With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. This blog delves into a detailed comparison between the two data management techniques.
In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Hence, databases are important for strategic data handling and enhanced operational efficiency.
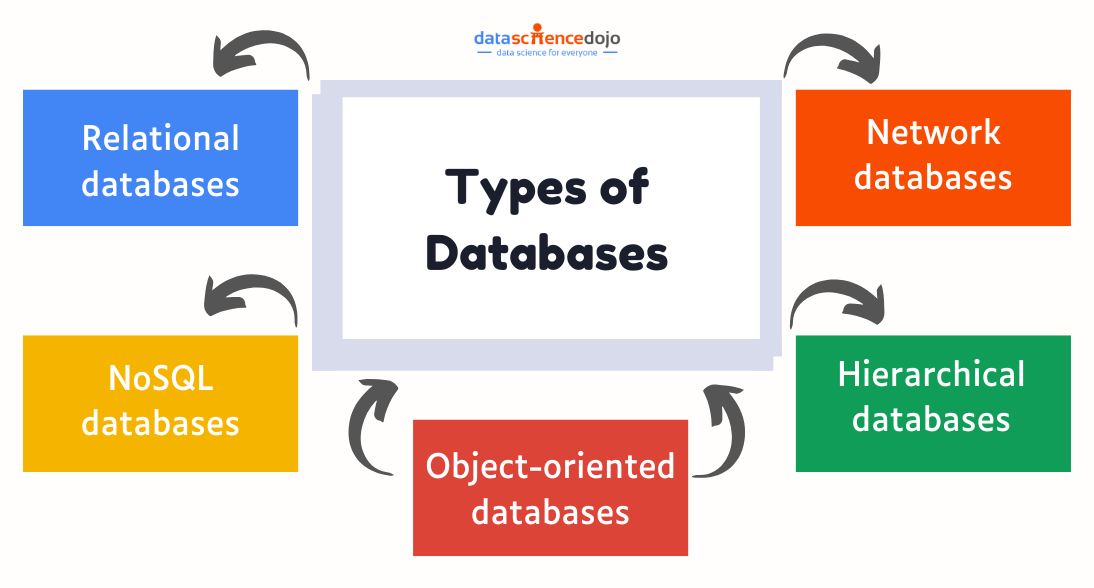
However, before we dig deeper into the types of databases, let’s understand them better.
Understanding Databases
Databases are a structured way to store and organize data effectively. It involves multiple data handling processes, like updating, deleting, or changing information. These are important for efficient data organization, security, and control.
Rules are put in place by databases to ensure data integrity and minimize redundancy. Moreover, organized storage of data facilitates data analysis, enabling retrieval of useful insights and data patterns. It also facilitates integration with different applications to enhance their functionality with organized access to data.
In data science, databases are important for data preprocessing, cleaning, and integration. Data scientists often rely on databases to perform complex queries and visualize data. Moreover, databases allow the storage of training datasets, facilitating model training and validation.
Read more about Understanding Databases
While databases are vital to data management, they have also developed over time. The changing technological world has led to a transition in available databases. Hence, the digital arena has gradually shifted from traditional to vector databases.
Since the shift is still underway, you can access both kinds of databases. However, it is important to understand the uses, limitations, and functions of both databases to understand which is more suitable for your organization. Let’s explore the arguments around the debate of traditional vs vector databases.

Exploring the Traditional vs Vector Databases Debate
In comparing the two categories of databases, we must explore a common set of factors to understand the basic differences between them. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process.

Data Models
Traditional Databases:
They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. While each column represents a particular field, each row represents a single record within that field. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
This relational data model holds a rigid schema, defining the structure of the data upfront. While it ensures high data integrity, it also makes the model inflexible in handling diverse and evolving data types.
Vector Databases:
Instead of a relational row and column structure, vector databases use a vector-based model consisting of a multidimensional array of numbers. Each data point is stored as a vector in a three-dimensional space, representing different features and properties of data.
Unlike a traditional database, the vector representation is well-suited to store unstructured data. It also allows easier handling of complex data points, making it a versatile data model. Its flexible schema allows better adaptability but at the cost of data integrity.
Suggestion:
Based on the data models of both databases, it can be said that when making a choice, you must find the right balance between maintaining data integrity and flexible data-handling capabilities. Understanding your database requirements between these two properties will help you towards an accurate option.
Here’s your guide to top vector databases in the market
Query Language
Traditional Databases:
They rely on Structured Query Language (SQL), designed to navigate through relational databases. It provides a standardized way to interact with data, allowing data manipulation in the form of updating, inserting, deleting, and more.
It presents a highly focused method of addressing queries where data is filtered using exact matches, comparisons, and logical operators. SQL querying has long been present in the industry, hence it comes with a rich ecosystem of support.
Here’s a list of 12 SQL concepts for data scientists
Vector Databases:
Unlike a declarative language like SQL, vector databases execute querying through API calls. These can vary based on the vector database you use. The APIs perform similarity searches and nearest-neighbor operations as part of the querying process.
The process is based on retrieving similar data points to a query from the multidimensional vector space. It leverages indexing and search techniques that are suitable for complex vector databases.
Suggestion:
Hence, query language specifications are highly particular to your choice of a database. You would have to rely on either SQL for traditional databases or work with API calls if you are dealing with vector spaces for data storage.

Indexing Techniques
Traditional Databases:
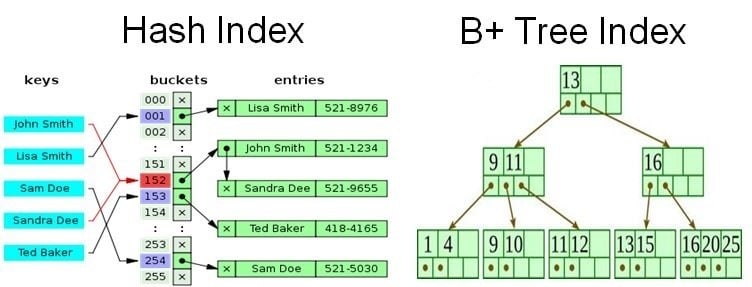
Indexing techniques for traditional databases include B-trees and hash indexes that are designed for structured data. B-trees is the most common method that organizes data in a hierarchical tree format. It assists in the efficient sorting and retrieval of data.
Hash indexes rely on hash functions to map data to particular locations in an index. On accessing this location, you can retrieve the actual data stored there. They are integral for point queries where exact matches are known.
Vector Databases:
HNSW and IVF are indexing methods that specialize in handling vector databases. These differentiated techniques optimize similarity searches in high-dimensional vector data.
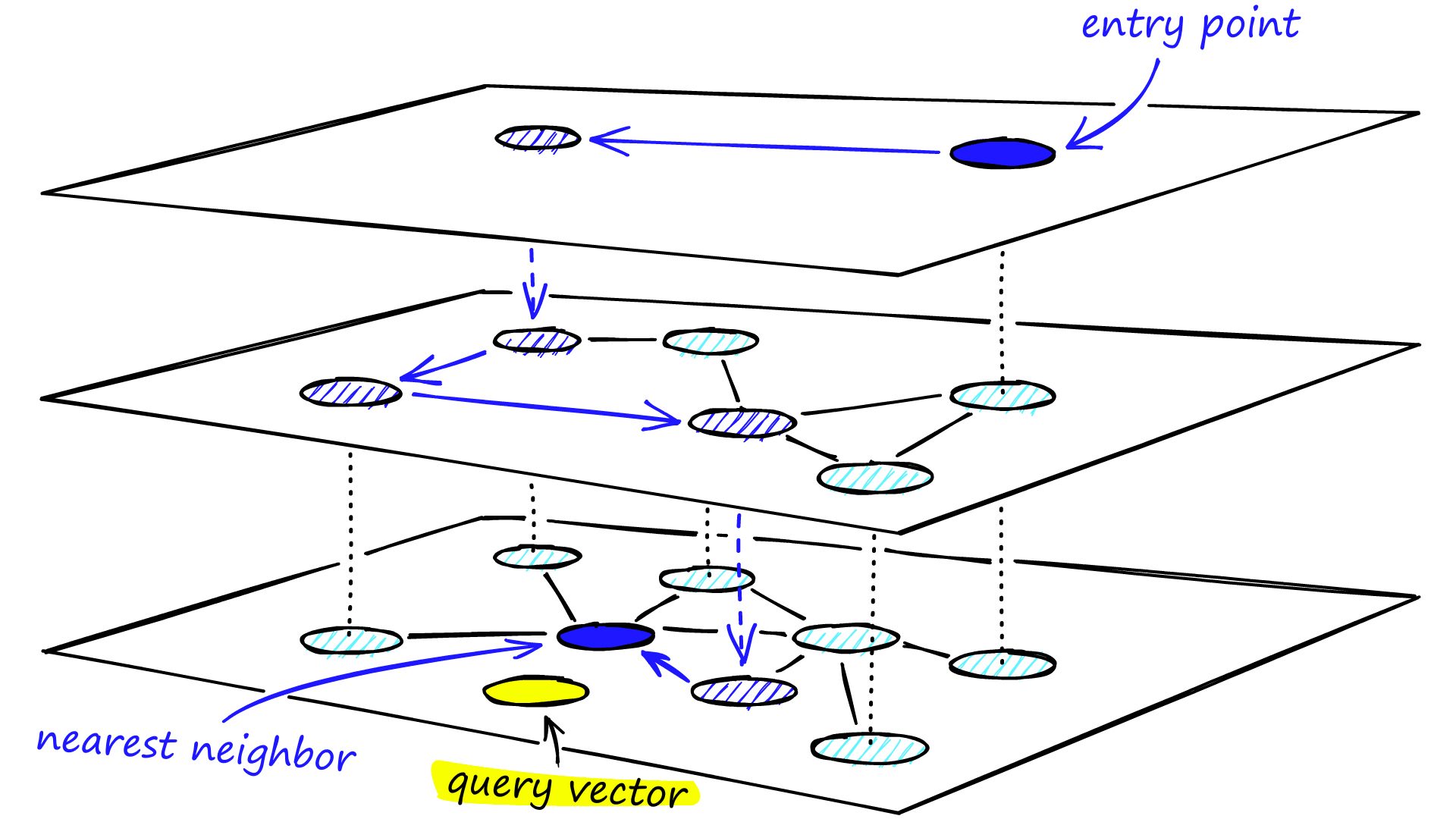
HNSW stands for Hierarchical Navigable Small World which facilitates rapid proximity searches. It creates a multi-layer navigation graph to represent the vector space, creating a network of shortcuts to narrow down the search space to a small subset of similar vectors.
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters.
Both methods aim to enhance the similarity search in vector databases. While HNSW speeds up the process, IVF also increases its efficiency.
Suggestion:
While traditional indexing techniques optimize precise queries and efficient data manipulation in structured data, vector database methods are designed for similarity searches within high-dimensional data, handling complex queries such as nearest neighbor searches in machine learning applications.
Learn more about the mystery of indexing
Performance and Scalability
Traditional Databases:
These databases manage transactional workloads with a focus on data integrity (ACID compliance) and support complex querying capabilities. However, their performance is limited due to their design of vertical scalability, making it a costly and hardware-dependent process to handle large data volumes.
Vector Databases:
Vector databases provide distinct performance advantages in environments requiring quick insights from large volumes of complex data, enabling efficient search operations. Moreover, its horizontal scalability design promotes the distribution of data management across multiple machines, making it a cost-effective process.
Suggestion:
Performance-based decisions can be made by finding the right balance between data integrity and flexible data handling, similar to the consideration of their data model differences. However, the horizontal and vertical scalability highlights that vector databases are more cost-efficient for large data volumes.

Use Cases
Traditional Databases:
They are ideal for applications that rely on structured data and require transactional safety while managing data records and performing complex queries. Some common use cases include financial systems, E-commerce platforms, customer relationship management (CRM), and human resource (HR) systems.
Vector Databases:
They are useful for complex and multimodal datasets, often associated with complex machine learning (ML) tasks. Some important use cases include natural language processing (NLP), fraud detection, recommendation systems, and real-time personalization.
Understand tasks and techniques of natural language processing
Suggestion:
The differences in use cases highlight the varied strengths of both databases. You cannot undermine one over the other but understand both databases better to make the right choice for your data. Traditional databases remain the backbone for structured data while vector databases are better adapted for modern datasets.
The Final Verdict
Traditional databases are suitable for small or medium-sized datasets where retrieval of specific data is required from well-defined links of information. Vector databases, on the other hand, are better for large unstructured datasets with a focus on similarity searches.
Hence, the clash of databases can be seen as a tradition meeting innovation. Traditional databases excel in structured realms, while vector databases revolutionize with speed in high-dimensional data. The final verdict of making the right choice hinges on your specific use cases.