

Artificial intelligence (AI) has infiltrated every field of life, creating new avenues of development and creativity. Amongst these advancements is AI music generation. It refers to the use of AI tools and models to create melodious notes.
However, it is a complex process as generating music is challenging and requires modeling long-range sequences. Unlike speech, music requires the full frequency spectrum [Müller, 2015]. That means sampling the signal at a higher rate, i.e., the standard sampling rates of music recordings are 44.1 kHz or 48 kHz vs. 16 kHz for speech.
Moreover, the music contains harmonies and melodies from different instruments, creating complex structures. Since human listeners are highly sensitive to disharmony [Fedorenko et al., 2012; Norman-Haignere et al., 2019], generating music does not leave much room for making melodic errors.

Hence, the ability to control the generation process in a diverse set of methods, e.g., key, instruments, melody, genre, etc. is essential for music creators. Today, music generation models powered by AI are designed to cater to these complexities and promote creativity.
In this blog, we will explore the 5 leading AI music generation models and their role in revamping the music industry. Before we navigate the music generation models, let’s dig deeper into the idea of AI generated music and what it actually means.
What is AI Music Generation?
It is the process of using AI to generate music. It can range from composing entire pieces to assisting with specific elements like melodies or rhythms. AI analyzes large datasets of music, from catchy pop tunes to timeless symphonies, to learn the basics of music generation.
This knowledge lets it create new pieces based on your preferences. You can tell the AI what kind of music you want (think rock ballad or funky disco) and even provide starting ideas. Using its knowledge base and your input, AI generates melodies, harmonies, and rhythms. Some tools even allow you to edit the outputs as needed.
As a result, the music generation process has become more interesting and engaging. Some benefits of AI generated music include:
Explore the top 7 AI Music Generators
Enhanced Creativity and Experimentation
AI tools empower musicians to experiment with different styles and rhythms. It also results in the streamlining of the song production process, allowing for quick experimentation with new sounds and ideas.
This allows for the creation of personalized music based on individual preferences and moods can revolutionize how we listen to music. This capability enables the generation of unique soundtracks tailored to daily activities or specific emotional states.
Accessibility and Democratization
AI music generation tools make music creation accessible to everyone, regardless of their musical background or technical expertise. These tools enable users to compose music through text input, democratizing music production.
Moreover, in educational settings, AI tools introduce students to the fundamentals of music composition, allowing them to learn and create music in an engaging way. This practical approach helps cultivate musical skills from a young age.
Efficiency and Quality
AI music tools simplify the music-making process, allowing users to quickly craft complete songs without compromising quality. This efficiency is particularly beneficial for professional musicians and production teams.
Plus, AI platforms ensure that the songs produced are of professional-grade audio quality. This high level of sound clarity and richness ensures that AI-generated music captures and holds the listener’s attention.
Learn about AI tools for code generation
Cost and Time Savings
These tools also significantly reduce the costs associated with traditional music production, including studio time and hiring session musicians. This makes it an attractive option for indie artists and small production houses. Hence, music can be generated quickly and at lower costs.
These are some of the most common advantages of utilizing AI in music generation. While we understand the benefits, let’s take a closer look at the models involved in the process.
Also learn about AI tools that could revolutionize your daily routine
Types of Music Generation Models
There are two main types of music generation models utilized to create AI music.
1. Autoregressive Models
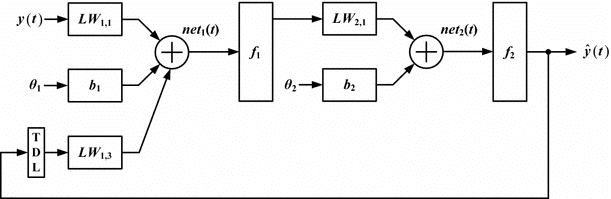
These models are a fundamental approach in AI music generation, where they predict future elements of a sequence based on past elements. They generate data points in a sequence one at a time, using previous data points to inform the next.
In the context of music generation, this means predicting the next note or sound based on the preceding ones. The model is trained to understand the sequence patterns and dependencies in the musical data. This makes them particularly effective for tasks involving sequence generation like music.
Thus, autoregressive models can generate high-quality, coherent musical compositions that align well with provided text descriptions or melodies. However, they are computationally complex, making their cost a challenge as each token prediction depends on all previous tokens, leading to higher inference times for long sequences.
2. Diffusion Models
They are an emerging class of generative models that have shown promising results in various forms of data generation, including music. These models work by reversing a diffusion process, which gradually adds noise to the data, and then learning to reverse this process to generate new data.
Diffusion models can be applied to generate music by treating audio signals as the data to be diffused and denoised. Here’s how they are typically employed:
- Audio Representation: Music is represented in a compressed form, such as spectrograms or latent audio embeddings, which are then used as the input to the diffusion process.
- Noise Addition: Gaussian noise is added to these representations over several steps, creating a series of increasingly noisy versions of the original music.
- Model Training: A neural network is trained to reverse the noise addition process. This involves learning to predict the original data from the noisy versions at each step.
- Music Generation: During generation, the model starts with pure noise and applies the learned reverse process to generate new music samples.
Thus, diffusion models can generate high-quality audio with fine details. They are flexible as they can handle various conditioning inputs, such as text descriptions or reference audio, making them versatile for different music generation tasks. However, they also pose the challenge of high computational costs.
Use GenAI for art generation too
5 Leading Music Generation Models
Now that we understand the basic models used in AI music generation, it is time we explore the 5 leading music generation models in the market nowadays.
1. MusicLM by Google
MusicLM is an AI music system developed by Google to create music based on textual prompts. It allows users to specify the genre, mood, instruments, and overall feeling of the desired music through words. Once a user inputs their prompt, the tool will generate multiple versions of the request.
Moreover, the tool allows the users to refine the outputs by specifying instruments and the desired effect or emotion. Google also published an academic paper to highlight the different aspects of its AI tool for music generation.
While you can explore the paper at leisure, here is a breakdown of how MusicLM works:
- Training Data:
- MusicLM is trained on a vast dataset comprising 280,000 hours of recorded music. This extensive training allows the model to understand a wide variety of musical styles and nuances 2.Learn the Best Programming Languages for Data Analysts
- Token-Based Representation:
- The system models sound in three distinct aspects: the correspondence between words and music, large-scale composition, and small-scale details.
- Different types of tokens are used to represent these aspects:
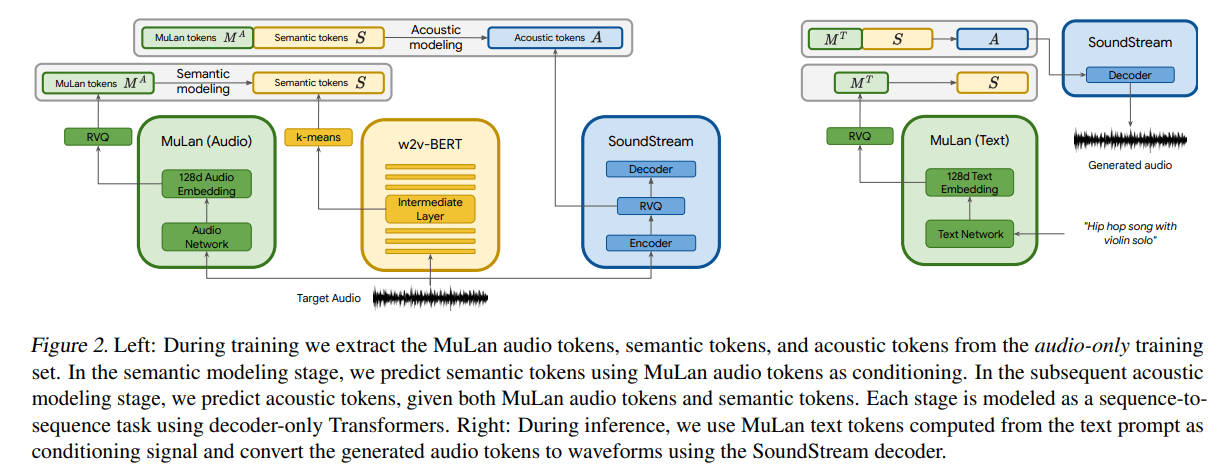
- Audio-Text Tokens: Generated by MuLan, a transformer-based system pre-trained on soundtracks of 44 million online music videos, these tokens capture the relationship between music and its descriptions.
- Semantic Tokens: Produced by w2v-BERT, these tokens represent large-scale compositions and are fine-tuned on 8,200 hours of music.
- Acoustic Tokens: Created by a SoundStream autoencoder, these tokens capture small-scale details of the music and are also fine-tuned on 8,200 hours of music.
- Transformation and Generation:
- Given a text description, MuLan generates audio-text tokens, which are then used to guide the generation of semantic tokens by a series of transformers.
- Another series of transformers takes these semantic tokens and generates acoustic tokens, which are then decoded by the SoundStream decoder to produce the final music clip.
- Inference Process:
- During inference, the model starts with audio-text tokens generated from the input description. These tokens then undergo a series of transformations and decoding steps to generate a music clip.
Evaluation and Performance
- The authors evaluated MusicLM on 1,000 text descriptions from a text-music dataset, comparing it to two other models, Riffusion and Mubert. MusicLM was judged to have created the best match 30.0% of the time, compared to 15.2% for Riffusion and 9.3% for Mubert 1.
MusicLM is a significant advancement in AI-driven music generation. It is available in the AI Test Kitchen app on the web, Android, or iOS, where users can generate music based on their text inputs. To avoid legal challenges, Google has restricted this available version, preventing it from generating music with specific artists or vocals.

2. MusicGen by Meta
MusicGen by Meta is an advanced AI model designed for music generation based on text descriptions or existing melodies. It is built on a robust transformer model and employs various techniques to ensure high-quality music generation.
This is similar to how language models predict the next words in a sentence. The model employs an audio tokenizer called EnCodec to break down audio data into smaller parts for easier processing.
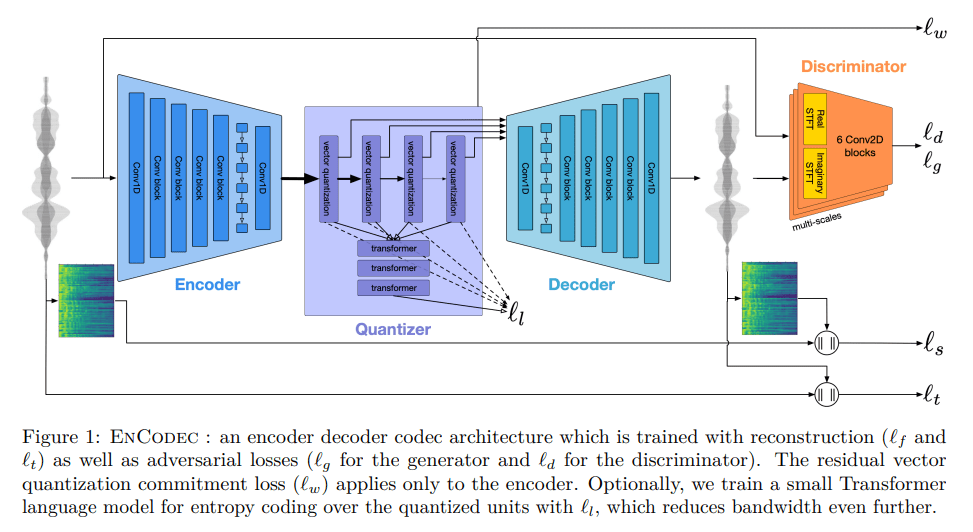
Some key components and aspects of MusicGen are as follows:
- Training Dataset:
- The model was trained on a large dataset of 20,000 hours of music. This includes 10,000 high-quality licensed music tracks and 390,000 instrument-only tracks from stock media libraries such as Shutterstock and Pond5. This extensive dataset ensures that MusicGen can generate tunes that resonate well with listeners.
- Residual Vector Quantization (RVQ):
- MusicGen leverages RVQ, a multi-stage quantization method that reduces data usage while maintaining high-quality audio output. This technique involves using multiple codebooks to quantize the audio data iteratively, thereby achieving efficient data compression and high fidelity.
- Model Architecture:
- The architecture comprises an encoder, decoder, and conditioning modules. The encoder converts input audio into a vector representation, which is then quantized using RVQ. The decoder reconstructs the audio from these quantized vectors. The conditioning modules handle text or melody inputs, allowing the model to generate music that aligns with the provided prompts.
- Open Source:
- Meta has open-sourced MusicGen, including the code and pre-trained models. This allows researchers and developers to reproduce the results and contribute to further improvements.
Performance and Evaluation
- MusicGen produces reasonably melodic and coherent music, especially for basic prompts. It has been noted to perform on par or even outshine other AI music generators like Google’s MusicLM in terms of musical coherence for complex prompts.
Hence, MusicGen offers a blend of creativity and technical precision within the world of music generation. Its ability to use both text and melody prompts, coupled with its open-source nature, makes it a valuable tool for researchers, musicians, and AI enthusiasts alike.
Also learn how to use AI image generation tools
3. Suno AI
Suno AI is an innovative AI-powered tool designed to democratize music creation by enabling users to compose music through text input. It leverages AI to translate users’ ideas into musical outputs. Users can input information in the textual data, including the mood of your song or the lyrics you have written.
The algorithms craft melodies and harmonies that align with the users’ input information. It results in structured and engaging melodious outputs. The AI refines every detail of the output song, from lyrics to rhythm, resulting in high-quality music tracks that capture your creative spark.
Moreover, the partnership with Microsoft Copilot enhances Suno AI’s capabilities, broadening creative horizons and transforming musical concepts into reality. It is a user-friendly platform with a simplified music-making process, ensuring enhanced accessibility and efficiency.
Some top features of Suno AI are listed below.
- High-Quality Instrumental Tracks: Suno AI creates high-quality instrumental tracks that align perfectly with the song’s theme and mood, ranging from soft piano melodies to dynamic guitar riffs.
- Exceptional Audio Quality: Every song produced boasts professional-grade audio quality, ensuring clarity and richness that captures and holds attention.
- Flexibility and Versatility: The platform adapts to a wide range of musical styles and genres, making it suitable for various types of music creation, from soothing ballads to upbeat dance tracks.
Users can start using Suno AI by signing up for the platform, providing text input, and letting Suno AI generate a unique composition based on their input. The platform offers a straightforward and enjoyable music creation experience.
4. Project Music GenAI Control by Adobe
Project Music GenAI Control by Adobe is an innovative tool designed to revolutionize the creation and editing of custom audio and music. It allows users to share textual prompts to generate music pieces. Once generated, it provides users fine-grained control to edit the audio to their needs.
The editing options include:
- Adjusting the tempo, structure, and repeating patterns of the music.
- Modifying the intensity of the audio at specific points.
- Extending the length of a music clip.
- Re-mixing sections of the audio.
- Creating seamlessly repeatable loops.
These capabilities allow users to transform generated audio based on reference melodies and make detailed adjustments directly within their workflow. The user interface also assists in the process by simplified and automated creation and editing.
The automated workflow efficiency allows users to produce exactly the audio pieces they need with minimal manual intervention, streamlining the entire process.
It provides a level of control over music creation akin to what Photoshop offers for image editing. This “pixel-level control” for music enables creatives to shape, tweak, and edit their audio in highly detailed ways, providing deep control over the final output.
With its automation and fine-grained control, Project Music GenAI Control by Adobe stands out as a valuable tool in the creative industry.
5. Stable Audio 2.0 by Stability AI
Stable Audio 2.0 by Stability AI has set new standards in the field of AI music generation as the model is designed to generate high-quality audio tracks and sound effects using both text and audio inputs. It can produce full tracks with coherent musical structures up to three minutes long at 44.1kHz stereo from a single natural language prompt.
Moreover, its audio-to-audio generation capability enables users to upload audio samples and transform them using textual prompts. It enhances the flexibility and creativity of the tool. Alongside this, Stable Audio 2.0 offers amplified sound and audio effects to create diverse sounds.
Its style transfer feature allows for the seamless modification of newly generated or uploaded audio to align with a project’s specific style and tone. It enhances the customization options available to users.
Some additional aspects of the model include:
- Training and Dataset:
- Stable Audio 2.0 was trained on a licensed dataset from the AudioSparx music library, which includes over 800,000 audio files containing music, sound effects, and single-instrument stems. The training process honors opt-out requests and ensures fair compensation for creators.
- Model Architecture:
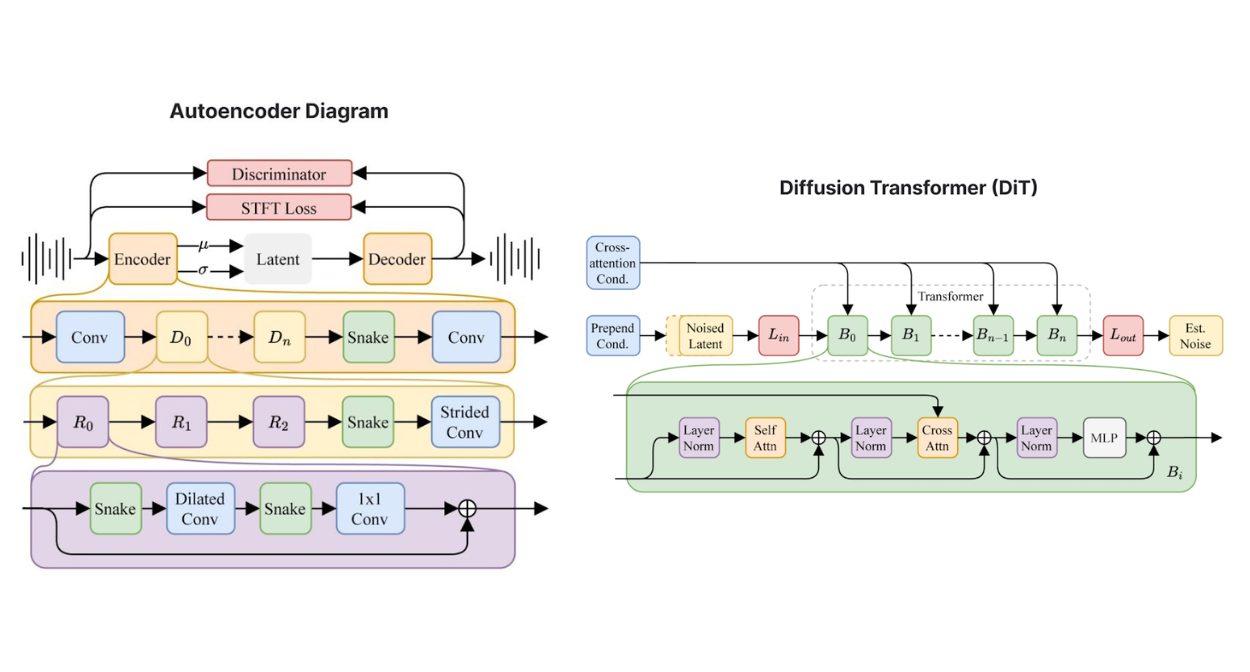
- Its architecture leverages a highly compressed autoencoder to condense raw audio waveforms into shorter representations. It uses a diffusion transformer (DiT) which is more adept at manipulating data over long sequences. This combination results in a model capable of recognizing and reproducing large-scale structures essential for high-quality musical compositions.
- Safeguards and Compliance:
- To protect creator copyrights, Stability AI uses advanced content recognition technology (ACR) powered by Audible Magic to prevent copyright infringement. The Terms of Service require that uploads be free of copyrighted material.
Stable Audio 2.0 offers high-quality audio production, extensive sound effect generation, and flexible style transfer capabilities. It is available for free on the Stable Audio website, and it will soon be accessible via the Stable Audio API.
Hence, AI music generation has witnessed significant advancements through various models, each contributing uniquely to the field. Each of these models pushes the boundaries of what AI can achieve in music generation, offering various tools and functionalities for creators and enthusiasts alike.
While we understand the transformative impact of AI music generation models, they present their own set of limitations and challenges. It is important to understand these limitations to navigate through the available options appropriately and use these tools efficiently.
Read more about 6 AI Tools for Data Analysis
Limitations and Challenges of AI Generated Music
Some prominent concerns associated with AI music generation can be categorized as follows.
Copyright Infringement
AI models like MusicLM and MusicGen often train on extensive musical datasets, which can include copyrighted material. This raises the risk of generated compositions bearing similarities to existing works, potentially infringing on copyright laws. Proper attribution and respect for original artists’ rights are vital to upholding fair practices.
Ethical Use of Training Data
The ethical use of training data is another critical issue. AI models “learn” from existing music to produce similar effects, which not all artists or users are comfortable with. This includes concerns over using artists’ work without their knowledge or consent, as highlighted by several ongoing lawsuits.
Disruption of the Music Industry
The advent of AI-generated music could disrupt the music industry, posing challenges for musicians seeking recognition in an environment flooded with AI compositions. There’s a need to balance utilizing AI as a creative tool while safeguarding the artistic individuality and livelihoods of human musicians.
Here’s a list of 5 Most Useful AI Translation Tools
Bias and Originality
AI-generated music can exhibit biases or specific patterns based on the training dataset. If the dataset is biased, the generated music might also reflect these biases, limiting its originality and potentially perpetuating existing biases in music styles and genres.
Licensing and Legal Agreements
Companies like Meta claim that all music used to train their models, such as MusicGen, was covered by legal agreements with the right holders. However, the continuous evolution of licensing agreements and the legal landscape around AI-generated music remains uncertain.

What is the Future of AI Music?
AI has revolutionized music creation, leading to a new level of creativity and innovation for musicians. However, it is a complex process that requires the handling of intricate details and harmonies. Plus, AI music needs to be adjustable across genre, melody, and other aspects to avoid sounding off-putting.
Today’s AI music generators, like Google’s MusicLM, are tackling these challenges. These models are designed to give creators more control over the music generation process and enhance their creative workflow.
As AI generated music continues to evolve, it’s important to use these technologies responsibly, ensuring AI serves as a tool that empowers human creativity rather than replaces it.