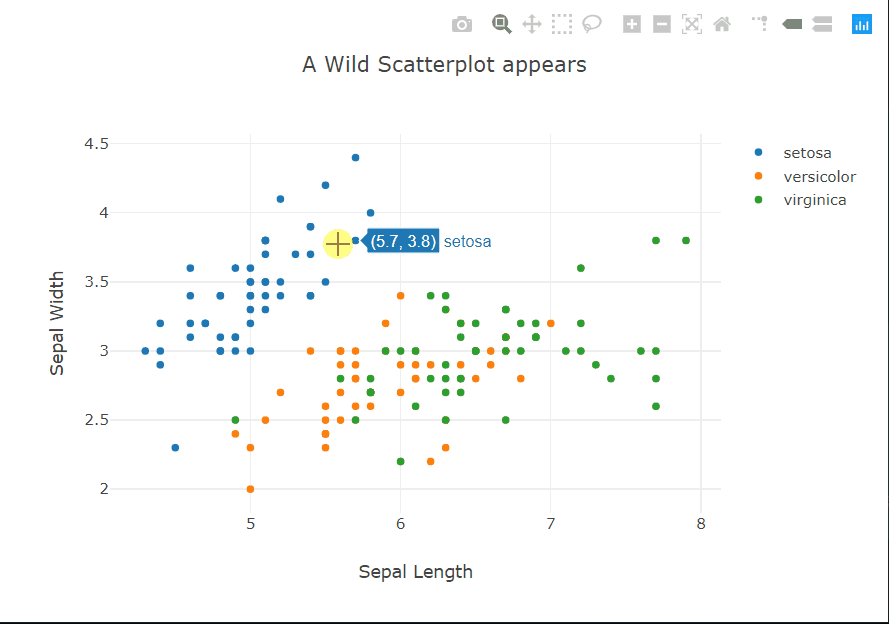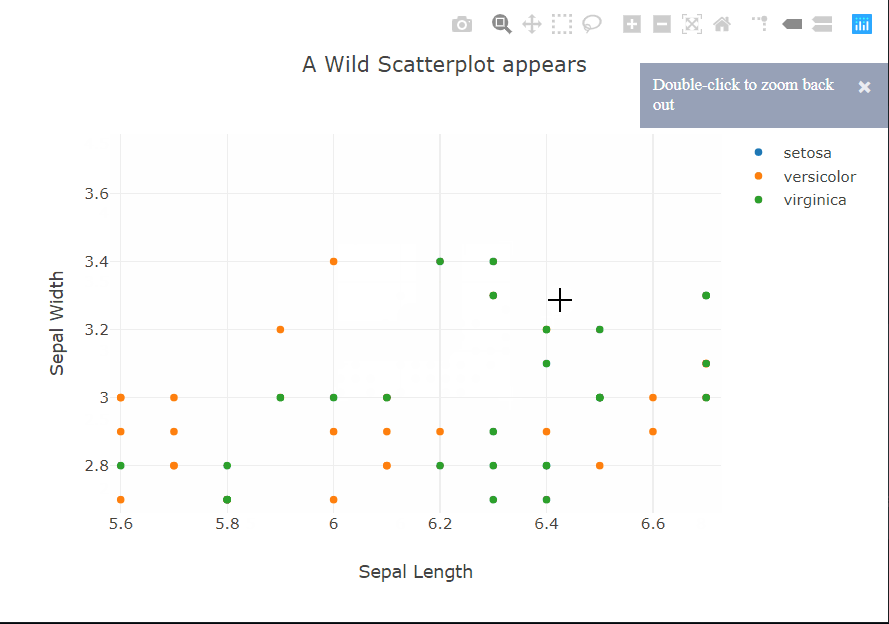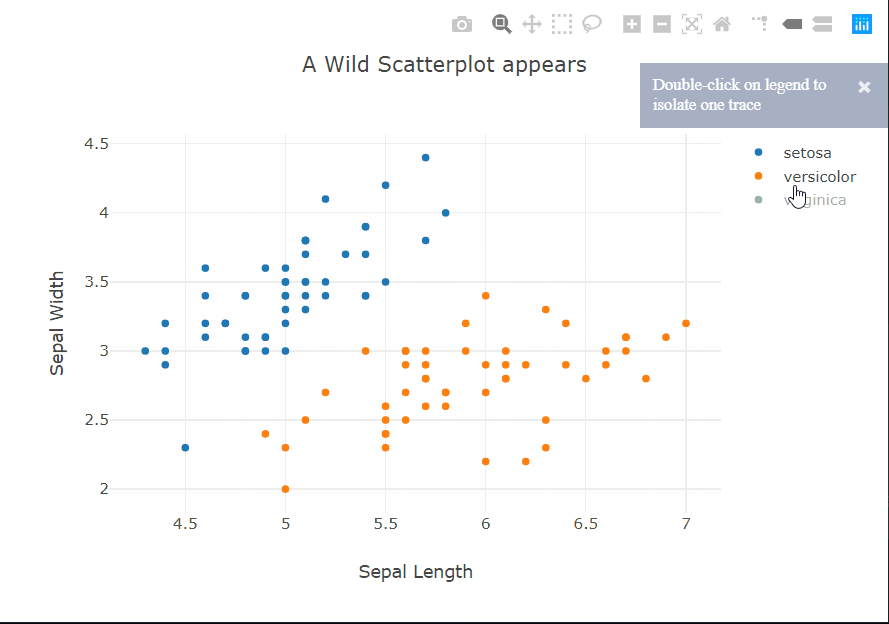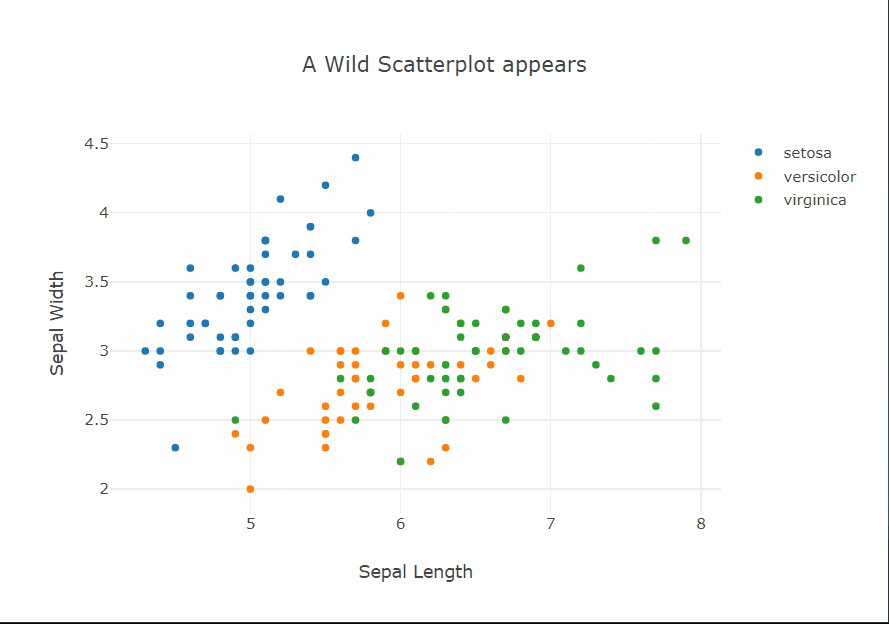
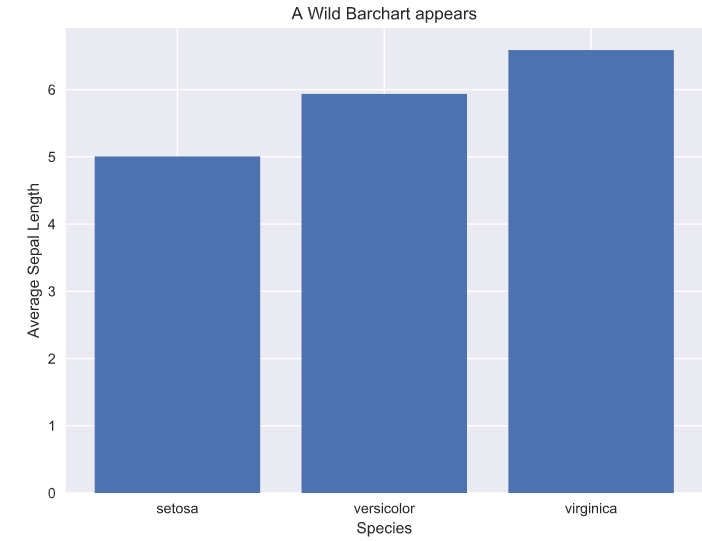
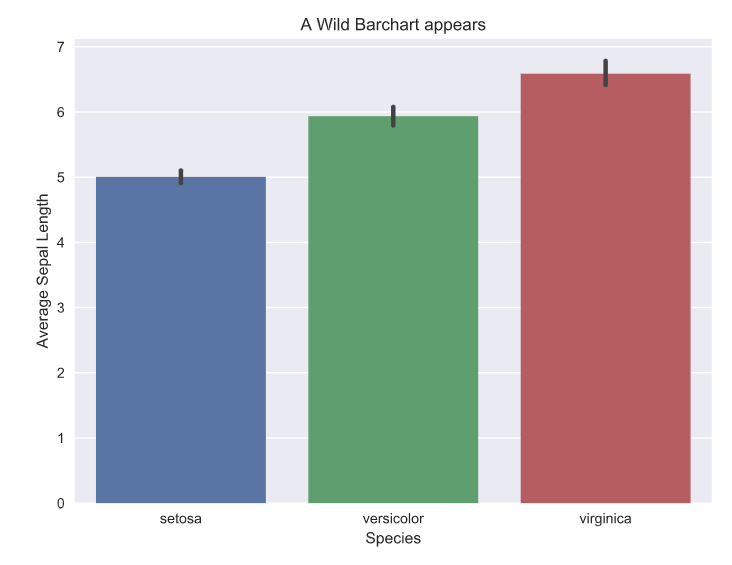
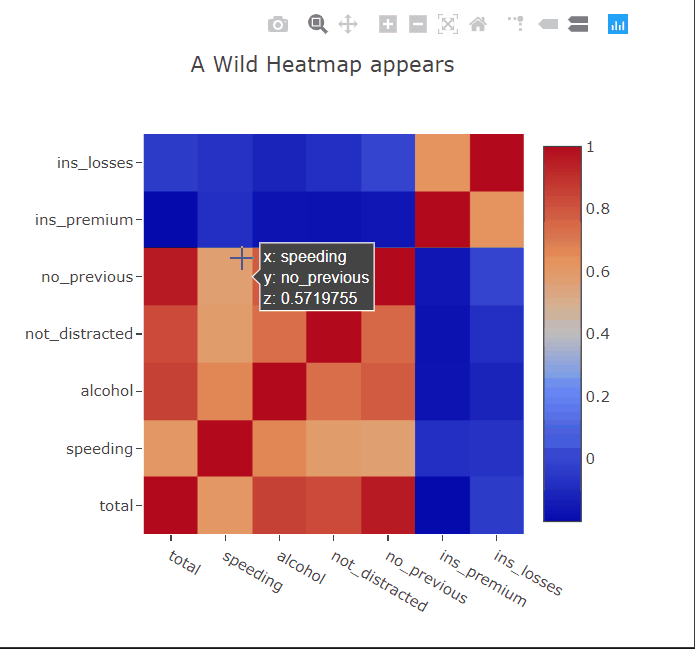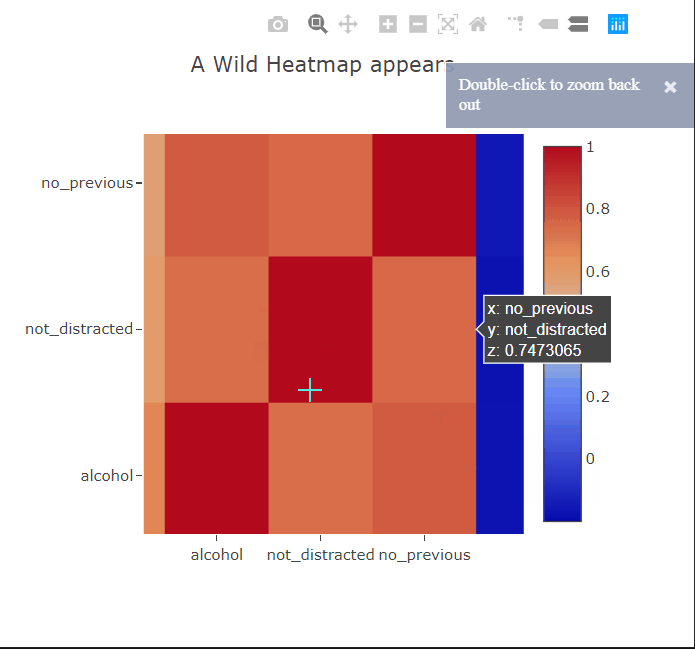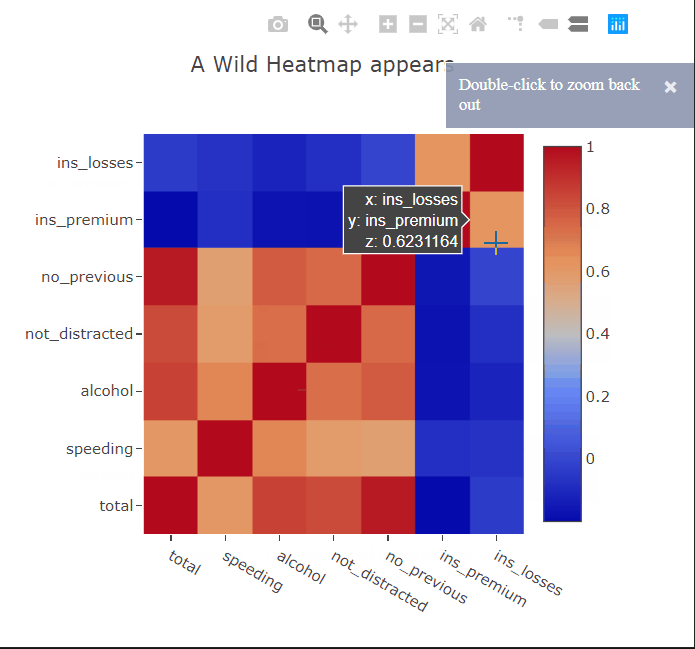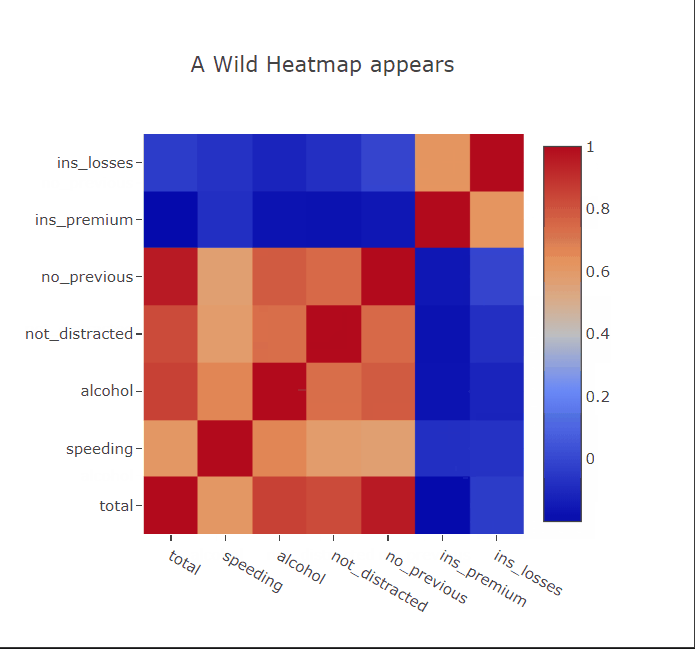
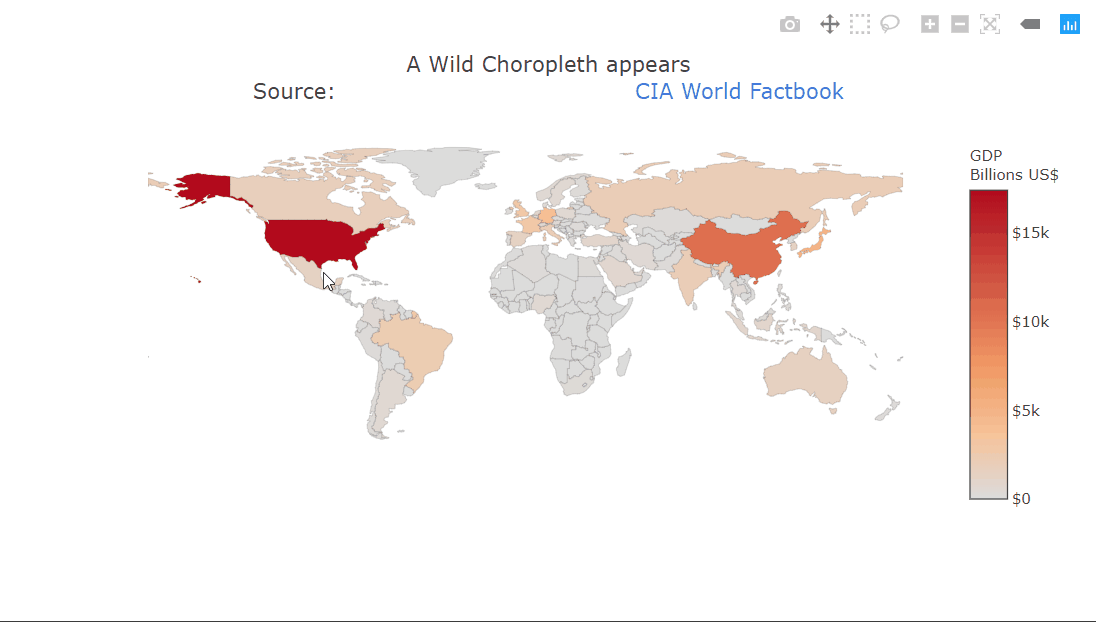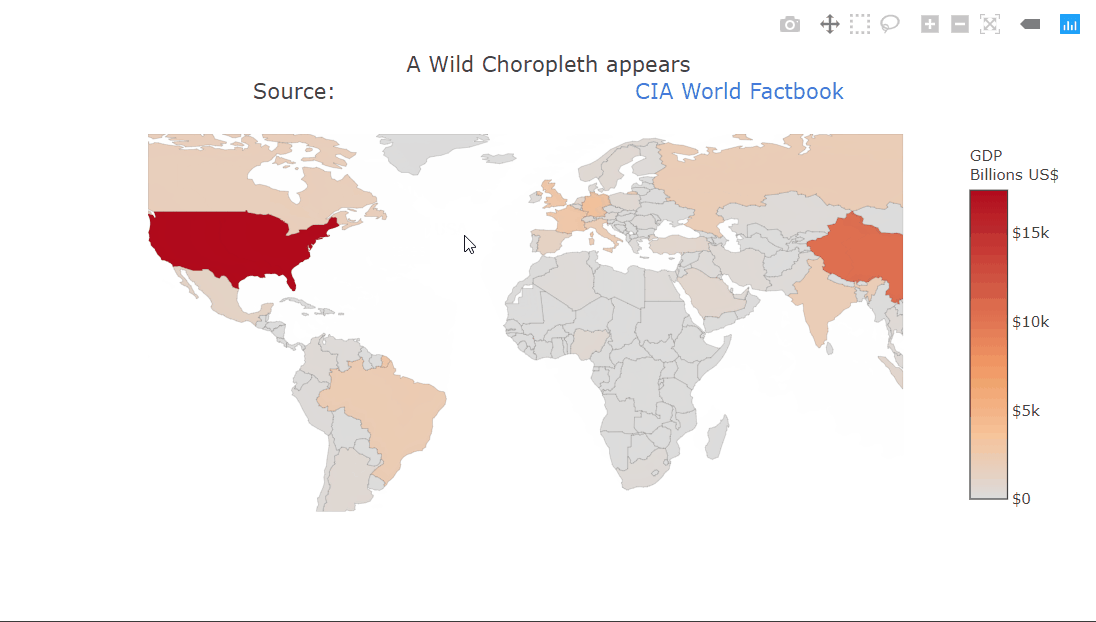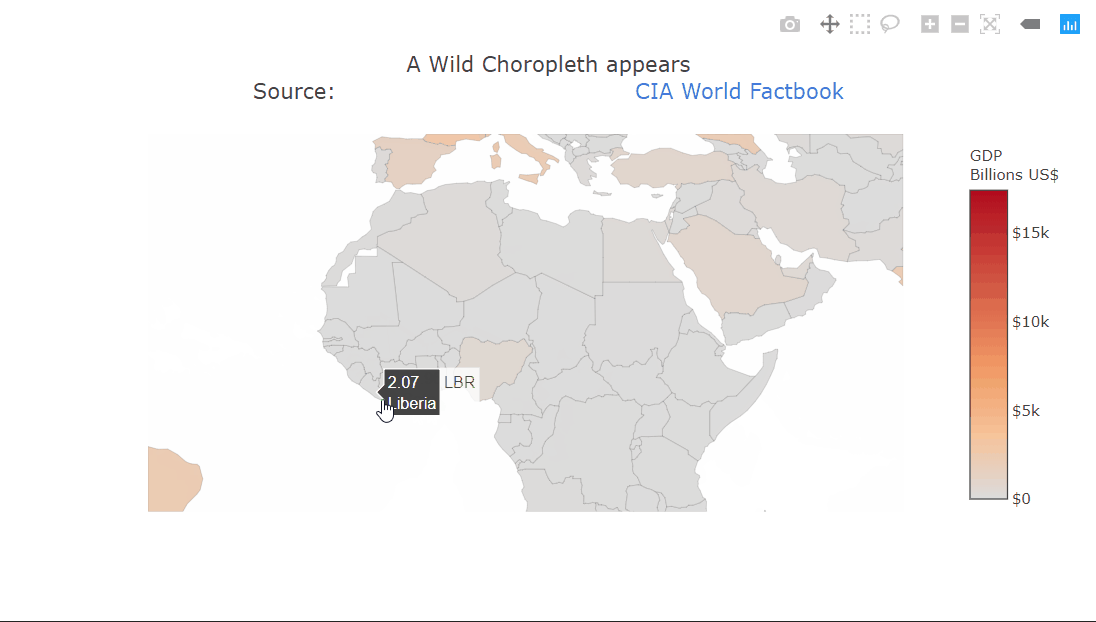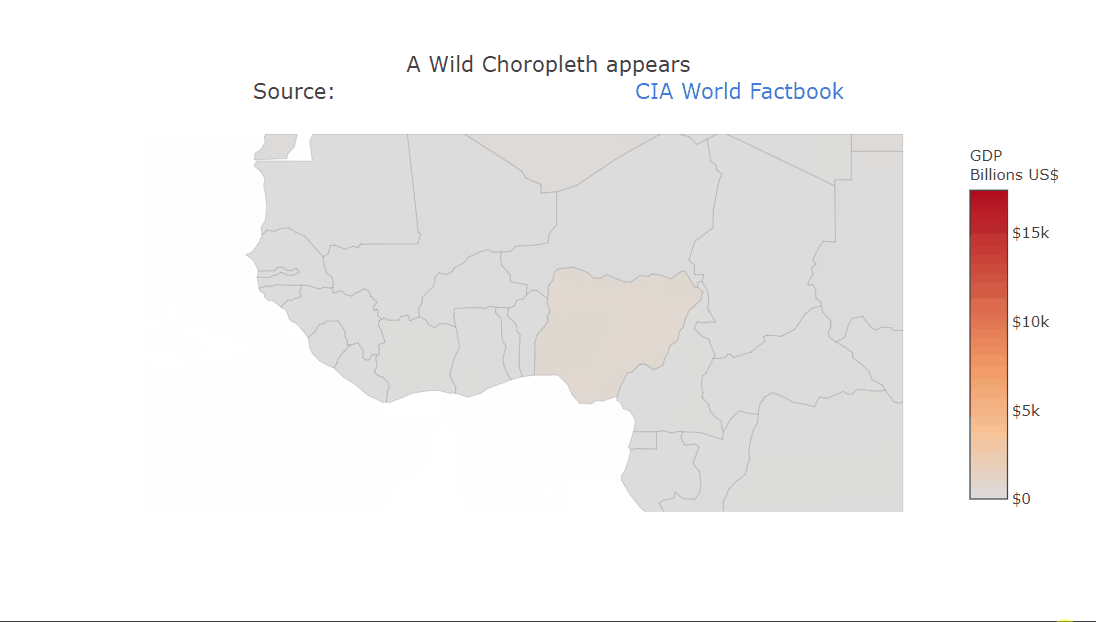
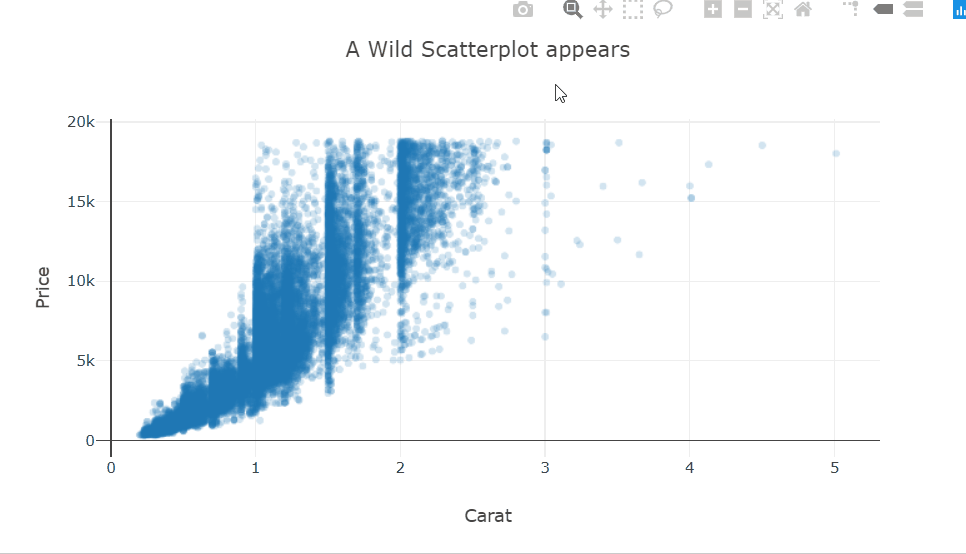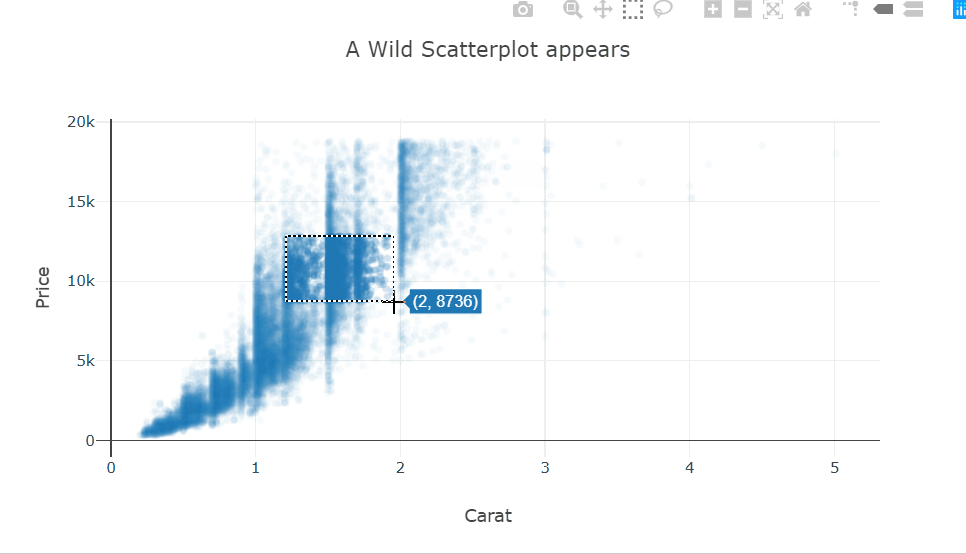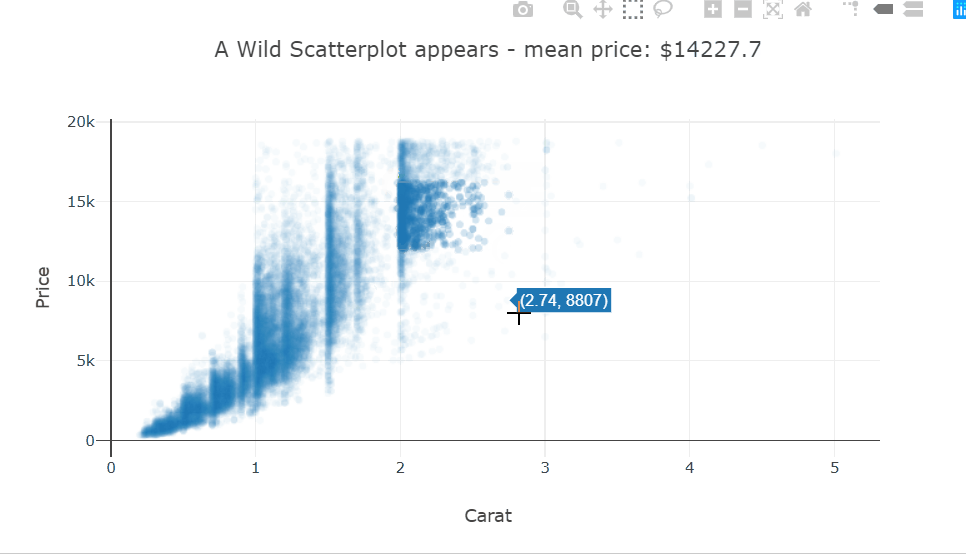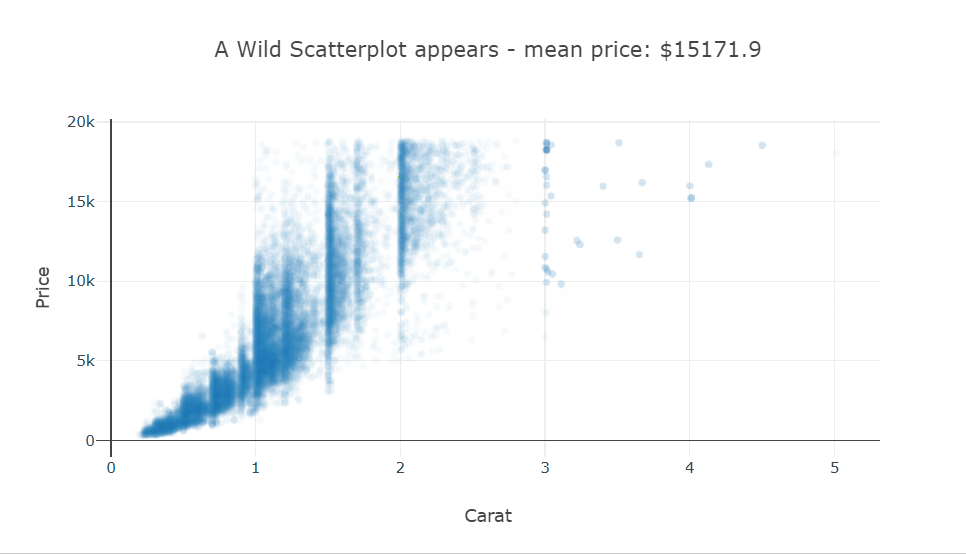
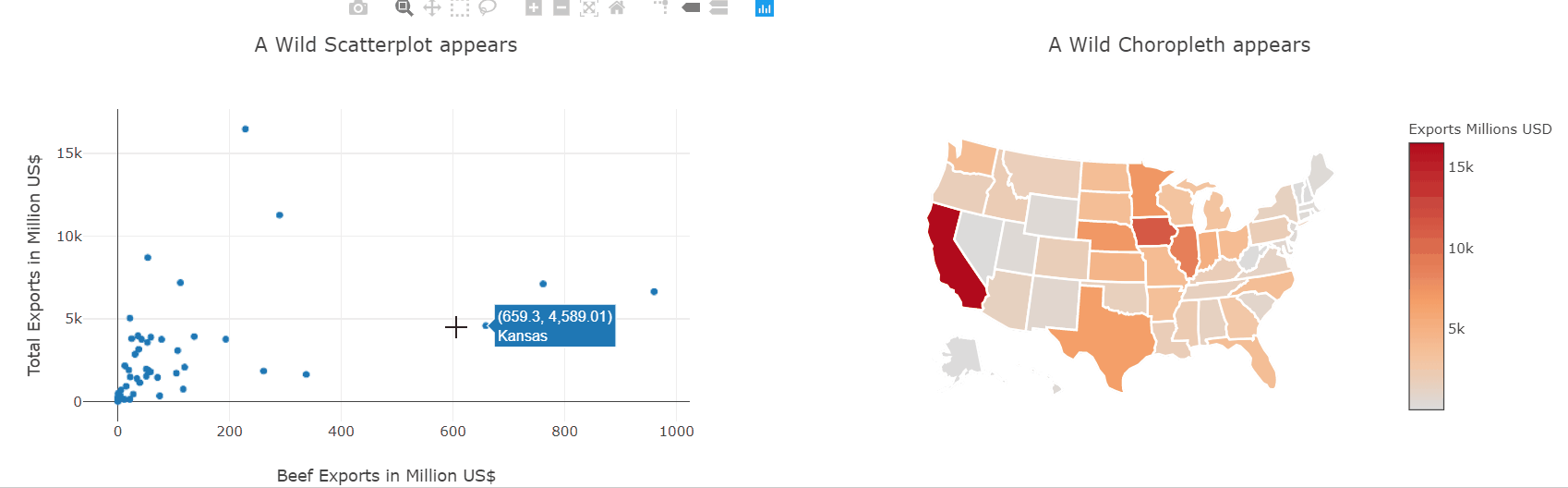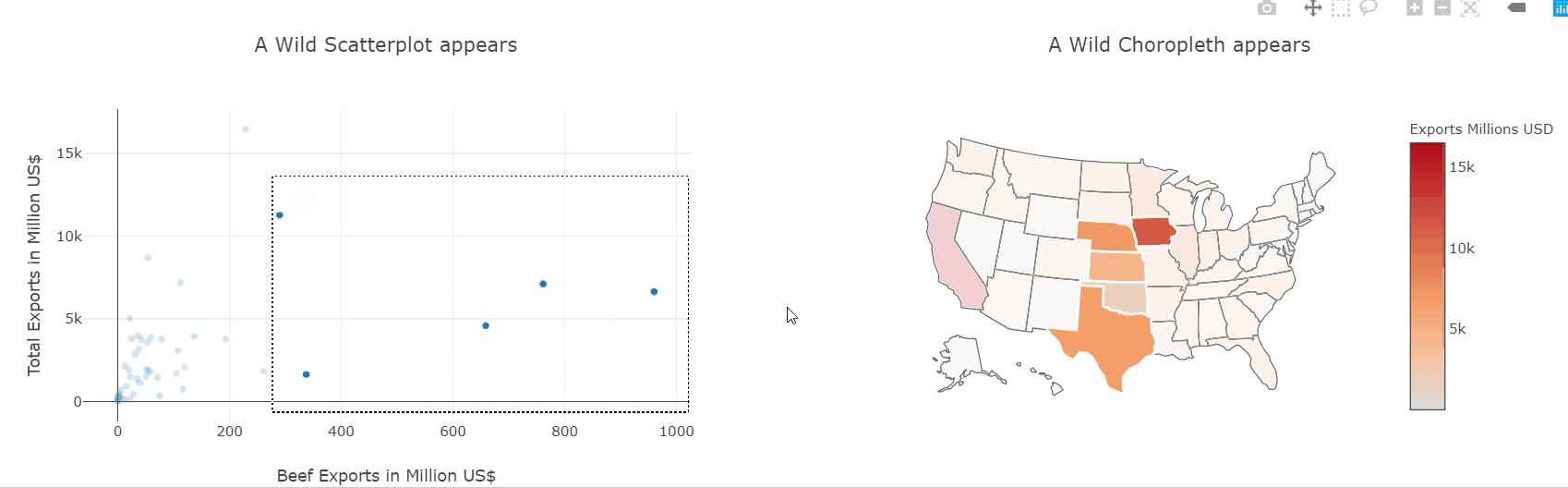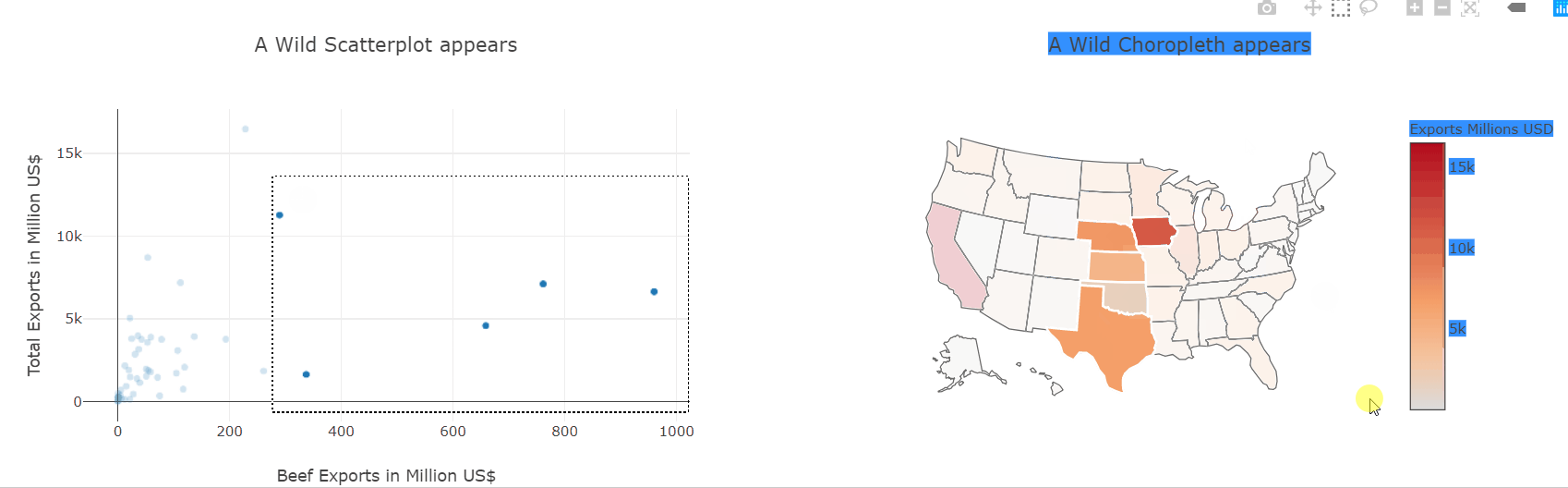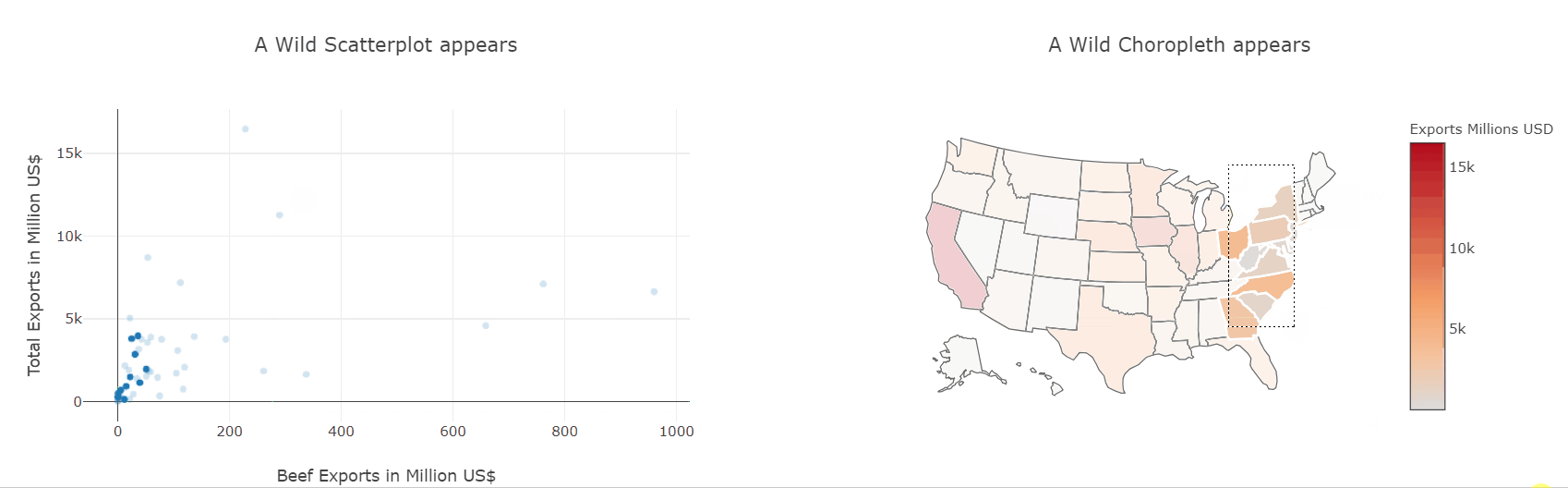
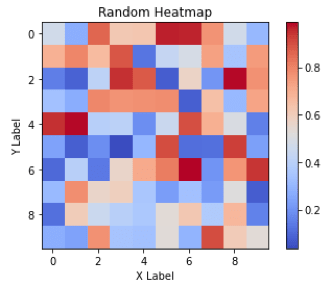
Heatmaps are a type of data visualization that uses color to represent data values. For the unversed,
data visualization is the process of representing data in a visual format. This can be done through charts, graphs, maps, and other visual representations.
What are heatmaps?
A heatmap is a graphical representation of data in which values are represented as colors on a two-dimensional plane. Typically, heatmaps are used to visualize data in a way that makes it easy to identify patterns and trends.
Heatmaps are often used in fields such as data analysis, biology, and finance. In data analysis, heatmaps are used to visualize patterns in large datasets, such as website traffic or user behavior.
In biology, heatmaps are used to visualize gene expression data or protein-protein interaction networks. In finance, heatmaps are used to visualize stock market trends and performance. This diagram shows a random 10×10 heatmap using `NumPy` and `Matplotlib`.
Advantages of heatmaps
- Visual representation: Heatmaps provide an easily understandable visual representation of data, enabling quick interpretation of patterns and trends through color-coded values.
- Large data visualization: They excel at visualizing large datasets, simplifying complex information and facilitating analysis.
- Comparative analysis: They allow for easy comparison of different data sets, highlighting differences and similarities between, for example, website traffic across pages or time periods.
- Customizability: They can be tailored to emphasize specific values or ranges, enabling focused examination of critical information.
- User-friendly: They are intuitive and accessible, making them valuable across various fields, from scientific research to business analytics.
- Interactivity: Interactive features like zooming, hover-over details, and data filtering enhance the usability of heatmaps.
- Effective communication: They offer a concise and clear means of presenting complex information, enabling effective communication of insights to stakeholders.
Creating heatmaps using “Matplotlib”
We can create heatmaps using Matplotlib by following the aforementioned steps:
- To begin, we import the necessary libraries, namely Matplotlib and NumPy.
- Following that, we define our data as a 3×3 NumPy array.
- Afterward, we utilize Matplotlib’s imshow function to create a heatmap, specifying the color map as ‘coolwarm’.
- To enhance the visualization, we incorporate a color bar by employing Matplotlib’s colorbar function.
- Subsequently, we set the title and axis labels using Matplotlib’s set_title, set_xlabel, and set_ylabel functions.
- Lastly, we display the plot using the show function.
Bottom line: This will create a simple 3×3 heatmap with a color bar, title, and axis labels.
Customizations available in Matplotlib for heatmaps
Following is a list of the customizations available for Heatmaps in Matplotlib:
- Changing the color map
- Changing the axis labels
- Changing the title
- Adding a color bar
- Adjusting the size and aspect ratio
- Setting the minimum and maximum values
- Adding annotations
- Adjusting the cell size
- Masking certain cells
- Adding borders
These are just a few examples of the many customizations that can be done in heatmaps using Matplotlib. Now, let’s see all the customizations being implemented in a single example code snippet:
In this example, the heatmap is customized in the following ways:
- Set the colormap to ‘coolwarm’
- Set the minimum and maximum values of the colormap using `vmin` and `vmax`
- Set the size of the figure using `figsize`
- Set the extent of the heatmap using `extent`
- Set the linewidth of the heatmap using `linewidth`
- Add a colorbar to the figure using the `colorbar`
- Set the title, xlabel, and ylabel using `set_title`, `set_xlabel`, and `set_ylabel`, respectively
- Add annotations to the heatmap using `text`
- Mask certain cells in the heatmap by setting their values to `np.nan`
- Show the frame around the heatmap using `set_frame_on(True)`
Creating heatmaps using “Seaborn”
We can create heatmaps using Seaborn by following the aforementioned steps:
- First, we import the necessary libraries:
seaborn,matplotlib, andnumpy. - Next, we generate a random 10×10 matrix of numbers using NumPy’s
randfunction and store it in the variabledata. - We create a heatmap by using Seaborn’s
heatmapfunction. It takes thedataas input and specifies the color map using thecmapparameter. Additionally, we set theannotparameter toTrueto display the values in each cell of the heatmap. - To enhance the plot, we add a title, x-label, and y-label using Matplotlib’s
title,xlabel, andylabelfunctions. - Finally, we display the plot using the
showfunction from Matplotlib.
Overall, the code generates a random heatmap using Seaborn with a color map, annotations, and labels using Matplotlib.
Customizations available in Seaborn for heatmaps:
Following is a list of the customizations available for Heatmaps in Seaborn:
- Change the color map
- Add annotations to the heatmap cells
- Adjust the size of the heatmap
- Display the actual numerical values of the data in each cell of the heatmap
- Add a color bar to the side of the heatmap
- Change the font size of the heatmap
- Adjust the spacing between cells
- Customize the x-axis and y-axis labels
- Rotate the x-axis and y-axis tick labels
Now, let’s see all the customizations being implemented in a single example code snippet:
In this example, the heatmap is customized in the following ways:
- Set the color palette to “Blues”.
- Add annotations with a font size of 10.
- Set the x and y labels and adjust font size.
- Set the title of the heatmap.
- Adjust the figure size.
- Show the heatmap plot.
Limitations of heatmaps:
Heatmaps are a useful visualization tool for exploring and analyzing data, but they do have some limitations that you should be aware of:
- Limited to two-dimensional data: They are designed to visualize two-dimensional data, which means that they are not suitable for visualizing higher-dimensional data.
- Limited to continuous data: They are best suited for continuous data, such as numerical values, as they rely on a color scale to convey the information. Categorical or binary data may not be as effectively visualized using heatmaps.
- May be affected by color blindness: Some people are color blind, which means that they may have difficulty distinguishing between certain colors. This can make it difficult for them to interpret the information in a heatmap.
- Can be sensitive to scaling: The color mapping in a heatmap is sensitive to the scale of the data being visualized. Therefore, it is important to carefully choose the color scale and to consider normalizing or standardizing the data to ensure that the heatmap accurately represents the underlying data.
- Can be misleading: They can be visually appealing and highlight patterns in the data, but they can also be misleading if not carefully designed. For example, choosing a poor color scale or omitting important data points can distort the visual representation of the data.
It is important to consider these limitations when deciding whether or not to use a heatmap for visualizing your data.
Conclusion
Heatmaps are powerful tools for visualizing data patterns and trends. They find applications in various fields, enabling easy interpretation and analysis of large datasets. Matplotlib and Seaborn offer flexible options to create and customize heatmaps. However, it’s essential to understand their limitations, such as two-dimensional data representation and sensitivity to color perception. By considering these factors, heatmaps can be a valuable asset in gaining insights and communicating information effectively.
Written by Safia Faiz