In the dynamic world of machine learning and natural language processing (NLP), managing complex data efficiently has become crucial. Traditional databases often fall short when handling the high-dimensional data generated by modern AI applications, such as embeddings from text, images, and audio.
This challenge has led to the rise of vector databases, which offer robust solutions for storing and retrieving complex data types with remarkable efficiency. These sophisticated platforms have emerged as indispensable tools, providing a robust infrastructure for managing the intricate data structures generated by large language models (LLMs).
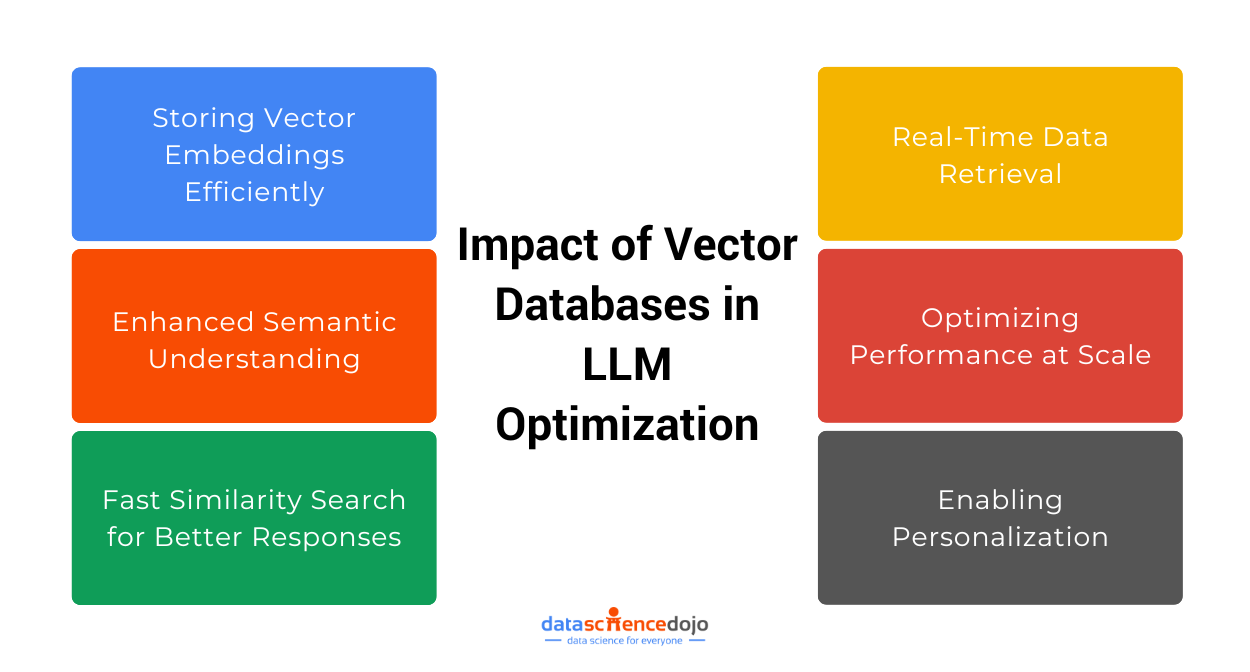
These databases support efficient storage and rapid, accurate similarity searches, making them vital for various applications.

This blog explores the significance of vector databases, examining their unique features and applications in LLM scenarios. We will also present real-world case studies that highlight their impact across different industries. Join us as we uncover the critical role of vector databases in driving AI innovation.
What are Vector Databases?
Vector databases are specialized purpose-built platforms designed to store, manage, and query high-dimensional data represented as vectors. These vectors are mathematical representations that capture the semantic meaning of unstructured data types such as text, images, audio, and more.
These databases enable efficient and accurate similarity searches within these complex data structures, which are beyond the capabilities of traditional databases. By organizing data as vectors, these databases facilitate advanced ML and NLP tasks, such as semantic search, recommendation systems, and real-time personalization.
Learn more about the Traditional vs Vector Databases debate
Hence, vector databases are meticulously designed to address the intricate challenges posed by the storage and retrieval of vector embeddings.
In the landscape of NLP applications, these embeddings serve as the lifeblood, capturing intricate semantic and contextual relationships within vast datasets. Traditional databases, grappling with the high-dimensional nature of these embeddings, falter in comparison to the efficiency and adaptability offered by vector databases.
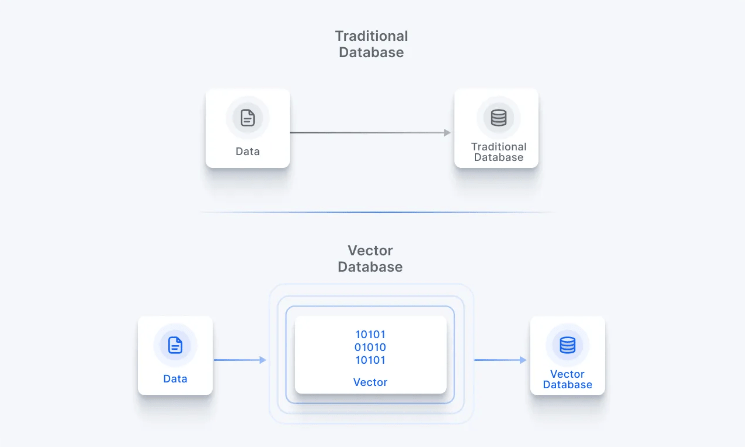
The uniqueness of vector databases lies in their tailored ability to efficiently manage complex data structures, a critical requirement for handling embeddings generated from large language models and other intricate machine learning models.
These databases serve as the hub, providing an optimized solution for the nuanced demands of NLP tasks. In a landscape where the boundaries of machine learning are continually pushed, vector databases stand as pillars of adaptability, efficiently catering to the specific needs of high-dimensional vector storage and retrieval.
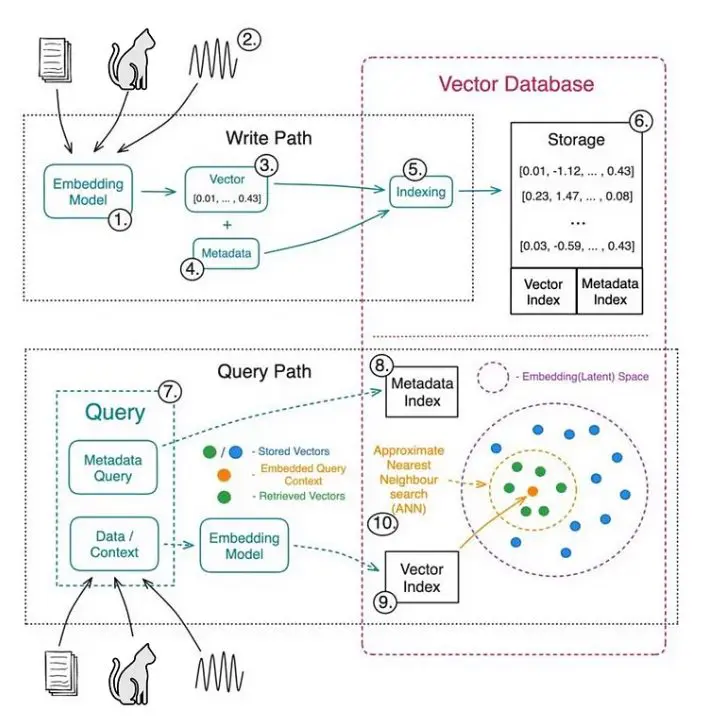
How are Vector Embeddings Linked to Vector Databases?
Vector embeddings are mathematical representations of data in the form of multi-dimensional vectors that algorithms can easily process and analyze. Unlike traditional methods, vector embeddings place data points in a continuous space, allowing for more detailed and meaningful comparisons.
Read more about embeddings and their foundational role in LLMs
For example, in natural language processing (NLP), embeddings can capture the contextual meaning of words, enabling more sophisticated text analysis and understanding. The dimensions of these vectors represent different data features, and the vector position in space reflects the relationships and similarities between different points.
These vector embeddings are the fundamental data type that vector databases store, manage, and retrieve. The databases rely on the high-dimensional characteristics of these embeddings for quick and efficient searches.
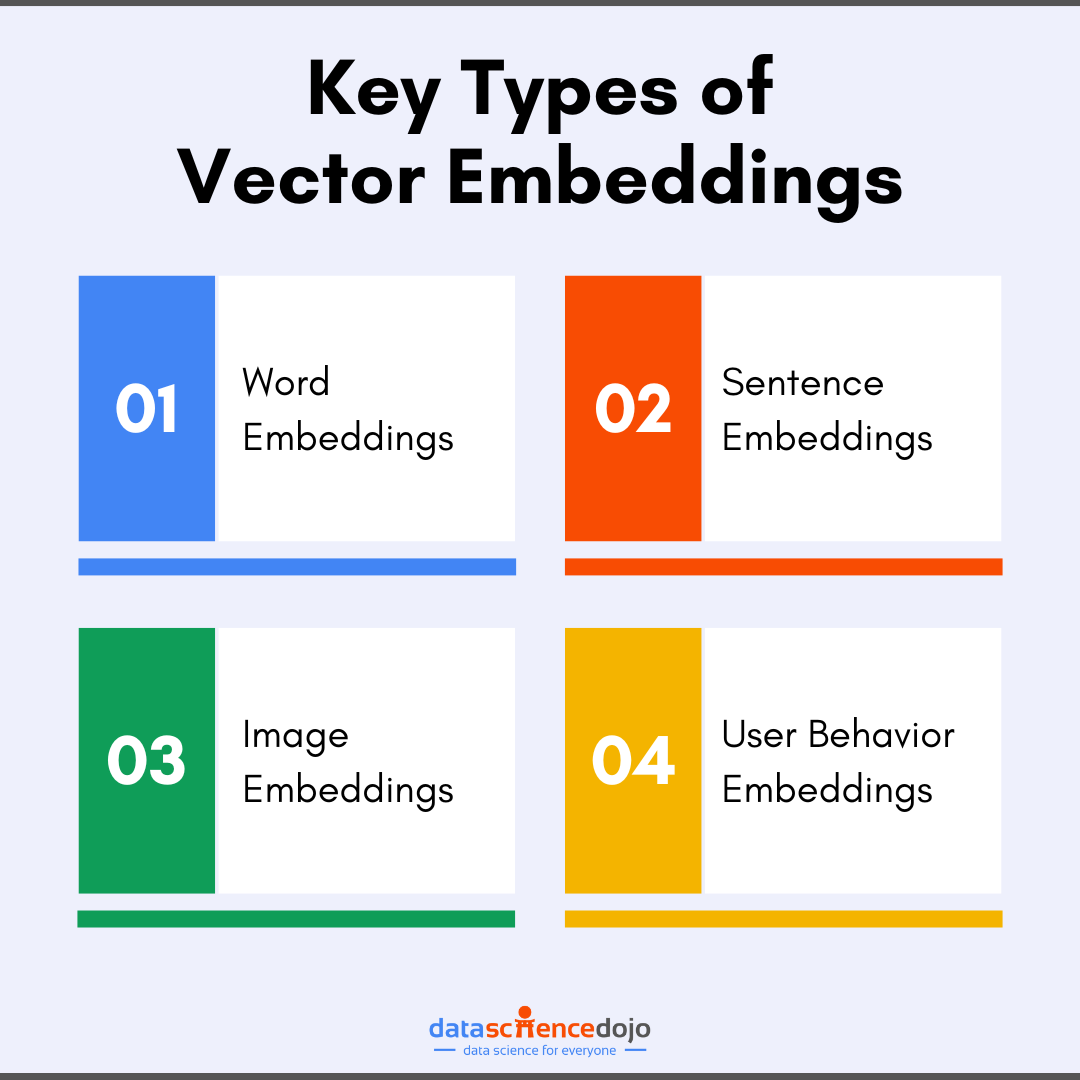
Common types of vector embeddings include:
- Word Embeddings: represent words in vector space based on their context
- Sentence Embeddings: capture the meaning of entire sentences to aid tasks like semantic search
- Image Embeddings: present visual features like shapes and colors as vectors for efficient image search
- User Behavior Embeddings: quantify user actions and preferences for enhanced recommendations
The variety of these vector embeddings empowers advanced AI and machine learning applications for deeper insights and more personalized, intelligent systems across various fields.
Read about the evolution of word embeddings
How are Embeddings Created?
Machine learning (ML) models transform raw data points into numerical representations in a high-dimensional space as vector embeddings. The models are designed to capture the meaningful features and relationships in the data to encode them as vectors.
Some popular ML models used for the creation of vector embeddings are as follows:
BERT (Bidirectional Encoder Representations from Transformers): BERT is a model that reads text in both directions (left-to-right and right-to-left) to understand the context of each word in a sentence. This helps in capturing the detailed meaning of words based on their surroundings.
GPT (Generative Pre-trained Transformer): GPT is designed to predict the next word in a sequence, which helps in generating text that is coherent and contextually relevant. It also captures the relationships between words effectively.
CNNs (Convolutional Neural Networks): Although CNNs are primarily used for image data, they can also be applied to text. CNNs analyze smaller parts of data, such as phrases or image patches, to create embeddings that capture essential features.
Explore key factors to consider when choosing your vector embedding model
All these ML models rely on high-dimensional space to capture the complex relationships and semantic meanings within data. Each dimension is used to represent a different feature of the data, enabling ML models to understand and analyze various types of data for more accurate results.
For example, words with similar meanings will be placed closer together, while unrelated words will be farther apart. This spatial arrangement helps in understanding and processing data more effectively.
The Problem of High-Dimensional Data Retrieval
Since multi-dimensional vector embeddings capture complex features of data, each vector can have hundreds or thousands of dimensions. With an increase in dimensions, distances between data points become less meaningful making it difficult to navigate data.
Thus, traditional retrieval methods do not work for such complex databases. Hence, data retrieval from vector databases requires specialized algorithms and indexing techniques to find vectors efficiently. Let’s explore some indexing techniques used to navigate high-dimensional data.
Indexing Techniques in Vector Databases
Indexing techniques in vector databases are specialized methods designed to handle high-dimensional data efficiently. These techniques are optimized for performing similarity searches in vector spaces.

Here are some key indexing techniques used in vector databases:
- Hierarchical Navigable Small World (HNSW) – a graph-based algorithm that creates a multi-layer navigation graph to represent the vector space, forming a network of shortcuts that narrow down the search space to a small subset of similar vectors.
- Inverted File Index (IVF) – divides the vector space into clusters and creates an inverted file for each cluster. Each file records vectors belonging to a specific cluster, enabling comparison and detailed data search within clusters.
- Product Quantization (PQ) – compresses vectors into a smaller representation that can be used for efficient search. It reduces the storage space and improves the query performance, making it suitable for large datasets.
- Locality-Sensitive Hashing (LSH) – finds similar vectors by hashing them into buckets. Vectors that are close to each other in the vector space are likely to be hashed into the same bucket, facilitating efficient similarity searches.
Uncover the mystery of indexing and its types
Important Trade-Offs in Indexing
Indexing in vector databases is essential to achieve a balance between accuracy and speed, especially when dealing with large datasets. It results in trade-offs of retrieval speed, memory usage, and accuracy. Following are the key trade-offs in indexing:
Retrieval Speed vs. Accuracy:
Exact nearest neighbor methods guarantee high accuracy but can be slow, especially with large datasets. However, Approximate nearest neighbor (ANN) techniques offer faster retrieval times by slightly sacrificing accuracy to quickly find vectors that are close enough, making them ideal for large-scale applications.
Memory Usage vs. Speed:
Some indexing techniques, like Product Quantization (PQ), compress vectors to reduce memory usage, which can also speed up searches by making data more manageable. Meanwhile, Locality-Sensitive Hashing (LSH) hashes vectors into buckets, which speeds up the search but might require more memory to maintain the hash tables.
Hence, indexing in vector databases strikes a balance between accuracy and speed, ensuring efficient data management and scalability. By leveraging sophisticated algorithms, these databases handle large datasets while maintaining quick and reliable search performance.
Let’s look at some common search processes that rely on vector databases to produce useful and accurate results.
Discover how vector search and embeddings enable enhanced data analysis
Vector Search – A Focused Similarity Search for Vector Databases
Similarity search is a data retrieval technique to find items that are most similar to a query input. Unlike traditional keyword searches that rely on exact matches, similarity search focuses on finding items that are alike in terms of their semantic meaning or other complex relationships.
A type of similarity search is vector search that is specifically designed for high-dimensional data represented as vector embeddings. The process relies on vector databases to execute large-scale data retrieval efficiently.
With suitable indexing techniques in these databases, it also executes faster searches. As a result, vector search is used to conduct context-aware or semantic search to user queries. Other applications of vector search include:
- Text Search: Phrases or documents search for ones that are semantically similar to a query.
- Image Retrieval: Identifying images that are visually similar.
- Recommendation Systems: Suggesting products or content based on user preferences.
- Fraud Detection: Identifying suspicious activities by comparing them to known patterns.
Exploring Different Types of Vector Databases and Their Features
The vast landscape of vector databases unfolds in diverse types, each armed with unique features meticulously crafted for specific use cases.

Weaviate: Graph-Driven Semantic Understanding
Weaviate stands out for seamlessly blending graph database features with powerful vector search capabilities, making it an ideal choice for NLP applications requiring advanced semantic understanding and embedding exploration.
With a user-friendly RESTful API, client libraries, and a WebUI, Weaviate simplifies integration and management for developers. The API ensures standardized interactions, while client libraries abstract complexities, and the WebUI offers an intuitive graphical interface.
Weaviate’s cohesive approach empowers developers to leverage its capabilities effortlessly, making it a standout solution in the evolving landscape of data management for NLP.
Read about simplifying API interactions with LangChain
DeepLake: Open-Source Scalability and Speed
DeepLake, an open-source powerhouse, excels in the efficient storage and retrieval of embeddings, prioritizing scalability and speed. With a distributed architecture and built-in support for horizontal scalability, DeepLake emerges as the preferred solution for managing vast NLP datasets.
Its implementation of an Approximate Nearest Neighbor (ANN) algorithm, specifically based on the Product Quantization (PQ) method, not only guarantees rapid search capabilities but also maintains pinpoint accuracy in similarity searches.
DeepLake is meticulously designed to address the challenges of handling large-scale NLP data, offering a robust and high-performance solution for storage and retrieval tasks.
Faiss by Facebook: High-Performance Similarity Search
Faiss, known for its outstanding performance in similarity searches, offers a diverse range of optimized indexing methods for swift retrieval of nearest neighbors. With support for GPU acceleration and a user-friendly Python interface, Faiss firmly establishes itself in the landscape.
This versatility enables seamless integration with NLP pipelines, enhancing its effectiveness across a wide spectrum of machine learning applications. Faiss stands out as a powerful tool, combining performance, flexibility, and ease of integration for robust similarity search capabilities in diverse use cases.
Milvus: Scaling Heights with Open-Source Flexibility
Milvus, an open-source tool, stands out for its emphasis on scalability and GPU acceleration. Its ability to scale up and work with graphics cards makes it great for managing large NLP datasets. Milvus is designed to be distributed across multiple machines, making it ideal for handling massive amounts of data.
It easily integrates with popular libraries like Faiss, Annoy, and NMSLIB, giving developers more choices for organizing data and improving the accuracy and efficiency of vector searches. The diversity of vector databases ensures that developers have a nuanced selection of tools, each catering to specific requirements and use cases within the expansive landscape of NLP and machine learning.
A guide to exploring top vector databases in the market
Efficient Storage and Retrieval of Vector Embeddings for LLM Applications
Efficiently leveraging vector databases for the storage and retrieval of embeddings in the world of large language models (LLMs) involves a meticulous process. This journey is multifaceted, encompassing crucial considerations and strategic steps that collectively pave the way for optimized performance.
Choosing the Right Database
The foundational step in this intricate process is the selection of a vector database that seamlessly aligns with the scalability, speed, and indexing requirements specific to the LLM project at hand.
The decision-making process involves a careful evaluation of the project’s intricacies, understanding the nuances of the data, and forecasting future scalability needs. The chosen vector database becomes the backbone, laying the groundwork for subsequent stages in the embedding storage and retrieval journey.
Integration with NLP Pipelines
Leveraging the provided RESTful APIs and client libraries is the key to ensuring a harmonious integration of the chosen vector database within NLP frameworks and LLM applications.
This stage is characterized by a meticulous orchestration of tools, ensuring that the vector database seamlessly becomes an integral part of the larger ecosystem. The RESTful APIs serve as the conduit, facilitating communication and interaction between the database and the broader NLP infrastructure.

Optimizing Search Performance
The crux of efficient storage and retrieval lies in the optimization of search performance. Here, developers delve into the intricacies of the chosen vector database, exploring and utilizing specific indexing methods and GPU acceleration capabilities.
These nuanced optimizations are tailored to the unique demands of LLM applications, ensuring that vector searches are not only precise but also executed with optimal speed. The performance optimization stage serves as the fine-tuning mechanism, aligning with the intricacies of large language models.
Language-specific Indexing
In scenarios where LLM applications involve multilingual content, the choice of a vector database supporting language-specific indexing and retrieval capabilities becomes paramount. This consideration reflects the diverse linguistic landscape that the LLM is expected to navigate.
Language-specific indexing ensures that the database comprehends and processes linguistic nuances, ultimately leading to accurate search results across different languages.
Incremental Updates
A forward-thinking strategy involves the consideration of vector databases supporting incremental updates. This capability is crucial for LLM applications characterized by dynamically changing embeddings.
The database’s ability to efficiently store and retrieve these dynamic embeddings, adapting in real-time to the evolving nature of the data, becomes a pivotal factor in ensuring the sustained accuracy and relevance of the LLM application.
This multifaceted approach to embedding storage and retrieval for LLM applications ensures that developers navigate the complexities of large language models with precision and efficacy, harnessing the full potential of vector databases.
Read about the role of vector embeddings in generative AI
Case Studies: Real-world Impact of Database Optimization with Vector Databases
The real-world impact of vector databases unfolds through compelling case studies across diverse industries, showcasing their versatility and efficacy in varied applications.
Case Study 1: Semantic Understanding in Chatbots
The implementation of Weaviate‘s vector database in an AI chatbot leveraging large language models exemplifies the real-world impact on semantic understanding. Weaviate facilitates the efficient storage and retrieval of semantic embeddings, enabling the chatbot to interpret user queries within context.
The result is a chatbot that provides accurate and contextually relevant responses, significantly enhancing the user experience.
Case Study 2: Multilingual NLP Applications
VectorStore’s language-specific indexing and retrieval capabilities take center stage in a multilingual NLP platform.
The case study illuminates how VectorStore efficiently manages and retrieves embeddings across different languages, providing contextually relevant results for a global user base. This underscores the adaptability of vector databases in diverse linguistic landscapes.
Case Study 3: Image Generation and Similarity Search
In the world of image generation and similarity search, a company harnesses databases to streamline the storage and retrieval of image embeddings. By representing images as high-dimensional vectors, the database enables swift and accurate similarity searches, enhancing tasks such as image categorization, duplicate detection, and recommendation systems.
The real-world impact extends to the world of visual content, underscoring the versatility of vector databases.
Case Study 4: Movie and Product Recommendations
E-commerce and movie streaming platforms optimize their recommendation systems through the power of vector databases. Representing movies or products as high-dimensional vectors based on attributes like genre, cast, and user reviews, the database ensures personalized recommendations.
This personalized touch elevates the user experience, leading to higher conversion rates and improved customer retention. The case study vividly illustrates how vector databases contribute to the dynamic landscape of recommendation systems.

Case Study 5: Sentiment Analysis in Social Media
A social media analytics company transforms sentiment analysis with the efficient use of vector databases. Representing text snippets or social media posts as high-dimensional vectors, the database enables rapid and accurate sentiment analysis.
This real-time analysis of large volumes of text data provides valuable insights, allowing businesses and marketers to track public opinion, detect trends, and identify potential brand reputation issues.
Case Study 6: Fraud Detection in Financial Services
The application of vector databases in a financial services company amplifies fraud detection capabilities. By representing transaction patterns as high-dimensional vectors, the database enables rapid similarity searches to identify suspicious or anomalous behavior.
In the world of financial services, where timely detection is paramount, vector databases provide the efficiency and accuracy needed to safeguard customer accounts. The case study emphasizes the real-world impact of these databases in enhancing security measures.
The Final Word
In conclusion, the complex interplay of efficient storage and retrieval of vector embeddings using vector databases is at the heart of the success of machine learning and NLP applications, particularly in the expansive landscape of large language models.
This journey has unveiled the profound significance of vector databases, explored the diverse types and features they bring to the table, and provided insights into their application in LLM scenarios.

Real-world case studies have served as representations of their tangible impact, showcasing their ability to enhance semantic understanding, multilingual support, image generation, recommendation systems, sentiment analysis, and fraud detection.
By assimilating the insights shared in this exploration, developers embark on a path that brings them closer to harnessing the full potential of vector databases. These databases, with their adaptability, efficiency, and real-world impact, emerge as indispensable allies in the dynamic landscape of machine learning and NLP applications.