

Data science model deployment can sound intimidating if you have never had a chance to try it in a safe space. Do you want to make a rest API or a full frontend app? What does it take to do either of these? It’s not as hard as you might think.
In this series, we’ll go through how you can take machine learning models and deploy them to a web app or a rest API (using saturn cloud) so that others can interact. In this app, we’ll let the user make some feature selections and then the model will predict an outcome for them. But using this same idea, you could easily do other things, such as letting the user retrain the model, upload things like images, or conduct other interactions with your model.
Just to be interesting, we’re going to do this same project with two frameworks, voila and flask, so you can see how they both work and decide what’s right for your needs. In a flask, we’ll create a rest API and a web app version.
A

a
Our toolkit
- saturn cloud (so you can deploy easily!)
- flask
- voila
- plotly (python and js)
- scikit-learn (for our model)
A
Other helpful links
- ipywidgets (helpful for voila)
- codebook for the dataset
- plotly.js cheat sheet
- jinja (helpful for flask)
A
The project – Deploying machine learning models
The first steps of our process are exactly the same, whether we are going for voila or flask. We need to get some data and build a model! I will take the us department of education’s college scorecard data, and build a quick linear regression model that accepts a few inputs and predicts a student’s likely earnings 2 years after graduation. (you can get this data yourself at https://collegescorecard.ed.gov/data/)
About measurements
According to the data codebook: “the cohort of evaluated graduates for earnings metrics consists of those individuals who received federal financial aid, but excludes those who were subsequently enrolled in school during the measurement year, died before the end of the measurement year, received a higher-level credential than the credential level of the field of the study measured, or did not work during the measurement year.”
Load data
I already did some data cleaning and uploaded the features I wanted to a public bucket on s3, for easy access. This way, I can load it quickly when the app is run.
Format for training
Once we have the dataset, this is going to give us a handful of features and our outcome. We just need to split it between features and target with scikit-learn to be ready to model. (note that all of these functions will be run exactly as written in each of our apps.)
Our features are:
- Region: geographic location of college
- Locale: type of city or town the college is in
- Control: type of college (public/private/for-profit)
- Cipdesc_new: major field of study (cip code)
- Creddesc: credential (bachelor, master, etc)
- Adm_rate_all: admission rate
- Sat_avg_all: average sat score for admitted students (proxy for college prestige)
- Tuition: cost to attend the institution for one year
Our target outcome is earn_mdn_hi_2yr: median earnings measured two years after completion of degree.
Train model
We are going to use scikit-learn’s pipeline to make our feature engineering as easy and quick as possible. We’re going to return a trained model as well as the r-squared value for the test sample, so we have a quick and straightforward measure of the model’s performance on the test set that we can return along with the model object.
Now we have a model, and we’re ready to put together the app! All these functions will be run when the app runs, because it’s so fast that it doesn’t make sense to save out a model object to be loaded. If your model doesn’t train this fast, save your model object and return it in your app when you need to predict.
If you’re interested in learning some valuable tips for machine learning projects, read our blog on machine learning project tips.
Visualization
In addition to building a model and creating predictions, we want our app to show a visual of the prediction against a relevant distribution. The same plot function can be used for both apps, because we are using plotly for the job.
The function below accepts the type of degree and the major, to generate the distributions, as well as the prediction that the model has given. That way, the viewer can see how their prediction compares to others. Later, we’ll see how the different app frameworks use the plotly object.
This is the general visual we’ll be generating — but because it’s plotly, it’ll be interactive!
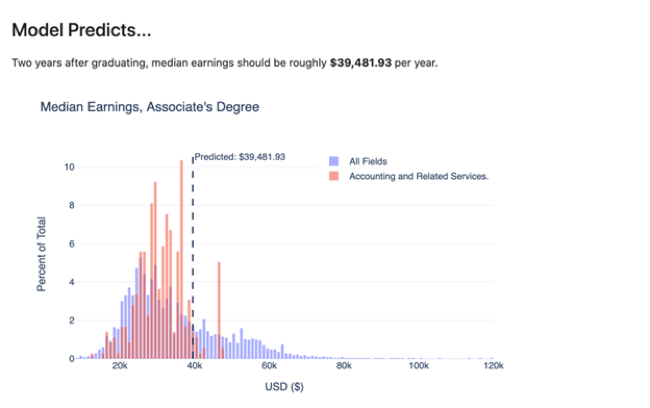
You might be wondering whether your favorite visualization library could work here — the answer is, maybe! Every python viz library has idiosyncrasies and is not likely to be supported exactly the same for voila and flask. I chose plotly because it has interactivity and is fully functional in both frameworks, but you are welcome to try your own visualization tool and see how it goes.
Wrapping up
In conclusion, deploying machine learning models to a web app or REST API can seem daunting, but it’s not as difficult as it may seem. By using frameworks like voila and Flask, along with libraries like scikit-learn, plotly, and pandas, you can easily create an app that allows users to interact with machine learning models.
In this project, we used the US Department of Education’s college scorecard data to build a linear regression model that predicts a student’s likely earnings two years after graduation.
Written by Stephanie Kirmer