
In the rapidly evolving landscape of artificial intelligence, open-source large language models (LLMs) are emerging as pivotal tools for democratizing AI technology and fostering innovation.
These models offer unparalleled accessibility, allowing researchers, developers, and organizations to train, fine-tune, and deploy sophisticated AI systems without the constraints imposed by proprietary solutions.
Open-source LLMs are not just about code transparency; they represent a collaborative effort to push the boundaries of what AI can achieve, ensuring that advancements are shared and built upon by the global community.
Llama 3.1, the latest release from Meta Platforms Inc., epitomizes the potential and promise of open-source LLMs. With a staggering 405 billion parameters, Llama 3.1 is designed to compete with the best-closed models from tech giants like OpenAI and Anthropic PBC.

In this blog, we will explore all the information you need to know about Llama 3.1 and its impact on the world of LLMs.
What is Llama 3.1?
Llama 3.1 is Meta Platforms Inc.’s latest and most advanced open-source artificial intelligence model. Released in July 2024, the LLM is designed to compete with some of the most powerful closed models on the market, such as those from OpenAI and Anthropic PBC.
The release of Llama 3.1 marks a significant milestone in the large language model (LLM) world by democratizing access to advanced AI technology. It is available in three versions—405B, 70B, and 8B parameters—each catering to different computational needs and use cases.
The model’s open-source nature not only promotes transparency and collaboration within the AI community but also provides an affordable and efficient alternative to proprietary models.
Here’s a comparison between open-source and closed-source LLMs
Meta has taken steps to ensure the model’s safety and usability by integrating rigorous safety systems and making it accessible through various cloud providers. This release is expected to shift the industry towards more open-source AI development, fostering innovation and potentially leading to breakthroughs that benefit society as a whole.
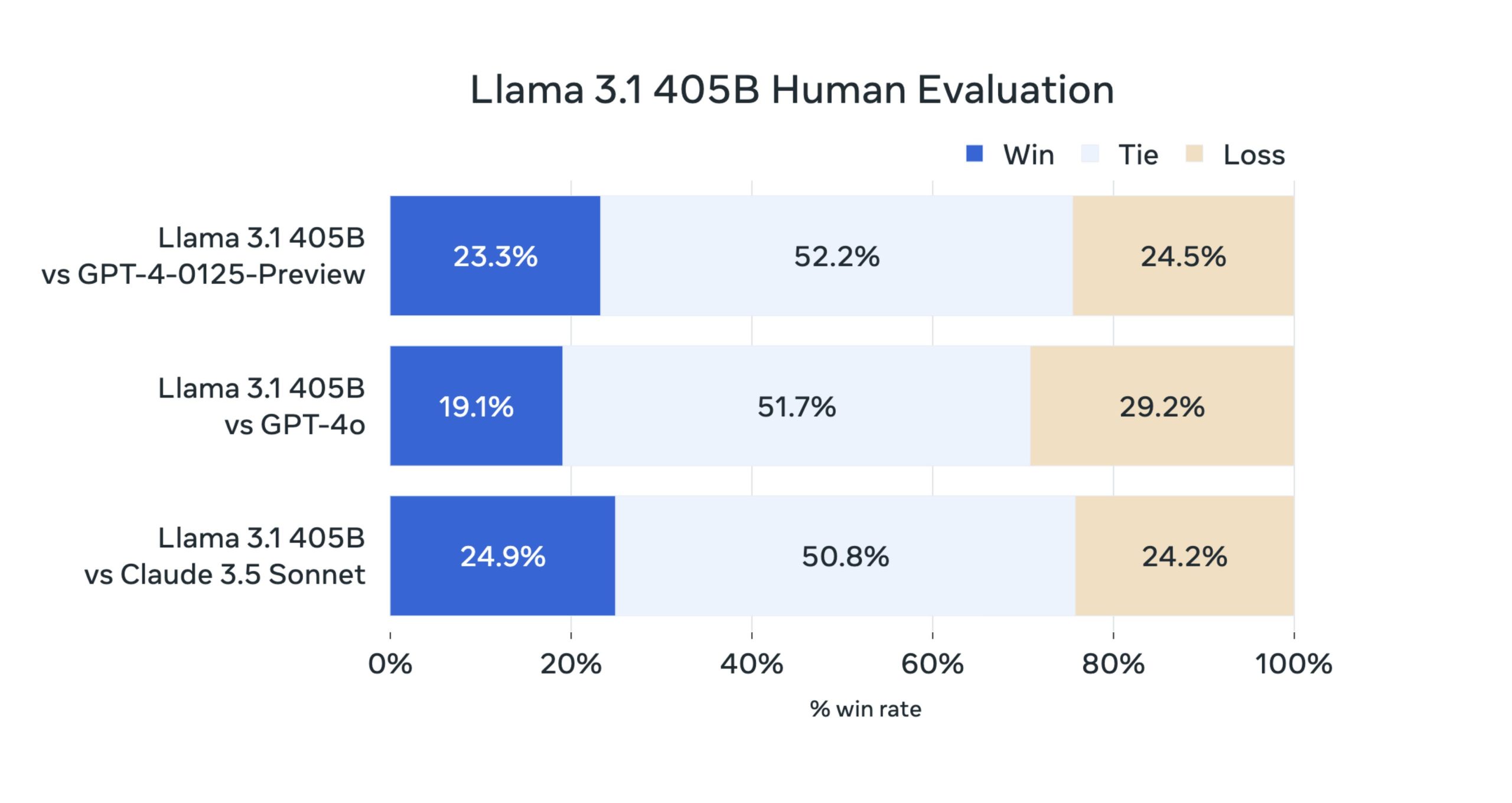
Benchmark Tests
-
- GSM8K: Llama 3.1 beats models like Claude 3.5 and GPT-4o in GSM8K, which tests math word problems.
- Nexus: The model also outperforms these competitors in Nexus benchmarks.
- HumanEval: Llama 3.1 remains competitive in HumanEval, which assesses the model’s ability to generate correct code solutions.
- MMLU: It performs well on the Massive Multitask Language Understanding (MMLU) benchmark, which evaluates a model’s ability to handle a wide range of topics and tasks.
Architecture of Llama 3.1
The architecture of Llama 3.1 is built upon a standard decoder-only transformer model, which has been adapted with some minor changes to enhance its performance and usability. Some key aspects of the architecture include:
- Decoder-Only Transformer Model:
- Llama 3.1 utilizes a decoder-only transformer model architecture, which is a common framework for language models. This architecture is designed to generate text by predicting the next token in a sequence based on the preceding tokens.
- Parameter Size:
- The model has 405 billion parameters, making it one of the largest open-source AI models available. This extensive parameter size allows it to handle complex tasks and generate high-quality outputs.
- Training Data and Tokens:
- Llama 3.1 was trained on more than 15 trillion tokens. This extensive training dataset helps the model to learn and generalize from a vast amount of information, improving its performance across various tasks.
- Quantization and Efficiency:
- For users interested in model efficiency, Llama 3.1 supports fp8 quantization, which requires the fbgemm-gpu package and torch >= 2.4.0. This feature helps to reduce the model’s computational and memory requirements while maintaining performance.
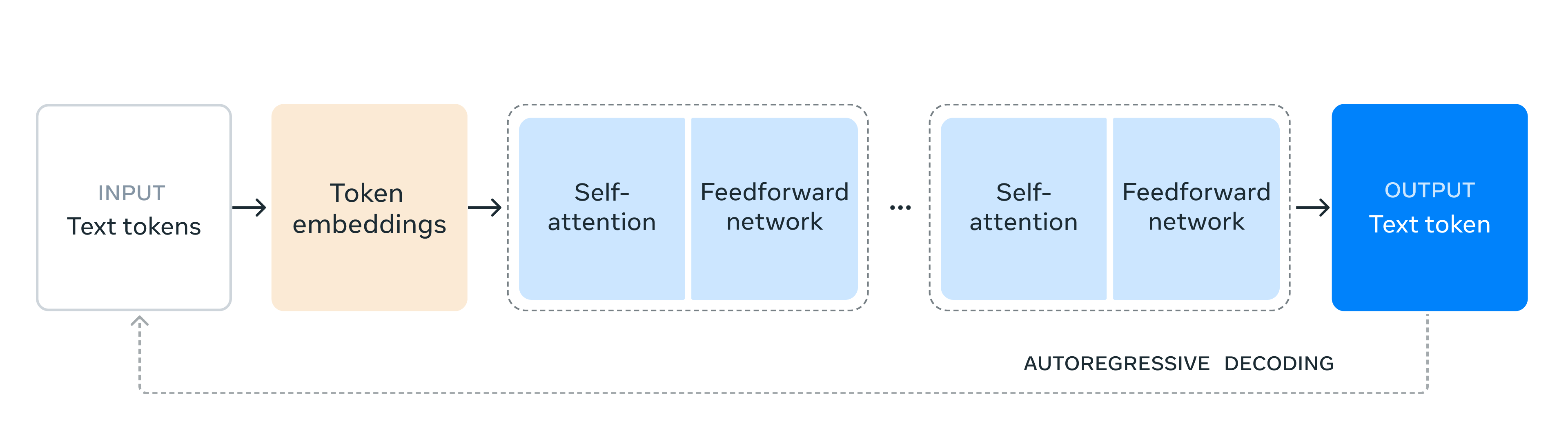
These architectural choices make Llama 3.1 a robust and versatile AI model capable of performing a wide range of tasks with high efficiency and safety.
Revisit and read about Llama 3 and Meta AI
Three Main Models in the Llama 3.1 Family
Llama 3.1 includes three different models, each with varying parameter sizes to cater to different needs and use cases. These models are the 405B, 70B, and 8B versions.
405B Model
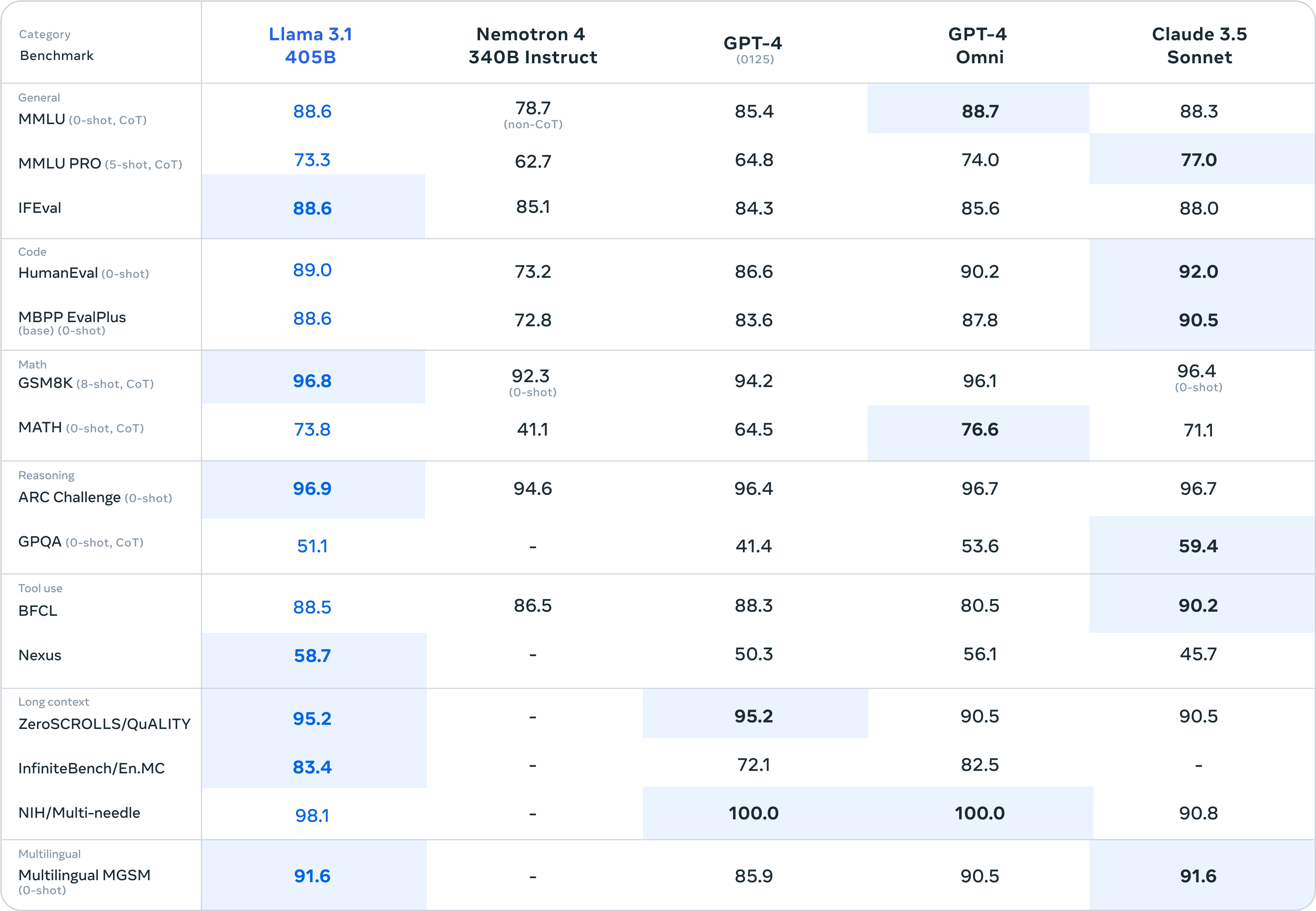
This model is the largest in the Llama 3.1 lineup, boasting 405 billion parameters. The model is designed for highly complex tasks that require extensive processing power. It is suitable for applications such as multilingual conversational agents, long-form text summarization, and other advanced AI tasks.
The LLM model excels in general knowledge, math, tool use, and multilingual translation. Despite its large size, Meta has made this model open-source and accessible through various platforms, including Hugging Face, GitHub, and several cloud providers like AWS, Nvidia, Microsoft Azure, and Google Cloud.
70B Model
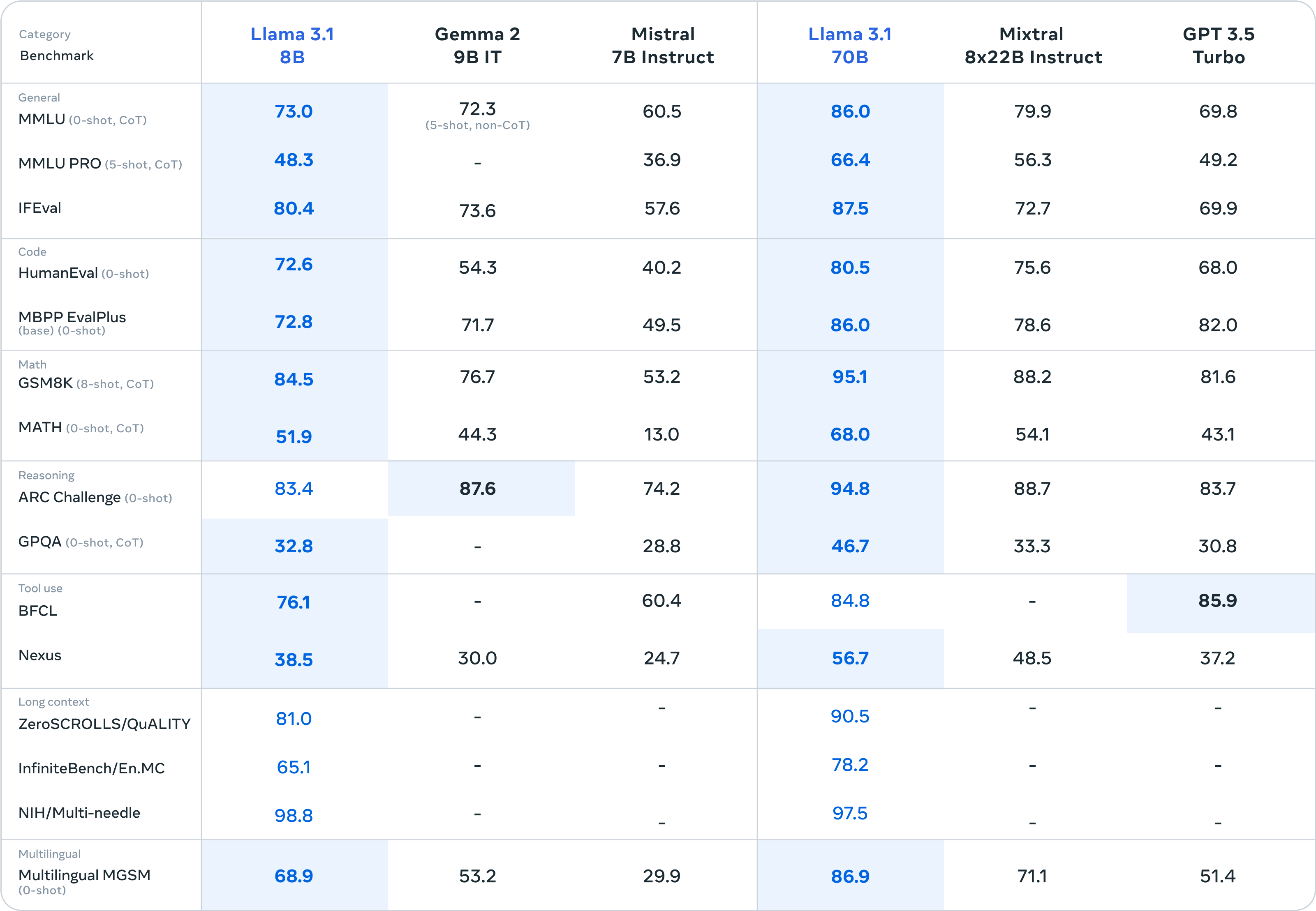
The 70B model has 70 billion parameters, making it significantly smaller than the 405B model but still highly capable. It is suitable for tasks that require a balance between performance and computational efficiency. It can handle advanced reasoning, long-form summarization, multilingual conversation, and coding capabilities.
Like the 405B model, the 70B version is also open-source and available for download and use on various platforms. However, it requires substantial hardware resources, typically around 8 GPUs, to run effectively.
8B Model
With 8 billion parameters, the 8B model is the smallest in the Llama 3.1 family. This smaller size makes it more accessible for users with limited computational resources.
This model is ideal for tasks that require less computational power but still need a robust AI capability. It is suitable for on-device tasks, classification tasks, and other applications that need smaller, more efficient models.
It can be run on a single GPU, making it the most accessible option for users with limited hardware resources. It is also open-source and available through the same platforms as the larger models.
Key Features of Llama 3.1

Meta has packed its latest LLM with several key features that make it a powerful and versatile tool in the realm of AI Below are the primary features of Llama 3.1:
Multilingual Support
The model supports eight new languages, including French, German, Hindi, Italian, Portuguese, and Spanish, among others. This expands its usability across different linguistic and cultural contexts.
Extended Context Window
It has a 128,000-token context window, which allows it to process long sequences of text efficiently. This feature is particularly beneficial for applications such as long-form summarization and multilingual conversation.
Learn more about the LLM context window paradox
State-of-the-Art Capabilities
Llama 3.1 excels in tasks such as general knowledge, mathematics, tool use, and multilingual translation. It is competitive with leading closed models like GPT-4 and Claude 3.5 Sonnet.
Safety Measures
Meta has implemented rigorous safety testing and introduced tools like Llama Guard to moderate the output and manage the risks of misuse. This includes prompt injection filters and other safety systems to ensure responsible usage.
Availability on Multiple Platforms
Llama 3.1 can be downloaded from Hugging Face, GitHub, or directly from Meta. It is also accessible through several cloud providers, including AWS, Nvidia, Microsoft Azure, and Google Cloud, making it versatile and easy to deploy.
Efficiency and Cost-Effectiveness
Developers can run inference on Llama 3.1 405B on their own infrastructure at roughly 50% of the cost of using closed models like GPT-4o, making it an efficient and affordable option.
These features collectively make Llama 3.1 a robust, accessible, and highly capable AI model, suitable for a wide range of applications from research to practical deployment in various industries.
What Safety Measures are Included in the LLM?
Llama 3.1 incorporates several safety measures to ensure that the model’s outputs are secure and responsible. Here are the key safety features included:
- Risk Assessments and Safety Evaluations: Before releasing Llama 3.1, Meta conducted multiple risk assessments and safety evaluations. This included extensive red-teaming with both internal and external experts to stress-test the model.
- Multilingual Capabilities Evaluation: Meta scaled its evaluations across the model’s multilingual capabilities to ensure that outputs are safe and sensible beyond English.
- Prompt Injection Filter: A new prompt injection filter has been added to mitigate risks associated with harmful inputs. Meta claims that this filter does not impact the quality of responses.
- Llama Guard: This built-in safety system filters both input and output. It helps shift safety evaluation from the model level to the overall system level, allowing the underlying model to remain broadly steerable and adaptable for various use cases.
- Moderation Tools: Meta has released tools to help developers keep Llama models safe by moderating their output and blocking attempts to break restrictions.
- Case-by-Case Model Release Decisions: Meta plans to decide on the release of future models on a case-by-case basis, ensuring that each model meets safety standards before being made publicly available.
These measures collectively aim to make Llama 3.1 a safer and more reliable model for a wide range of applications.
How Does Llama 3.1 Address Environmental Sustainability Concerns?
Meta has placed environmental sustainability at the center of the LLM’s development by focusing on model efficiency rather than merely increasing model size.
Some key areas to ensure the models remained environment-friendly include:
Efficiency Innovations
Victor Botev, co-founder and CTO of Iris.ai, emphasizes that innovations in model efficiency might benefit the AI community more than simply scaling up to larger sizes. Efficient models can achieve similar or superior results while reducing costs and environmental impact.
Open Source Nature
It allows for broader scrutiny and optimization by the community, leading to more efficient and environmentally friendly implementations. By enabling researchers and developers worldwide to explore and innovate, the model fosters an environment where efficiency improvements can be rapidly shared and adopted.
Read more about the rise of open-source language models
Access to Advanced Models
Meta’s approach of making Llama 3.1 open source and available through various cloud providers, including AWS, Nvidia, Microsoft Azure, and Google Cloud, ensures that the model can be run on optimized infrastructure that may be more energy-efficient compared to on-premises solutions.
Synthetic Data Generation and Model Distillation
The Llama 3.1 model supports new workflows like synthetic data generation and model distillation, which can help in creating smaller, more efficient models that maintain high performance while being less resource-intensive.
By focusing on efficiency and leveraging the collaborative power of the open-source community, Llama 3.1 aims to mitigate the environmental impact often associated with large AI models.
Future Prospects and Community Impact
The future prospects of Llama 3.1 are promising, with Meta envisioning a significant impact on the global AI community. Meta aims to democratize AI technology, allowing researchers, developers, and organizations worldwide to harness its power without the constraints of proprietary systems.
Meta is actively working to grow a robust ecosystem around Llama 3.1 by partnering with leading technology companies like Amazon, Databricks, and NVIDIA. These collaborations are crucial in providing the necessary infrastructure and support for developers to fine-tune and distill their own models using Llama 3.1.
For instance, Amazon, Databricks, and NVIDIA are launching comprehensive suites of services to aid developers in customizing the models to fit their specific needs.

This ecosystem approach not only enhances the model’s utility but also promotes a diverse range of applications, from low-latency, cost-effective inference serving to specialized enterprise solutions offered by companies like Scale.AI, Dell, and Deloitte.
By fostering such a vibrant ecosystem, Meta aims to make Llama 3.1 the industry standard, driving widespread adoption and innovation.
Ultimately, Meta envisions a future where open-source AI drives economic growth, enhances productivity, and improves quality of life globally, much like how Linux transformed cloud computing and mobile operating systems.