
Byte pair encoding (BPE) has quietly become one of the most influential algorithms in natural language processing (NLP) and machine learning. If you’ve ever wondered how models like GPT, BERT, or Llama handle vast vocabularies and rare words, the answer often lies in byte pair encoding. In this comprehensive guide, we’ll demystify byte pair encoding, explore its origins, applications, and impact on modern AI, and show you how to leverage BPE in your own data science projects.
What is Byte Pair Encoding?
Byte pair encoding is a data compression and tokenization algorithm that iteratively replaces the most frequent pair of bytes (or characters) in a sequence with a new, unused byte. Originally developed for data compression, BPE has found new life in NLP as a powerful subword segmentation technique.
From tokenization to sentiment—learn Python-powered NLP from parsing to purpose.
Why is this important?
Traditional tokenization methods, splitting text into words or characters, struggle with rare words, misspellings, and out-of-vocabulary (OOV) terms. BPE bridges the gap by breaking words into subword units, enabling models to handle any input text, no matter how unusual.
The Origins of Byte Pair Encoding
BPE was first introduced by Philip Gage in 1994 as a simple data compression algorithm. Its core idea was to iteratively replace the most common pair of adjacent bytes in a file with a byte that does not occur in the file, thus reducing file size.
In 2015, Sennrich, Haddow, and Birch adapted BPE for NLP, using it to segment words into subword units for neural machine translation. This innovation allowed translation models to handle rare and compound words more effectively.
How Byte Pair Encoding Works: Step-by-Step

Byte Pair Encoding (BPE) is a powerful algorithm for tokenizing text, especially in natural language processing (NLP). Its strength lies in transforming raw text into manageable subword units, which helps language models handle rare words and diverse vocabularies. Let’s walk through the BPE process in detail:
1. Initialize the Vocabulary
Context:
The first step in BPE is to break down your entire text corpus into its smallest building blocks, individual characters. This granular approach ensures that every possible word, even those not seen during training, can be represented using the available vocabulary.
Process:
- List every unique character found in your dataset (e.g., a-z, punctuation, spaces).
- For each word, split it into its constituent characters.
- Append a special end-of-word marker (eg “</w>” or “▁”) to each word. This marker helps the algorithm distinguish between words and prevents merges across word boundaries.
Example:
Suppose your dataset contains the words:
- “lower” → l o w e r</w>
- “lowest” → l o w e s t</w>
- “newest” → n e w e s t</w>
Why the end-of-word marker?
It ensures that merges only happen within words, not across them, preserving word boundaries and meaning.
2. Count Symbol Pairs
Context:
Now, the algorithm looks for patterns specifically, pairs of adjacent symbols (characters or previously merged subwords) within each word. By counting how often each pair appears, BPE identifies which combinations are most common and thus most useful to merge.
Process:
- For every word, list all adjacent symbol pairs.
- Tally the frequency of each pair across the entire dataset.
Example:
For “lower” (l o w e r ), the pairs are:
- (l, o), (o, w), (w, e), (e, r), (r, )
For “lowest” (l o w e s t ):
- (l, o), (o, w), (w, e), (e, s), (s, t), (t, )
For “newest” (n e w e s t ):
- (n, e), (e, w), (w, e), (e, s), (s, t), (t, )
Frequency Table Example:
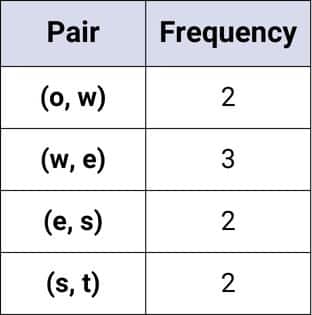
3. Merge the Most Frequent Pair
Context:
The heart of BPE is merging. By combining the most frequent pair into a new symbol, the algorithm creates subword units that capture common patterns in the language.
Process:
- Identify the pair with the highest frequency.
- Merge this pair everywhere it appears in the dataset, treating it as a single symbol in future iterations.
Example:
Suppose (w, e) is the most frequent pair (appearing 3 times).
- Merge “w e” into “we”.
Update the words:
- “lower” → l o we r
- “lowest” → l o we s t
- “newest” → n e we s t
Note:
After each merge, the vocabulary grows to include the new subword (“we” in this case).
4. Repeat the Process
Context:
BPE is an iterative algorithm. After each merge, the dataset changes, and new frequent pairs may emerge. The process continues until a stopping criterion is met, usually a target vocabulary size or a set number of merges.
Process:
- Recount all adjacent symbol pairs in the updated dataset.
- Merge the next most frequent pair.
- Update all words accordingly.
Example:
If (o, we) is now the most frequent pair, merge it to “owe”:
- “lower” → l owe r
- “lowest” → l owe s t
Continue merging:
- “lower” → low er
- “lowest” → low est
- “newest” → new est
Iteration Table Example:
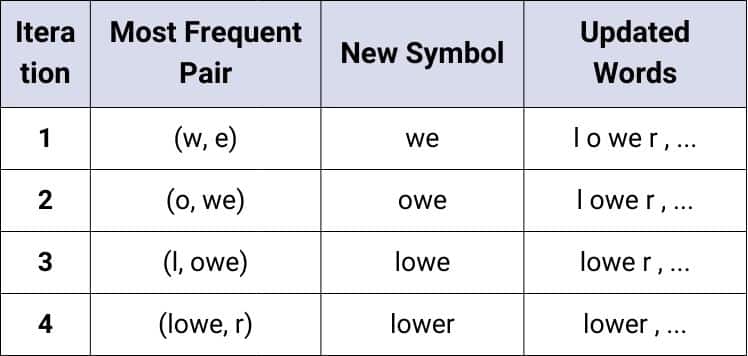
5. Build the Final Vocabulary
Context:
After the desired number of merges, the vocabulary contains both individual characters and frequently occurring subword units. This vocabulary is used to tokenize any input text, allowing the model to represent rare or unseen words as sequences of known subwords.
Process:
- The final vocabulary includes all original characters plus all merged subwords.
- Any word can be broken down into a sequence of these subwords, ensuring robust handling of out-of-vocabulary terms.
Example:
Final vocabulary might include:
{l, o, w, e, r, s, t, n, we, owe, low, est, new, lower, lowest, newest, }
Tokenization Example:
- “lower” → lower
- “lowest” → low est
- “newest” → new est
Why Byte Pair Encoding Matters in NLP
Handling Out-of-Vocabulary Words
Traditional word-level tokenization fails when encountering new or rare words. BPE’s subword approach ensures that any word, no matter how rare, can be represented as a sequence of known subwords.
Efficient Vocabulary Size
BPE allows you to control the vocabulary size, balancing model complexity and coverage. This is crucial for deploying models on resource-constrained devices or scaling up to massive datasets.
Improved Generalization
By breaking words into meaningful subword units, BPE enables models to generalize better across languages, dialects, and domains.
Byte Pair Encoding in Modern Language Models
BPE is the backbone of tokenization in many state-of-the-art language models:
-
GPT & GPT-2/3/4: Use BPE to tokenize input text, enabling efficient handling of diverse vocabularies.
-
BERT & RoBERTa: Employ similar subword tokenization strategies (WordPiece, SentencePiece) inspired by BPE.
-
Llama, Qwen, and other transformer models: Rely on BPE or its variants for robust, multilingual tokenization.
Practical Applications of Byte Pair Encoding
1. Machine Translation
BPE enables translation models to handle rare words, compound nouns, and morphologically rich languages by breaking them into manageable subwords.
2. Text Generation
Language models use BPE to generate coherent text, even when inventing new words or handling typos.
3. Data Compression
BPE’s roots in data compression make it useful for reducing the size of text data, especially in resource-limited environments.
4. Preprocessing for Neural Networks
BPE simplifies text preprocessing, ensuring consistent tokenization across training and inference.
Implementing Byte Pair Encoding: A Hands-On Example
Let’s walk through a simple Python implementation using the popular tokenizers library from Hugging Face:
This code trains a custom Byte Pair Encoding (BPE) tokenizer using the Hugging Face tokenizers library. It first initializes a BPE model and applies a whitespace pre-tokenizer so that words are split on spaces before subword merges are learned. A BpeTrainer is then configured with a target vocabulary size of 10,000 tokens and a minimum frequency threshold, ensuring that only subwords appearing at least twice are included in the final vocabulary. The tokenizer is trained on a text corpus your_corpus.text (you may use whatever text you want to tokenize here), during which it builds a vocabulary and set of merge rules based on the most frequent character pairs in the data. Once trained, the tokenizer can encode new text by breaking it into tokens (subwords) according to the learned rules, which helps represent both common and rare words efficiently.
Byte Pair Encoding vs. Other Tokenization Methods

Challenges and Limitations
- Morpheme Boundaries: BPE merges based on frequency, not linguistic meaning, so subwords may not align with true morphemes.
- Language-Specific Issues: Some languages (e.g., Chinese, Japanese) require adaptations for optimal performance.
- Vocabulary Tuning: Choosing the right vocabulary size is crucial for balancing efficiency and coverage.
Best Practices for Using Byte Pair Encoding
-
Tune Vocabulary Size:
Start with 10,000–50,000 tokens for most NLP tasks; adjust based on dataset and model size.
-
Preprocess Consistently:
Ensure the same BPE vocabulary is used during training and inference.
-
Monitor OOV Rates:
Analyze how often your model encounters unknown tokens and adjust accordingly.
-
Combine with Other Techniques:
For multilingual or domain-specific tasks, consider hybrid approaches (e.g., SentencePiece, Unigram LM).
Real-World Example: BPE in GPT-3
OpenAI’s GPT-3 uses a variant of BPE to tokenize text into 50,257 unique tokens, balancing efficiency and expressiveness. This enables GPT-3 to handle everything from code to poetry, across dozens of languages.
FAQ: Byte Pair Encoding
Q1: Is byte pair encoding the same as WordPiece or SentencePiece?
A: No, but they are closely related. WordPiece and SentencePiece are subword tokenization algorithms inspired by BPE, each with unique features.
Q2: How do I choose the right vocabulary size for BPE?
A: It depends on your dataset and model. Start with 10,000–50,000 tokens and experiment to find the sweet spot.
Q3: Can BPE handle non-English languages?
A: Yes! BPE is language-agnostic and works well for multilingual and morphologically rich languages.
Q4: Is BPE only for NLP?
A: While most popular in NLP, BPE’s principles apply to any sequential data, including DNA sequences and code.
Conclusion: Why Byte Pair Encoding Matters for Data Scientists
Byte pair encoding is more than just a clever algorithm, it’s a foundational tool that powers the world’s most advanced language models. By mastering BPE, you’ll unlock new possibilities in NLP, machine translation, and AI-driven applications. Whether you’re building your own transformer model or fine-tuning a chatbot, understanding byte pair encoding will give you a competitive edge in the fast-evolving field of data science.
Ready to dive deeper?