Machine learning practices are the guiding principles that transform raw data into powerful insights. By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success.
In this blog, we focus on machine learning practices—the essential steps that unlock the potential of this transformative technology. By adhering to best practices, such as selecting the right machine learning algorithms, gathering high-quality data, performing effective preprocessing, evaluating models, and deploying them strategically, we pave the path toward accurate and impactful results.
Join us as we explore these key machine learning practices and uncover the secrets to optimizing machine-learning models for revolutionary advancements in diverse domains.

1. Choose the Right Algorithm
When choosing an algorithm, it is important to consider the following factors:
- The type of problem you are trying to solve. Some algorithms are better suited for classification tasks, while others are better suited for regression tasks.
- The amount of data you have. Some algorithms require a lot of data to train, while others can be trained with less data.
- The desired accuracy. Some algorithms are more accurate than others
- The computational resources you have available. Some algorithms are more computationally expensive than others.
Once you have considered these factors, you can start to narrow down your choices of algorithms. You can then read more about each algorithm and experiment with different algorithms to see which one works best for your problem.
2. Get Enough Data
Machine learning models are only as good as the data they are trained on. If you don’t have enough data, your models will not be able to learn effectively. It is important to collect as much data as possible that is relevant to your problem. The more data you have, the better your models will be.
There are a number of different ways to collect data for machine learning projects. Some common techniques include:
- Web scraping: Web scraping is the process of extracting data from websites. This can be done using a variety of tools and techniques.
- Social media: Social media platforms can be a great source of data for machine learning projects. This data can be used to train models for tasks such as sentiment analysis and topic modeling.
- Sensor data: Sensor data can be used to train models for tasks such as object detection and anomaly detection. This data can be collected from a variety of sources, such as smartphones, wearable devices, and traffic cameras.
3. Clean Your Data
Even if you have a lot of data, it is important to make sure that it is clean. This means removing any errors or outliers from your data. If your data is dirty, it will make it difficult for your models to learn effectively. There are a number of different ways to clean your data. Some common techniques include:
- Identifying and removing errors: This can be done by looking for data that is missing, incorrect, or inconsistent.
- Identifying and removing outliers: Outliers are data points that are significantly different from the rest of the data. They can be removed by identifying them and then removing them from the dataset.
- Imputing missing values: Missing values can be imputed by filling them in with the mean, median, or mode of the other values in the column.
- Transforming categorical data: Categorical data can be transformed into numerical data by using a process called one-hot encoding.
Once you have cleaned your data, you can then proceed to train your machine learning models.
4. Evaluate Your Models
Once you have trained your models, it is important to evaluate their performance. This can be done by using a holdout set of data that was not used to train the models. The holdout set can be used to measure the accuracy, precision, and recall of the models.
- Accuracy: Accuracy is the percentage of data points that are correctly classified by the model.
- Precision: Precision is the percentage of data points that are classified as positive that are actually positive.
- Recall: Recall is the percentage of positive data points that are correctly classified as positive.
The ideal model would have high accuracy, precision, and recall. However, in practice, it is often necessary to trade-off between these three metrics. For example, a model with high accuracy may have low precision or recall.
Once you have evaluated your models, you can then choose the model that has the best performance. You can then deploy the model to production and use it to make predictions.
5. Deploy Your Models
Once you are satisfied with the performance of your models, it is time to deploy them. This means making them available to users so that they can use them to make predictions. There are many different ways to deploy machine learning models, such as through a web service or a mobile app.
Deploying your machine learning models is considered a good practice because it enables the practical utilization of your models by making them accessible to users. Also, it has the potential to reach a broader audience, maximizing its impact.
By making your models accessible, you enable a wider range of users to benefit from the predictive capabilities of machine learning, driving decision-making processes and generating valuable outcomes.
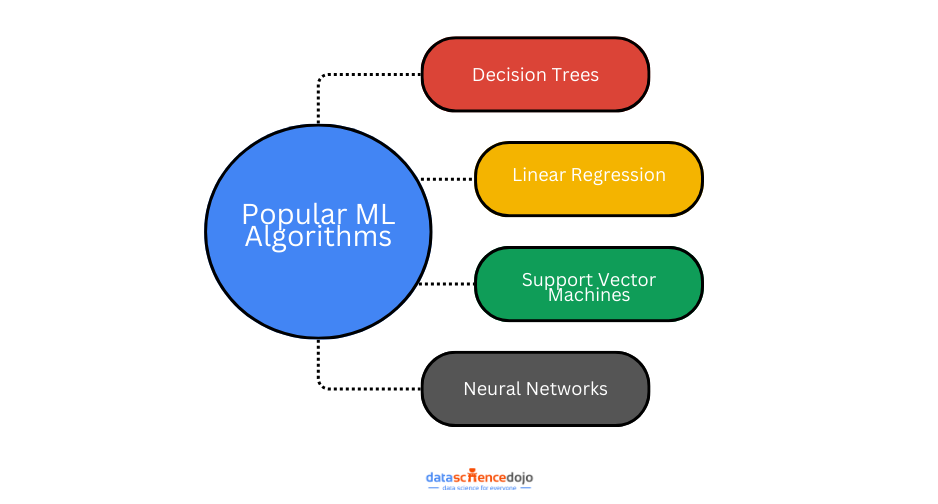
Popular Machine-Learning Algorithms
Here are some of the most popular machine-learning algorithms:
1. Decision Trees
Decision trees are intuitive and easy to interpret, making them great for beginners. They work by splitting the data into smaller subsets based on certain conditions (like yes/no questions), forming a tree-like structure. The final “leaves” of the tree represent the classification or outcome. They’re especially useful in classification problems, such as deciding whether an email is spam or not.

2. Linear Regression
Linear regression is one of the simplest algorithms used for predictive analysis. It finds the best-fitting straight line (also called a regression line) through the data points and predicts the target value based on that line. It’s best suited for problems where the relationship between the input and output variables is linear—such as predicting housing prices based on square footage.
3. Support Vector Machines (SVM)
SVMs are more advanced algorithms used for both classification and regression. They work by finding a hyperplane (a boundary) that best separates the data into classes. SVMs are powerful in high-dimensional spaces and are effective when the margin of separation between classes is very clear. For example, they can be used in image classification or handwriting recognition.
4. Neural Networks
Neural networks are inspired by the human brain and are composed of layers of interconnected nodes (neurons). They are highly versatile and can handle complex, non-linear relationships in data. Neural networks are the backbone of deep learning and are used in applications like speech recognition, image generation, and natural language processing. However, they require large datasets and significant computational power to perform well.
It is important to note that there are no single “best” machine learning practices or algorithms. The best algorithm for a particular problem will depend on the specific factors of that problem.
In a Nutshell
Machine learning practices are essential for accurate and reliable results. Choose the right algorithm, gather quality data, clean and preprocess it, evaluate model performance, and deploy it effectively. These practices optimize algorithm selection, data quality, accuracy, decision-making, and practical utilization. By following these practices, you improve accuracy and solve real-world problems.