Becoming an LLM master is an invaluable skill for AI practitioners, developers, and data scientists looking to excel in the rapidly evolving field of artificial intelligence. Whether you’re fine-tuning models, building intelligent applications, or mastering prompt engineering, effectively leveraging Large Language Models (LLMs) can set you apart in the AI-driven world.
In this blog, we’ll walk you through the key steps to becoming an LLM expert—from understanding foundational concepts to implementing advanced techniques. Whether you’re just starting out or refining your expertise, this structured roadmap will equip you with the knowledge and tools needed to master LLMs.
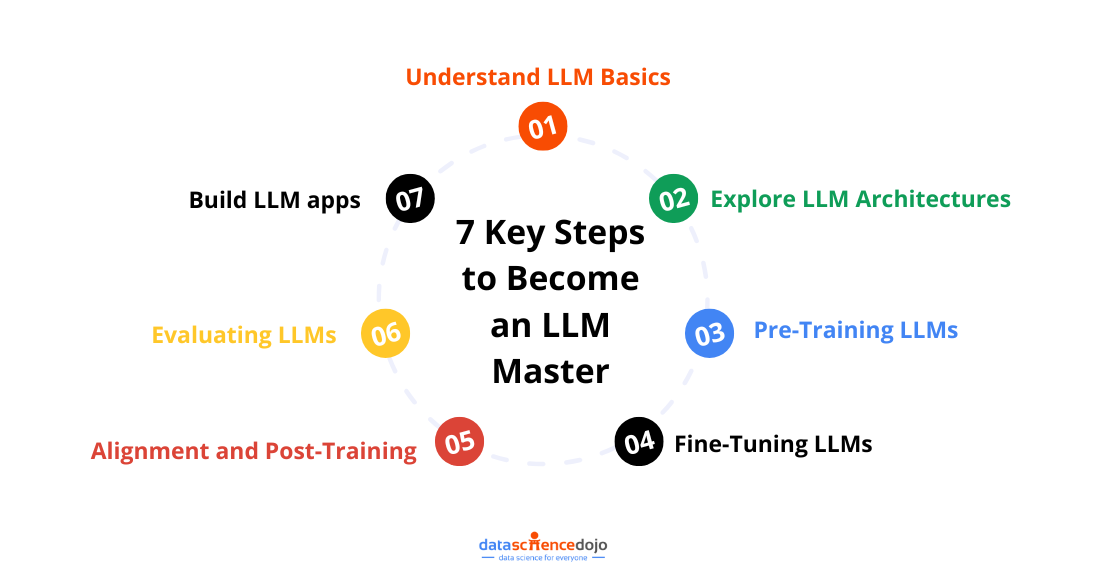
However, becoming an LLM expert requires more than just theoretical knowledge; it demands a deep understanding of model architectures, training methodologies, and best practices. To help you navigate this journey, we’ve outlined a 7-step approach to mastering LLMs:
Step 1: Understand LLM Basics
Before diving into the complexities of Large Language models, it’s crucial to establish a solid foundation in the fundamental concepts. This includes understanding the following:
Natural Language Processing (NLP): NLP is the field of computer science that deals with the interaction between computers and human language. It encompasses tasks like machine translation, text summarization, and sentiment analysis.
Deep Learning: LLMs are powered by deep learning, a subfield of machine learning that utilizes artificial neural networks to learn from data. Familiarize yourself with the concepts of neural networks, such as neurons, layers, and activation functions.
Transformer: The transformer architecture is a cornerstone of modern LLMs. Understand the components of the transformer architecture, including self-attention, encoder-decoder architecture, and positional encoding.
Step 2: Explore LLM Architectures
Large Language models come in various architectures, each with its strengths and limitations. Explore different LLM architectures, such as:
BERT (Bidirectional Encoder Representations from Transformers): BERT is a widely used LLM that excels in natural language understanding tasks, such as question answering and sentiment analysis.
GPT (Generative Pre-training Transformer): GPT is known for its ability to generate human-quality text, making it suitable for tasks like creative writing and chatbots.
XLNet (Generalized Autoregressive Pre-training for Language Understanding): XLNet is an extension of BERT that addresses some of its limitations, such as its bidirectional nature.
Step 3: Pre-Training LLMs
Pre-training is a crucial step in the development of LLMs. It involves training the LLM on a massive dataset of text and code to learn general language patterns and representations. Explore different pre-training techniques, such as:
Masked Language Modeling (MLM): In MLM, random words are masked in the input text, and the LLM is tasked with predicting the missing words.
Next Sentence Prediction (NSP): In NSP, the LLM is given two sentences and asked to determine whether they are consecutive sentences from a text or not.
Contrastive Language-Image Pre-training (CLIP): CLIP involves training the LLM to match text descriptions with their corresponding images.
Step 4: Fine-Tuning LLMs
Fine-tuning involves adapting a pre-trained LLM to a specific task or domain. This is done by training the LLM on a smaller dataset of task-specific data. Explore different fine-tuning techniques, such as:
Task-specific loss functions: Define loss functions that align with the specific task, such as accuracy for classification tasks or BLEU score for translation tasks.
Data augmentation: Augment the task-specific dataset to improve the LLM’s generalization ability.
Early stopping: Implement early stopping to prevent overfitting and optimize the LLM’s performance.
This talk below can help you get started with fine-tuning GPT 3.5 Turbo.
Step 5: Alignment and Post-Training
Alignment and post-training are essential steps to ensure that Large Language models are aligned with human values and ethical considerations. This includes:
Bias mitigation: Identify and mitigate biases in the LLM’s training data and outputs.
Fairness evaluation: Evaluate the fairness of the LLM’s decisions and identify potential discriminatory patterns.
Explainability: Develop methods to explain the LLM’s reasoning and decision-making processes.
Step 6: Evaluating LLMs
Evaluating LLMs is crucial to assess their performance and identify areas for improvement. Explore different evaluation metrics, such as:
Accuracy: Measure the proportion of correct predictions for classification tasks.
Fluency: Assess the naturalness and coherence of the LLM’s generated text.
Relevance: Evaluate the relevance of the LLM’s outputs to the given prompts or questions.
With a strong understanding of Large Language models, you can start building applications that leverage their capabilities. Explore different application scenarios, such as:
Chatbots: Develop chatbots that can engage in natural conversations with users.
Content creation: Utilize LLMs to generate creative content, such as poems, scripts, or musical pieces.
Machine translation: Build machine translation systems that can accurately translate languages.
Start Learning to Become an LLM Master
Mastering large language models is an ongoing journey that requires continuous learning and exploration. By following these seven steps, you can gain a comprehensive understanding of LLMs, their underlying principles, and the techniques involved in their development and application.
As Large Language models continue to evolve, stay informed about the latest advancements and contribute to the responsible and ethical development of these powerful tools. Here’s a list of YouTube channels that can help you stay updated in the world of large language models.
7 Steps to Mastering Large Language Models (LLMs)
Large language models (LLMs) have revolutionized the field of natural language processing (NLP), enabling machines to generate human-quality text, translate languages, and answer questions in an informative way. These advancements have opened up a world of possibilities for applications in various domains, from customer service to education.
However, mastering LLMs requires a comprehensive understanding of their underlying principles, architectures, and training techniques.
This 7-step guide will provide you with a structured approach to mastering LLMs:
Step 1: Understand LLM Basics
Before diving into the complexities of LLMs, it’s crucial to establish a solid foundation in the fundamental concepts. This includes understanding the following:
Natural Language Processing (NLP): NLP is the field of computer science that deals with the interaction between computers and human language. It encompasses tasks like machine translation, text summarization, and sentiment analysis.
Deep Learning: LLMs are powered by deep learning, a subfield of machine learning that utilizes artificial neural networks to learn from data. Familiarize yourself with the concepts of neural networks, such as neurons, layers, and activation functions.
Transformer: The transformer architecture is a cornerstone of modern LLMs. Understand the components of the transformer architecture, including self-attention, encoder-decoder architecture, and positional encoding.
Step 2: Explore LLM Architectures
LLMs come in various architectures, each with its strengths and limitations. Explore different LLM architectures, such as:
BERT (Bidirectional Encoder Representations from Transformers): BERT is a widely used LLM that excels in natural language understanding tasks, such as question answering and sentiment analysis.
GPT (Generative Pre-training Transformer): GPT is known for its ability to generate human-quality text, making it suitable for tasks like creative writing and chatbots.
XLNet (Generalized Autoregressive Pre-training for Language Understanding): XLNet is an extension of BERT that addresses some of its limitations, such as its bidirectional nature.
Step 3: Pre-training LLMs
Pre-training is a crucial step in the development of LLMs. It involves training the LLM on a massive dataset of text and code to learn general language patterns and representations. Explore different pre-training techniques, such as:
Masked Language Modeling (MLM): In MLM, random words are masked in the input text, and the LLM is tasked with predicting the missing words.
Next Sentence Prediction (NSP): In NSP, the LLM is given two sentences and asked to determine whether they are consecutive sentences from a text or not.
Contrastive Language-Image Pre-training (CLIP): CLIP involves training the LLM to match text descriptions with their corresponding images.
Step 4: Fine-tuning LLMs
Fine-tuning involves adapting a pre-trained LLM to a specific task or domain. This is done by training the LLM on a smaller dataset of task-specific data. Explore different fine-tuning techniques, such as:
Task-specific loss functions: Define loss functions that align with the specific task, such as accuracy for classification tasks or BLEU score for translation tasks.
Data augmentation: Augment the task-specific dataset to improve the LLM’s generalization ability.
Early stopping: Implement early stopping to prevent overfitting and optimize the LLM’s performance.
This talk below can help you get started with fine-tuning GPT 3.5 Turbo.
Alignment and post-training are essential steps to ensure that LLMs are aligned with human values and ethical considerations. This includes:
Bias mitigation: Identify and mitigate biases in the LLM’s training data and outputs.
Fairness evaluation: Evaluate the fairness of the LLM’s decisions and identify potential discriminatory patterns.
Explainability: Develop methods to explain the LLM’s reasoning and decision-making processes.
Step 6: Evaluating LLMs
Evaluating LLMs is crucial to assess their performance and identify areas for improvement. Explore different evaluation metrics, such as:
Accuracy: Measure the proportion of correct predictions for classification tasks.
Fluency: Assess the naturalness and coherence of the LLM’s generated text.
Relevance: Evaluate the relevance of the LLM’s outputs to the given prompts or questions.
Step 7: Build LLM Apps
With a strong understanding of LLMs, you can start building applications that leverage their capabilities. Explore different application scenarios, such as:
Chatbots: Develop chatbots that can engage in natural conversations with users.
Content creation: Utilize LLMs to generate creative content, such as poems, scripts, or musical pieces.
Machine translation: Build machine translation systems that can accurately translate languages.
Conclusion
Mastering large language models (LLMs) is an ongoing journey that requires continuous learning and exploration. By following these seven steps, you can gain a comprehensive understanding of LLMs, their underlying principles, and the techniques involved in their development and application.
As LLMs continue to evolve, stay informed about the latest advancements and contribute to the responsible and ethical development of these powerful tools. Here’s a list of YouTube channel that can help you stay updated in the world of large language models.
GPT-3.5 and other large language models (LLMs) have transformed natural language processing (NLP). Trained on massive datasets, LLMs can generate text that is both coherent and relevant to the context, making them invaluable for a wide range of applications.
Learning about LLMs is essential in today’s fast-changing technological landscape. These models are at the forefront of AI and NLP research, and understanding their capabilities and limitations can empower people in diverse fields.
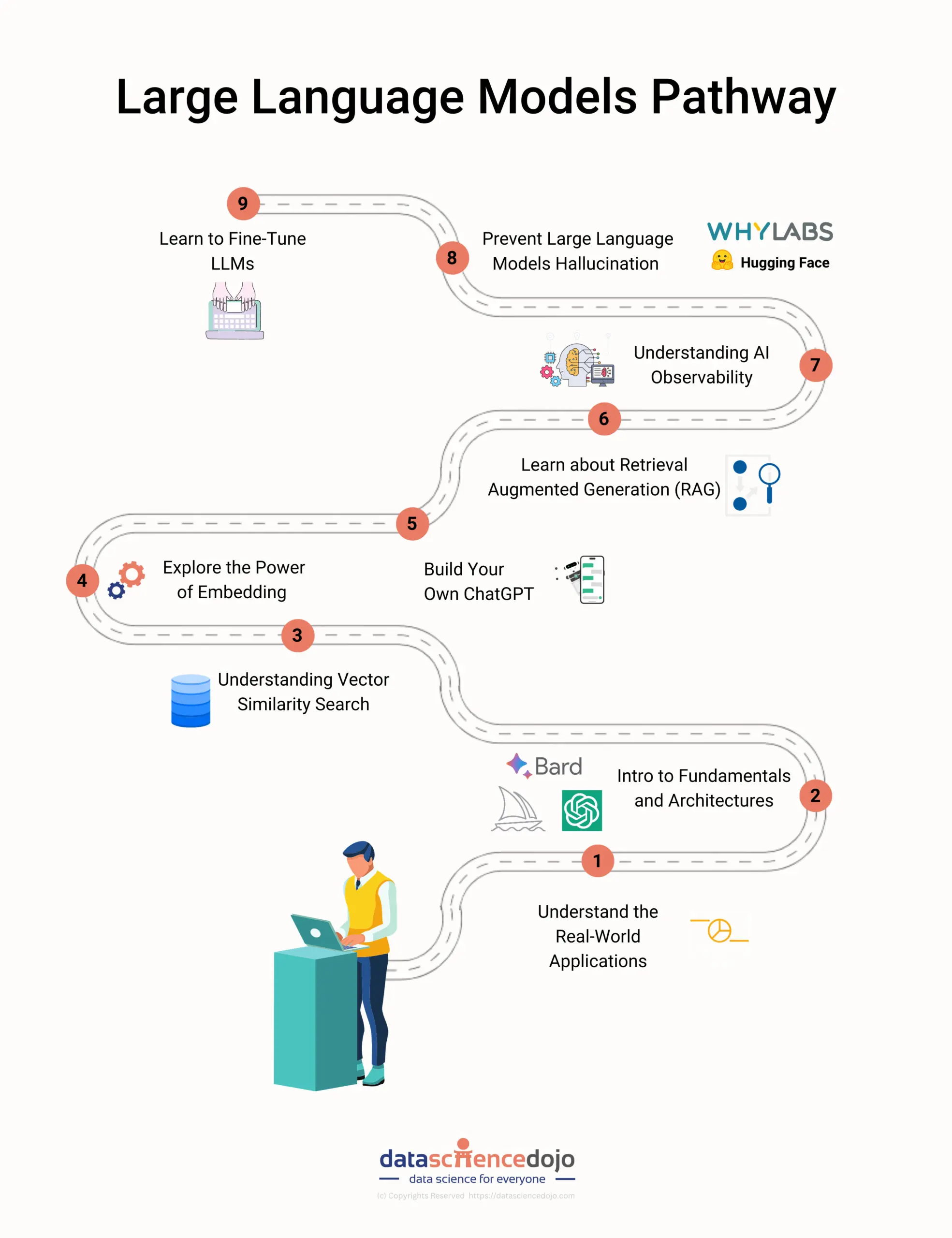
This blog lists steps and several tutorials that can help you get started with large language models. From understanding large language models to building your own ChatGPT, this roadmap covers it all.
Building a large language model application on custom data can help improve your business in a number of ways. This means that LLMs can be tailored to your specific needs. For example, you could train a custom LLM on your customer data to improve your customer service experience.
The talk below will give an overview of different real-world applications of large language models and how these models can assist with different routine or business activities.
Step 2: Introduction to fundamentals and architectures of LLM applications
Applications like Bard, ChatGPT, Midjourney, and DallE have entered some applications like content generation and summarization. However, there are inherent challenges for a lot of tasks that require a deeper understanding of trade-offs like latency, accuracy, and consistency of responses.
Any serious applications of LLMs require an understanding of nuances in how LLMs work, including embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more.
This talk will introduce you to the fundamentals of large language models and their emerging architectures. This video is perfect for anyone who wants to learn more about Large Language Models and how to use LLMs to build real-world applications.
Step 3: Understanding vector similarity search
Traditional keyword-based methods have limitations, leaving us searching for a better way to improve search. But what if we could use deep learning to revolutionize search?
Imagine representing data as vectors, where the distance between vectors reflects similarity, and using Vector Similarity Search algorithms to search billions of vectors in milliseconds. It’s the future of search, and it can transform text, multimedia, images, recommendations, and more.
The challenge of searching today is indexing billions of entries, which makes it vital to learn about vector similarity search. This talk below will help you learn how to incorporate vector search and vector databases into your own applications to harness deep learning insights at scale.
Step 4: Explore the power of embedding with vector search
The total amount of digital data generated worldwide is increasing at a rapid rate. Simultaneously, approximately 80% (and growing) of this newly generated data is unstructured data—data that does not conform to a table- or object-based model.
Examples of unstructured data include text, images, protein structures, geospatial information, and IoT data streams. Despite this, the vast majority of companies and organizations do not have a way of storing and analyzing these increasingly large quantities of unstructured data.
Embeddings—high-dimensional, dense vectors that represent the semantic content of unstructured data can remedy this issue. This makes it significant to learn about embeddings.
The talk below will provide a high-level overview of embeddings, discuss best practices around embedding generation and usage, build two systems (semantic text search and reverse image search), and see how we can put our application into production using Milvus.
Step 5: Discover the key challenges in building LLM applications
As enterprises move beyond ChatGPT, Bard, and ‘demo applications’ of large language models, product leaders and engineers are running into challenges. The magical experience we observe on content generation and summarization tasks using ChatGPT is not replicated on custom LLM applications built on enterprise data.
Enterprise LLM applications are easy to imagine and build a demo out of, but somewhat challenging to turn into a business application. The complexity of datasets, training costs, cost of token usage, response latency, context limit, fragility of prompts, and repeatability are some of the problems faced during product development.
Delve deeper into these challenges with the below talk:
Step 6: Building Your Own ChatGPT
Learn how to build your own ChatGPT or a custom large language model using different AI platforms like Llama Index, LangChain, and more. Here are a few talks that can help you to get started:
Step 7: Learn about Retrieval Augmented Generation (RAG)
Learn the common design patterns for LLM applications, especially the Retrieval Augmented Generation (RAG) framework; What is RAG and how it works, how to use vector databases and knowledge graphs to enhance LLM performance, and how to prioritize and implement LLM applications in your business.
The discussion below will not only inspire organizational leaders to reimagine their data strategies in the face of LLMs and generative AI but also empower technical architects and engineers with practical insights and methodologies.
Step 8: Understanding AI observability
AI observability is the ability to monitor and understand the behavior of AI systems. It is essential for responsible AI, as it helps to ensure that AI systems are safe, reliable, and aligned with human values.
The talk below will discuss the importance of AI observability for responsible AI and offer fresh insights for technical architects, engineers, and organizational leaders seeking to leverage Large Language Model applications and generative AI through AI observability.
>
Step 9: Prevent large language models hallucination
It important to evaluate user interactions to monitor prompts and responses, configure acceptable limits to indicate things like malicious prompts, toxic responses, llm hallucinations, and jailbreak attempts, and set up monitors and alerts to help prevent undesirable behaviour. Tools like WhyLabs and Hugging Face play a vital role here.
The talk below will use Hugging Face + LangKit to effectively monitor Machine Learning and LLMs like GPT from OpenAI. This session will equip you with the knowledge and skills to use LangKit with Hugging Face models.
Step 10: Learn to fine-tune LLMs
Fine-tuning GPT-3.5 Turbo allows you to customize the model to your specific use case, improving performance on specialized tasks, achieving top-tier performance, enhancing steerability, and ensuring consistent output formatting. It important to understand what fine-tuning is, why it’s important for GPT-3.5 Turbo, how to fine-tune GPT-3.5 Turbo for specific use cases, and some of the best practices for fine-tuning GPT-3.5 Turbo.
Whether you’re a data scientist, machine learning engineer, or business user, this talk below will teach you everything you need to know about fine-tuning GPT-3.5 Turbo to achieve your goals and using a fine tuned GPT3.5 Turbo model to solve a real-world problem.
Step 11: Become ChatGPT prompting expert
Learn advanced ChatGPT prompting techniques essential to upgrading your prompt engineering experience. Use ChatGPT prompts in all formats, from freeform to structured, to get the most out of large language models. Explore the latest research on prompting and discover advanced techniques like chain-of-thought, tree-of-thought, and skeleton prompts.
Explore scientific principles of research for data-driven prompt design and master prompt engineering to create effective prompts in all formats.
LLMs have revolutionized natural language processing, offering unprecedented capabilities in text generation, understanding, and analysis. From creative content to data analysis, LLMs are transforming various fields.
By understanding their applications, diving into fundamentals, and mastering techniques, you’re well-equipped to leverage their power. Embark on your LLM journey and unlock the transformative potential of these remarkable language models!
Start learning about LLMs and mastering the skills for tasks that can ease up your business activities.
To learn more about large language models, check out this playlist; from tutorials to crash courses, it is your one-stop learning spot for LLMs and Generative AI.
Artificial Intelligence is evolving at a fast pace, and Large Language Models (LLMs) are at the heart of this transformation. Powerful models like GPT-4 can generate text, answer questions, and even assist in coding. Thus, understanding LLMs is becoming an essential skill.
Learning about them has become increasingly important in today’s rapidly evolving technological landscape. These models are at the forefront of advancements in artificial intelligence and natural language processing. Understanding their capabilities and limitations empowers individuals and professionals across various fields.
But where do you start? LLMs can feel overwhelming, with complex concepts like tokenization, fine-tuning, and prompt engineering.
The good news? YouTube is packed with high-quality educational content to help you grasp these concepts at your own pace.
Why YouTube Channels are a Good Resource?
Research papers, documentation, and textbooks are valuable resources but can be technical and difficult to digest, especially for beginners. That’s where YouTube comes in. It’s one of the best free resources for learning about LLMs, offering a mix of theory, practical tutorials, expert discussions, and real-world applications.
Here’s why YouTube is an excellent platform to kickstart and deepen your understanding of LLMs:
Visual and Hands-On Learning Makes Concepts Easier: LLMs involve complex topics that can feel abstract when explained through text alone. YouTube makes these concepts easier to grasp with visual demonstrations, step-by-step coding tutorials, and engaging animations that break down difficult ideas into digestible chunks.
Learn from AI Experts and Industry Leaders: YouTube provides direct access to leading AI researchers, developers, and engineers who share their expertise for free. Professionals from companies like OpenAI, Google, and Meta regularly post videos covering the latest breakthroughs in AI and real-world applications of LLMs.
Up-to-Date Content on the Rapidly Evolving AI Landscape: While traditional resources can quickly become outdated, YouTube creators continuously upload videos on new LLM models and AI tools. Emerging techniques like Retrieval-Augmented Generation (RAG) and fine-tuning strategies are frequently discussed, ensuring learners always have access to the latest advancements.
Free and Accessible for Everyone: One of YouTube’s greatest advantages is that it is completely free, making AI education accessible to everyone, regardless of their budget. Videos can be watched anywhere, anytime, and at your own pace, allowing learners to pause, rewind, and rewatch as needed.
Covers Every Learning Level – From Beginner to Advanced: YouTube caters to learners of all experience levels. From introductory videos explaining fundamental concepts to coding tutorials, API integrations, and more, YouTube covers it all. This flexibility allows everyone to progress at their own pace and choose content based on their current skills and goals.
Engaging Communities and Interactive Learning: Many AI-focused channels feature comment sections where learners can ask questions, Discord and Slack groups for deeper discussions, and live Q&A sessions with AI experts. This interactive learning environment provides support, motivation, and opportunities to connect with like-minded individuals, making AI education more engaging and collaborative.
These YouTube videos will help you learn large language models
In this blog, we will explore some of the top YouTube channels that cover everything from LLM basics to advanced AI techniques. Whether you’re a beginner or an experienced developer, these channels will help you build, experiment, and stay updated with the latest trends in AI. Let’s dive in!
1. Data Science Dojo: A YouTube Hub for Learning about LLMs
If you are looking to kickstart your learning about LLMs, this is the right place to start. From beginners to experienced AI enthusiasts, this channel will cater to all levels of learners in their journey to learn about LLMs.
Whether you want to understand the basics of LLMs or dive deep into advanced techniques, this channel has something for you. With clear explanations, hands-on tutorials, and expert insights, it covers key topics like Llama Index, LangChain, Redis, Retrieval Augmented Generation, AI observability, and more.
The channel covers a wide range of AI topics, including:
LLM Fundamentals – Learn how models like GPT and BERT process language.
Hands-on Coding Tutorials – Follow step-by-step guides on fine-tuning and deploying LLMs.
Expert Insights – Get valuable knowledge from AI professionals.
Real-World Applications – See how LLMs power chatbots, automation, and text generation.
Data Science Dojo helps you stay updated with the latest trends and techniques with its informative and practical videos, making it easier to apply what you learn. If you’re looking for a structured way to understand and experiment with LLMs, visit and subscribe to Data Science Dojo’s YouTube channel.
Known for its expertise in big data, AI, and machine learning, Databricks offers high-quality videos that break down complex topics into simple, actionable insights. From the basics of foundation models to fundamental concepts, you can find a ton of useful tutorials and talks that can help you get started with LLMs.
Databricks provides a structured approach, helping both beginners and professionals build, fine-tune, and scale AI models efficiently.
The channel covers:
LLM Development – How to train and deploy models like GPT on scalable cloud platforms.
Optimizing AI Workflows – Learn how to use Databricks’ tools to speed up model training.
Real-World Use Cases – See how LLMs are transforming industries like healthcare and finance.
Expert Talks & Demos – Insights from AI leaders and hands-on coding walkthroughs.
Whether you’re fine-tuning models or handling massive datasets, Databricks provides the tools and knowledge you need.
From speech AI, NLP, and deep learning to LLMs, the AssemblyAI channel covers all cutting-edge AI topics to make them easy to understand. It breaks down these complex topics into simple, engaging, and well-explained videos, making it easier for developers, researchers, and AI enthusiasts to stay ahead.
You can learn about Llama Index, vector databases, and LangChain while also exploring how to build your own coding assistant with ChatGPT. Thus, the AssemblyAI channel offers plentiful learning tutorials within the domain of LLMs.
Some key topics covered by the channel include:
LLMs & NLP Fundamentals – Learn how models like GPT and BERT process language.
Speech AI & Transcription Models – Discover how AI converts speech into text with high accuracy.
Building & Optimizing AI Models – Get hands-on guidance for training and deploying models.
AI Industry Insights – Stay updated with the latest advancements in deep learning and AI ethics.
4. FreeCodeCamp: A Free Resource for Learning About LLMs
FreeCodeCamp offers a wide range of tutorials, including how to build LLMs with Python, prompt engineering for web developers, a LangChain course, and more. This channel can help you get started with the basics by providing everything you need to understand, build, and experiment with AI models, and that too without a paywall.
This channel offers:
Beginner to Advanced AI Tutorials – Learn the basics and then move on to fine-tuning models.
Hands-on Coding Lessons – Build and train LLMs using Python, TensorFlow, and PyTorch.
Deep Learning & NLP Courses – Understand how models like GPT, BERT, and LLaMA work.
If you’re looking for straightforward and practical insights into LLMs, the Matthew Berman YouTube channel is a great place to start. His content focuses on AI, machine learning, and coding, making complex topics easy to understand.
From artificial intelligence to generative art, this channel sheds light on several significant areas, including AI art, ChatGPT, LLMs, machine learning, technology, and coding. Some key areas it covers include:
LLM Basics & Fundamentals – Understand how models like GPT work.
Practical AI Tutorials – Hands-on coding sessions to build and train LLMs.
Fine-Tuning & Deployment – Learn how to customize AI models for specific tasks.
AI Tools & Best Practices – Get tips on working efficiently with LLMs.
6. IBM Technology: Exploring LLMs with Industry Experts
IBM has been a leader in AI research, cloud computing, and data science, making this channel a valuable resource for learning about technological advancements like LLMs and their real-world applications.
The channel includes several talks and tutorials pertaining to machine learning and generative AI. From useful tutorials like building a chatbot with AI to insightful talks like the rise of generative AI, it can help you navigate your learning path.
Some key aspects of the channel include:
LLM Fundamentals & Development – Understand how IBM integrates AI into business solutions.
AI Ethics & Responsible AI – Learn about fairness, bias, and security in LLMs.
Watson & AI-Powered Tools – See how IBM’s AI models are applied in different industries.
7. Yannic Kilcher: Deep Dives into LLMs and AI Research
Yannic specializes in breaking down AI papers, machine learning concepts, and cutting-edge research, making complex ideas easier to grasp. His videos make academic research more accessible to AI enthusiasts and professionals.
From detailed talks to short tutorials, this channel offers a number of resources to learn about LLMs. For instance, it covers ideas around Llama 2, ReST for language modeling, retentive networks, and more to assist you in building your LLM knowledge base.
It covers:
LLM Research & Innovations – Breakdown of the latest AI papers and advancements.
Model Architectures – Deep dives into how GPT, BERT, and other models are built.
AI Ethics & Controversies – Discussions on bias, alignment, and responsible AI.
Hands-on AI Experiments – Testing AI models and showcasing real-world applications.
Unlike purely theoretical channels, Nicholas dives straight into coding. His step-by-step tutorials help you train, fine-tune, and deploy AI models, making complex topics feel simple. Whether you’re a beginner or an experienced developer, his videos provide clear, actionable guidance.
Nicholas shares practical ways to get started with data science, machine learning, and deep learning using a bunch of different tools but mainly Python and Javascript. The channel includes many useful talks, like breaking down the generative AI stack, building an AutoGPT, and using Llama 2 70B to rebuild GPT Banker.
This channel covers:
Hands-on AI Projects – Build chatbots, text generators, and other AI-powered tools.
Fine-Tuning & Deployment – Learn how to customize and optimize LLMs.
AI & ML Workflows – Explore how AI fits into real-world applications.
With clear, concise, and insightful discussions on LLMs, Eye on Tech is a great resource to learn and stay updated on the latest technological trends. It focuses on the latest business technology and IT topics, including AI, DevOps, security, networking, cloud, storage, and more.
This channel covers a number of useful talks, like the introduction to foundation models, AI buzzwords, conversational AI versus generative AI, and more that can help you get started with the basics. Some key features covered in the videos are:
AI in Business & Tech – See how companies use LLMs for automation and efficiency.
Industry Trends & Innovations – Stay ahead with the latest AI developments.
Tech Explainers & Insights – Get expert opinions on the future of AI and machine learning.
Large language models (LLMs) are a type of artificial intelligence (AI) model that can generate and understand text. They are trained on massive datasets of text and code, which allows them to learn the statistical relationships between words and phrases.
The field of LLMs is rapidly growing, and new models are being developed all the time. In recent years, there have been a number of breakthroughs in LLM technology, including:
The development of new training algorithms that allow LLMs to be trained on much larger datasets than ever before.
The development of new hardware architectures that can support the training and inference of LLMs more efficiently.
The release of open-source models has made LLMs more accessible to researchers and developers.
As a result of these advances, LLMs are becoming increasingly powerful and capable. By understanding LLMs, you can position yourself to take advantage of the opportunities that they create. You can also explore Data Science Dojo’s LLM Bootcamp and learn to build your own LLM applications.
Probability distributions are fundamental to data science, influencing the ways in which we analyze and interpret data. They offer a systematic approach to modeling uncertainty, facilitating predictions, and extracting insights from real-world events.
Whether it’s understanding customer behavior or refining machine learning models, probability distributions are crucial in the decision-making process. In this blog, we will delve into nine fundamental probability distributions commonly used in data science
Whether you’re new to the field or a seasoned data scientist, gaining expertise in these distributions will significantly improve your data analysis skills. In the realm of data science, understanding probability distributions is crucial. They provide a mathematical framework for modeling and analyzing data.
Explore Probability Distributions in Data Science with Practical Applications
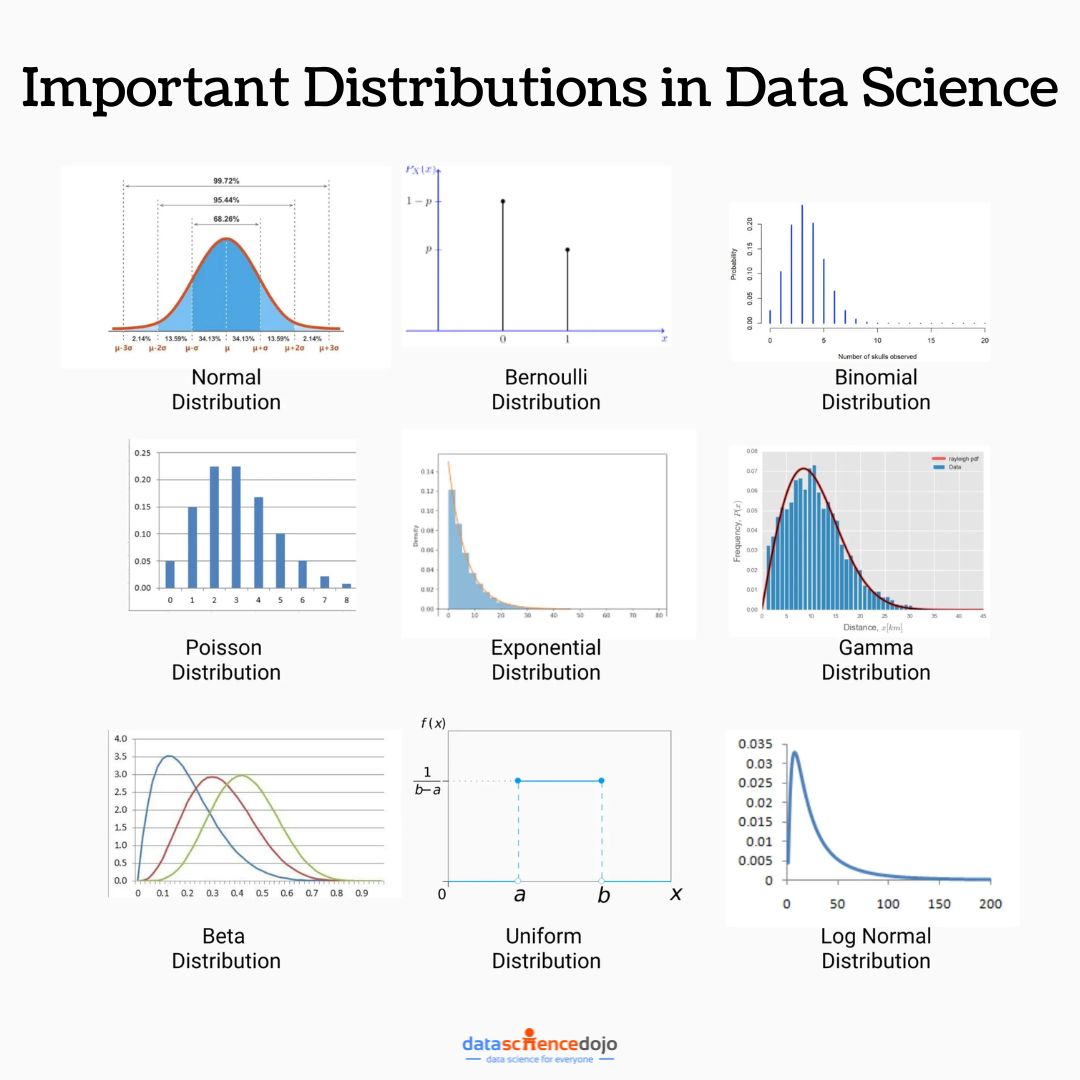
Following are the nine important data science distributions and their practical applications:
1. Normal Distribution
The normal distribution, characterized by its bell-shaped curve, is prevalent in various natural phenomena. For instance, IQ scores in a population tend to follow a normal distribution. This allows psychologists and educators to understand the distribution of intelligence levels and make informed decisions regarding education programs and interventions.
Heights of adult males in a given population often exhibit a normal distribution. In such a scenario, most men tend to cluster around the average height, with fewer individuals being exceptionally tall or short.
This means that the majority fall within one standard deviation of the mean, while a smaller percentage deviates further from the average.
2. Binomial Distribution
The binomial distribution describes the number of successes in a fixed number of Bernoulli trials. Imagine conducting 10 coin flips and counting the number of heads. This scenario follows a binomial distribution. In practice, this distribution is used in fields like manufacturing, where it helps in estimating the probability of defects in a batch of products.
Imagine a basketball player with a 70% free throw success rate. If this player attempts 10 free throws, the number of successful shots follows a binomial distribution. This distribution allows us to calculate the probability of making a specific number of successful shots out of the total attempts.
3. Bernoulli Distribution
The Bernoulli distribution models a random variable with two possible outcomes: success or failure. Consider a scenario where a coin is tossed. Here, the outcome can be either a head (success) or a tail (failure). This distribution finds application in various fields, including quality control, where it’s used to assess whether a product meets a specific quality standard.
When flipping a fair coin, the outcome of each flip can be modeled using a Bernoulli distribution. This distribution is aptly suited as it accounts for only two possible results – heads or tails. The probability of success (getting a head) is 0.5, making it a fundamental model for simple binary events.
4. Poisson Distribution
The Poisson distribution models the number of events occurring in a fixed interval of time or space, assuming a constant rate. For example, in a call center, the number of calls received in an hour can often be modeled using a Poisson distribution. This information is crucial for optimizing staffing levels to meet customer demands efficiently.
Learn about 5 tips to enhance customer service using data science
In the context of a call center, the number of incoming calls over a given period can often be modeled using a Poisson distribution. This distribution is applicable when events occur randomly and are relatively rare, like calls to a hotline or requests for customer service during specific hours.
5. Exponential Distribution
The exponential distribution represents the time until a continuous, random event occurs. In the context of reliability engineering, this distribution is employed to model the lifespan of a device or system before it fails. This information aids in maintenance planning and ensuring uninterrupted operation.
The time intervals between successive earthquakes in a certain region can be accurately modeled by an exponential distribution. This is especially true when these events occur randomly over time, but the probability of them happening in a particular time frame is constant.
6. Gamma Distribution
The gamma distribution extends the concept of the exponential distribution to model the sum of k independent exponential random variables. This distribution is used in various domains, including queuing theory, where it helps in understanding waiting times in systems with multiple stages.
Consider a scenario where customers arrive at a service point following a Poisson process, and the time it takes to serve them follows an exponential distribution. In this case, the total waiting time for a certain number of customers can be accurately described using a gamma distribution. This is particularly relevant for modeling queues and wait times in various service industries.
7. Beta Distribution
The beta distribution is a continuous probability distribution bound between 0 and 1. It’s widely used in Bayesian statistics to model probabilities and proportions. In marketing, for instance, it can be applied to optimize conversion rates on a website, allowing businesses to make data-driven decisions to enhance user experience.
In the realm of A/B testing, the conversion rate of users interacting with two different versions of a webpage or product is often modeled using a beta distribution. This distribution allows analysts to estimate the uncertainty associated with conversion rates and make informed decisions regarding which version to implement.
8. Uniform Distribution
In a uniform distribution, all outcomes have an equal probability of occurring. A classic example is rolling a fair six-sided die. In simulations and games, the uniform distribution is used to model random events where each outcome is equally likely.
When rolling a fair six-sided die, each outcome (1 through 6) has an equal probability of occurring. This characteristic makes it a prime example of a discrete uniform distribution, where each possible outcome has the same likelihood of happening.
Get started with your data science learning journey with our instructor-led live bootcamp. Explore now.
9. Log Normal Distribution
The log normal distribution describes a random variable whose logarithm is normally distributed. In finance, this distribution is applied to model the prices of financial assets, such as stocks. Understanding the log normal distribution is crucial for making informed investment decisions.
The distribution of wealth among individuals in an economy often follows a log-normal distribution. This means that when the logarithm of wealth is considered, the resulting values tend to cluster around a central point, reflecting the skewed nature of wealth distribution in many societies.
Learn Probability Distributions Today!
Understanding these distributions and their applications empowers data scientists to make informed decisions and build accurate models. Remember, the choice of distribution greatly impacts the interpretation of results, so it’s a critical aspect of data analysis.
Delve deeper into probability with this short tutorial
Final Thoughts
Getting a solid grasp of probability distributions is key to making sense of data and creating reliable models in data science. Each type of distribution has its own unique role—whether it’s capturing natural patterns with the normal distribution or forecasting rare occurrences with the Poisson distribution.
By mastering these tools, data scientists can make smarter decisions, fine-tune algorithms, and improve real-world outcomes.
As you dive deeper into your data science journey, keep exploring these distributions and how they’re applied in practice. The more you understand them, the stronger and more impactful your data-driven insights will become!
In today’s data-driven world, visual storytelling plays a crucial role in making sense of complex information—and that’s where plots in data science become indispensable. Whether you’re analyzing customer behavior, monitoring system performance, or presenting business intelligence reports, plots in data science help transform raw data into clear, actionable insights.
These visual tools allow data scientists to explore patterns, detect anomalies, and communicate findings with clarity and impact. From basic line charts to advanced scatter plots and heatmaps, plots in data science serve as the foundation for effective data visualization.
This blog will explore the most commonly used plots in data science, guiding you through their applications, best practices, and how to choose the right plot for your analysis. Whether you’re just starting your data science journey or refining your visualization toolkit, understanding these plots will significantly enhance the way you interpret and present data.
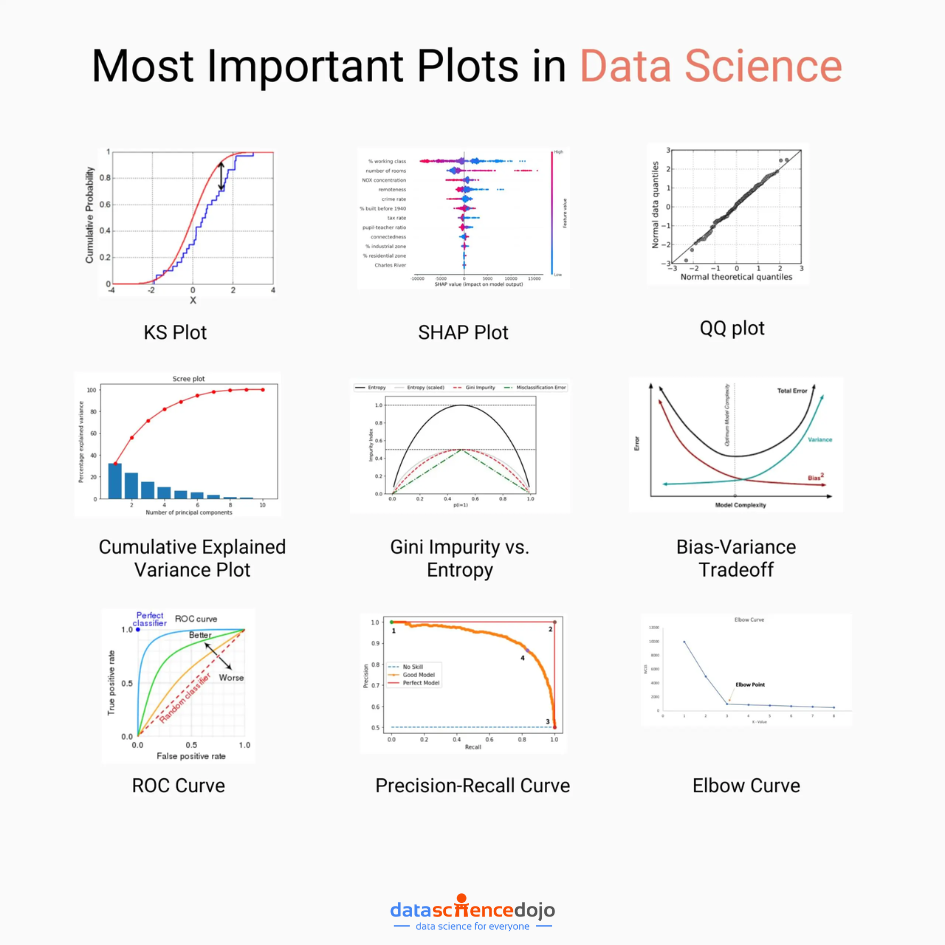
1. KS Plot (Kolmogorov-Smirnov Plot):
The KS Plot is a powerful tool for comparing two probability distributions. It measures the maximum vertical distance between the cumulative distribution functions (CDFs) of two datasets. This plot is particularly useful for tasks like hypothesis testing, anomaly detection, and model evaluation.
Suppose you are a data scientist working for an e-commerce company. You want to compare the distribution of purchase amounts for two different marketing campaigns. By using a KS Plot, you can visually assess if there’s a significant difference in the distributions. This insight can guide future marketing strategies.
2. SHAP Plot:
SHAP plots offer an in-depth understanding of the importance of features in a predictive model. They provide a comprehensive view of how each feature contributes to the model’s output for a specific prediction. SHAP values help answer questions like, “Which features influence the prediction the most?”
Imagine you’re working on a loan approval model for a bank. You use a SHAP plot to explain to stakeholders why a certain applicant’s loan was approved or denied. The plot highlights the contribution of each feature (e.g., credit score, income) in the decision, providing transparency and aiding in compliance.
3. QQ Plot:
The QQ plot is a visual tool for comparing two probability distributions. It plots the quantiles of the two distributions against each other, helping to assess whether they follow the same distribution. This is especially valuable in identifying deviations from normality.
In a medical study, you want to check if a new drug’s effect on blood pressure follows a normal distribution. Using a QQ Plot, you compare the observed distribution of blood pressure readings post-treatment with an expected normal distribution. This helps in assessing the drug’s effectiveness.
4. Cumulative Explained Variance Plot:
In the context of Principal Component Analysis (PCA), this plot showcases the cumulative proportion of variance explained by each principal component. It aids in understanding how many principal components are required to retain a certain percentage of the total variance in the dataset.
Let’s say you’re working on a face recognition system using PCA. The cumulative explained variance plot helps you decide how many principal components to retain to achieve a desired level of image reconstruction accuracy while minimizing computational resources.
Explore, analyze, and visualize data using Power BI Desktop to make data-driven business decisions. Check out our Introduction to Power BI cohort.
5. Gini Impurity vs. Entropy:
These plots are critical in the field of decision trees and ensemble learning. They depict the impurity measures at different decision points. Gini impurity is faster to compute, while entropy provides a more balanced split. The choice between the two depends on the specific use case.
Suppose you’re building a decision tree to classify customer feedback as positive or negative. By comparing Gini impurity and entropy at different decision nodes, you can decide which impurity measure leads to a more effective splitting strategy for creating meaningful leaf nodes.
6. Bias-Variance Tradeoff:
Understanding the tradeoff between bias and variance is fundamental in machine learning. This concept is often visualized as a curve, showing how the total error of a model is influenced by its bias and variance. Striking the right balance is crucial for building models that generalize well.
Imagine you’re training a model to predict housing prices. If you choose a complex model (e.g., deep neural network) with many parameters, it might overfit the training data (high variance). On the other hand, if you choose a simple model (e.g., linear regression), it might underfit (high bias). Understanding this tradeoff helps in model selection.
7. ROC Curve:
The ROC curve is a staple in binary classification tasks. It illustrates the tradeoff between the true positive rate (sensitivity) and false positive rate (1 – specificity) for different threshold values. The area under the ROC curve (AUC-ROC) quantifies the model’s performance.
In a medical context, you’re developing a model to detect a rare disease. The ROC curve helps you choose an appropriate threshold for classifying individuals as positive or negative for the disease. This decision is crucial as false positives and false negatives can have significant consequences.
Want to get started with data science? Check out our instructor-led live Data Science Bootcamp.
8. Precision-Recall curve:
Especially useful when dealing with imbalanced datasets, the precision-recall curve showcases the tradeoff between precision and recall for different threshold values. It provides insights into a model’s performance, particularly in scenarios where false positives are costly.
Let’s say you’re working on a fraud detection system for a bank. In this scenario, correctly identifying fraudulent transactions (high recall) is more critical than minimizing false alarms (low precision). A precision-recall curve helps you find the right balance.
9. Elbow Curve:
In unsupervised learning, particularly clustering, the elbow curve aids in determining the optimal number of clusters for a dataset. It plots the variance explained as a function of the number of clusters. The “elbow point” is a good indicator of the ideal cluster count.
You’re tasked with clustering customer data for a marketing campaign. By using an elbow curve, you can determine the optimal number of customer segments. This insight informs personalized marketing strategies and improves customer engagement.
Improvise Your Models Today with Plots in Data Science!
These plots in data science are the backbone of your data. Incorporating them into your analytical toolkit will empower you to extract meaningful insights, build robust models, and make informed decisions from your data. Remember, visualizations are not just pretty pictures; they are powerful tools for understanding the underlying stories within your data.
Check out this crash course in data visualization, it will help you gain great insights so that you become a data visualization pro:
GitHub is a goldmine for developers, data scientists, and engineers looking to sharpen their skills and explore new technologies. With thousands of open-source repositories available, it can be overwhelming to find the most valuable ones.
In this blog, we highlight some of the best trending GitHub repositories in data science, analytics, and engineering. Whether you’re looking for machine learning frameworks, data visualization tools, or coding resources, these repositories can help you learn faster, work smarter, and stay ahead in the tech world. Let’s dive in!
What is GitHub?
Before exploring the top repositories, we should first understand what GitHub is and why it’s so important for developers and data scientists.
GitHub is an online platform that allows people to store, share, and collaborate on code. It works as a version control system, meaning you can track changes, revert to previous versions, and work on projects with teams seamlessly. Built on Git, an open-source version control tool, GitHub makes it easier to manage coding projects—whether you’re working alone or with a team.
One of the best things about GitHub is its massive collection of open-source repositories. Developers from around the world share their code, tools, and frameworks, making it a go-to platform for learning, innovation, and collaboration. Whether you’re looking for AI models, data science projects, or web development frameworks, GitHub has something for everyone.
Best GitHub Repositories to Stay Ahead of the Tech Curve
Now that we understand what GitHub is and why it’s a goldmine for developers, let’s dive into the repositories that can truly make a difference. The right repositories can save time, improve coding efficiency, and introduce you to cutting-edge technologies. Whether you’re looking for AI frameworks, automation tools, or coding best practices, these repositories will help you stay ahead of the tech curve and keep your skills sharp.
1. Scikit-learn: A Python library for machine learning built on top of NumPy, SciPy, and matplotlib. It provides a range of algorithms for classification, regression, clustering, and more.
2.TensorFlow: An open-source machine learning library developed by Google Brain Team. TensorFlow is used for numerical computation using data flow graphs.
3.Keras: A deep learning library for Python that provides a user-friendly interface for building neural networks. It can run on top of TensorFlow, Theano, or CNTK.
5.PyTorch: An open-source machine learning library developed by Facebook’s AI research group. PyTorch provides tensor computation and deep neural networks on a GPU.
6.Apache Spark: An open-source distributed computing system used for big data processing. It can be used with a range of programming languages such as Python, R, and Java.
7.FastAPI: A modern web framework for building APIs with Python. It is designed for high performance, asynchronous programming, and easy integration with other libraries.
9.Matplotlib: A Python plotting library that provides a range of 2D plotting features. It can be used for creating interactive visualizations, animations, and more.
11.NumPy: A Python library for numerical computing that provides a range of array and matrix operations. It is used extensively in scientific computing and data analysis.
12.Tidyverse: A collection of R packages for data manipulation, visualization, and analysis. It includes popular packages such as ggplot2, dplyr, and tidyr.
Now that you know the value of GitHub and some of the best repositories to explore, the next step is learning how to contribute. Open-source projects thrive on collaboration, and contributing to them is a great way to improve your coding skills, gain real-world experience, and connect with the developer community. Here’s a step-by-step guide to getting started:
1. Find a Repository to Contribute To
Look for repositories that align with your interests and expertise. You can start by browsing GitHub’s Explore section or checking issues labeled “good first issue” or “help wanted” in open-source projects.
2. Fork the Repository
Forking creates a copy of the original repository in your own GitHub account. This allows you to make changes without affecting the original project. To do this, simply click the Fork button on the repository page, and a copy will appear in your GitHub profile.
3. Clone the Repository
Once you have forked the repository, you need to download it to your local computer so you can work on it. This process is called cloning. It allows you to edit files and test changes before submitting them back to the original project.
4. Create a New Branch
Before making any changes, it’s best practice to create a new branch. This keeps your updates separate from the main code, making it easier to manage and review. Naming your branch based on the feature or fix you’re working on helps maintain organization.
5. Make Your Changes
Now, you can edit the code, fix bugs, or add new features. Be sure to follow any contribution guidelines provided in the repository, write clear code, and test your changes thoroughly.
Once you’re satisfied with your updates, you need to save them. In GitHub, this process is called committing. A commit is like a snapshot of your work, and it should include a short, meaningful message explaining what changes you made.
7. Push Your Changes to GitHub
After committing your updates, you need to send them back to your forked repository on GitHub. This ensures your changes are saved online and can be accessed when submitting a contribution.
8. Create a Pull Request (PR)
A pull request is how you ask the maintainers of the original repository to review and merge your changes. When creating a pull request, provide a clear title and description of what you’ve updated and why it’s beneficial to the project.
9. Collaborate and Make Changes if Needed
The project maintainers will review your pull request. They might approve it right away or request modifications. Be open to feedback and make any necessary adjustments before your contribution is merged.
10. Celebrate Your Contribution!
Once your pull request is merged, congratulations—you’ve successfully contributed to an open-source project! Keep exploring and contributing to more repositories to continue learning and growing as a developer.
Final Thoughts
GitHub is more than just a code-sharing platform—it’s a hub for innovation, learning, and collaboration. The repositories we’ve highlighted can help you stay ahead in the ever-evolving tech world, whether you’re exploring AI, data science, or software development. By engaging with these open-source projects, you can sharpen your skills, contribute to the community, and keep up with the latest industry trends. So, start exploring, experimenting, and leveling up your expertise with these powerful GitHub repositories!