Unlocking the potential of large language models like GPT-4 reveals a Pandora’s box of privacy concerns. Unintended data leaks sound the alarm, demanding stricter privacy measures.
Generative Artificial Intelligence (AI) has garnered significant interest, with users considering its application in critical domains such as financial planning and medical advice. However, this excitement raises a crucial question:
Can we truly trust these large language models (LLMs)?
Sanmi Koyejo and Bo Li, experts in computer science, delve into this question through their research, evaluating GPT-3.5 and GPT-4 models for trustworthiness across multiple perspectives.
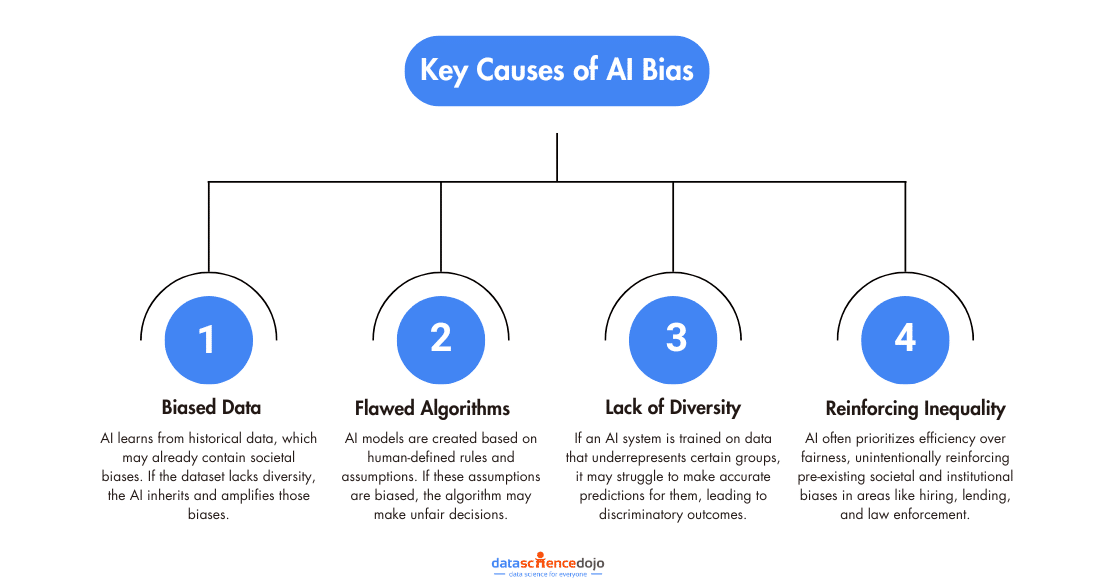
Koyejo and Li’s study takes a comprehensive look at eight trust perspectives: toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. While the newer models exhibit reduced toxicity on standard benchmarks, the researchers find that they can still be influenced to generate toxic and biased outputs, highlighting the need for caution in sensitive areas.

The illusion of perfection
Contrary to the common perception of LLMs as flawless and capable, the research underscores their vulnerabilities. These models, such as GPT-3.5 and GPT-4, though capable of extraordinary feats like natural conversations, fall short of the trust required for critical decision-making. Koyejo emphasizes the importance of recognizing these models as machine learning systems with inherent vulnerabilities, emphasizing that expectations need to align with the current reality of AI capabilities.
Unveiling the black box: Understanding the inner workings
A critical challenge in the realm of artificial intelligence is the enigmatic nature of model training, a conundrum that Koyejo and Li’s evaluation brought to light. They shed light on the lack of transparency in the training processes of AI models, particularly emphasizing the opacity surrounding popular models.
Many of these models are proprietary and concealed in a shroud of secrecy, leaving researchers and users grappling to comprehend their intricate inner workings. This lack of transparency poses a significant hurdle in understanding and analyzing these models comprehensively.
To tackle this issue, the study adopted the approach of a “Red Team,” mimicking a potential adversary. By stress-testing the models, the researchers aimed to unravel potential pitfalls and vulnerabilities. This proactive initiative provided invaluable insights into areas where these models could falter or be susceptible to malicious manipulation. It also underscored the necessity for greater transparency and openness in the development and deployment of AI models.

Toxicity and adversarial prompts
One of the key findings of the study pertained to the levels of toxicity exhibited by GPT-3.5 and GPT-4 under different prompts. When presented with benign prompts, these models showed a significant reduction in toxic outputs, indicating a degree of control and restraint. However, a startling revelation emerged when the models were subjected to adversarial prompts – their toxicity probability surged to an alarming 100%.
This dramatic escalation in toxicity under adversarial conditions raises a red flag regarding the model’s susceptibility to malicious manipulation. It underscores the critical need for vigilant monitoring and cautious utilization of AI models, particularly in contexts where toxic outputs could have severe real-world consequences.
Additionally, this finding highlights the importance of ongoing research to devise mechanisms that can effectively mitigate toxicity, making these AI systems safer and more reliable for users and society at large.
Bias and privacy concerns
Addressing bias in AI systems is an ongoing challenge, and despite efforts to reduce biases in GPT-4, the study uncovered persistent biases towards specific stereotypes. These biases can have significant implications in various applications where the model is deployed. The danger lies in perpetuating harmful societal prejudices and reinforcing discriminatory behaviors.
Furthermore, privacy concerns have emerged as a critical issue associated with GPT models. Both GPT-3.5 and GPT-4 have been shown to inadvertently leak sensitive training data, raising red flags about the privacy of individuals whose data is used to train these models. This leakage of information can encompass a wide range of private data, including but not limited to email addresses and potentially even more sensitive information like Social Security numbers.
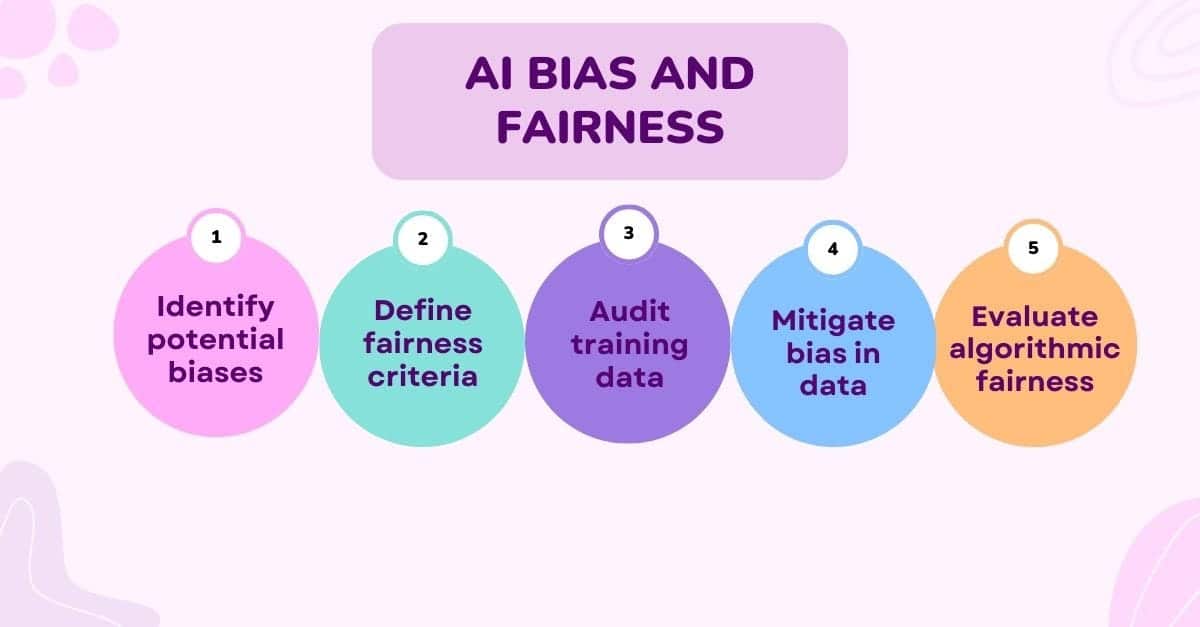
The study’s revelations emphasize the pressing need for ongoing research and development to effectively mitigate biases and improve privacy measures in AI systems like GPT-4. Developers and researchers must work collaboratively to identify and rectify biases, ensuring that AI models are more inclusive and representative of diverse perspectives.
To enhance privacy, it is crucial to implement stricter controls on data usage and storage during the training and usage of these models. Stringent protocols should be established to safeguard against the inadvertent leaking of sensitive information. This involves not only technical solutions but also ethical considerations in the development and deployment of AI technologies.
Fairness in predictions
The assessment of GPT-4 revealed worrisome biases in the model’s predictions, particularly concerning gender and race. These biases highlight disparities in how the model perceives and interprets different attributes of individuals, potentially leading to unfair and discriminatory outcomes in applications that utilize these predictions.
In the context of gender and race, the biases uncovered in the model’s predictions can perpetuate harmful stereotypes and reinforce societal inequalities. For instance, if the model consistently predicts higher incomes for certain genders or races, it could inadvertently reinforce existing biases related to income disparities.
Read more about -> 10 innovative ways to monetize business using ChatGPT
The study underscores the importance of ongoing research and vigilance to ensure fairness in AI predictions. Fairness assessments should be an integral part of the development and evaluation of AI models, particularly when these models are deployed in critical decision-making processes. This includes a continuous evaluation of the model’s performance across various demographic groups to identify and rectify biases.
Moreover, it’s crucial to promote diversity and inclusivity within the teams developing these AI models. A diverse team can provide a range of perspectives and insights necessary to address biases effectively and create AI systems that are fair and equitable for all users.
Conclusion: Balancing potential with caution
Koyejo and Li acknowledge the progress seen in GPT-4 compared to GPT-3.5 but caution against unfounded trust. They emphasize the ease with which these models can generate problematic content and stress the need for vigilant, human oversight, especially in sensitive contexts. Ongoing research and third-party risk assessments will be crucial in guiding the responsible use of generative AI. Maintaining a healthy skepticism, even as the technology evolves, is paramount.