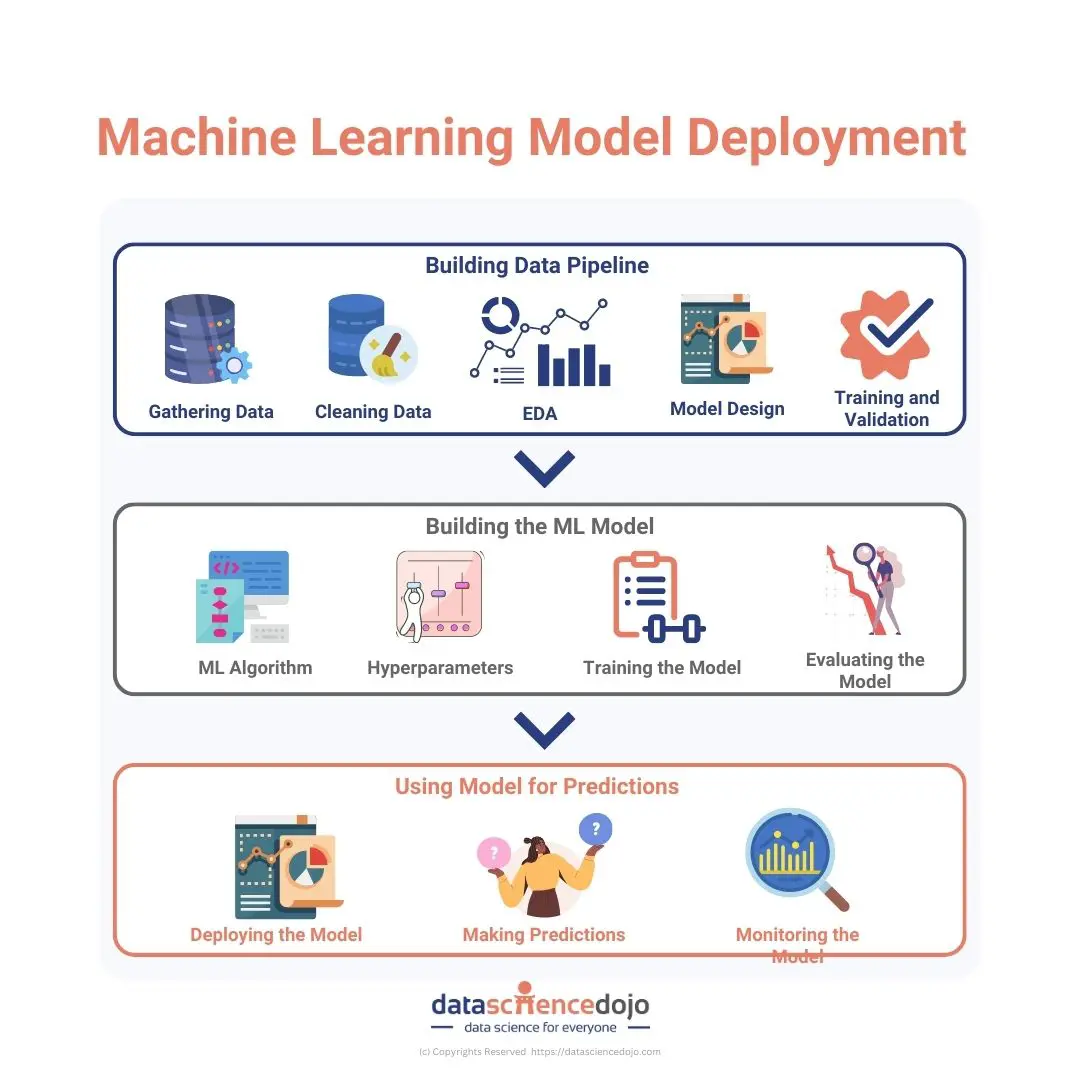
Machine learning models are algorithms designed to identify patterns and make predictions or decisions based on data. These models are trained using historical data to recognize underlying patterns and relationships. Once trained, they can be used to make predictions on new, unseen data.
Modern businesses are embracing machine learning (ML) models to gain a competitive edge. It enables them to personalize customer experience, detect fraud, predict equipment failures, and automate tasks. Hence, improving the overall efficiency of the business and allow them to make data-driven decisions.
Deploying ML models in their day-to-day processes allows businesses to adopt and integrate AI-powered solutions into their businesses. Since the impact and use of AI are growing drastically, it makes ML models a crucial element for modern businesses.
Here’s a step-by-step guide to deploying ML in your business
A PwC study on Global Artificial Intelligence states that the GDP for local economies will get a boost of 26% by 2030 due to the adoption of AI in businesses. This reiterates the increasing role of AI in modern businesses and consequently the need for ML models.

However, deploying ML models in businesses is a complex process and it requires proper testing methods to ensure successful deployment. In this blog, we will explore the 4 main methods to test ML models in the production phase.
What is Machine Learning Model Testing?
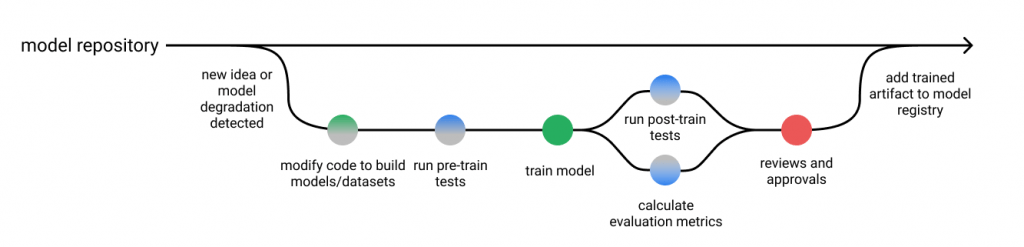
In the context of machine learning, model testing refers to a detailed process to ensure that it is robust, reliable, and free from biases. Each component of an ML model is verified, the integrity of data is checked, and the interaction among components is tested.
The main objective of model testing is to identify and fix flaws or vulnerabilities in the ML system. It aims to ensure that the model can handle unexpected inputs, mitigate biases, and remain consistent and robust in various scenarios, including real-world applications.
It is also important to note that ML model testing is different from model evaluation. Both are different processes and before we explore the different testing methods, let’s understand the difference between machine learning model evaluation and testing.
What is the Difference between Model Evaluation and Testing?
A quick overview of the basic difference between model evaluation and model testing is as follows:
| Aspect | Model Evaluation | Model Testing |
|---|---|---|
| Focus | Overall performance | Detailed component analysis |
| Metrics | Accuracy, Precision, Recall, RMSE, AUC-ROC | Code, Data, and Model behavior |
| Objective | Monitor performance, compare models | Identify and fix flaws, ensure robustness |
| Process | Split dataset, train, and evaluate | Unit tests, regression tests, integration tests |
| Use Cases | Algorithm comparison, hyperparameter tuning, performance summary | Bias detection, robustness checks, consistency verification |
From the above-mentioned details it can be concluded that while model evaluation gives a snapshot of how well a model performs, model testing ensures the model’s reliability, robustness, and fairness in real-world applications. Thus, it is important to test a machine learning model in its production to ensure its effectiveness and efficiency.
Explore this list of 9 free ML courses to get you started
Frameworks Used in ML Model Testing
Since testing ML models is a very important task, it requires a thorough and efficient approach. Multiple frameworks in the market offer pre-built tools, enforce structured testing, provide diverse testing functionalities, and promote reproducibility. It results in faster and more reliable testing for robust models.

Here’s a list of key frameworks used for ML model testing.
TensorFlow
There are three main types of TensorFlow frameworks for testing:
- TensorFlow Extended (TFX): This is designed for production pipeline testing, offering tools for data validation, model analysis, and deployment. It provides a comprehensive suite for defining, launching, and monitoring ML models in production.
- TensorFlow Data Validation: Useful for testing data quality in ML pipelines.
- TensorFlow Model Analysis: Used for in-depth model evaluation.
PyTorch
Known for its dynamic computation graph and ease of use, PyTorch provides model evaluation, debugging, and visualization tools. The torchvision package includes datasets and transformations for testing and validating computer vision models.
Scikit-learn
Scikit-learn is a versatile Python library that offers various algorithms and model evaluation metrics, including cross-validation and grid search for hyperparameter tuning. It is widely used for data mining, analysis, and machine learning tasks.
Read more about the top 6 python libraries for data science
Fairlearn
Fairlearn is a toolkit designed to assess and mitigate fairness and bias issues in ML models. It includes algorithms to reweight data and adjust predictions to achieve fairness, ensuring that models treat all individuals fairly and equitably.
Evidently AI
Evidently AI is an open-source Python tool that is used to analyze, monitor, and debug machine learning models in a production environment. It helps implement testing and monitoring for different model types and data types.
Amazon SageMaker Model Monitor
Amazon SageMaker is a tool that can alert developers of any deviations in model quality so that corrective actions can be taken. It supports no-code monitoring capabilities and custom analysis through coding.
These frameworks provide a comprehensive approach to testing machine learning models, ensuring they are reliable, fair, and well-performing in production environments.
4 Ways to Test ML Models in Production
Now that we have explored the basics of ML model testing, let’s look at the 4 main testing methods for ML models in their production phase.
1. A/B Testing
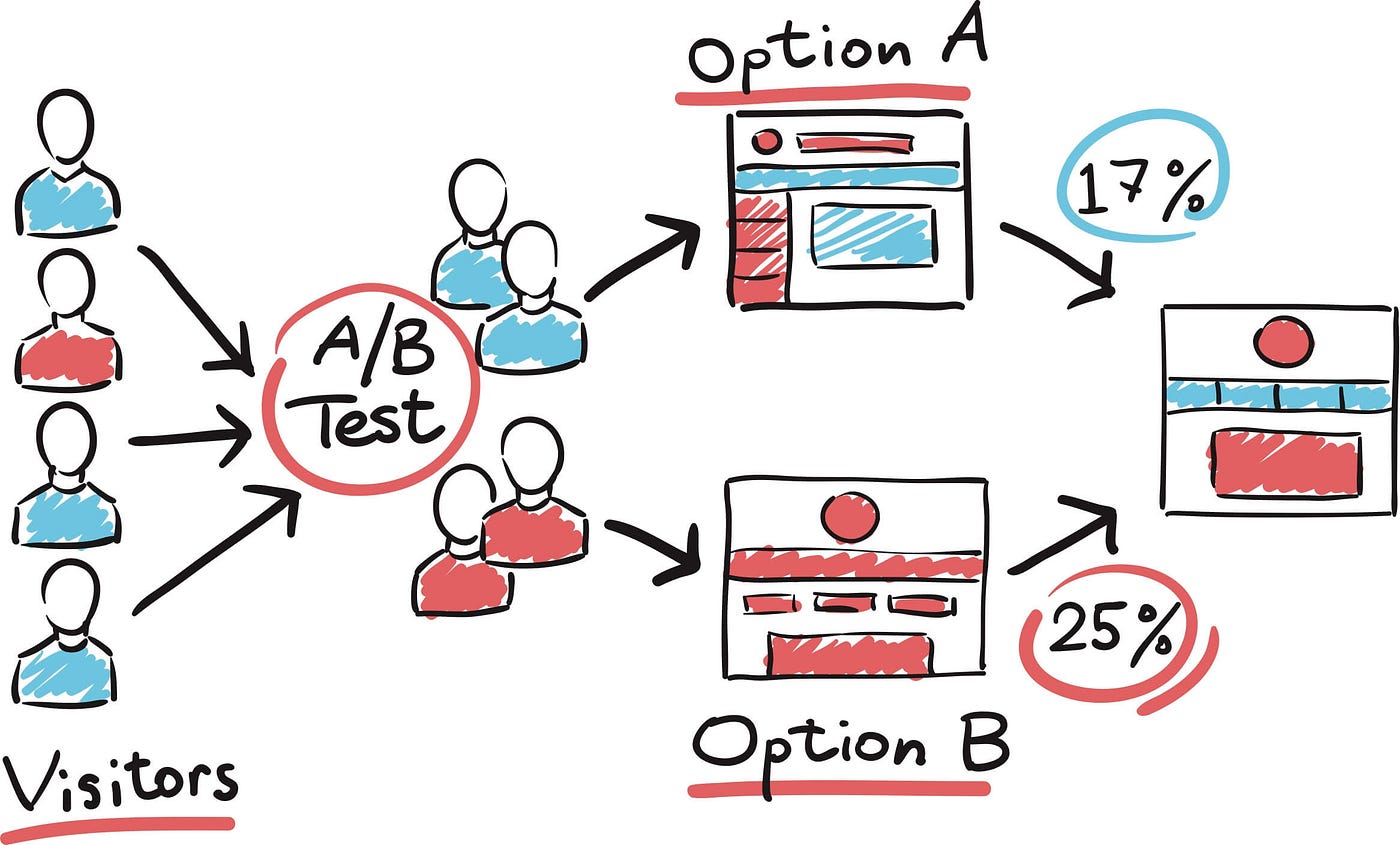
This is used to compare two versions of an ML model to determine which one performs better in a real-world setting. This approach is essential for validating the effectiveness of a new model before fully deploying it into production. This helps in understanding the impact of the new model and ensuring it does not introduce unexpected issues.
It works by distributing the incoming requests non-uniformly between the two models. A smaller portion of the traffic is directed to the new model that is being tested to minimize potential risks. The performance of both models is measured and compared based on predefined metrics.
Benefits of A/B Testing
- Risk Mitigation: By limiting the exposure of the candidate model, A/B testing helps in identifying any issues in the new model without affecting a large portion of users.
- Performance Validation: It allows teams to validate that the new model performs at least as well as, if not better than, the legacy model in a production environment.
- Data-Driven Decisions: The results from A/B testing provide concrete data to support decisions on whether to fully deploy the candidate model or make further improvements.
Thus, it is a critical testing step in ML model testing, ensuring that a new model is thoroughly vetted in a real-world environment, thereby maintaining model reliability and performance while minimizing risks associated with deploying untested models.
2. Canary Testing
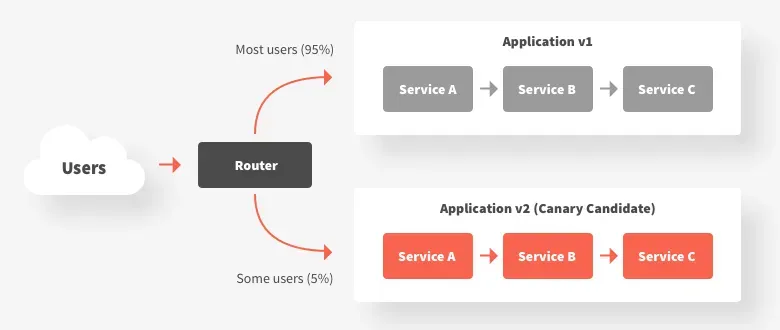
The canary testing method is used to gradually deploy a new ML model to a small subset of users in production to minimize risks and ensure that the new model performs as expected before rolling it out to a broader audience. This smaller subset of users is often referred to as the ‘canary’ group.
The main goal of this method is to limit the exposure of the new ML model initially. This incremental approach helps in identifying and mitigating any potential issues without affecting the entire user base. The performance of the ML model is monitored in the canary group.
If the model performs well in the canary group, it is gradually rolled out to a larger user base. This process continues incrementally until the new model is fully deployed to all users.
Benefits of Canary Testing
- Risk Reduction: By initially limiting the exposure of the new model, canary testing reduces the risk of widespread issues affecting all users. Any problems detected can be addressed before a full-scale deployment.
- Controlled Environment: This method provides a controlled environment to observe the new model’s behavior and make necessary adjustments based on real-world data.
- User Impact Minimization: Users in the canary group serve as an early indicator of potential issues, allowing teams to respond quickly and minimize the impact on the broader user base.
Canary testing is an effective strategy for deploying new ML models in production. It ensures that potential issues are identified and resolved early, thereby maintaining the stability and reliability of the service while introducing new features or improvements.
3. Interleaved Testing
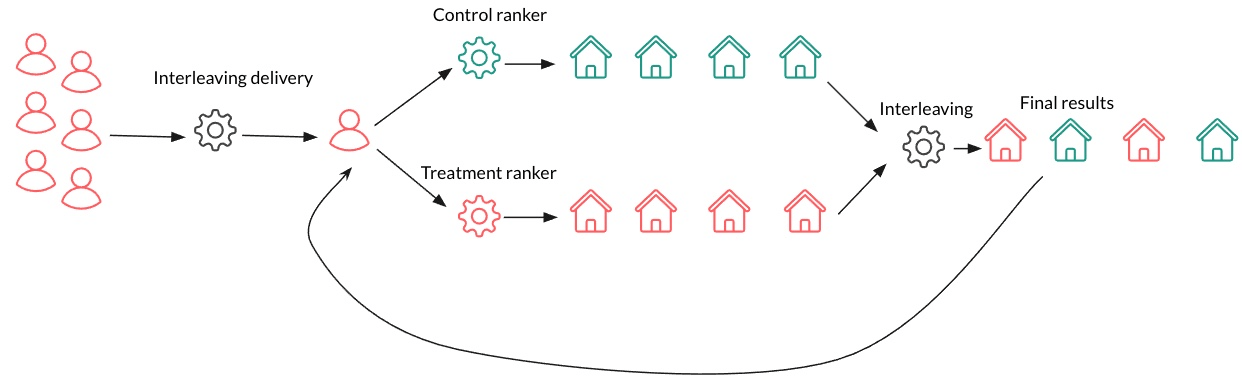
It is used to evaluate multiple ML models by mixing their outputs in real-time within the same user interface or service. This type of testing is particularly useful when you want to compare the performance of different models without exposing users to only one model at a time.
Users interact with the integrated output without knowing which model generated which part of the response. This helps in gathering unbiased user feedback and performance metrics for both models, allowing for a direct comparison under the same conditions and identifying which model performs better in real-world scenarios.
The performance of each model is tracked based on user interactions. Metrics such as click-through rates, engagement, and conversion rates are analyzed to determine which model is more effective.
Benefits of Interleaved Testing
- Direct Comparison: Interleaved testing allows for a direct, side-by-side comparison of multiple models under the same conditions, providing more accurate insights into their performance.
- User Experience Consistency: Since users are exposed to outputs from both models simultaneously, the overall user experience remains consistent, reducing the risk of user dissatisfaction.
- Detailed Feedback: This method provides detailed feedback on how users interact with different model outputs, helping in fine-tuning and improving model performance.
Interleaved testing is a useful testing strategy that ensures a direct comparison, providing valuable insights into model performance. It helps data scientists and engineers to make informed decisions about which model to deploy.
4. Shadow Testing
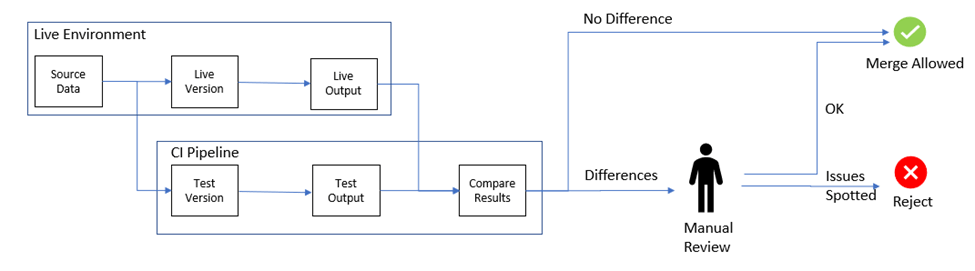
Shadow testing, also known as dark launching, is a technique used for real-world testing of a new ML model alongside the existing one, providing a risk-free way to gather performance data and insights.
It works by deploying both the new and old ML models in parallel. For each incoming request, the data is sent to both models simultaneously. Both models generate predictions, but only the output from the older model is served to the user. Predictions from the new ML model are logged for later analysis.
These predictions are then compared against the results of the older ML model and any available ground truth data to evaluate the performance of the new model.
Benefits of Shadow Testing
- Risk-Free Evaluation: Since the candidate model’s predictions are not served to the users, any errors or issues in the new model do not affect the user experience. This makes shadow testing a safe way to test new models.
- Real-World Data: Shadow testing provides insights based on real-world data and conditions, offering a more accurate assessment of the model’s performance compared to offline testing.
- Benchmarking: It allows for direct comparison between the legacy and candidate models, making it easier to benchmark the new model’s performance and identify areas for improvement.
Hence, it is a robust technique for evaluating new ML models in a live production environment without impacting the user experience. It provides valuable performance insights, ensures safe testing, and helps in making informed decisions about model deployment.

How to Choose a Testing Technique for Your ML Model Testing?
Choosing the appropriate testing technique for your machine learning models in production depends on several factors, including the nature of your model, the risks associated with its deployment, and the specific requirements of your application.
Here are some key considerations and steps to help you decide on the right testing technique:
Understand the Nature and Requirements of Your Model
Different models (classification, regression, recommendation, etc.) require different testing approaches. Complex models may benefit from more rigorous testing techniques like shadow testing or interleaved testing. Hence, you must understand the nature of your model and its complexity.
Moreover, it is crucial to assess the potential impact of model errors. High-stakes applications, such as financial services or healthcare, may necessitate more conservative and thorough testing techniques.
Evaluate Common Testing Techniques
Review and evaluate the pros and cons of the testing techniques, like the 4 methods discussed earlier in the blog. A thorough understanding of the techniques can make your decision easier and more informed.
Learn more about important ML techniques
Assess Your Infrastructure and Resources
While you have multiple options available, the state of your infrastructure and available resources are strong parameters for your final decision. Ensure that your production environment can support the chosen testing technique. For example, shadow testing requires infrastructure capable of parallel processing.
You must also evaluate the available resources, including computational power, storage, and monitoring tools. Techniques like shadow testing and interleaved testing can be resource-intensive. Hence, you must consider both factors when choosing a testing technique for your ML model.
Consider Ethical and Regulatory Constraints
Data privacy and digital ethics are important parameters for modern-day businesses and users. Hence, you must ensure compliance with data privacy regulations such as GDPR or CCPA, especially when handling sensitive data. You must choose techniques that allow for the mitigation of model bias, ensuring fairness in predictions.
Monitor and Iterate
Testing ML models in production is a continuous process. You must continuously track your model performance, data drift, and prediction accuracy over time. This must link to an iterative model improvement process. You can establish a feedback loop to retrain and update the model based on the gathered performance data.

Hence, you must carefully select the model technique for your ML model. You can consider techniques like A/B testing for direct performance comparison, canary testing for gradual rollout, interleaved testing for simultaneous output assessment, and shadow testing for risk-free evaluation.
To Sum it Up…
ML model testing when in production is a critical step. You must ensure your model’s reliability, performance, and safety in real-world scenarios. You can do that by evaluating the model’s performance in a live environment, identifying potential issues, and finding ways to resolve them.
We have explored 4 different methods to test ML models where way offers unique benefits and is suited to different scenarios and business needs. By carefully selecting the appropriate technique, you can ensure your ML models perform as expected, maintain user satisfaction, and uphold high standards of reliability and safety.
If you are interested in learning how to build ML models from scratch, here’s a video for a more engaging learning experience: