
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as Big Data, encompasses information from various sources, including social media interactions, online transactions, sensor data, and more.
The sheer volume and variety of Big Data present immense potential for organizations to gain valuable insights, make data-driven decisions, and uncover patterns that were once hidden.

Understanding Big Data Engineering
Big Data and its Characteristics (Volume, Velocity, Variety, Veracity)
Big Data refers to the enormous volume of data that is generated at a high velocity from diverse sources, including structured and unstructured data. Its characteristics can be summarized as follows:
- Volume: Big Data involves datasets that are too large to be processed by traditional database management systems. These datasets can range from terabytes to petabytes and beyond.
- Velocity: The speed at which Big Data is generated and collected is often rapid. Streaming data from various sources, such as social media or IoT devices, requires real-time processing.
- Variety: Big Data comes in various formats, including structured data (e.g., databases), semi-structured data (e.g., XML, JSON), and unstructured data (e.g., text, images, videos). Processing such diverse data types poses a challenge.
- Veracity: The reliability and accuracy of Big Data can vary significantly, as it may contain noise, inconsistencies, and errors.
- Processing Speed: As the data volume and velocity increase, processing times become unacceptably long, leading to delays in insights and decision-making.
- Scalability: Traditional systems may not scale effectively to handle the growing data size and user demands.
- Data Variety: Single-server setups often struggle to accommodate and process different data types effectively.
- Fault Tolerance: With larger datasets, the likelihood of hardware failures or software issues increases, making fault tolerance critical.
Read more –> Big data problem, its impact, and a possible solution for it
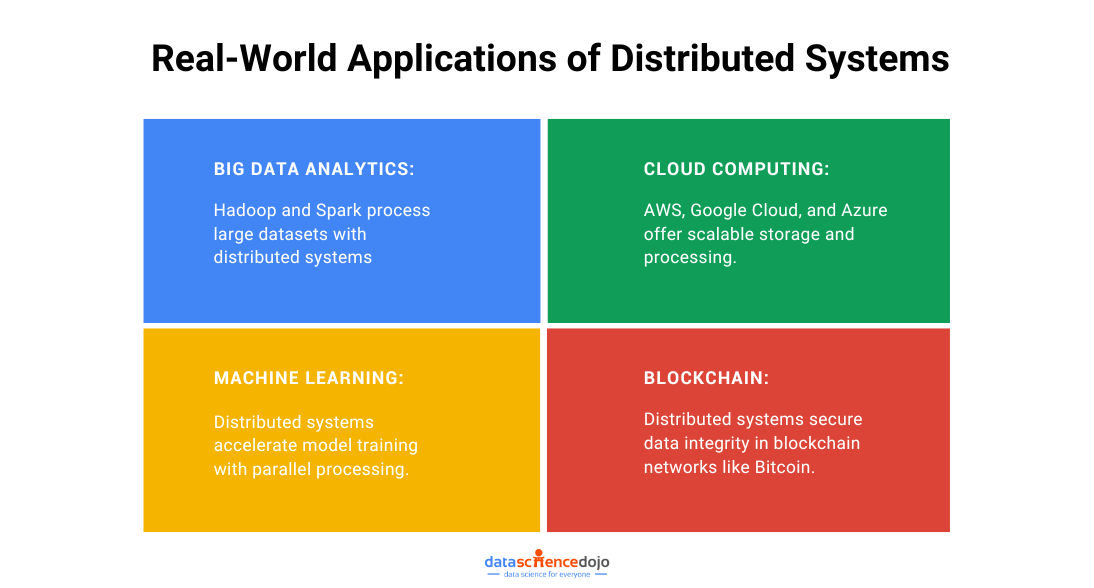
Big Data Engineering is the discipline that focuses on designing, building, and maintaining systems and solutions to process, store, and analyze massive datasets. It involves various technologies and techniques that enable efficient data processing and retrieval. Distributed Systems play a crucial role in Big Data Engineering by breaking down data processing tasks into smaller sub-tasks, distributing them across multiple machines, and reassembling the results for analysis.
In the next sections of this blog, we will delve deeper into the technical aspects of Distributed Systems in Big Data Engineering, showcasing code snippets to illustrate how these systems work in practice. Stay tuned for an insightful exploration into the world of Big Data Engineering with Distributed Systems!
Distributed Systems, as the name suggests, are a network of interconnected computers that work together to achieve a common goal. In the context of Big Data Engineering, distributed systems play a crucial role in handling the massive scale of data processing and storage. The core principles of distributed systems are:
- Decentralization: Distributed Systems do not rely on a single centralized server; instead, they distribute data and processing tasks across multiple nodes.
- Scalability: Distributed Systems are designed to scale horizontally by adding more machines to the network, enabling them to handle increasing data loads.
- Fault Tolerance: Distributed Systems are built to be resilient to hardware failures or network issues. They use redundancy and replication to ensure data availability.
- Consistency: Maintaining data consistency across distributed nodes is a fundamental challenge in these systems. Different algorithms and techniques are employed to achieve eventual consistency.
Key Components of Distributed Systems
- Nodes: Nodes are individual machines or servers that form the building blocks of a distributed system. Each node is capable of processing and storing data independently.
- Clusters: Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes.
- Fault-tolerance: Distributed Systems incorporate fault tolerance mechanisms to ensure data availability even in the face of node failures. Data replication and redundant storage help achieve fault tolerance.
- Distributed File Systems: Distributed Systems often rely on distributed file systems to manage data storage across nodes and ensure efficient data access and retrieval.
Hadoop Distributed File System (HDFS):
HDFS is a distributed file system designed to store vast amounts of data across multiple nodes in a Hadoop cluster. It provides fault tolerance and high throughput for Big Data storage and processing.
Amazon S3
Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS). It allows organizations to store and retrieve any amount of data, making it popular for storing and managing Big Data in the cloud.
Google Cloud Storage
Similar to Amazon S3, Google Cloud Storage provides object storage with high availability, global accessibility, and strong data consistency. It is widely used for Big Data storage and analysis on the Google Cloud Platform.
Replication and Data Redundancy
One of the key advantages of using distributed data storage is the implementation of data replication and redundancy. Data is replicated across multiple nodes to ensure fault tolerance and high availability. If a node fails, the data can still be accessed from other replicated copies, minimizing the risk of data loss and system downtime.
Another interesting read: 10 Vs of Big Data
Real-Time Data Streaming and Batch Processing for Storage Optimization
Distributed data storage solutions support both real-time data streaming and batch processing. Real-time streaming allows data to be ingested and processed in real time, enabling organizations to gain insights from data as it is generated. On the other hand, batch processing allows for the processing of large volumes of data at once, optimizing storage and reducing the need for constant data retrieval.
Incorporating distributed data storage technologies into Big Data Engineering enables organizations to efficiently manage and store massive datasets, ensuring fault tolerance, scalability, and real-time data processing capabilities. The combination of distributed systems and distributed data storage forms the backbone of modern Big Data infrastructure, powering data-driven insights and innovations across various industries.

Distributed Data Processing: Understanding MapReduce
MapReduce is a programming model and processing paradigm that plays a significant role in distributed data processing. It was popularized by Google and has become a fundamental technique for handling large-scale data operations. The MapReduce model breaks down complex tasks into two main phases:
- Map Phase: In this phase, data is divided into smaller chunks and processed in parallel by multiple nodes. Each node applies a “map” function to the data, producing a set of key-value pairs as intermediate outputs.
- Reduce Phase: The intermediate outputs from the Map phase are then grouped by their keys and passed to the “reduce” function. The reduced function aggregates and processes the data further, producing the final output.
The MapReduce model is particularly suitable for data-intensive tasks like data cleaning, transformation, and aggregation. It provides fault tolerance by automatically re-executing failed tasks and is highly scalable due to its parallel processing capabilities.
Example Python code snippet using MapReduce:
Apache Spark
Apache Spark is an open-source distributed computing system that provides an alternative to the MapReduce model. Spark offers a more flexible and memory-resilient approach, allowing for iterative data processing and in-memory caching, which significantly improves performance.
Spark provides a high-level API in multiple languages like Scala, Python, Java, and SQL, making it accessible to a wide range of developers. It supports various data processing operations, including batch processing, real-time stream processing, machine learning, and graph processing.
Example Python code snippet using Apache Spark:
Parallel Processing
In distributed data processing, parallel processing is the key to efficient utilization of resources. By dividing tasks across multiple nodes, it allows for simultaneous data processing, reducing overall execution time.
Data shuffling is a crucial aspect of distributed processing when data needs to be reorganized and redistributed among nodes. It often occurs during the data exchange between the Map and Reduce phases in MapReduce. While data shuffling enables parallel processing, it can also be a performance bottleneck if not managed efficiently.
To optimize data shuffling, distributed systems use techniques like data partitioning, compression, and data locality. These techniques ensure that data is moved and processed as efficiently as possible, minimizing network overhead and improving overall performance.

Stream Processing with Distributed Systems
Stream processing is a data processing technique that involves real-time data ingestion, analysis, and action on data as it flows through the system. Unlike traditional batch processing, where data is processed in fixed intervals, stream processing enables organizations to gain insights and respond to events as they happen in real time.
In Big Data Engineering, stream processing finds numerous applications, including:
- Real-time Analytics: Organizations can monitor and analyze data streams to derive immediate insights, enabling faster decision-making and better business outcomes.
- Fraud Detection: Stream processing allows the identification of fraudulent activities in real time, helping prevent financial losses and ensuring data security.
- Internet of Things (IoT) Data Processing: Stream processing is vital for handling continuous data streams from IoT devices, enabling real-time monitoring and control.
Apache Flink for stream processing:
Wrapping Up
In conclusion, stream processing with distributed systems like Apache Kafka, Apache Flink, and Apache Spark Streaming empowers organizations to harness real-time data insights, enabling timely decision-making and enhanced user experiences. By integrating stream processing into their Big Data Engineering pipelines, companies can stay at the forefront of innovation and address evolving customer demands effectively.