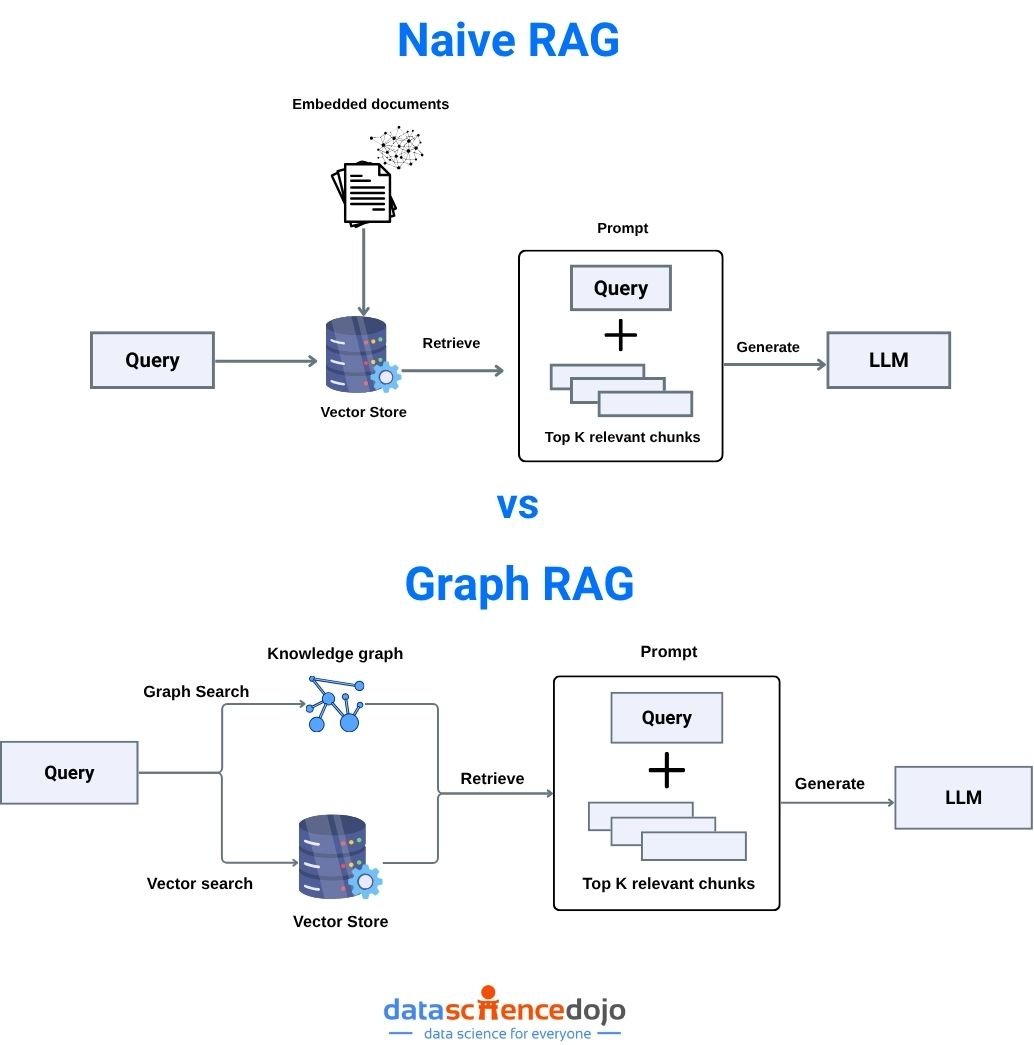
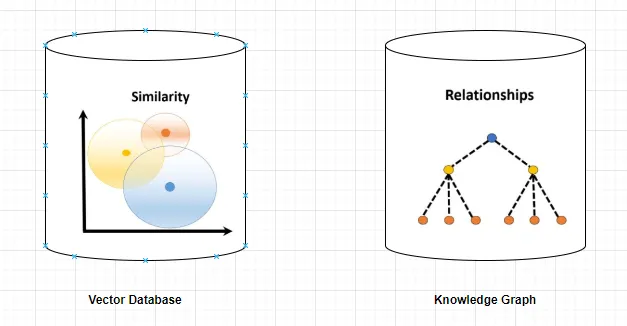
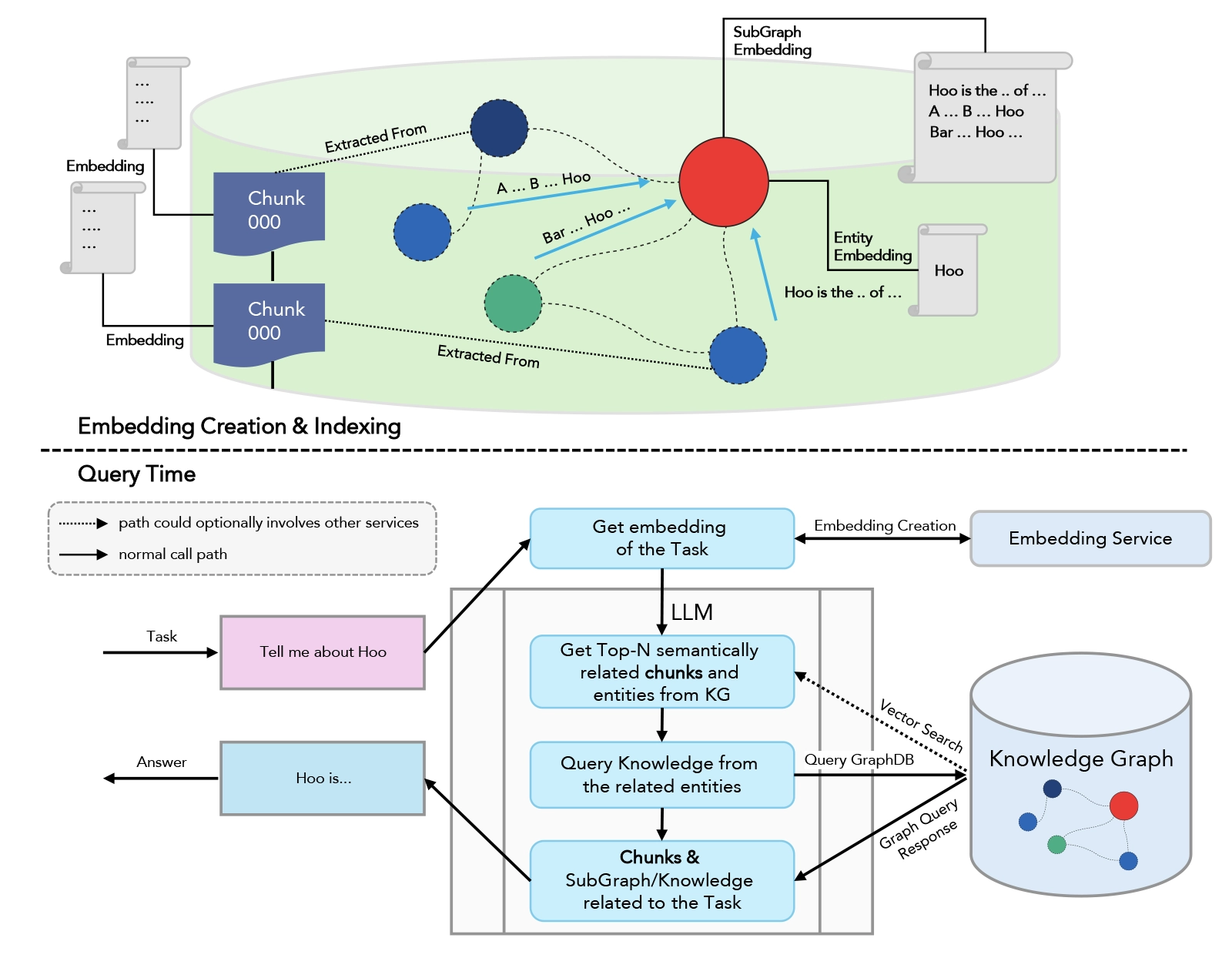
Indexing: Documents are chunked and embedded into a vector database.
Retrieval: At query time, the system finds the most semantically relevant chunks using vector similarity search.
Augmentation: Retrieved context is concatenated with the user’s prompt and fed to the LLM.
Generation: The LLM produces a grounded, context-aware response.
Graph rag is an advanced evolution of RAG that leverages knowledge graphs—structured representations of entities (nodes) and their relationships (edges). Instead of retrieving isolated text chunks, graph rag retrieves interconnected entities and their relationships, enabling multi-hop reasoning and deeper contextual understanding.
Key Features of Graph RAG
Multi-hop Reasoning:Answers complex queries by traversing relationships across multiple entities.
Contextual Depth: Retrieves not just facts, but the relationships and context connecting them.
Structured Data Integration: Ideal for enterprise data, scientific research, and compliance scenarios.
Explainability:Provides transparent reasoning paths, improving trust and auditability.
Retriever: Finds top-k relevant chunks for a query using vector similarity.
LLM: Generates a response using retrieved context.
Limitations:
Traditional RAG is limited to single-hop retrieval and struggles with queries that require understanding relationships or synthesizing information across multiple documents.
Graph RAG Pipeline
Knowledge Graph: Stores entities and their relationships as nodes and edges.
Graph Retriever:Traverses the graph to find relevant nodes, paths, and multi-hop connections.
LLM: Synthesizes a response using both entities and their relationships, often providing reasoning chains.
Why Graph RAG Excels:
Graph rag enables LLMs to answer questions that require understanding of how concepts are connected, not just what is written in isolated paragraphs. For example, in healthcare, graph rag can connect symptoms, treatments, and patient history for more accurate recommendations.
A leading hospital implemented graph rag to power its clinical decision support system. By integrating patient records, drug databases, and medical literature into a knowledge graph, the assistant could answer complex queries such as:
“What is the recommended treatment for a diabetic patient with hypertension and a history of kidney disease?”
Impact:
Reduced diagnostic errors by 30%
Improved clinician trust due to transparent reasoning paths
Case Study 2: Financial Compliance
A global bank used graph rag to automate compliance checks. The system mapped transactions, regulations, and customer profiles in a knowledge graph, enabling multi-hop queries like:
“Which transactions are indirectly linked to sanctioned entities through intermediaries?”
Impact:
Detected 2x more suspicious patterns than traditional RAG
Streamlined audit trails for regulatory reporting
Case Study 3: Data Science Dojo’s LLM Bootcamp
Participants in the LLM Bootcamp built both RAG and graph rag pipelines. They observed that graph rag consistently outperformed RAG in tasks requiring reasoning across multiple data sources, such as legal document analysis and scientific literature review.
Best Practices for Implementation
source: infogain
Start with RAG:
Use traditional RAG for unstructured data and simple Q&A.
Adopt Graph RAG for Complexity:
When queries require multi-hop reasoning or relationship mapping, transition to graph rag.
Leverage Hybrid Approaches:
Combine vector search and graph traversal for maximum coverage.
Monitor and Benchmark:
Use hybrid scorecards to track both AI quality and engineering velocity.
Iterate Relentlessly:
Experiment with chunking, retrieval, and prompt formats for optimal results.
Treat Context as a Product:
Apply version control, quality checks, and continuous improvement to your context pipelines.
Structure Prompts Clearly:
Separate instructions, context, and queries for clarity.
Leverage In-Context Learning:
Provide high-quality examples in the prompt.
Security and Compliance:
Guard against prompt injection, data leakage, and unauthorized tool use.
Ethics and Privacy:
Ensure responsible use of interconnected personal or proprietary data.
Context Quality Paradox: More context isn’t always better—balance breadth and relevance.
Scalability: Graph rag can be resource-intensive; optimize graph size and traversal algorithms.
Security:Guard against data leakage and unauthorized access to sensitive relationships.
Ethics and Privacy: Ensure responsible use of interconnected personal or proprietary data.
Performance:Graph traversal can introduce latency compared to vector search.
Future Trends
Context-as-a-Service: Platforms offering dynamic context assembly and delivery.
Multimodal Context: Integrating text, audio, video, and structured data.
Agentic AI:Embedding graph rag in multi-step agent loops with planning, tool use, and reflection.
Automated Knowledge Graph Construction:Using LLMs and data pipelines to build and update knowledge graphs in real time.
Explainable AI: Graph rag’s reasoning chains will drive transparency and trust in enterprise AI.
Emerging trends include context-as-a-service platforms, multimodal context (text, audio, video), and contextual AI ethics frameworks. For more, see Agentic AI.
Frequently Asked Questions (FAQ)
Q1: What is the main advantage of graph rag over traditional RAG?
A: Graph rag enables multi-hop reasoning and richer, more accurate responses by leveraging relationships between entities, not just isolated facts.
Q2: When should I use graph rag?
A: Use graph rag when your queries require understanding of how concepts are connected—such as in enterprise search, compliance, or scientific discovery.
Q3: What frameworks support graph rag?
A: Popular frameworks include LangChain and LlamaIndex, which offer orchestration, memory management, and integration with vector databases and knowledge graphs.
A: Graph rag can be slower due to graph traversal and reasoning, but it delivers superior accuracy and explainability for complex queries 1.
Q6: Can I combine RAG and graph rag in one system?
A: Yes! Many advanced systems use a hybrid approach, first retrieving relevant documents with RAG, then mapping entities and relationships with graph rag for deeper reasoning.
Conclusion & Next Steps
Graph rag is redefining what’s possible with retrieval-augmented generation. By enabling LLMs to reason over knowledge graphs, organizations can unlock new levels of accuracy, transparency, and insight in their AI systems. Whether you’re building enterprise AI, scientific discovery tools, or next-gen chatbots, understanding the difference between graph rag and traditional RAG is essential for staying ahead.
Model Context Protocol (MCP) is rapidly emerging as the foundational layer for intelligent, tool-using AI systems, especially as organizations shift from prompt engineering to context engineering. Developed by Anthropic and now adopted by major players like OpenAI and Microsoft, MCP provides a standardized, secure way for large language models (LLMs) and agentic systems to interface with external APIs, databases, applications, and tools. It is revolutionizing how developers scale, govern, and deploy context-aware AI applications at the enterprise level.
As the world embraces agentic AI, where models don’t just generate text but interact with tools and act autonomously, MCP ensures those actions are interoperable, auditable, and secure, forming the glue that binds agents to the real world.
Model Context Protocol is an open specification that standardizes the way LLMs and AI agents connect with external systems like REST APIs, code repositories, knowledge bases, cloud applications, or internal databases. It acts as a universal interface layer, allowing models to ground their outputs in real-world context and execute tool calls safely.
Key Objectives of MCP:
Standardize interactions between models and external tools
Enable secure, observable, and auditable tool usage
Reduce integration complexity and duplication
Promote interoperability across AI vendors and ecosystems
Unlike proprietary plugin systems or vendor-specific APIs, MCP is model-agnostic and language-independent, supporting multiple SDKs including Python, TypeScript, Java, Swift, Rust, Kotlin, and more.
Why MCP Matters: Solving the M×N Integration Problem
Before MCP, integrating each of M models (agents, chatbots, RAG pipelines) with N tools (like GitHub, Notion, Postgres, etc.) required M × N custom connections—leading to enormous technical debt.
MCP collapses this to M + N:
Each AI agent integrates one MCP client
Each tool or data system provides one MCP server
All components communicate using a shared schema and protocol
This pattern is similar to USB-C in hardware: a unified protocol for any model to plug into any tool, regardless of vendor.
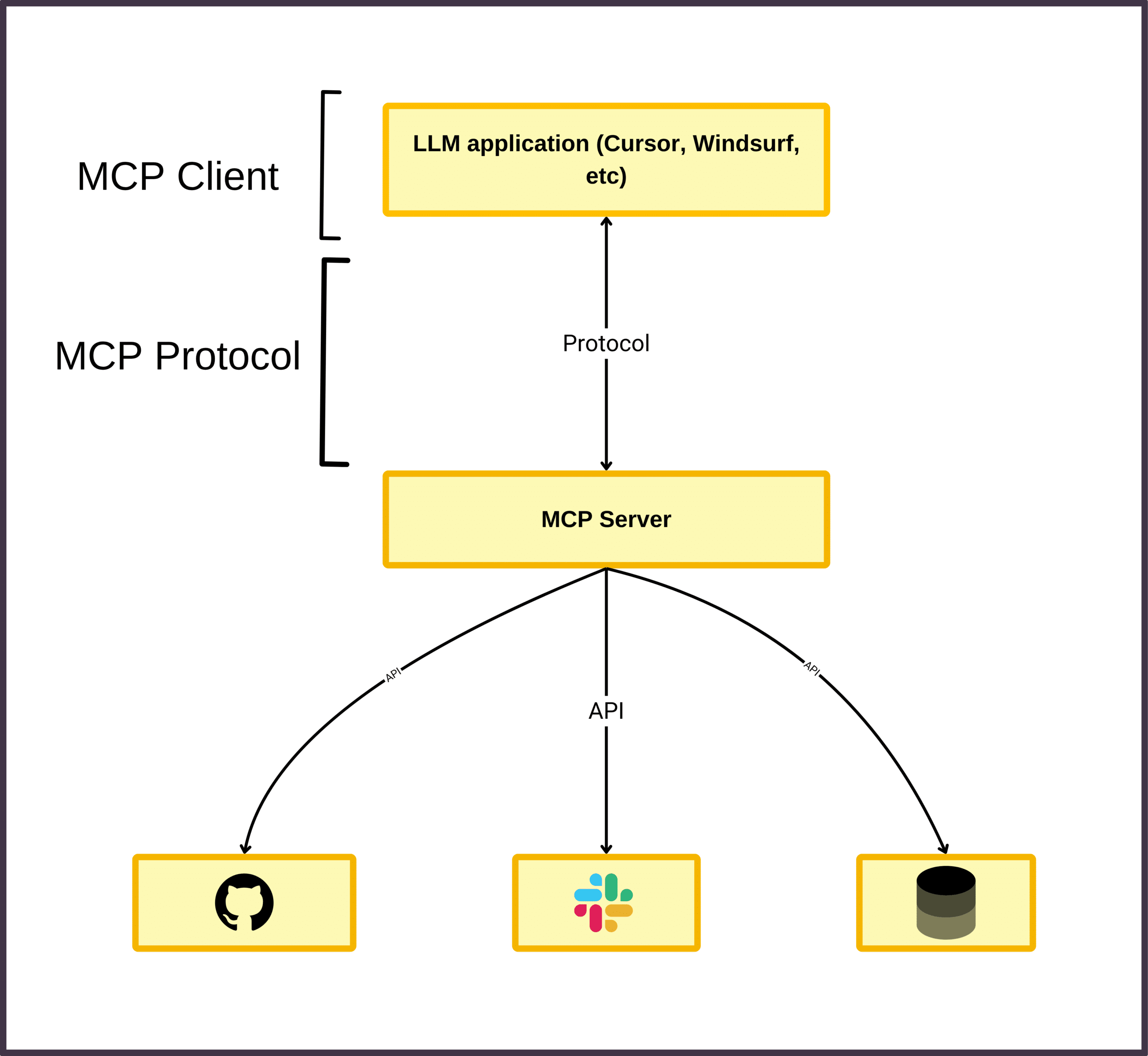
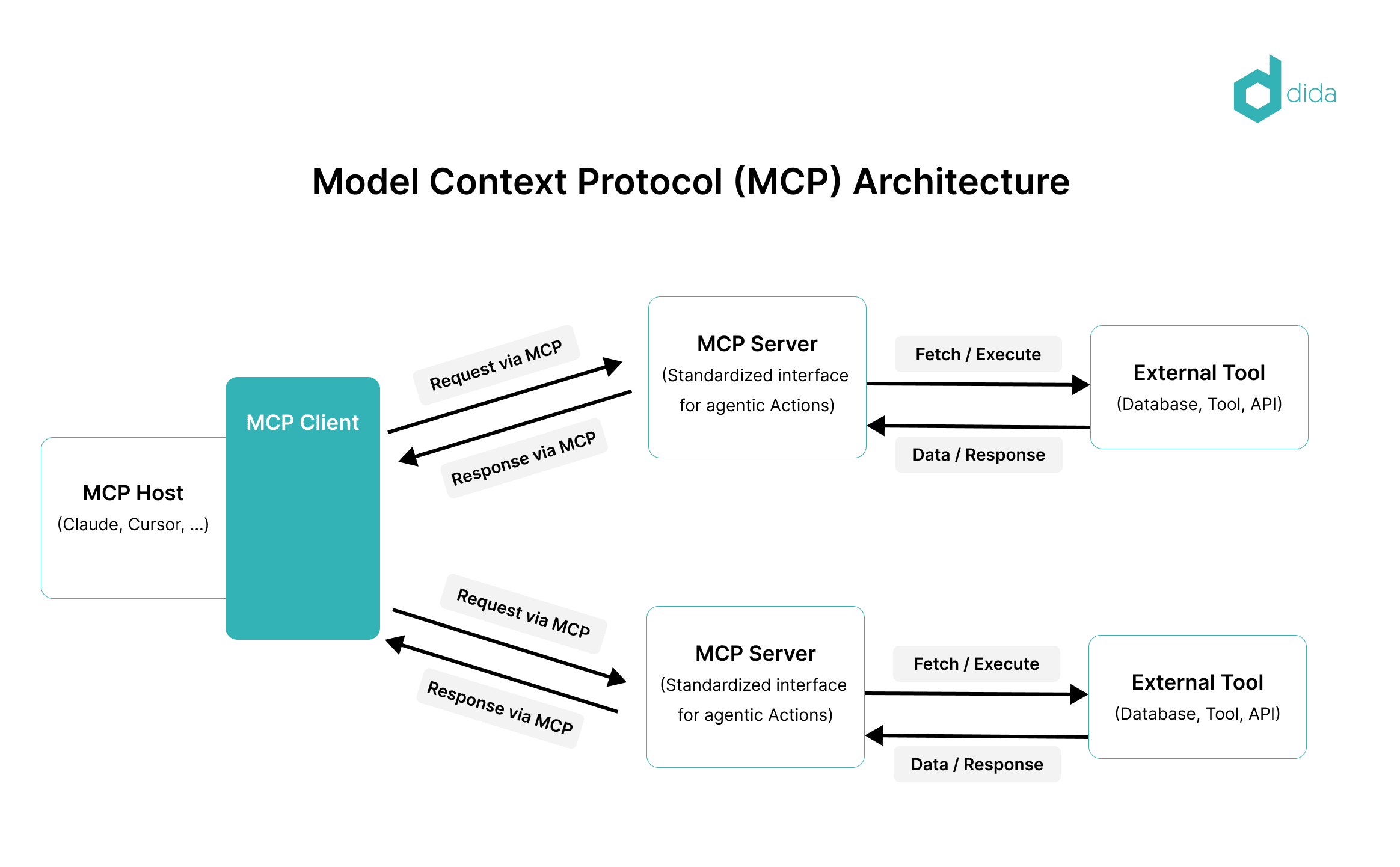
Architecture: Clients, Servers, and Hosts
source: dida.do
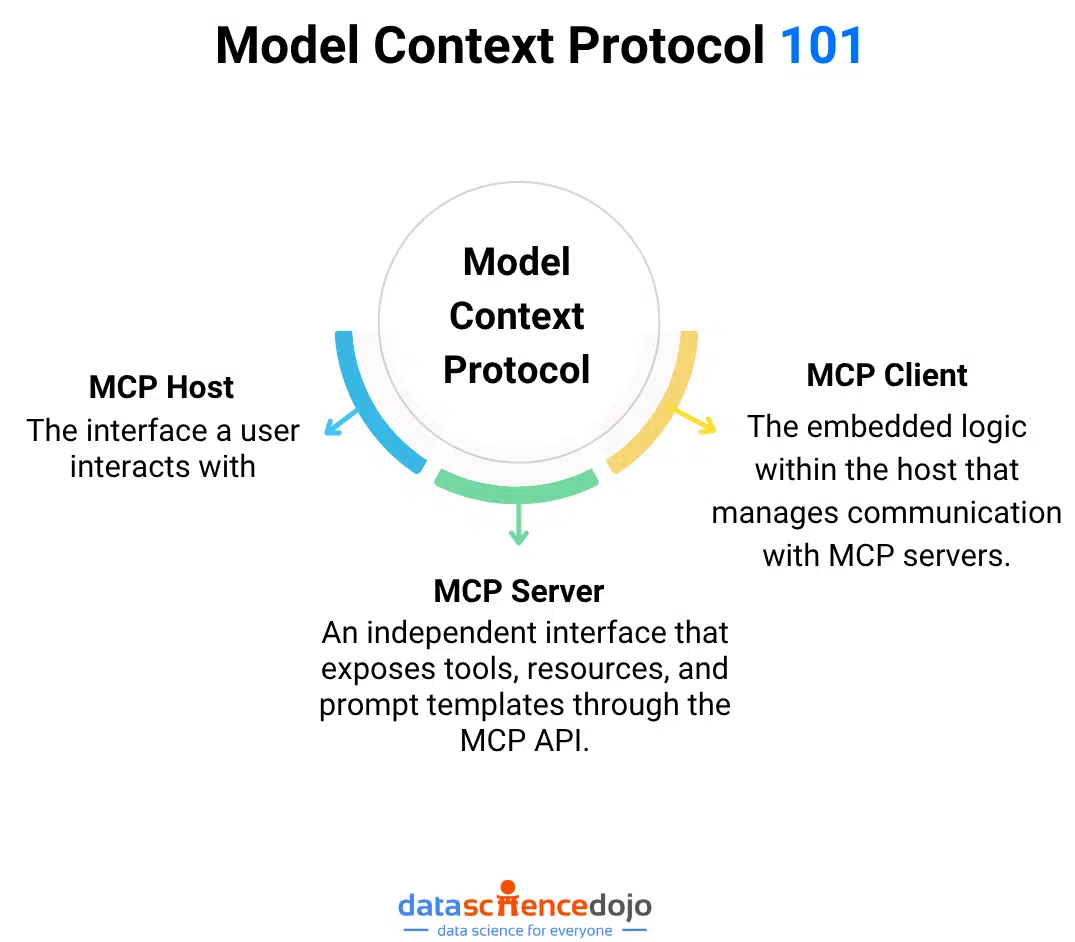
MCP is built around a structured host–client–server architecture:
1. Host
The interface a user interacts with—e.g., an IDE, a chatbot UI, a voice assistant.
2. Client
The embedded logic within the host that manages communication with MCP servers. It mediates requests from the model and sends them to the right tools.
3. Server
An independent interface that exposes tools, resources, and prompt templates through the MCP API.
Supported Transports:
stdio: For local tool execution (high trust, low latency)
HTTP/SSE: For cloud-native or remote server integration
Example Use Case:
An AI coding assistant (host) uses an MCP client to connect with:
A GitHub MCP server to manage issues or PRs
A CI/CD MCP server to trigger test pipelines
A local file system server to read/write code
All these interactions happen via a standard protocol, with complete traceability.
Key Features and Technical Innovations
A. Unified Tool and Resource Interfaces
Tools: Executable functions (e.g., API calls, deployments)
Resources: Read-only data (e.g., support tickets, product specs)
Prompts: Model-guided instructions on how to use tools or retrieve data effectively
This separation makes AI behavior predictable, modular, and controllable.
B. Structured Messaging Format
MCP defines strict message types:
user, assistant, tool, system, resource
Each message is tied to a role, enabling:
Explicit context control
Deterministic tool invocation
Preventing prompt injection and role leakage
C. Context Management
MCP clients handle context windows efficiently:
Trimming token history
Prioritizing relevant threads
Integrating summarization or vector embeddings
This allows agents to operate over long sessions, even with token-limited models.
D. Security and Governance
MCP includes:
OAuth 2.1, mTLS for secure authentication
Role-based access control (RBAC)
Tool-level permission scopes
Signed, versioned components for supply chain security
E. Open Extensibility
Dozens of public MCP servers now exist for GitHub, Slack, Postgres, Notion, and more.
SDKs available in all major programming languages
Supports custom toolchains and internal infrastructure
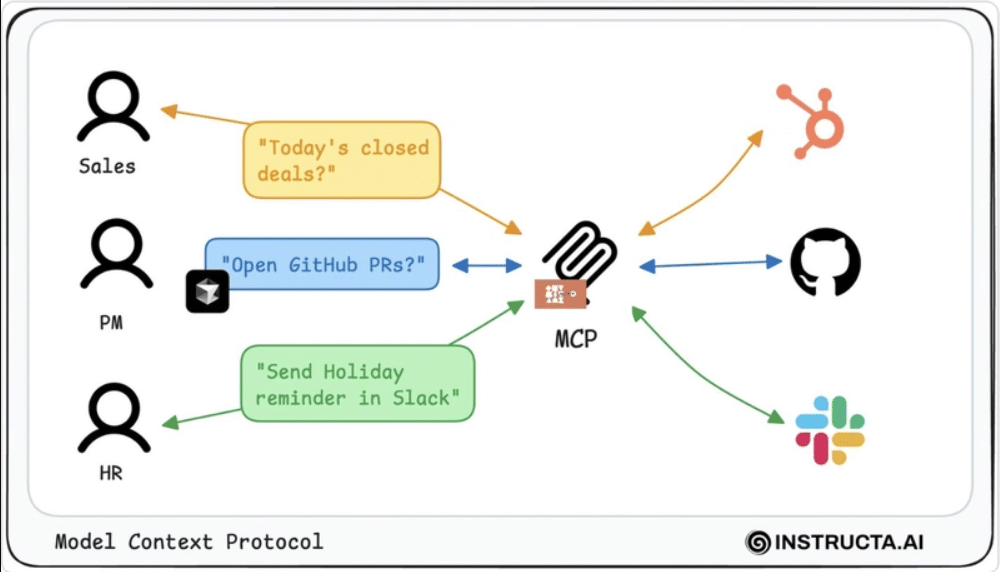
Model Context Protocol in Practice: Enterprise Use Cases
source: Instructa.ai
1. AI Assistants
LLMs access user history, CRM data, and company knowledge via MCP-integrated resources—enabling dynamic, contextual assistance.
2. RAG Pipelines
Instead of static embedding retrieval, RAG agents use MCP to query live APIs or internal data systems before generating responses.
3. Multi-Agent Workflows
Agents delegate tasks to other agents, tools, or humans, all via standardized MCP messages—enabling team-like behavior.
4. Developer Productivity
LLMs in IDEs use MCP to:
Review pull requests
Run tests
Retrieve changelogs
Deploy applications
5. AI Model Evaluation
Testing frameworks use MCP to pull logs, test cases, and user interactions—enabling automated accuracy and safety checks.
Challenges, Limitations, and the Future of Model Context Protocol
Known Challenges:
Managing long context histories and token limits
Multi-agent state synchronization
Server lifecycle/versioning and compatibility
Future Innovations:
Embedding-based context retrieval
Real-time agent collaboration protocols
Cloud-native standards for multi-vendor compatibility
Secure agent sandboxing for tool execution
As agentic systems mature, MCP will likely evolve into the default interface layer for enterprise-grade LLM deployment, much like REST or GraphQL for web apps.
FAQ
Q: What is the main benefit of MCP for enterprises?
A: MCP standardizes how AI models connect to tools and data, reducing integration complexity, improving security, and enabling scalable, context-aware AI solutions.
Q: How does MCP improve security?
A: MCP enforces authentication, authorization, and boundary controls, protecting against prompt/tool injection and unauthorized access.
Q: Can MCP be used with any LLM or agentic AI system?
A: Yes, MCP is model-agnostic and supported by major vendors (Anthropic, OpenAI), with SDKs for multiple languages.
Q: What are the best practices for deploying MCP?
A: Use vector databases, optimize context windows, sandbox local servers, and regularly audit/update components for security.
Conclusion:
Model Context Protocol isn’t just another spec, it’s the API standard for agentic intelligence. It abstracts away complexity, enforces governance, and empowers AI systems to operate effectively across real-world tools and systems.
Want to build secure, interoperable, and production-grade AI agents?
AI is revolutionizing business, but are enterprises truly prepared to scale it safely?
While AI promises efficiency, innovation, and competitive advantage, many organizations struggle with data security risks, governance complexities, and the challenge of managing unstructured data. Without the right infrastructure and safeguards, enterprise AI adoption can lead to data breaches, regulatory failures, and untrustworthy outcomes.
The solution? A strategic approach that integrates robust infrastructure with strong governance.
The combination of Databricks’ AI infrastructure and Securiti’s Gencore AI offers a security-first AI building framework, enabling enterprises to innovate while safeguarding sensitive data. This blog explores how businesses can build scalable, governed, and responsible AI systems by integrating robust infrastructure with embedded security, privacy, and observability controls.
However, before we dig deeper into the partnership and its role in boosting AI adoption, let’s understand the challenges around it.
Challenges in AI Adoption
AI adoption is no longer a question of if but how. Yet many enterprises face critical roadblocks that threaten both compliance and operational success. Without the rightunstructured data management and robust safeguards, AI projects risk non-compliance, non-transparency, and security vulnerabilities.
Here are the top challenges businesses must address:
Safeguarding Data Security and Compliance: AI systems process vast amounts of sensitive data. Organizations must ensure compliance with the EU AI Act, NIST AI RMF, GDPR, HIPAA, etc., while preventing unauthorized access. Failure to do so can lead to data breaches, legal repercussions, and loss of customer trust.
Managing Unstructured Data at Scale: AI models rely on high-quality data, yet most enterprise data is unstructured and fragmented. Without effective curation and sanitization, AI systems may generate unreliable or insecure results, undermining business decisions.
Ensuring AI Integrity and Trustworthiness: Biased, misleading, or unverifiable AI outputs can damage stakeholder confidence. Real-time monitoring, runtime governance, and ethical AI frameworks are essential to ensuring outcomes remain accurate and accountable.
Overcoming these challenges is key to unlocking AI’s full potential. The right strategy integrates AI development with strong security, governance, and compliance frameworks. This is where the Databricks and Securiti partnership creates a game-changing opportunity.
You can also read about algorithmic biases and their challenges in fair AI
A Strategic Partnership: Databricks and Securiti’s Gencore AI
In the face of these challenges, enterprises strive to balance innovation with security and compliance. Organizations must navigate data security, regulatory adherence, and ethical AI implementation.
The partnership between Databricks and Securiti offers a solution that empowers enterprises to scale AI initiatives confidently, ensuring security and governance are embedded in every step of the AI lifecycle.
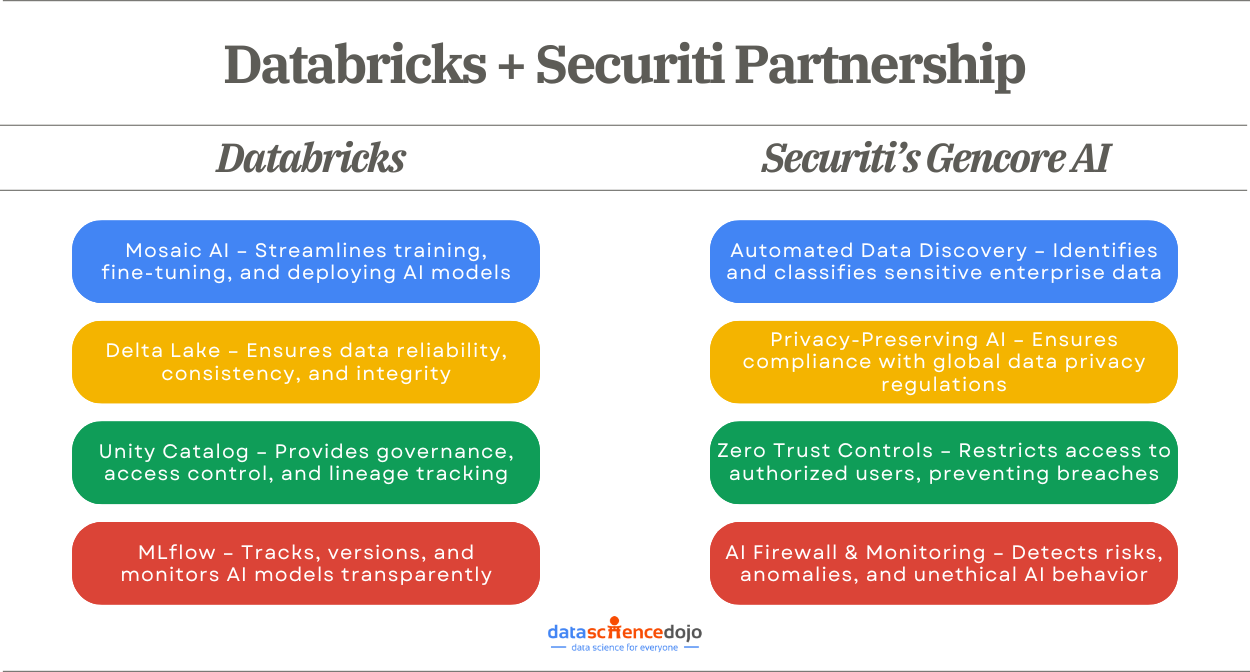
Databricks: Laying the AI Foundation
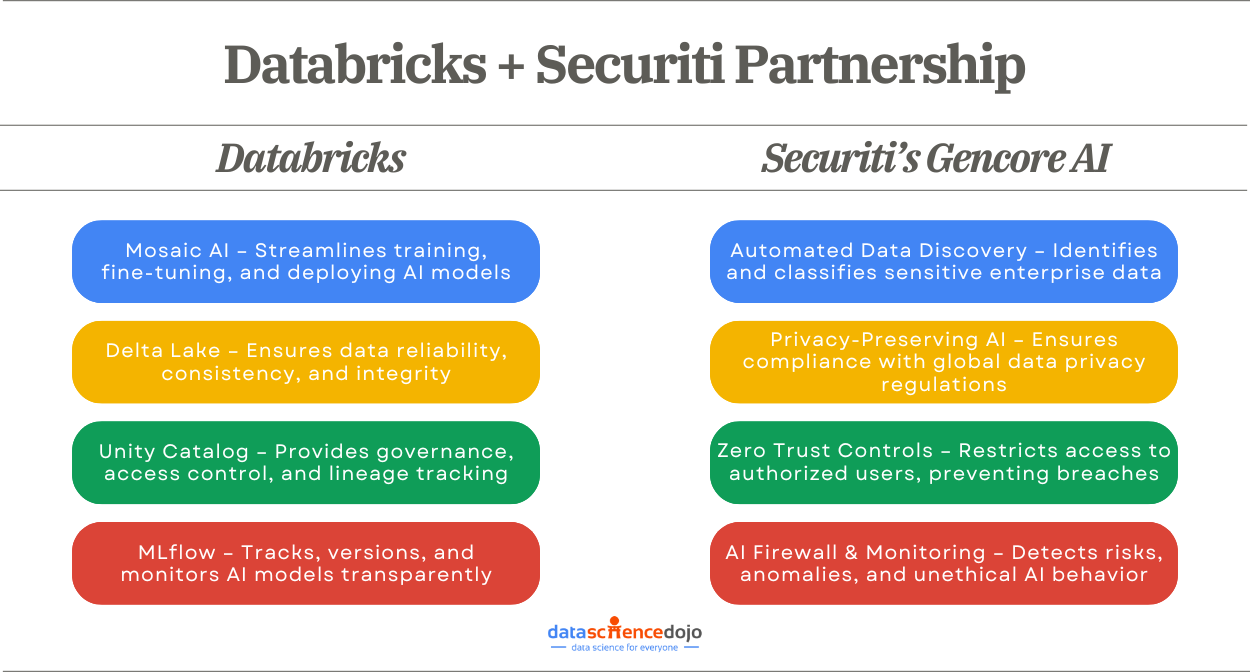
Databricks provides the foundational infrastructure needed for successful AI adoption. It offers tools that simplify data management and accelerate AI model development, such as:
Scalable Data Infrastructure – Databricks provides a unified platform for storing, processing, and analyzing vast amounts of structured and unstructured data. Its cloud-native architecture ensures seamless scalability to meet enterprise AI demands.
End-to-End AI Development – With tools like MLflow for model lifecycle management, Delta Lake for reliable data storage, and Mosaic AI for scalable training, Databricks streamlines AI development from experimentation to deployment.
Governance & Data Access Management – Databricks’ Unity Catalog enables centralized governance, enforcing secure data access, lineage tracking, and regulatory compliance to ensure AI models operate within a trusted framework.
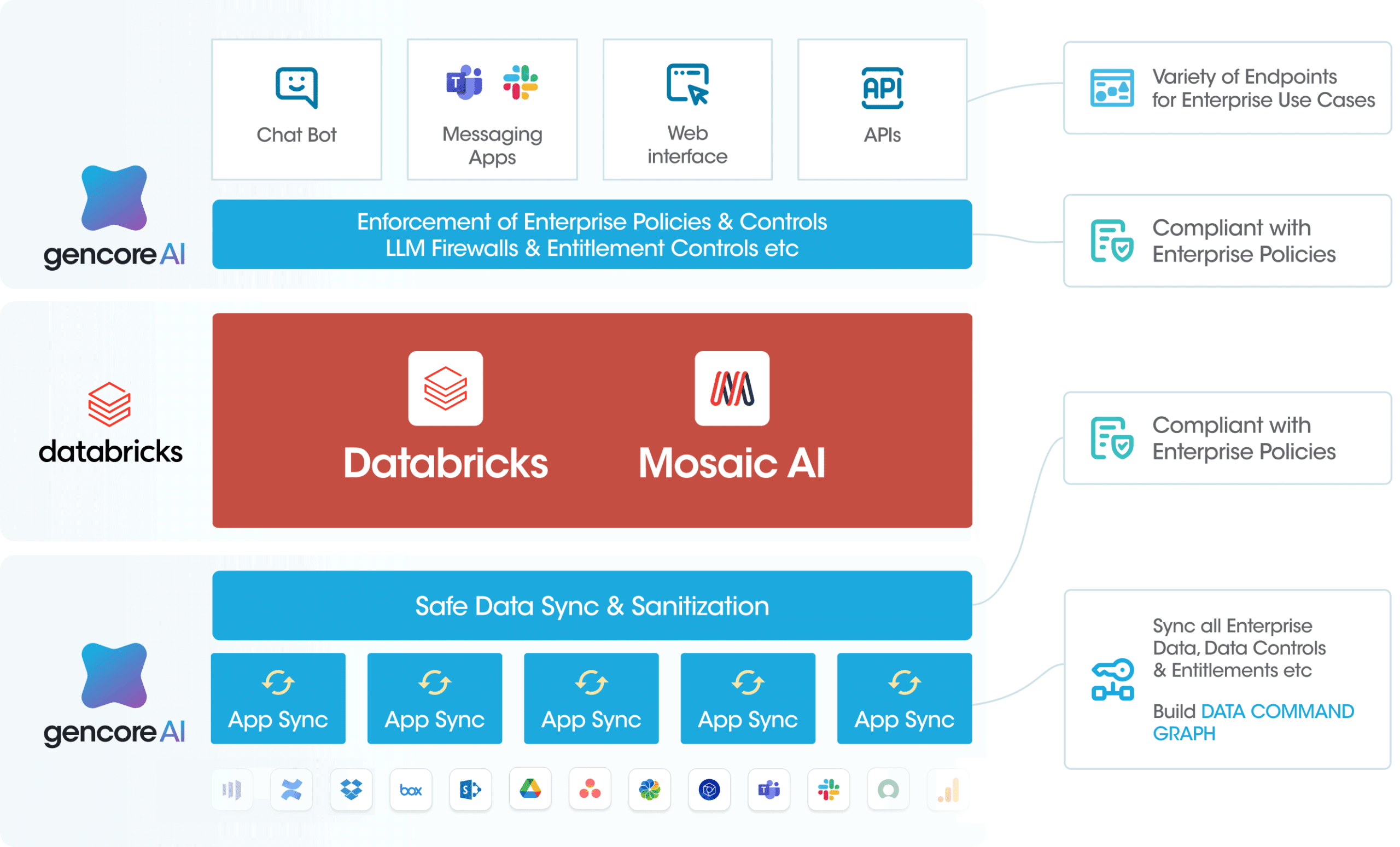
Building Safe Enterprise AI Systems with Databricks & Gencore AI
Securiti’s Gencore AI: Reinforcing Security and Compliance
While Databricks provides the AI infrastructure, Securiti’s Gencore AI ensures that AI models operate within a secure and compliant framework. It provides:
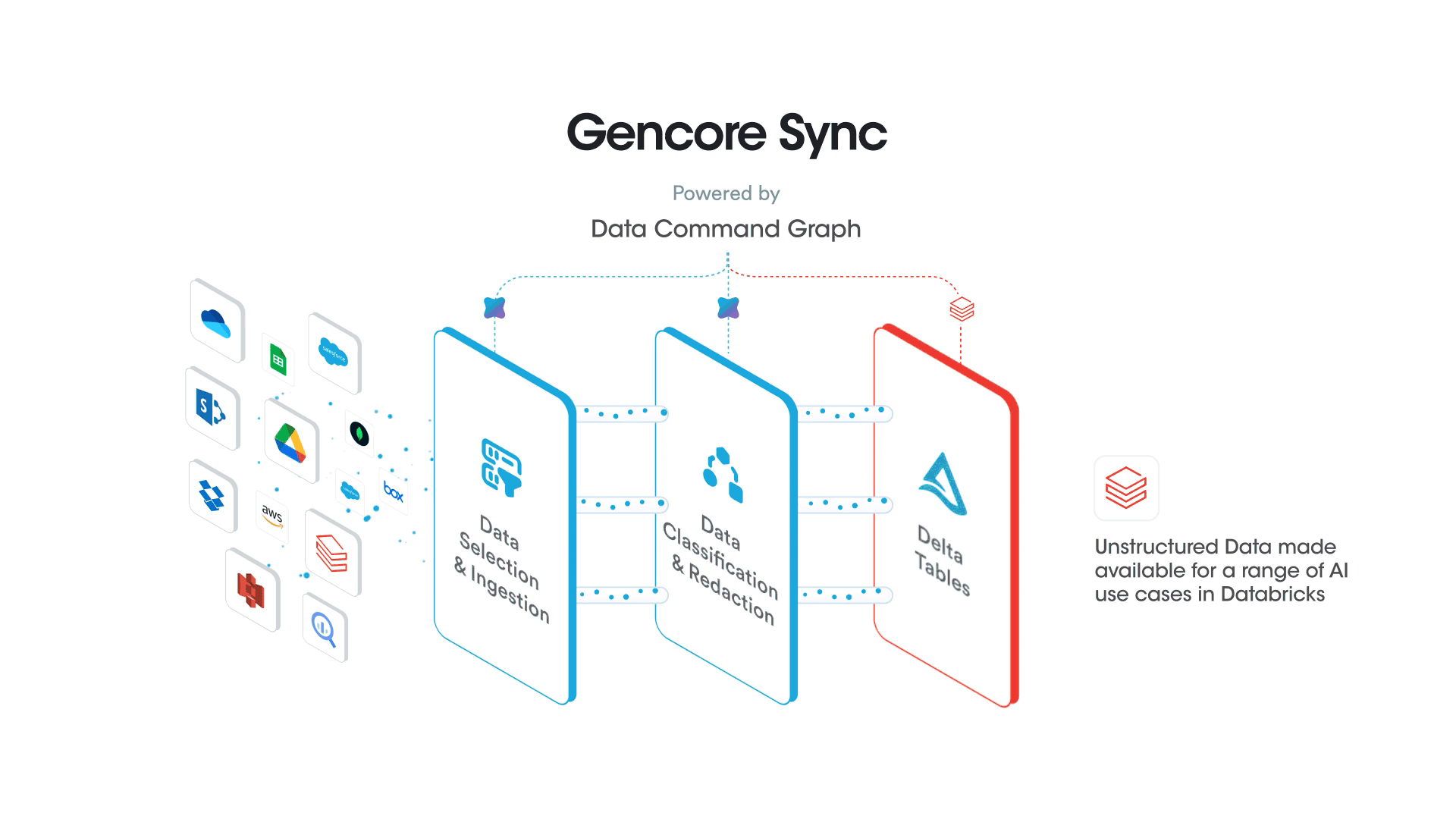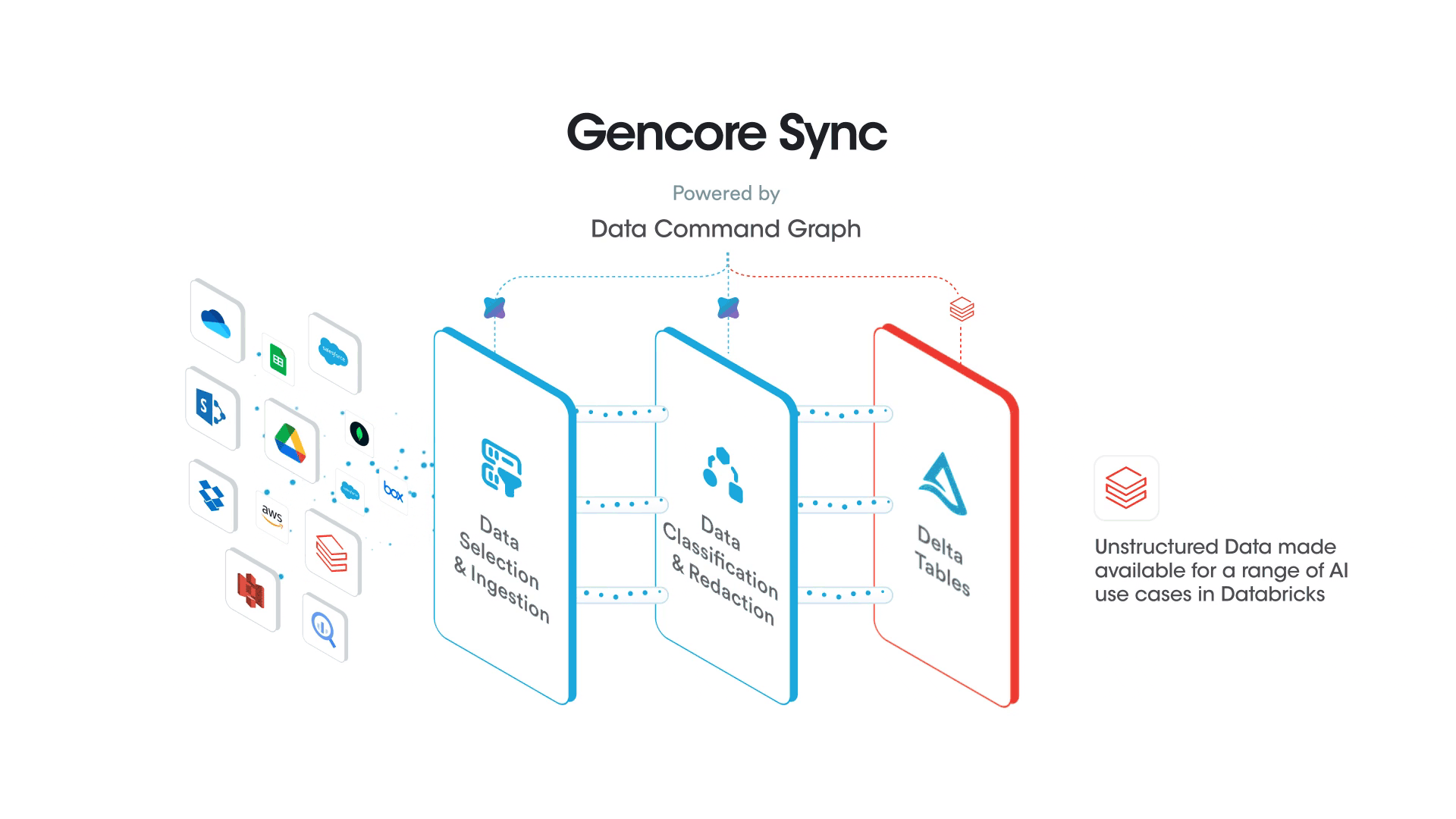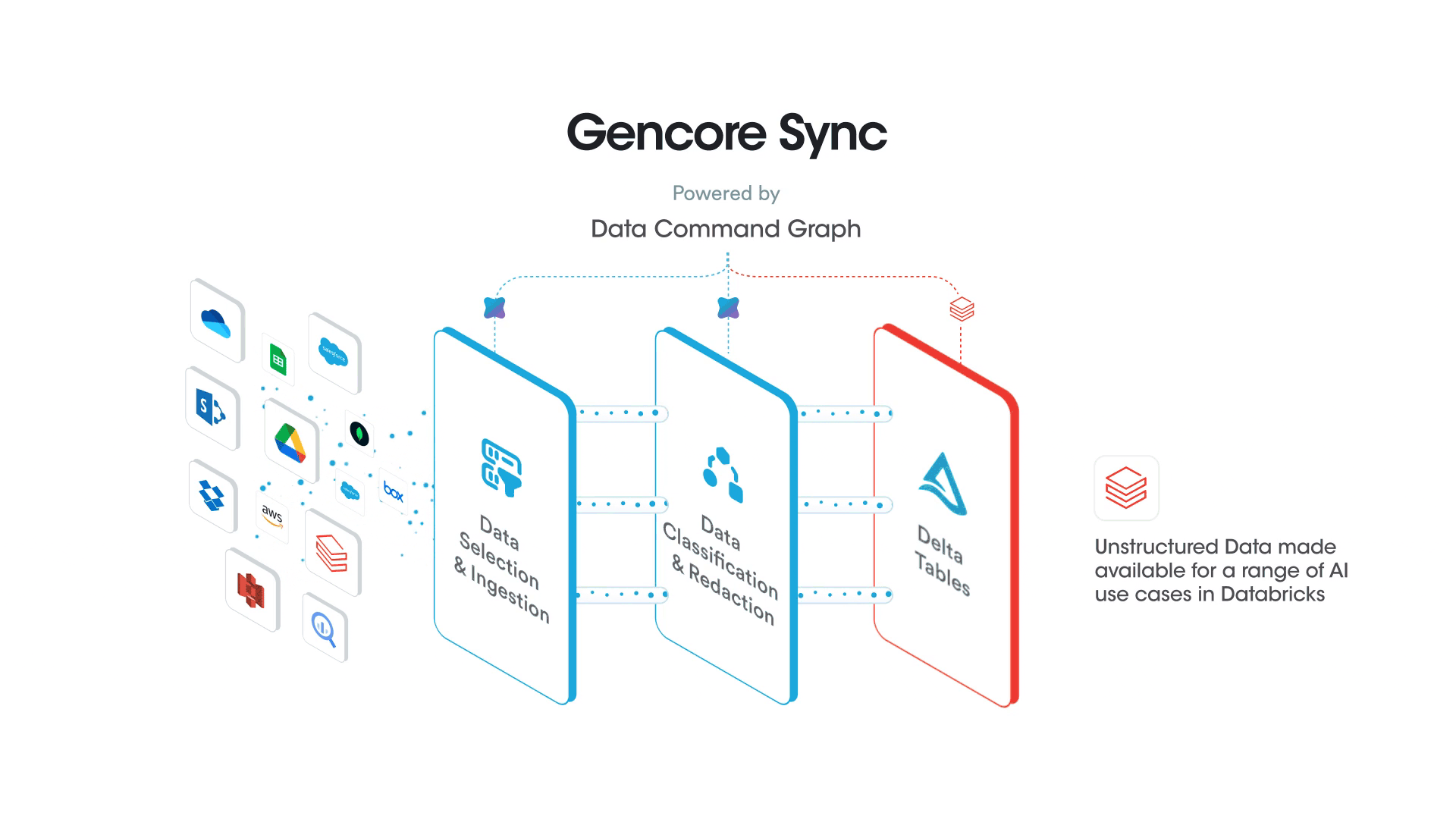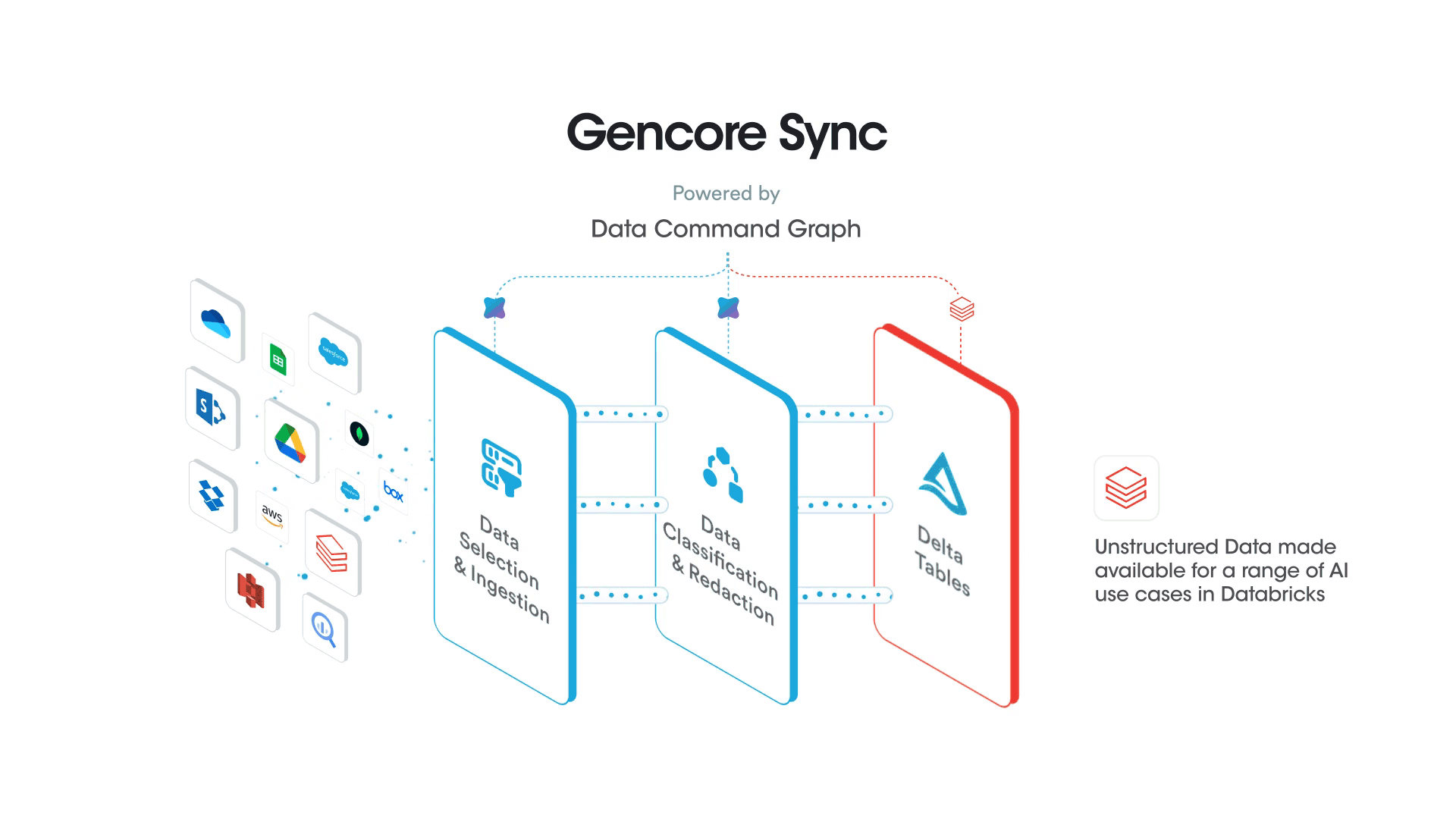
Ease of Building and Operating Safe AI Systems: Gencore AI streamlines data ingestion by connecting to both unstructured and structured data across different systems and applications, while allowing the use of any foundational or custom AI models in Databricks.
Embedded Security and Governance in AI Systems: Gencore AI aligns with OWASP Top 10 for LLMs to help embed data security and governance at every important stage of the AI System within Databricks, from data ingestion to AI consumption layers.
Complete Provenance Tracking for AI Systems: Gencore AI’s proprietary knowledge graph provides granular contextual insights about data and AI systems within Databricks.
Compliance with AI Regulations for each AI System: Gencore AI uniquely provides automated compliance checks for each of the AI Systems being operationalized in it.
Competitive Advantage: A Strategic AI Approach
To fully realize AI’s business potential, enterprises need more than just advanced models – they need a secure, scalable, and responsible AI strategy. The partnership between Databricks and Securiti is designed to achieve exactly that. It offers:
AI at Scale with Enterprise Trust – Databricks delivers an end-to-end AI infrastructure, while Securiti ensures security and compliance at every stage. Together, they create a seamless framework for enterprises to scale AI initiatives with confidence.
Security-Embedded Innovation – The integration ensures that AI models operate within a robust security framework, reducing risks of bias, data breaches, and regulatory violations. Businesses can focus on innovation without compromising compliance.
Holistic AI System Governance – This is not just a tech integration—it’s a strategic investment in AI governance and sustainability. As AI regulations evolve, enterprises using Databricks + Securiti will be well-positioned to adapt, ensuring long-term AI success. Effective AI governance requires embedded controls throughout the AI system, with a foundation rooted in understanding enterprise data context and its controls. Securiti’s Data Command Graph delivers this foundation by providing comprehensive contextual insights about data objects and their controls, enabling complete monitoring and governance of the entire enterprise AI system across all interconnected components rather than focusing solely on models.
Thus, the collaboration ensures AI systems are secure, governable, and ethically responsible while enabling enterprises to accelerate AI adoption confidently. Whether scaling AI, managing LLMs, or ensuring compliance, this gives businesses the confidence to innovate responsibly.
By embedding AI security, governance, and trust from day one, businesses can accelerate adoption while maintaining full control over their AI ecosystem. This partnership is not just about deploying AI, but also about building a future-ready AI strategy.
A 5-Step Framework for Secure Enterprise AI Deployment
Building a secure and compliant enterprise AI system requires more than just deploying AI models. A robust infrastructure, strong data governance, and proactive security measures are some key requirements for the process.
The combination of Databricks and Securiti’s Gencore AI provides an ideal foundation for enterprises to leverage AI while maintaining control, privacy, and compliance.
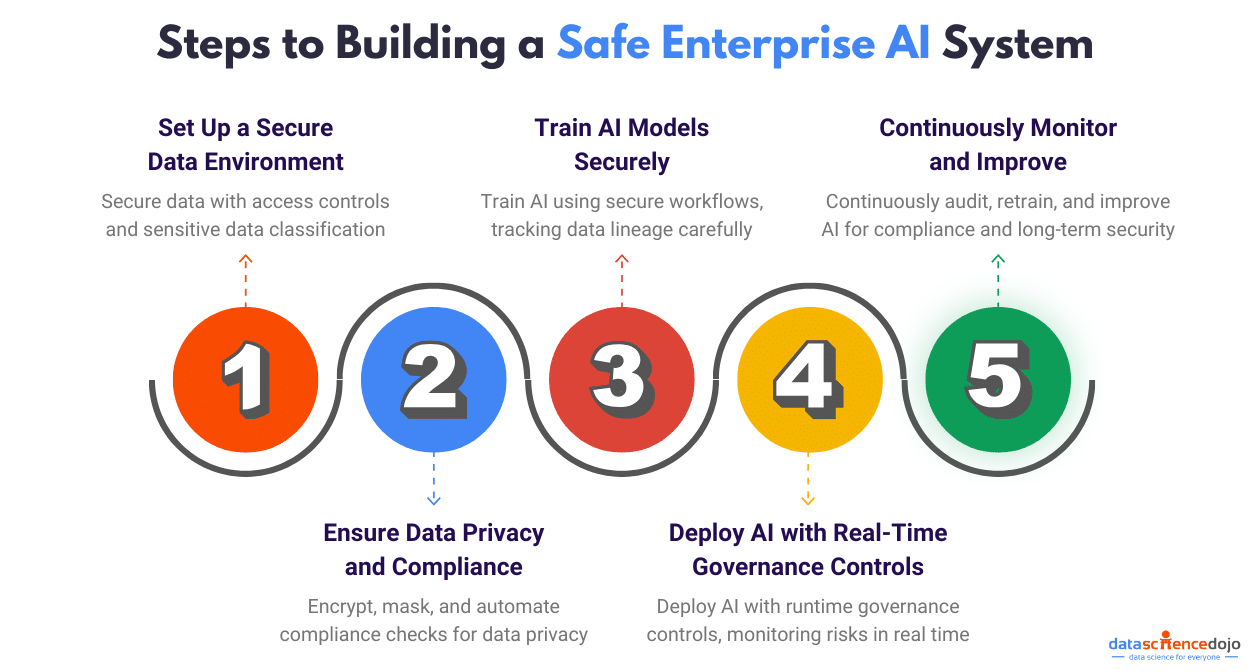
Steps to Building a Safe Enterprise AI System
Below is a structured step-by-step approach to building a safe AI system in Databricks with Securiti’s Gencore AI.
Step 1: Set Up a Secure Data Environment
The environment for your data is a crucial element and must be secured since it can contain sensitive information. Without the right safeguards, enterprises risk data breaches, compliance violations, and unauthorized access.
To establish such an environment, you must use Databricks’s Unity Catalog to establish role-based access control (RBAC) and enforce data security policies. It will ensure that only authorized users have access to specific datasets and avoid unintended data exposure.
The other action item at this step is to use Securiti’s Data Discovery & Classification to identify sensitive data before AI model training begins. This will ensure regulatory compliance by identifying data subject to the EU AI Act, NIST AI RMF, GDPR, HIPAA, and CCPA.
Step 2: Ensure Data Privacy and Compliance
Once data is classified and protected, it is important to ensure your AI operations maintain user privacy. AI models should never compromise user privacy or violate regulatory standards. You can establish this by enabling data encryption and masking to protect sensitive information.
While data masking will ensure that only anonymized information is used for AI training, you can also use synthetic data to ensure compliance and privacy.
Safely Syncing Unstructured Data to Databricks Delta Tables for Enterprise AI Use Cases
Step 3: Train AI Models Securely
Now that the data environment is secure and compliant, you can focus on training your AI models. However, AI model training must be monitored and controlled to prevent data misuse and security risks. Some key actions you can take for this include:
Leverage Databricks’ Mosaic AI for Scalable Model Training – use distributed computing power for efficient training of large-scale models while ensuring cost and performance optimization
Monitor Data Lineage & Usage with Databricks’ Unity Catalog – track data’s origin and how it is transformed and used in AI models to ensure only approved datasets are used for training and testing
Validate Models for Security & Compliance Before Deployment – perform security checks to identify any vulnerabilities and ensure that models conform to corporate AI governance policies
By implementing these controls, enterprises can train AI models securely and ethically while maintaining full visibility into their data, models, and AI system lifecycles.
Step 4: Deploy AI with Real-Time Governance Controls
The security threats and challenges do not end with the training and deployment. You must ensure continuous governance and security of your AI models and systems to prevent bias, data leaks, or any unauthorized AI interactions.
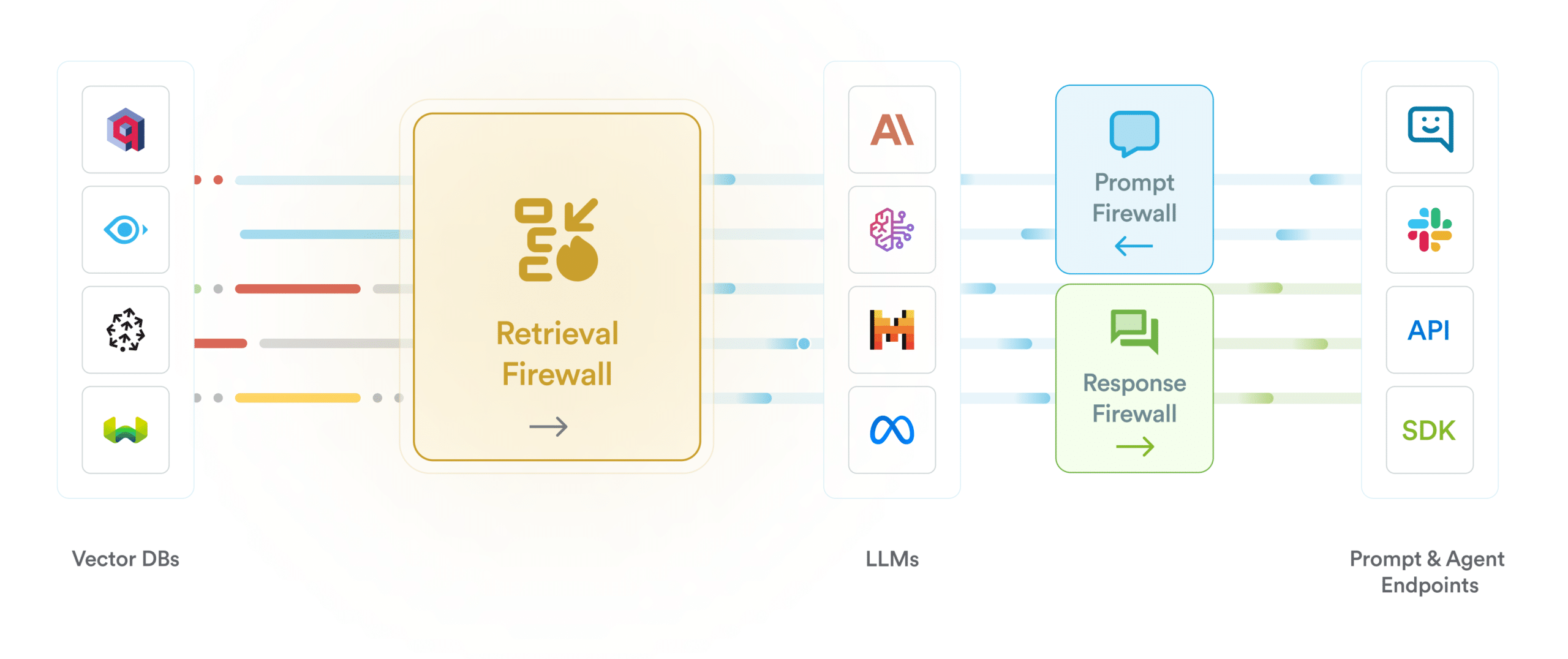
You can use Securiti’s distributed, context-aware LLM Firewall to monitor your model’s interactions and detect any unauthorized attempts, adversarial attacks, or security threats. The firewall will also monitor your AI model for hallucinations, bias, and regulatory violations.
Moreover, you must continuously audit your model’s output for accuracy and other ethical regulations. During the audit, you must flag and correct any responses that are inaccurate or unintended.
Inspecting and Controlling Prompts, Retrievals, and Responses
You must also implement Databricks’MLflowfor AI model version control and performance monitoring. It will maintain version histories for all the AI models you have deployed, enabling you to continuously track and improve model performance. This real-time monitoring ensures AI systems remain safe and accountable.
Step 5: Continuously Monitor and Improve AI Systems
Deploying and maintaining enterprise AI systems becomes an iterative process once you have set up the basic infrastructure. Continuous efforts are required to monitor and improve the system to maintain top-notch security, accuracy, and compliance.
You can do this by:
Using Securiti’s AI Risk Monitoring to detect threats in real-time and proactively address the issues
Regularly retrain AI models with safe, high-quality, and de-risked datasets
Conduct periodic AI audits and explainability assessments to ensure ethical AI usage
Automate compliance checks across AI systems to continuously monitor and enforce compliance with global regulations like the EU AI Act, NIST AI RMF, GDPR, HIPAA, and CCPA.
By implementing these actions, organizations can improve their systems, reduce risks, and ensure long-term success with AI adoption.
Applications to Leverage Gencore AI with Databricks
As AI adoption accelerates, businesses must ensure that their AI-driven applications are powerful, secure, compliant, and transparent. The partnership between Databricks and Gencore AI enables enterprises to develop AI applications with robust security measures, optimized data pipelines, and comprehensive governance.
Here’s how businesses can leverage this integration for maximum impact.
1. Personalized AI Applications with Built-in Security
While the adoption of AI has led to the emergence of personalized experiences, users do not want it at the cost of their data security. Databricks’ scalable infrastructure and Gencore AI’s entitlement controls enabled enterprises to build AI applications that tailor user experiences while protecting sensitive data. This can ensure:
Recommendation engines in retail and E-commerce can analyze purchase history and browsing behavior to provide hyper-personalized suggestions while ensuring that customer data remains protected
AI-driven diagnostics and treatment recommendations can be fine-tuned for individual patients while maintaining strict compliance with HIPAA and other healthcare regulations
AI-driven wealth management platforms can provide personalized investment strategies while preventing unauthorized access to financial records
Hence, with built-in security controls, businesses can deliver highly personalized AI applications without compromising data privacy or regulatory compliance.
AI models are only as good as the data they process. A well-structured data pipeline ensures that AI applications work with clean, reliable, and regulatory-compliant data. The Databricks + Gencore AI integration simplifies this by automating data preparation, cleaning, and governance.
Automated Data Sanitization: AI-driven models must be trained on high-quality and sanitized data that has no sensitive context. This partnership enables businesses to eliminate data inconsistencies, biases, and sensitive data before model training
Real-time Data Processing: Databricks’ powerful infrastructure ensures that enterprises can ingest, process, and analyze vast amounts of structured and unstructured data at scale
Seamless Integration with Enterprise Systems: Companies can connect disparate unstructured and structured data sources and standardize AI training datasets, improving model accuracy and reliability
Thus, by optimizing data pipelines, businesses can accelerate AI adoption and enhance the overall performance of AI applications.
Configuring and Operationalizing Safe AI Systems in Minutes (API-Based)
3. Comprehensive Visibility and Control for AI Governance
Enterprises deploying AI must maintain end-to-end visibility over their AI systems to ensure transparency, fairness, and accountability. The combination of Databricks’ governance tools and Gencore AI’s security framework empowers organizations to maintain strict oversight of AI workflows with:
AI Model Explainability: Stakeholders can track AI decision-making processes, ensuring that outputs are fair, unbiased, and aligned with ethical standards
Regulatory Compliance Monitoring: Businesses can automate compliance checks, ensuring that AI models adhere to global data and AI regulations such as the EU AI Act, NIST AI RMF, GDPR, CCPA, and HIPAA
Audit Trails & Access Controls: Enterprises gain real-time visibility into who accesses, modifies, or deploys AI models, reducing security risks and unauthorized interventions
Securiti’s Data Command Graph Provides Embedded Deep Visibility and Provenance for AI Systems
Hence, the synergy between Databricks and Gencore AI provides enterprises with a robust foundation for developing, deploying, and governing AI applications at scale. Organizations can confidently harness the power of AI without exposing themselves to compliance, security, or ethical risks, ensuring it’s built on a foundation of trust, transparency, and control.
The Future of Responsible AI Adoption
AI is no longer a competitive edge, but a business imperative. However, without the right security and governance in place, enterprises risk exposing sensitive data, violating compliance regulations, and deploying untrustworthy AI systems.
The partnership between Databricks and Securiti’s Gencore AI provides a blueprint for scalable, secure, and responsible AI adoption. By integrating robust infrastructure with automated compliance controls, businesses can unlock AI’s full potential while ensuring privacy, security, and ethical governance.
Organizations that proactively embed governance into their AI ecosystems will not only mitigate risks but also accelerate innovation with confidence. You can leverage Databricks and Securiti’s Gencore AI solution to build a safe, scalable, and high-performing AI ecosystem that drives business growth.