

Imagine tackling a mountain of laundry. You wouldn’t throw everything in one washing machine, right? You’d sort the delicates, towels, and jeans, sending each to its specialized cycle. The human brain does something similar when solving complex problems. We leverage our diverse skills, drawing on specific knowledge depending on the task at hand.

This blog will be your guide on this journey into the realm of MoE. We’ll dissect its core components, unveil its advantages and applications, and explore the challenges and future of this revolutionary technology.
What is the Mixture of Experts?
The Mixture of Experts (MoE) is a sophisticated machine learning technique that leverages the divide-and-conquer principle to enhance performance. It involves partitioning the problem space into subspaces, each managed by a specialized neural network expert.
Explore 5 Main Types of Neural Networks and their Applications
A gating network oversees this process, dynamically assigning input data to the most suitable expert based on their local efficiency. This method is particularly effective because it allows for the specialization of experts in different regions of the input space, leading to improved accuracy and reliability in complex classification tasks.
The MoE approach is distinct in its use of a gating network to compute combinational weights dynamically, which contrasts with static methods that assign fixed weights to experts.
Importance of MOE
So, why is MoE important? This innovative model unlocks unprecedented potential in the world of AI. Forget brute-force calculations and mountains of parameters. MoE empowers us to build powerful models that are smarter, leaner, and more efficient.
It’s like having a team of expert consultants working behind the scenes, ensuring accurate predictions and insightful decisions, all while conserving precious computational resources.
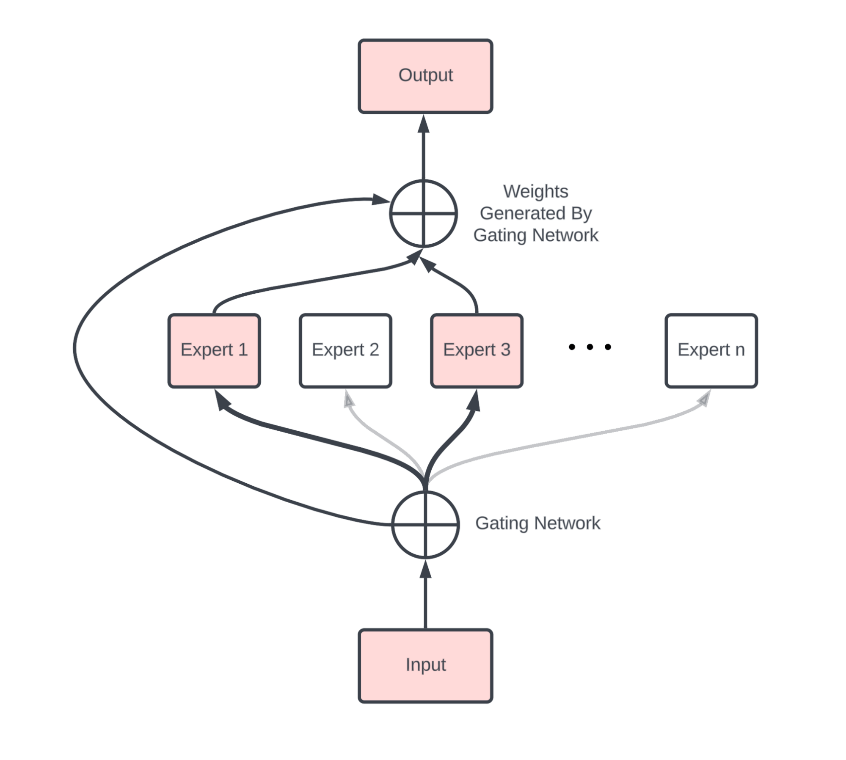
The core of MoE
The Mixture of Experts (MoE) model revolutionizes AI by dynamically selecting specialized expert models for specific tasks, enhancing accuracy and efficiency. This approach allows MoE to excel in diverse applications, from language understanding to personalized user experiences.
Meet the Experts
Imagine a bustling marketplace where each stall houses a master in their craft. In MoE, these stalls are the expert networks, each a miniature neural network trained to handle a specific subtask within the larger problem. These experts could be, for example:
Factual experts specializing in retrieving and interpreting vast amounts of data.
Visual experts are trained to recognize patterns and objects in images or videos.
The individual experts are relatively simple compared to the overall model, making them more efficient and flexible in adapting to different data distributions. This specialization also allows MoE to handle complex tasks that would overwhelm a single, monolithic network.
The Gatekeeper: Choosing the Right Expert
But how does MoE know which expert to call upon for a particular input? That’s where the gating function comes in. Imagine it as a wise oracle stationed at the entrance of the marketplace, observing each input and directing it to the most relevant expert stall.
This gating mechanism is crucial for the magic of MoE. It dynamically assigns tasks to the appropriate experts, avoiding the computational overhead of running all experts on every input. This sparse activation, where only a few experts are active at any given time, is the key to MoE’s efficiency and scalability.

Traditional Ensemble Approach vs MoE
MoE is not alone in the realm of ensemble learning. Techniques like bagging, boosting, and stacking have long dominated the scene. But how does MoE compare? Let’s explore its unique strengths and weaknesses in contrast to these established approaches
Bagging
Both MoE and bagging leverage multiple models, but their strategies differ. Bagging trains independent models on different subsets of data and then aggregates their predictions by voting or averaging.
Understand Big Data Ethics
MoE, on the other hand, utilizes specialized experts within a single architecture, dynamically choosing one for each input. This specialization can lead to higher accuracy and efficiency for complex tasks, especially when data distributions are diverse.
Boosting
While both techniques learn from mistakes, boosting focuses on sequentially building models that correct the errors of their predecessors. MoE, with its parallel experts, avoids sequential dependency, potentially speeding up training.

However, boosting can be more effective for specific tasks by explicitly focusing on challenging examples.
Stacking
Both approaches combine multiple models, but stacking uses a meta-learner to further refine the predictions of the base models. MoE doesn’t require a separate meta-learner, making it simpler and potentially faster.
Understand how to build a Predictive Model of your house with Azure machine learning
However, stacking can offer greater flexibility in combining predictions, potentially leading to higher accuracy in certain situations.
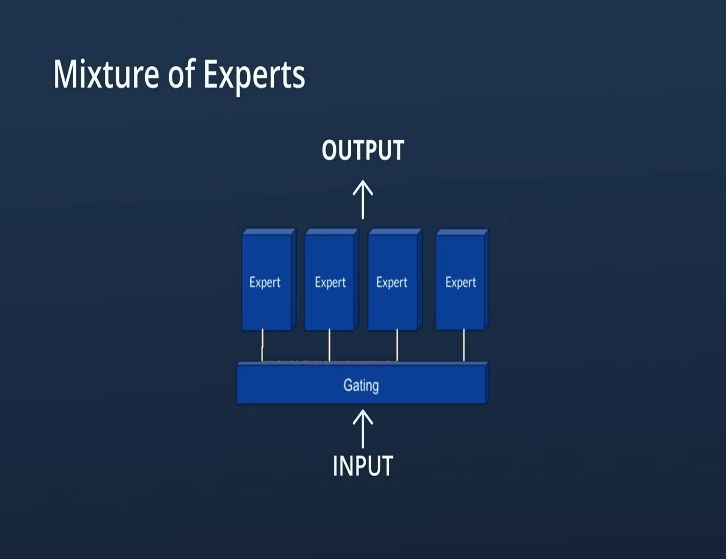
Benefits of a Mixture of Experts

Boosted Model Capacity without Parameter Explosion
The biggest challenge traditional neural networks face is complexity. Increasing their capacity often means piling on parameters, leading to computational nightmares and training difficulties.
Explore the Applications of Neural Networks in 7 Different Industries
MoE bypasses this by distributing the workload amongst specialized experts, increasing model capacity without the parameter bloat. This allows us to tackle more complex problems without sacrificing efficiency.
Efficiency
MoE’s sparse activation is a game-changer in terms of efficiency. With only a handful of experts active per input, the model consumes significantly less computational power and memory compared to traditional approaches.
This translates to faster training times, lower hardware requirements, and ultimately, cost savings. It’s like having a team of skilled workers doing their job efficiently, while the rest take a well-deserved coffee break.

Tackling Complex Tasks
By dividing and conquering, MoE allows experts to focus on specific aspects of a problem, leading to more accurate and nuanced predictions. Imagine trying to understand a foreign language – a linguist expert can decipher grammar, while a factual expert provides cultural context.
This collaboration leads to a deeper understanding than either expert could achieve alone. Similarly, MoE’s specialized experts tackle complex tasks with greater precision and robustness.
Adaptability
The world is messy, and data rarely comes in neat, homogenous packages. MoE excels at handling diverse data distributions. Different experts can be trained on specific data subsets, making the overall model adaptable to various scenarios.
Think of it like having a team of multilingual translators – each expert seamlessly handles their assigned language, ensuring accurate communication across diverse data landscapes.
Know more about the 5 useful AI Translation Tools to diversify your business
Applications of MoE
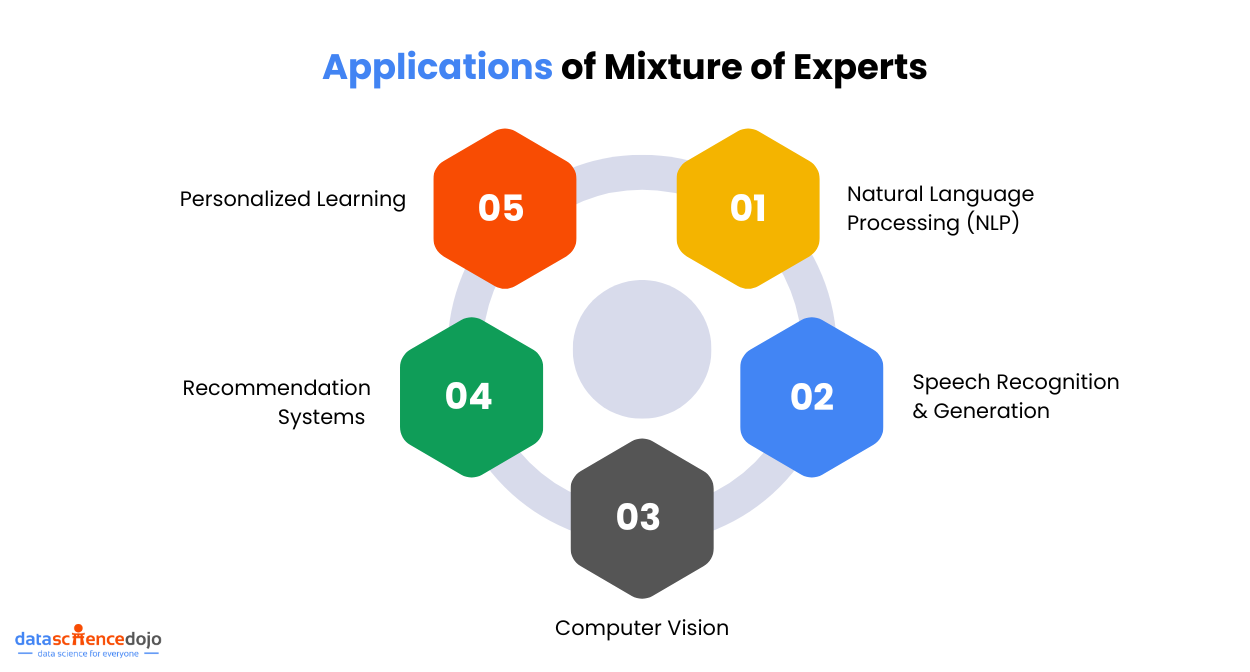
Now that we understand what Mixture of Experts are and how they work. Let’s explore some common applications of the Mixture of Experts models.
Natural Language Processing (NLP)
In the realm of Natural Language Processing, the Mixture of Experts (MoE) model shines by addressing the intricate layers of human language.
Explore Natural Language Processing and its Applications
MoE’s experts are adept at handling the subtleties of language, including nuances, humor, and cultural references, which are crucial for delivering translations that are not only accurate but also fluid and engaging.
Learn Top 6 Programming Languages to kickstart your career in tech
This capability extends to text summarization, where MoE condenses lengthy and complex articles into concise, informative summaries that capture the essence of the original content.
Furthermore, dialogue systems powered by MoE transcend traditional robotic responses, engaging users with witty banter and insightful conversations, making interactions more human-like and enjoyable.
Computer Vision
In the field of Computer Vision, MoE demonstrates its prowess by training experts on specific objects, such as birds in flight or ancient ruins, enabling them to identify these objects in images with remarkable precision.
This specialization allows for enhanced accuracy in object recognition tasks. MoE also plays a pivotal role in video understanding, where it analyzes sports highlights, deciphers news reports, and even tracks emotions in film scenes.
Overcome Challenges and Improving Efficiency in Video Production
By doing so, MoE enhances the ability to interpret and understand visual content, making it a valuable tool for applications ranging from security surveillance to entertainment.
Speech Recognition & Generation
MoE excels in Speech Recognition and Generation by untangling the complexities of accents, background noise, and technical jargon. This capability ensures that speech recognition systems can accurately transcribe spoken language in diverse environments.
On the generation side, AI voices powered by MoE bring a human touch to speech synthesis. They can read bedtime stories with warmth and narrate audiobooks with the cadence and expressiveness of a seasoned storyteller, enhancing the listener’s experience and engagement.
Explore easily build AI-based Chatbots in Python
MoE’s experts can handle nuances, humor, and cultural references, delivering translations that sing and flow. Text summarization takes flight, condensing complex articles into concise gems, and dialogue systems evolve beyond robotic responses, engaging in witty banter and insightful conversations.
Recommendation Systems
In the world of Recommendation Systems, the Mixture of Experts (MoE) model plays a crucial role in delivering highly personalized experiences. By analyzing user behavior, preferences, and historical data, MoE experts can craft product suggestions that align closely with individual tastes.
Build a Recommendation System using Python
This approach enhances user engagement and satisfaction, as recommendations feel more relevant and timely. For instance, in e-commerce, MoE can suggest products that a user is likely to purchase based on their browsing history and previous purchases, thereby increasing conversion rates.
Similarly, in streaming services, MoE can recommend movies or music that match a user’s unique preferences, creating a more enjoyable and tailored viewing or listening experience.
Personalized Learning
In the realm of Personalized Learning, MoE offers a transformative approach to education by developing adaptive learning plans that cater to the unique needs of each learner. MoE experts assess a student’s learning style, pace, and areas of interest to create customized educational content.
This personalization ensures that learners receive the right level of challenge and support, enhancing their engagement and retention of information. For example, in online education platforms, MoE can adjust the difficulty of exercises based on a student’s performance, providing additional resources or challenges as needed.
This tailored approach not only improves learning outcomes but also fosters a more motivating and supportive learning environment.
Challenges and Limitations of MoE
Now that we have looked at the benefits and applications of the MoE. Let’s explore some major limitations of the MoE.
Training Complexity
Finding the right balance between experts and gating is a major challenge in training an MoE model. too few, and the model lacks capacity; too many, and training complexity spikes. Finding the optimal number of experts and calibrating their interaction with the gating function is a delicate balancing act.
Explainability and Interpretability
Unlike monolithic models, the internal workings of MoE can be opaque, making it challenging to determine which expert handles a specific input and why. This complexity can hinder interpretability and complicate debugging efforts.
Hardware Limitations
While MoE shines in efficiency, scaling it to massive datasets and complex tasks can be hardware-intensive. Optimizing for specific architectures and leveraging specialized hardware, like TPUs, are crucial for tackling these scalability challenges.
MoE, Shaping the Future of AI
This concludes our exploration of the Mixture of Experts. We hope you’ve gained valuable insights into this revolutionary technology and its potential to shape the future of AI. Remember, the journey doesn’t end here.
Learn how AI is helping Webmaster and content creators progress
Stay curious, keep exploring, and join the conversation as we chart the course for a future powered by the collective intelligence of humans and machines.