Qwen models have rapidly become a cornerstone in the open-source large language model (LLM) ecosystem. Developed by Alibaba Cloud, these models have evolved from robust, multilingual LLMs to the latest Qwen 3 series, which sets new standards in reasoning, efficiency, and agentic capabilities. Whether you’re a data scientist, ML engineer, or AI enthusiast, understanding the Qwen models, especially the advancements in Qwen 3, will empower you to build smarter, more scalable AI solutions.
In this guide, we’ll cover the full Qwen model lineage, highlight the technical breakthroughs of Qwen 3, and provide actionable insights for deploying and fine-tuning these models in real-world applications.
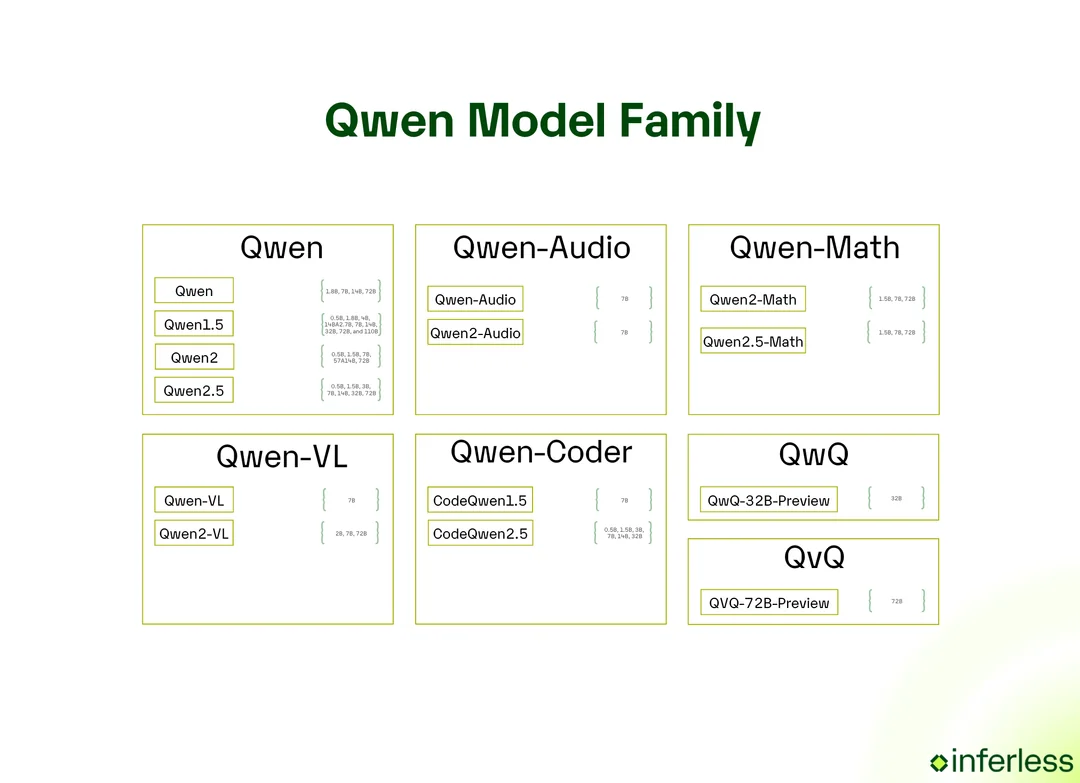
What Are Qwen Models?
Qwen models are a family of open-source large language models developed by Alibaba Cloud. Since their debut, they have expanded into a suite of LLMs covering general-purpose language understanding, code generation, math reasoning, vision-language tasks, and more. Qwen models are known for:
- Transformer-based architecture with advanced attention mechanisms.
- Multilingual support (now up to 119 languages in Qwen 3).
- Open-source licensing (Apache 2.0), making them accessible for research and commercial use.
- Specialized variants for coding (Qwen-Coder), math (Qwen-Math), and multimodal tasks (Qwen-VL).
Why Qwen Models Matter:
They offer a unique blend of performance, flexibility, and openness, making them ideal for both enterprise and research applications. Their rapid evolution has kept them at the cutting edge of LLM development.
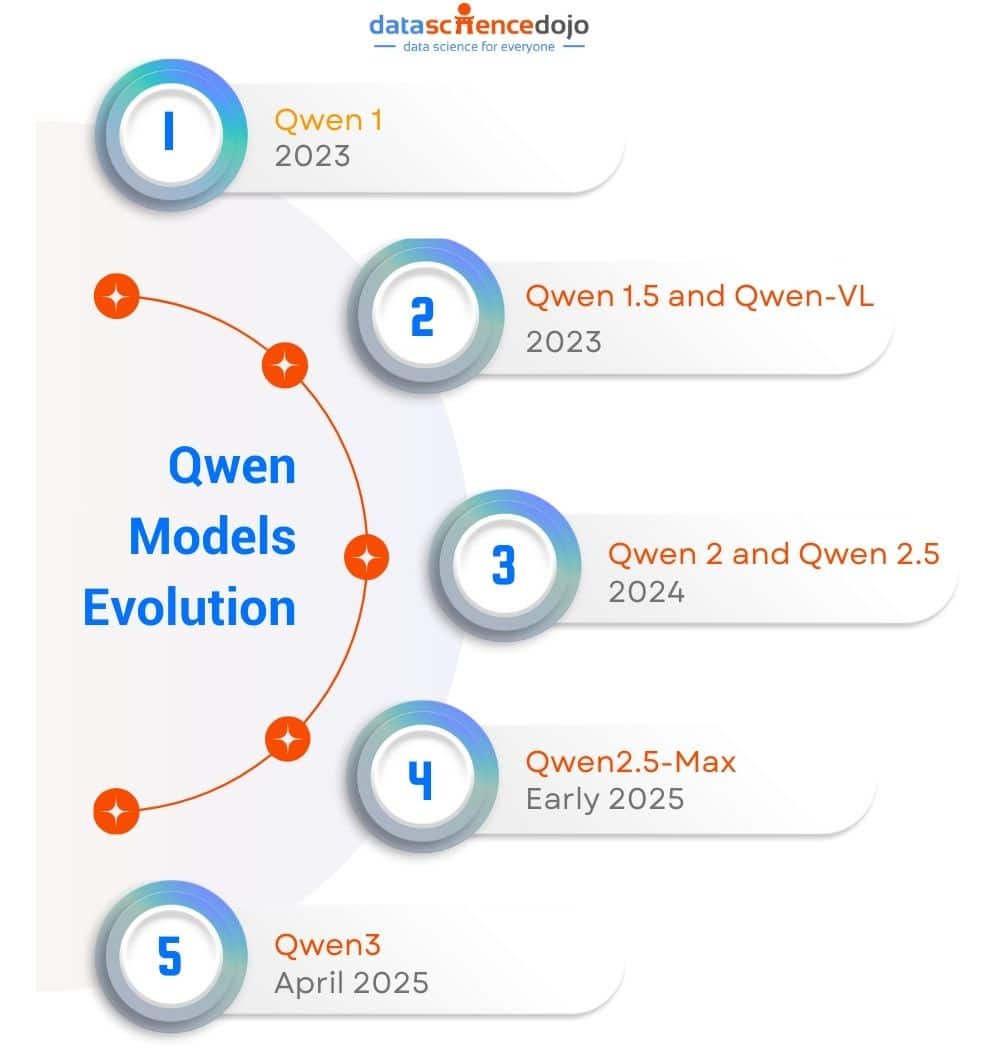
The Evolution of Qwen: From Qwen 1 to Qwen 3
Qwen 1 & Qwen 1.5
- Initial releases focused on robust transformer architectures and multilingual capabilities.
- Context windows up to 32K tokens.
- Strong performance in Chinese and English, with growing support for other languages.
Qwen 2 & Qwen 2.5
- Expanded parameter sizes (up to 110B dense, 72B instruct).
- Improved training data (up to 18 trillion tokens in Qwen 2.5).
- Enhanced alignment via supervised fine-tuning and Direct Preference Optimization (DPO).
- Specialized models for math, coding, and vision-language tasks.
Qwen 3: The Breakthrough Generation
- Released in 2025, Qwen 3 marks a leap in architecture, scale, and reasoning.
- Model lineup includes both dense and Mixture-of-Experts (MoE) variants, from 0.6B to 235B parameters.
- Hybrid reasoning modes (thinking and non-thinking) for adaptive task handling.
- Multilingual fluency across 119 languages and dialects.
- Agentic capabilities for tool use, memory, and autonomous workflows.
- Open-weight models under Apache 2.0, available on Hugging Face and other platforms.
Qwen 3: Architecture, Features, and Advancements
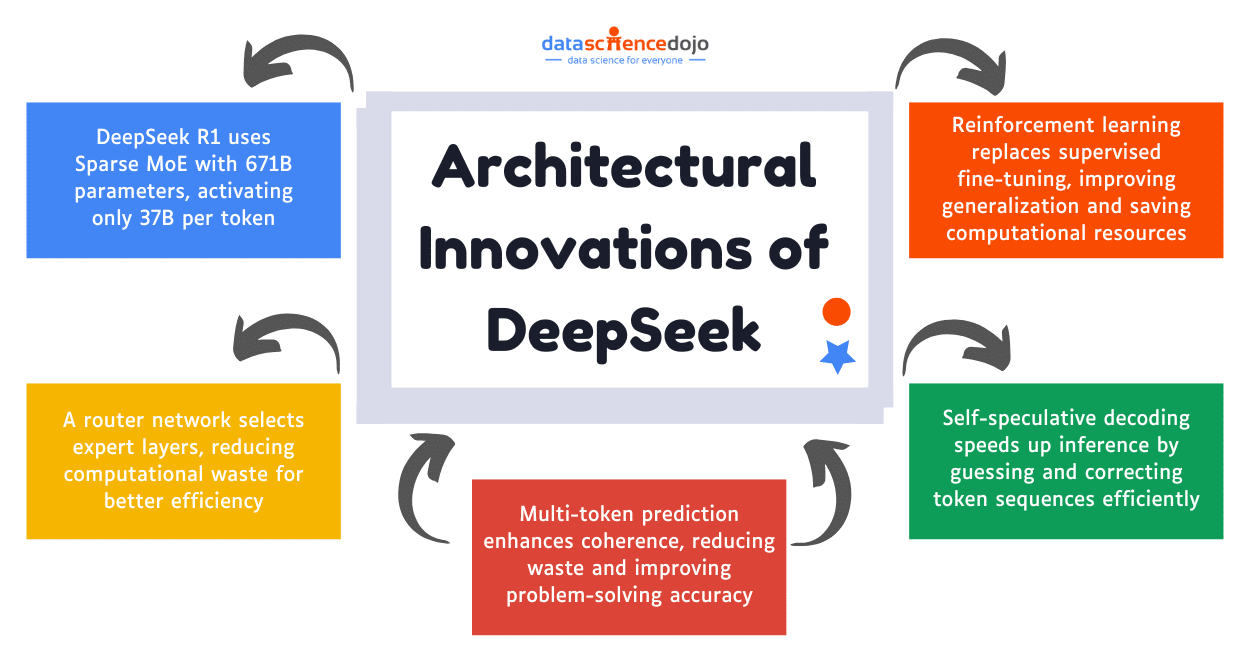
Architectural Innovations
Mixture-of-Experts (MoE):
Qwen 3’s flagship models (e.g., Qwen3-235B-A22B) use MoE architecture, activating only a subset of parameters per input. This enables massive scale (235B total, 22B active) with efficient inference and training.
Deep dive into what makes Mixture of Experts an efficient architecture
Grouped Query Attention (GQA):
Bundles similar queries to reduce redundant computation, boosting throughput and lowering latency, critical for interactive and coding applications.
Global-Batch Load Balancing:
Distributes computational load evenly across experts, ensuring stable, high-throughput training even at massive scale.
Hybrid Reasoning Modes:
Qwen 3 introduces “thinking mode” (for deep, step-by-step reasoning) and “non-thinking mode” (for fast, general-purpose responses). Users can dynamically switch modes via prompt tags or API parameters.
Unified Chat/Reasoner Model:
Unlike previous generations, Qwen 3 merges instruction-following and reasoning into a single model, simplifying deployment and enabling seamless context switching.
Training and Data
- 36 trillion tokens used in pretraining, covering 119 languages and diverse domains.
- Three-stage pretraining: general language, knowledge-intensive data (STEM, code, reasoning), and long-context adaptation.
- Synthetic data generation for math and code using earlier Qwen models.
Post-Training Pipeline
- Four-stage post-training: chain-of-thought (CoT) cold start, reasoning-based RL, thinking mode fusion, and general RL.
- Alignment with human preferences via DAPO and RLHF techniques.
Key Features
- Context window up to 128K tokens (dense) and 256K+ (Qwen3 Coder).
- Dynamic mode switching for task-specific reasoning depth.
- Agentic readiness: tool use, memory, and action planning for autonomous AI agents.
- Multilingual support: 119 languages and dialects.
- Open-source weights and permissive licensing.
Benchmark and compare LLMs effectively using proven evaluation frameworks and metrics.
Comparing Qwen 3 to Previous Qwen Models
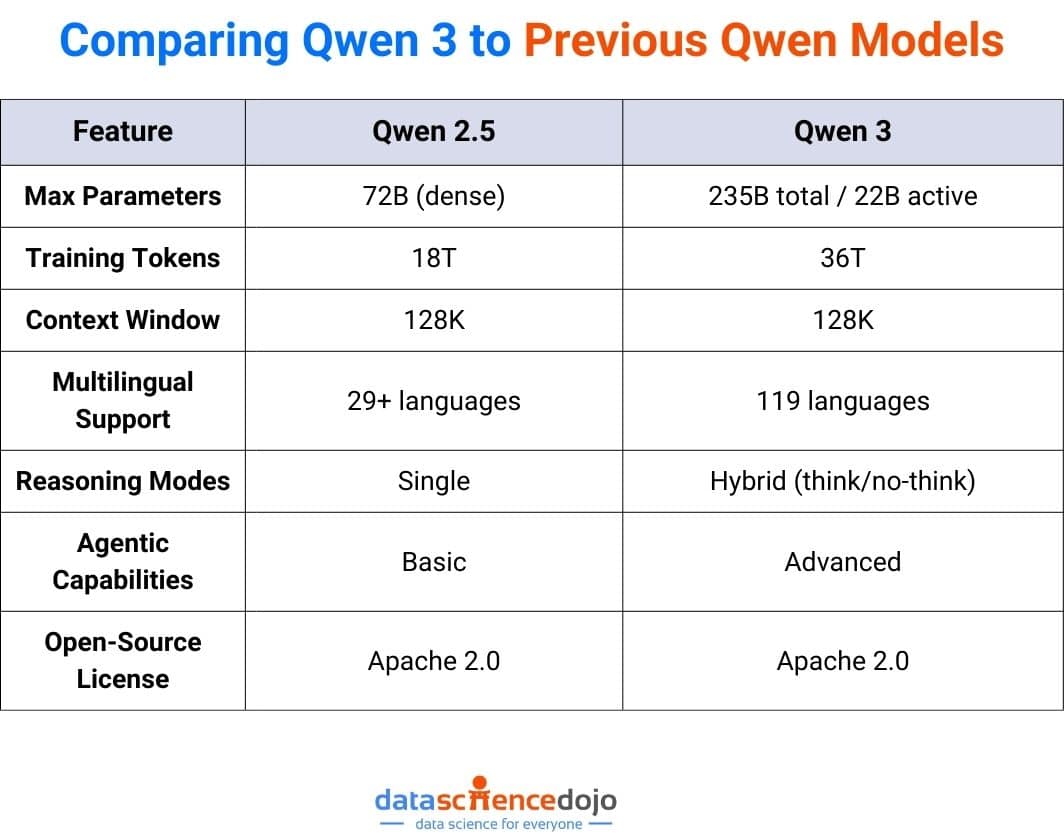
Key Takeaways:
- Qwen 3’s dense models match or exceed Qwen 2.5’s larger models in performance, thanks to architectural and data improvements.
- MoE models deliver flagship performance with lower active parameter counts, reducing inference costs.
- Hybrid reasoning and agentic features make Qwen 3 uniquely suited for next-gen AI applications.
Benchmarks and Real-World Performance
Qwen 3 models set new standards in open-source LLM benchmarks:
- Coding: Qwen3-32B matches GPT-4o in code generation and completion.
- Math: Qwen3 integrates Chain-of-Thought and Tool-Integrated Reasoning for multi-step problem solving.
- Multilingual: Outperforms previous Qwen models and rivals top open-source LLMs in translation and cross-lingual tasks.
- Agentic: Qwen 3 is optimized for tool use, memory, and multi-step workflows, making it ideal for building autonomous AI agents.
Deployment, Fine-Tuning, and Ecosystem
Deployment Options
- Cloud: Alibaba Cloud Model Studio, Hugging Face, ModelScope, Kaggle.
- Local: Ollama, LMStudio, llama.cpp, KTransformers.
- Inference Frameworks: vLLM, SGLang, TensorRT-LLM.
- API Integration: OpenAI-compatible endpoints, CLI tools, IDE plugins.
Fine-Tuning and Customization
- LoRA/QLoRA for efficient domain adaptation.
- Agentic RL for tool use and multi-step workflows.
- Quantized models for edge and resource-constrained environments.
Master the art of customizing LLMs for specialized tasks with actionable fine-tuning techniques.
Ecosystem and Community
- Active open-source community on GitHub and Discord.
- Extensive documentation and deployment guides.
- Integration with agentic AI frameworks (see Open Source Tools for Agentic AI).
Industry Use Cases and Applications
Qwen models are powering innovation across industries:
-
Software Engineering:
Code generation, review, and documentation (Qwen3 Coder).
-
Data Science:
Automated analysis, report generation, and workflow orchestration.
-
Customer Support:
Multilingual chatbots and virtual assistants.
-
Healthcare:
Medical document analysis and decision support.
-
Finance:
Automated reporting, risk analysis, and compliance.
-
Education:
Math tutoring, personalized learning, and research assistance.
Explore more use cases in AI Use Cases in Industry.
FAQs About Qwen Models
Q1: What makes Qwen 3 different from previous Qwen models?
A: Qwen 3 introduces Mixture-of-Experts architecture, hybrid reasoning modes, expanded multilingual support, and advanced agentic capabilities, setting new benchmarks in open-source LLM performance.
Q2: Can I deploy Qwen 3 models locally?
A: Yes. Smaller variants can run on high-end workstations, and quantized models are available for edge devices. See Qwen3 Coder: The Open-Source AI Coding Model Redefining Code Generation for deployment details.
Q3: How does Qwen 3 compare to Llama 3, DeepSeek, or GPT-4o?
A: Qwen 3 matches or exceeds these models in coding, reasoning, and multilingual tasks, with the added benefit of open-source weights and a full suite of model sizes.
Q4: What are the best resources to learn more about Qwen models?
A: Start with A Guide to Large Language Models and Open Source Tools for Agentic AI.
Conclusion & Next Steps
Qwen models have redefined what’s possible in open-source large language models. With Qwen 3, Alibaba has delivered a suite of models that combine scale, efficiency, reasoning, and agentic capabilities, making them a top choice for developers, researchers, and enterprises alike.
Ready to get started?
- Explore Qwen 3 models on Hugging Face
- Read Qwen3 Coder: The Open-Source AI Coding Model Redefining Code Generation
- Join the Data Science Dojo LLM Bootcamp for hands-on training in building and deploying custom LLM applications
Stay ahead in AI, experiment with Qwen models and join the open-source revolution!