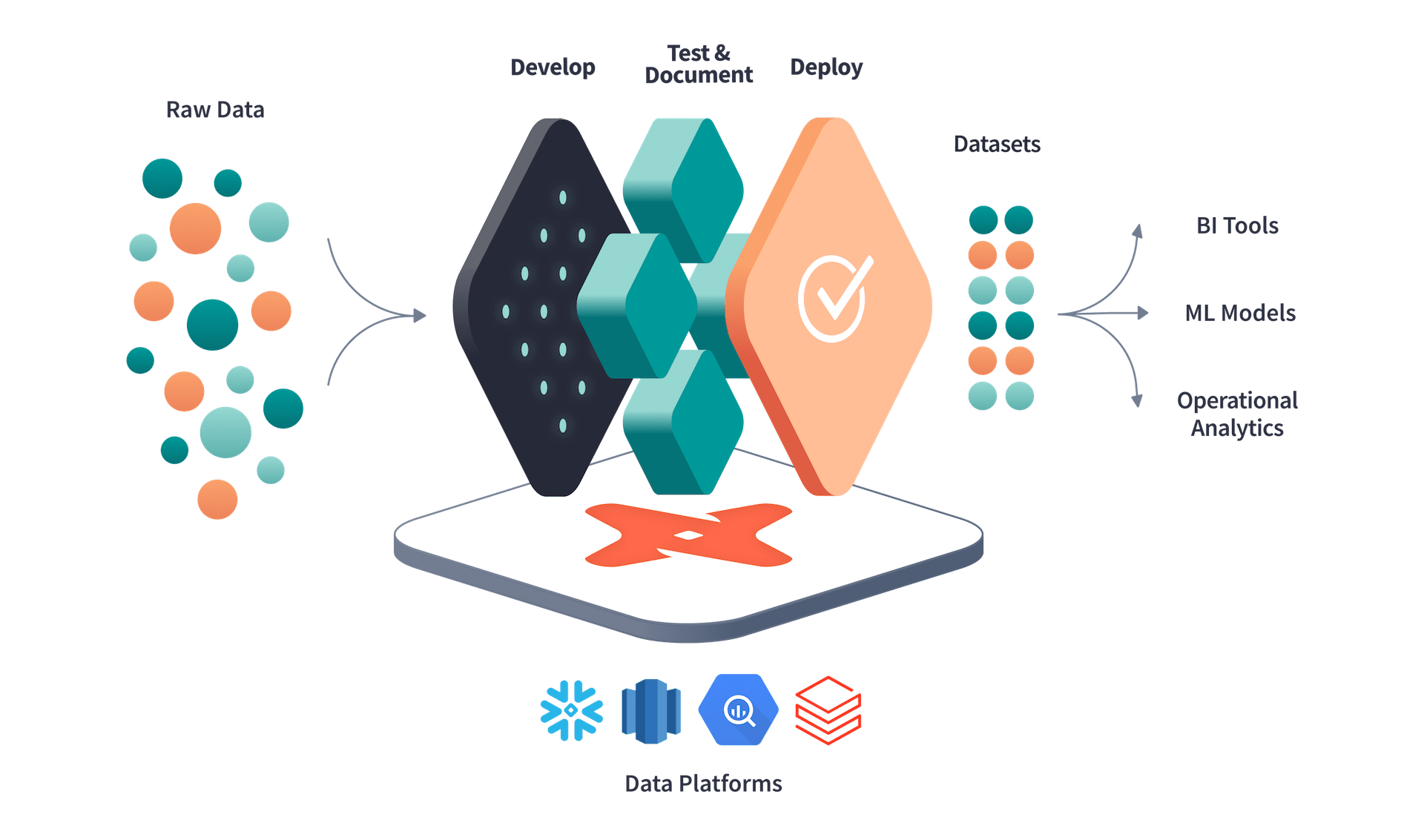
Data engineering tools are specialized software applications or frameworks designed to simplify and optimize the process of managing, processing, and transforming large volumes of data. These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build scalable data pipelines, and prepare data for further analysis and consumption by other applications.
By offering a wide range of features, such as data integration, transformation, and quality management, data engineering tools help ensure that data is structured, reliable, and ready for decision-making.
Data engineering tools also enable workflow orchestration, automate tasks, and provide data visualization capabilities, making it easier for teams to manage complex data processes. In today’s data-driven world, these tools are essential for building efficient, effective data pipelines that support business intelligence, analytics, and overall data strategy.
Top 10 data engineering tools
1. Snowflake
Snowflake is a cloud-based data warehouse platform that offers scalability, performance, and ease of use. Its architecture separates storage and compute, allowing for flexible scaling. It supports various data types and features advanced capabilities like multi-cluster warehouses and data sharing, making it ideal for large-scale data analysis. Snowflake’s ability to support structured and semi-structured data (like JSON) makes it versatile for various business use cases.
In addition, Snowflake provides a secure and collaborative environment with features like real-time data sharing and automatic scaling. Its native support for data sharing across organizations allows users to securely share data between departments or with external partners. Snowflake’s fully managed service eliminates the need for infrastructure management, allowing organizations to focus more on data analysis.
2. Amazon Redshift
Amazon Redshift is a powerful cloud data warehouse service known for its high performance and cost-effectiveness. It uses massively parallel processing (MPP) for fast query execution and integrates seamlessly with AWS services. Redshift supports various data workflows, enabling efficient data analysis. Its architecture is designed to scale for petabytes of data, ensuring optimal performance even with large datasets.
Amazon Redshift also offers robust security features, such as encryption at rest and in transit, to ensure the protection of sensitive data. Additionally, its integration with other AWS tools like S3 and Lambda makes it easier for data engineers to create end-to-end data processing pipelines. Redshift’s advanced compression capabilities also help reduce storage costs while enhancing data retrieval speed.
3. Google BigQuery
Google BigQuery is a serverless cloud-based data warehouse designed for big data analytics. It offers scalable storage and compute capabilities with fast query performance. BigQuery integrates with Google Cloud services, making it an excellent choice for data engineers working on large datasets and advanced analytics. It supports a fully managed environment, reducing the need for manual infrastructure management.
One of BigQuery’s key strengths is its ability to run SQL-like queries on vast amounts of data quickly. Additionally, it offers a feature called BigQuery ML, which allows users to build and train machine learning models directly in the platform without needing to export data. This integration of machine learning capabilities makes BigQuery a powerful tool for both data storage and predictive analytics.
4. Apache Hadoop
Apache Hadoop is an open-source framework for distributed storage and processing of large datasets. With its Hadoop Distributed File System (HDFS) and MapReduce, it enables fault-tolerant and scalable data processing. Hadoop is ideal for batch processing and handling large, unstructured data. It is widely used for processing log files, social media feeds, and large data dumps.
Beyond HDFS and MapReduce, Hadoop has a rich ecosystem that includes tools like Hive for querying large datasets and Pig for data transformation. It also integrates with Apache HBase, a NoSQL database for real-time data storage, enhancing its capabilities for large-scale data applications. Hadoop is a go-to solution for enterprises dealing with vast amounts of unstructured data from a variety of sources.
5. Apache Spark
Apache Spark is a high-speed, open-source analytics engine for big data processing. It provides in-memory processing and supports multiple programming languages like Python, Java, and Scala. Spark handles both batch and real-time data efficiently, with built-in libraries for machine learning and graph processing. Spark’s ability to process data in memory leads to faster performance compared to traditional disk-based processing engines like Hadoop.
Spark also integrates well with other big data technologies, such as Hadoop, and can run on multiple platforms, from standalone clusters to cloud environments. Its unified framework means that users can execute SQL queries, run machine learning algorithms, and perform data analytics all within the same environment, making it an essential tool for modern data engineering workflows.
6. Airflow
Apache Airflow is an open-source platform for orchestrating and managing data workflows. Using Directed Acyclic Graphs (DAGs), Airflow enables scheduling and dependency management of data tasks. It integrates with other tools, providing flexibility to automate complex data pipelines. Airflow also supports real-time monitoring and logging, which helps data engineers track the status and health of workflows.
Airflow’s extensibility is another significant advantage, as it allows users to create custom operators, hooks, and sensors to interact with different data sources or services. It has a strong community and ecosystem, which continuously contributes to its development and improvement. With its ability to automate and manage workflows across multiple systems, Airflow has become a key tool in modern data engineering environments.
7. dbt (Data Build Tool)
dbt is an open-source tool for transforming raw data into structured, analytics-ready datasets. It allows for SQL-based transformations, dependency management, and automated testing. dbt is crucial for maintaining data quality and building efficient data pipelines. With dbt, data engineers can write modular SQL queries, ensuring a clear and maintainable transformation process.
Another standout feature of dbt is its version control capabilities. It integrates seamlessly with Git, allowing teams to collaborate on data models and track changes over time. This ensures that the data transformation process is transparent, reliable, and reproducible. Additionally, dbt’s testing framework helps data engineers detect issues early, improving the quality and integrity of data pipelines.
8. Fivetran
Fivetran is a cloud-based data integration platform that automates the ETL process. It offers pre-built connectors for various data sources, simplifying the process of loading data into data warehouses. Fivetran ensures up-to-date and reliable data with minimal setup. It also handles schema changes automatically, allowing data engineers to focus on higher-level tasks without worrying about manual updates.
Fivetran’s fully managed service means that users don’t need to deal with the complexity of building and maintaining their own ETL infrastructure. It integrates with major data warehouses like Snowflake and Redshift, ensuring seamless data movement between systems. This ease of integration and automation makes Fivetran a highly efficient tool for modern data engineering workflows.
9. Looker
Looker is a business intelligence platform that allows data engineers to create interactive dashboards and reports. It features a flexible modeling layer for defining relationships and metrics, promoting collaboration. Looker integrates with various data platforms, providing a powerful tool for data exploration and visualization. It enables real-time analysis of data stored in different data warehouses, making it a valuable tool for decision-making.
Additionally, Looker’s semantic modeling layer helps ensure that everyone in the organization uses consistent definitions for metrics and KPIs. This reduces confusion and promotes data-driven decision-making across teams. With its scalable architecture, Looker can handle growing datasets, making it a long-term solution for business intelligence needs.
10. Tableau
Tableau is a popular business intelligence and data visualization tool. It allows users to create interactive, visually engaging dashboards and reports. With its drag-and-drop interface, Tableau makes it easy to explore and analyze data, making it an essential tool for data visualization. It connects to various data sources, including data warehouses, spreadsheets, and cloud services.
Tableau’s advanced analytics capabilities, such as trend analysis, forecasting, and predictive modeling, make it more than just a visualization tool. It also supports real-time data updates, ensuring that reports and dashboards always reflect the latest information. With its powerful sharing and collaboration features, Tableau allows teams to make data-driven decisions quickly and effectively.
Benefits of Data Engineering Tools
Efficient Data Management Easily extract, consolidate, and store large volumes of data while enhancing data quality, consistency, and accessibility.
Streamlined Data Transformation Automate the process of converting raw data into structured, usable formats, applying business logic at scale.
Workflow Orchestration Schedule, monitor, and manage data pipelines to ensure seamless and automated data workflows.
Scalability and Performance Efficiently process growing data volumes with high-speed performance and resource optimization.
Seamless Data Integration Connect diverse data sources—cloud, on-premise, or third-party—with minimal effort and configuration.
Data Governance and Security Maintain compliance, enforce access controls, and safeguard sensitive information throughout the data lifecycle.
Collaborative Workflows Support teamwork by enabling version control, documentation, and structured project organization across teams.
Wrapping up
In summary, data engineering tools are vital for managing, processing, and transforming data efficiently. They streamline workflows, handle big data challenges, and ensure the availability of high-quality data for analysis. These tools enhance scalability, optimize performance, and support seamless integration, making data accessible and reliable for decision-making.
Ultimately, data engineering tools enable organizations to build effective data pipelines and maintain data security, unlocking valuable insights across teams.
Data Science Dojo is offering DBT for FREE on Azure Marketplace packaged with support for various data warehouses and data lakes to be configured from CLI.
What does DBT stands for?
Traditionally, data engineers had to process extensive data available at multiple data clouds in the same available cloud environments. The next task was to migrate the data and then transform it as per the requirements, but Data migration was a task not easy to do so. DBT short for Data Build Tool, allows the analysts and engineers to manipulate massive amounts of data from various significant cloud warehouses to be processed reliably at a single workstation using modular SQL.
It is basically the “T” in ELT for data transformation in diverse data warehouses.
ELT vs ETL – Insights of both terms
Now what do these two terms mean? Have a look at the table below:
ELT
ETL
1.
Stands for Extraction Load Transform
Stands for Extraction Transform Load
2.
Supports structured, unstructured, semi structured and raw type of data
Requires relational and structured dataset
3.
New technology, so it’s difficult to find experts or to create data pipelines
Old process, used for over 20 years now
4.
Dataset is extracted from sources and warehoused in the destination and then transformed
After extraction, data is brought into the staging area where’s its transformed and then loaded into target system
5.
Quick data loading time because data is integrated at target system once and then transformed
Takes more time as it’s a multistage process involving a staging area for transformation and twice loading operations
Use cases for ELT
Since dbt relates closely to ELT process, let’s discuss its use cases:
Associations with huge volumes of information: Meteorological frameworks like weather forecasters gather, examine and utilize a lot of information consistently. Organizations with enormous exchange volumes additionally fall into this classification. The ELT process considers faster exchange of data
Associations needing quick accessibility: Stock trades produce and utilize a lot of data continuously, where postponements can be destructive.
Challenges for Data Build Tool (DBT)
Data distributed across multiple data centers and the ability to transform those volumes at a single place was a big challenge.
Then testing and documenting the workflow was another problem.
Therefore, an engine that could cater to the multiple disjointed data warehouses for data transformation would be suitable for the data engineers. Additionally, testing the complex data pipeline with the same agent would do wonders.
Working of DBT
Data Build Tool is a partially open-source platform for transforming and modeling data obtained from your data warehouses all in one place. It allows the usage of simple SQL to manipulate data acquired from different sources. Users can document their files and can generate DAG diagrams thereby identifying the lineage of workflow using dbt docs. Automated tests can be run to detect flaws and missing entries in the data models as well. Ultimately, you can deploy the transformed data model to any other warehouse. DBT serves pleasantly in the cutting-edge information stack and is considered cloud agnostic meaning it operates with several significant cloud environments.
DBT enables data analysts with the feasibility to take over the task of data engineers. With modular SQL at hand, analysts can take ownership of data transformation and eventually create visualizations upon it
It’s cloud agnostic which means that DBT can handle multiple significant cloud environments with their warehouses such as BigQuery, Redshift, and Snowflake to process mission-critical data
Users can maintain a profile specifying connections to different data sources along with schema and threads
Users can document their work and can generate DAG diagrams to visualize their workflow
Through the snapshot feature, you can take a copy of your data at any point in time for a variety of reasons such as tracing changes, time intervals, etc.
What Data Science Dojo has for you
DBT instance packaged by Data Science Dojo comes with pre-installed plugins which are ready to use from CLI without the burden of installation. It provides the flexibility to connect with different warehouses, load the data, transform it using analysts’ favorite language – SQL and finally deploy it to the data warehouse again or export it to data analysis tools.
Ubuntu VM having dbt Core installed to be used from Command Line Interface (CLI)
Database: PostgreSQL
Support for BigQuery
Support for Redshift
Support for Snowflake
Robust integrations
A web interface at port 8080 is spun up by dbt docs to visualize the documentation and DAG workflow
Several data models as samples are provided after initiating a new project
This dbt offer is compatible with the following cloud providers:
GCP
Snowflake
AWS
Disclaimer: The service in consideration is the free open-source version which operates from CLI. The paid features as stated officially by DBT are not endorsed in this offer.
Conclusion
Incoherent sources, data consistency problems, and conflicting definitions for measurements and enterprise details lead to disarray, excess endeavors, and unfortunate data being dispersed for decision-making. DBT resolves all these issues. It was built with version control in mind. It has enabled data analysts to take on the role of data engineers. Any developer with good SQL skills is able to operate on the data – this is in fact the beauty of this tool.
At Data Science Dojo, we deliver data science education, consulting, and technical services to increase the power of data. Therefore, to enhance your data engineering and analysis skills and make the most out of this tool, use the Data Science Bootcamp by Data Science Dojo, your ideal companion in your journey to learn data science!
Click on the button below to head over to the Azure Marketplace and deploy DBT for FREE by clicking on “Get it now”.
Note: You’ll have to sign up to Azure, for free, if you do not have an existing account.
50 self-explanatory data science quotes by thought leaders you need to read if you’re a Data Scientist, – covering the four core components of data science landscape.
Data science for anyone can seem scary. This made me think of developing a simpler approach to it. To reinforce a complicated idea, quotes can do wonders. Also, they are a sneak peek into the window of the author’s experience. With precise phrasing with chosen words, it reinstates a concept in your mind and offers a second thought to your beliefs and understandings.
In this article, we jot down 51 best quotes on data science that were once shared by experts. So, before you let the fear of data scienceget to you, browse through the wise words of industry experts divided into four major components to get inspired.
Data strategy
If you successfully devise a data strategy with the information available, then it will help you to debug a business problem. It builds a connection to the data you gather and the goals you aim to achieve with it. Here are fiveinspiring and famous data strategy quotes by Bernard Marr from his book, “Data Strategy: How to Profit from a World of Big Data, Analytics and the Internet of Things”
“Those companies that view data as a strategic asset are the ones that will survive and thrive.”
“Doesn’t matter how much data you have, it’s whether you use it successfully that counts.”
“If every business, regardless of size, is now a data business, every business, therefore, needs a robust data strategy.”
“They need to develop a smart strategy that focuses on the data they really need to achieve their goals.”
“Data has become one of the most important business assets, and a company without a data strategy is unlikely to get the most out of their data resources.”
Other Best Quotes on Data Science
Some other influential data strategy quotes are as follows:
6. “Big data is at the foundation of all of the megatrends that are happening today, from social to mobile to the cloud to gaming.” – Chris Lynch, Former CEO, Vertica
7. “You can’t run a business today without data. But you also can’t let the numbers drive the car. No matter how big your company is or how far along you are, there’s an art to company-building that won’t fit in any spreadsheet.” Chris Savage, CEO, Wistia
8. “Data science is a combination of three things: quantitative analysis (for the rigor required to understand your data), programming (to process your data and act on your insights), and narrative (to help people comprehend what the data means).” — Darshan Somashekar, Co-founder,at Unwind media
9. “In the next two to three years, consumer data will be the most important differentiator. Whoever is able to unlock the reams of data and strategically use it will win.” — Eric McGee, VP Data and Analytics
10. “Data science isn’t about the quantity of data but rather the quality.” — Joo Ann Lee, Data Scientist, Witmer Group
11. “If someone reports close to a 100% accuracy, they are either lying to you, made a mistake, forecasting the future with the future, predicting something with the same thing, or rigged the problem.” — Matthew Schneider, Former United States Attorney
12. “Executive management is more likely to invest in data initiatives when they understand the ‘why.’” — Della Shea, Vice President of Privacy and Data Governance, Symcor
13. “If you want people to make the right decisions with data, you have to get in their head in a way they understand.” — Miro Kazakoff, Senior Lecturer, MIT Sloan
14. “Everyone has the right to use company data to grow the business. Everyone has the responsibility to safeguard the data and protect the business.” — Travis James Fell, CSPO, CDMP,– Product Manager
15. “For predictive analytics, we need an infrastructure that’s much more responsive to human-scale interactivity. The more real-time and granular we can get, the more responsive, and more competitive, we can be.” Peter Levine, VC and General Partner ,Andreessen Horowitz
Data engineering
Without a sophisticated system or technology to access, organize, and use the data, data science is no less than a bird without wings. Data engineering builds data pipelines and endpoints to utilize the flow of data. Check out these top quotes on data engineering by thought leaders:
16. “Defining success with metrics that were further downstream was more effective.” John Egan, Head of Growth Engineer, Pinterest
17. ” Wrangling data is like interrogating a prisoner. Just because you wrangled a confession doesn’t mean you wrangled the answer.” — Brad Schneider – Politician
18. “If you have your engineering team agree to measure the output of features quarter over quarter, you will get more features built. It’s just a fact.” Jason Lemkin, Founder, SaaStr Fund
19. “Data isn’t useful without the product context. Conversely, having only product context is not very useful without objective metrics…” Jonathan Hsu, CFO, and COO, AppNexus & Head of Data Science,at Social Capital
20. “I think you can have a ridiculously enormous and complex data set, but if you have the right tools and methodology, then it’s not a problem.” Aaron Koblin, Entrepreneur in Data and Digital Technologies
21. “Many people think of data science as a job, but it’s more accurate to think of it as a way of thinking, a means of extracting insights through the scientific method.” — Thilo Huellmann, Co-fFounder,at Levity
22. “You want everyone to be able to look at the data and make sense out of it. It should be a value everyone has at your company, especially people interacting directly with customers. There shouldn’t be any silos where engineers translate the data before handing it over to sales or customer service. That wastes precious time.” Ben Porterfield, Founder and VP of Engineering,at Looker
23. “Of course, hard numbers tell an important story; user stats and sales numbers will always be key metrics. But every day, your users are sharing a huge amount of qualitative data, too — and a lot of companies either don’t know how or forget to act on it.” Stewart Butterfield, CEO, Slack
Data analysis and models
Every business is bombarded with a plethora of data every day. When you get tons of data, analyze it and make impactful decisions. Data analysis usesstatistical and logical techniques to model the use of data:.
24. “In most cases, you can’t build high-quality predictive models with just internal data.” — Asif Syed, Vice President of Data Strategy, Hartford Steam Boiler
25. “Since most of the world’s data is unstructured, an ability to analyze and act on it presents a big opportunity.” — Michael Shulman, Head of Machine Learning, Kensho
26. “It’s easy to lie with statistics. It’s hard to tell the truth without statistics.” — Andrejs Dunkels, Mathematician, and Writer
27. “Information is the oil of the 21st century, and analytics is the combustion engine.” Peter Sondergaard, Senior Vice President, Gartner Research
28. “Use analytics to make decisions. I always thought you needed a clear answer before you made a decision and the thing that he taught me was [that] you’ve got to use analytics directionally…and never worry whether they are 100% sure. Just try to get them to point you in the right direction.” Mitch Lowe, Co-founder of Netflix
29. “Your metrics influence each other. You need to monitor how. Don’t just measure which clicks generate orders. Back it up and break it down. Follow users from their very first point of contact with you to their behavior on your site and the actual transaction. You have to make the linkage all the way through.” Lloyd Tabb, Founder, Looker
30. “Don’t let shallow analysis of data that happens to be cheap/easy/fast to collect nudge you off-course in your entrepreneurial pursuits.” Andrew Chen, Partner at Andreessen Horowitz,
31. “Our real job with data is to better understand these very human stories, so we can better serve these people. Every goal your business has is directly tied to your success in understanding and serving people.” — Daniel Burstein, Senior Director, Content & Marketing, MarketingSherpa
32. “A data scientist combines hacking, statistics, and machine learning to collect, scrub, examine, model, and understand data. Data scientists are not only skilled at working with data, but they also value data as a premium product.” — Erwin Caniba, Founder and Owner,Digitacular Marketing Solutions
33. “It has therefore become a strategic priority for visionary business leaders to unlock data and integrate it with cloud-based BI and analytic tools.” — Gil Peleg, Founder , Model 9 – Crunchbase
34. “The role of data analytics in an organization is to provide a greater level of specificity to discussion.” — Jeff Zeanah, Analytics Consultant
35. “Data is the nutrition of artificial intelligence. When an AI eats junk food, it’s not going to perform very well.” — Matthew Emerick, Data Quality Analyst
36. “Analytics software is uniquely leveraged. Most software can optimize existing processes, but analytics (done right) should generate insights that bring to life whole new initiatives. It should change what you do, not just how you do it.” Matin Movassate, Founder, Heap Analytics
37. “No major multinational organization can ever expect to clean up all of its data – it’s a never-ending journey. Instead, knowing which data sources feed your BI apps, and the accuracy of data coming from each source, is critical.” — Mike Dragan, COO, – Oveit
38. “All analytics models do well at what they are biased to look for.” — Matthew Schneider, Strategic Adviser
39. “Without big data analytics, companies are blind and deaf, wandering out onto the web like deer on a freeway.” Geoffrey Moore, Author and Consultant
Data visualization and operationalization
When you plan to take action with your data, you visualize it on a very large canvas. For an actionable insight, you must squeeze the meaning out of all the analysis performed on that data, this is data visualization. Some data visualization quotes that might interest you are:
40. “Companies have tons and tons of data, but [success] isn’t about data collection, it’s about data management and insight.” — Prashanth Southekal, Business Analytics Author
41. “Without clean data, or clean enough data, your data science is worthless.” — Michael Stonebraker, Adjunct Professor, MIT
42. “The skill of data storytelling is removing the noise and focusing people’s attention on the key insights.” — Brent Dykes, Author, “Effective Data Storytelling”
43. “In a world of more data, the companies with more data-literate people are the ones that are going to win.” — Miro Kazakoff, Senior Lecturer, MIT Sloan
44. The goal is to turn data into information and information into insight. Carly Fiorina, Former CEO, Hewlett Packard
45. “Data reveals impact, and with data, you can bring more science to your decisions.” Matt Trifiro, CMO, at Vapor IO
46. “The skill of data storytelling is removing the noise and focusing people’s attention on the key insights.” — Brent Dykes, data strategy consultant and author, “Effective Data Storytelling”
47. “In a world of more data, the companies with more data-literate people are the ones that are going to win.” — Miro Kazakoff, Senior Lecturer, MIT Sloan
48. “One cannot create a mosaic without the hard small marble bits known as ‘facts’ or ‘data’; what matters, however, is not so much the individual bits as the sequential patterns into which you organize them, then break them up and reorganize them'” — Timothy Robinson, Physician Scientist
49. “Data are just summaries of thousands of stories–tell a few of those stories to help make the data meaningful.” Chip and Dan Heath, Authors of Made to Stick and Switch
Parting thoughts on amazing data science quotes
Each quote by industry experts or experienced professionals provides us with insights to better understand the subject. Here are the final quotes for both aspiring and existing data scientists:
50. “The self-taught, un-credentialed, data-passionate people—will come to play a significant role in many organizations’ data science initiatives.” – Neil Raden, Founder, and Principal Analyst, Hired Brains Research.
51. “Data scientists are involved with gathering data, massaging it into a tractable form, making it tell its story, and presenting that story to others.” – Mike Loukides, Editor, O’Reilly Media.
Have we missed any of your favorite quotes on data? Or do you have any thoughts on the data quotes shared above? Let us know in the comments.