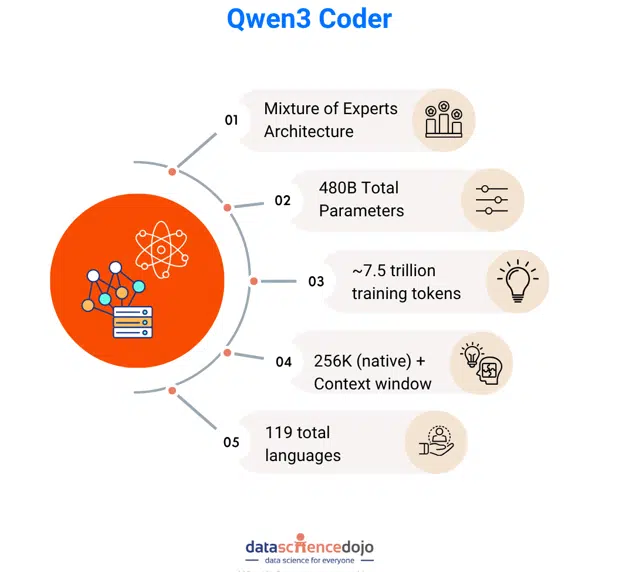
Qwen3 Coder is quickly emerging as one of the most powerful open-source AI models dedicated to code generation and software engineering. Developed by Alibaba’s Qwen team, this model represents a significant leap forward in the field of large language models (LLMs). It integrates an advanced Mixture-of-Experts (MoE) architecture, extensive reinforcement learning post-training, and a massive context window to enable highly intelligent, scalable, and context-aware code generation.
Released in July 2025 under the permissive Apache 2.0 license, Qwen3 Coder is poised to become a foundation model for enterprise-grade AI coding tools, intelligent agents, and automated development pipelines. Whether you’re an AI researcher, developer, or enterprise architect, understanding how Qwen3 Coder works will give you a competitive edge in building next-generation AI-driven software solutions.
What Is Qwen3 Coder?
Qwen3 Coder is a specialized variant of the Qwen3 language model series. It is fine-tuned specifically for programming-related tasks such as code generation, review, translation, documentation, and agentic tool use. What sets it apart is the architectural scalability paired with intelligent behavior in handling multi-step tasks, context-aware planning, and long-horizon code understanding.
Backed by Alibaba’s research in MoE transformers, agentic reinforcement learning, and tool-use integration, Qwen3 Coder is trained on over 7.5 trillion tokens—more than 70% of which are code. It supports over 100 programming and natural languages and has been evaluated on leading benchmarks like SWE-Bench Verified, CodeForces ELO, and LiveCodeBench v5.
Check out this comprehensive guide to large language models
Key Features of Qwen3 Coder
Mixture-of-Experts (MoE) Architecture
Qwen3 Coder’s flagship variant, Qwen3-Coder-480B-A35B-Instruct, employs a 480-billion parameter Mixture-of-Experts transformer. During inference, it activates only 35 billion parameters by selecting 8 out of 160 expert networks. This design drastically reduces computation while retaining accuracy and fluency, enabling enterprises and individual developers to run the model more efficiently.
Reinforcement Learning with Agentic Planning
Qwen3 Coder undergoes post-training with advanced reinforcement learning techniques, including both Code RL and long-horizon RL. It is fine-tuned in over 20,000 parallel environments where it learns to make decisions across multiple steps, handle tools, and interact with browser-like environments. This makes the model highly effective in scenarios like automated pull requests, multi-stage debugging, and planning entire code modules.
Want to take your RAG pipelines to the next level, check out this guide on agentic RAG
Massive Context Window
One of Qwen3 Coder’s most distinguishing features is its native support for 256,000-token context windows, which can be extended up to 1 million tokens using extrapolation methods like YaRN. This allows the model to process entire code repositories, large documentation files, and interconnected project files in a single pass, enabling deeper understanding and coherence.
Multi-Language and Framework Support
The model supports code generation and translation across a wide range of programming languages including Python, JavaScript, Java, C++, Go, Rust, and many others. It is capable of adapting code between frameworks and converting logic across platforms. This flexibility is critical for organizations that operate in polyglot environments or maintain cross-platform applications.
Developer Integration and Tooling
Qwen3 Coder can be integrated directly into popular IDEs like Visual Studio Code and JetBrains IDEs. It also offers an open-source CLI tool via npm (@qwen-code/qwen-code), which enables seamless access to the model’s capabilities via the terminal. Moreover, Qwen3 Coder supports API-based integration into CI/CD pipelines and internal developer tools.
Documentation and Code Commenting
The model excels at generating inline code comments, README files, and comprehensive API documentation. This ability to translate complex logic into natural language documentation reduces technical debt and ensures consistency across large-scale software projects.
Security Awareness
While Qwen3 Coder is not explicitly trained as a security analyzer, it can identify common software vulnerabilities such as SQL injections, cross-site scripting (XSS), and unsafe function usage. It can also recommend best practices for secure coding, helping developers catch potential issues before deployment.
For a deeper understanding of how finetuning LLMs work, check out this guide
Model Architecture and Training
Qwen3 Coder is built on top of a highly modular transformer architecture optimized for scalability and flexibility. The 480B MoE variant contains 160 expert modules with 62 transformer layers and grouped-query attention mechanisms. Only a fraction of the experts (8 at a time) are active during inference, reducing computational demands significantly.
Training involved a curated dataset of 7.5 trillion tokens, with code accounting for the majority of the training data. The model was trained in both English and multilingual settings and has a solid understanding of natural language programming instructions. After supervised fine-tuning, the model underwent agentic reinforcement learning with thousands of tool-use environments, leading to more grounded, executable, and context-aware code generation.
Benchmark Results
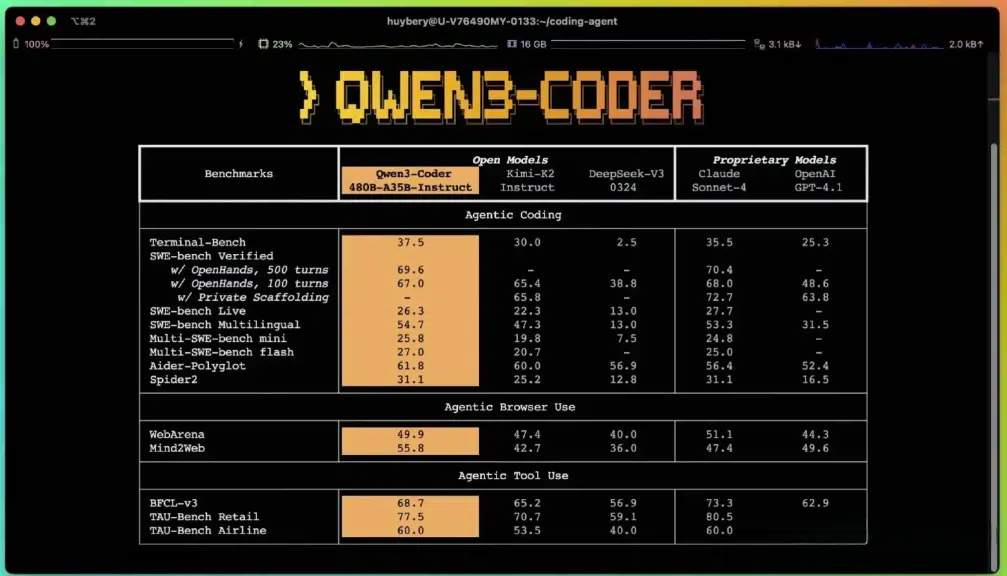
Qwen3 Coder has demonstrated leading performance across a number of open-source and agentic AI benchmarks:
- SWE-Bench Verified: Alibaba reports state-of-the-art performance among open-source models, with no test-time augmentation.
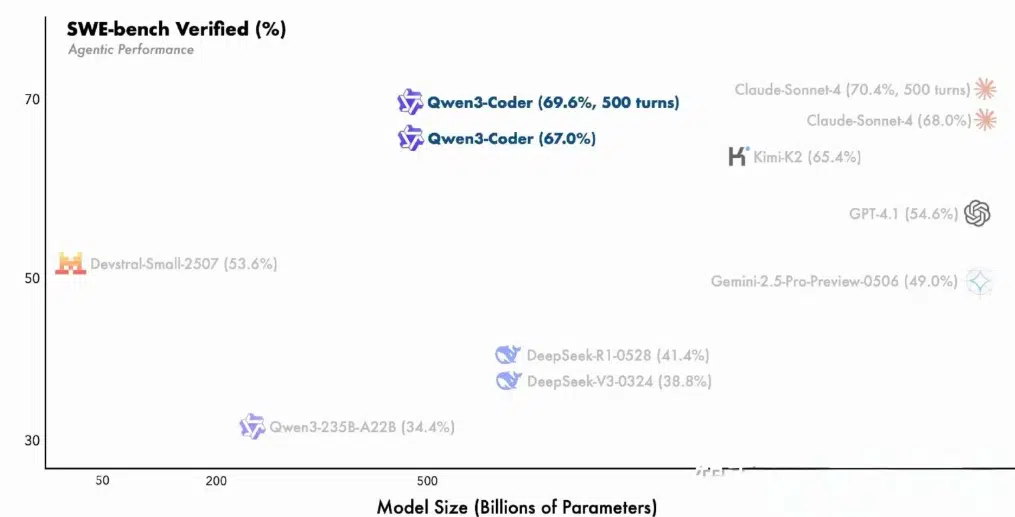
- CodeForces ELO: Qwen3 Coder leads open-source coding models in competitive programming tasks.
- LiveCodeBench v5: Excels at real-world code completion, editing, and translation.
- BFCL Tool Use Benchmarks: Performs reliably in browser-based tool-use environments and multistep reasoning tasks.
Although Alibaba has not publicly released exact pass rate percentages, several independent blogs and early access reports suggest Qwen3 Coder performs comparably to or better than models like Claude Sonnet 4 and GPT-4 on complex multi-turn agentic tasks.
Real-World Applications of Qwen3 Coder
AI Coding Assistants
Developers can integrate Qwen3 Coder into their IDEs or terminal environments to receive live code suggestions, function completions, and documentation summaries. This significantly improves coding speed and reduces the need for repetitive tasks.
Automated Code Review and Debugging
The model can analyze entire codebases to identify inefficiencies, logic bugs, and outdated practices. It can generate pull requests and make suggestions for optimization and refactoring, which is particularly useful in maintaining large legacy codebases.
Multi-Language Development
For teams working in multilingual codebases, Qwen3 Coder can translate code between languages while preserving structure and logic. This includes adapting syntax, optimizing library calls, and reformatting for platform-specific constraints.
Project Documentation
Qwen3 Coder can generate or update technical documentation automatically, producing consistent README files, docstrings, and architectural overviews. This feature is invaluable for onboarding new team members and improving project maintainability.
Secure Code Generation
While not a formal security analysis tool, Qwen3 Coder can help detect and prevent common coding vulnerabilities. Developers can use it to review risky patterns, update insecure dependencies, and implement best security practices across the stack.
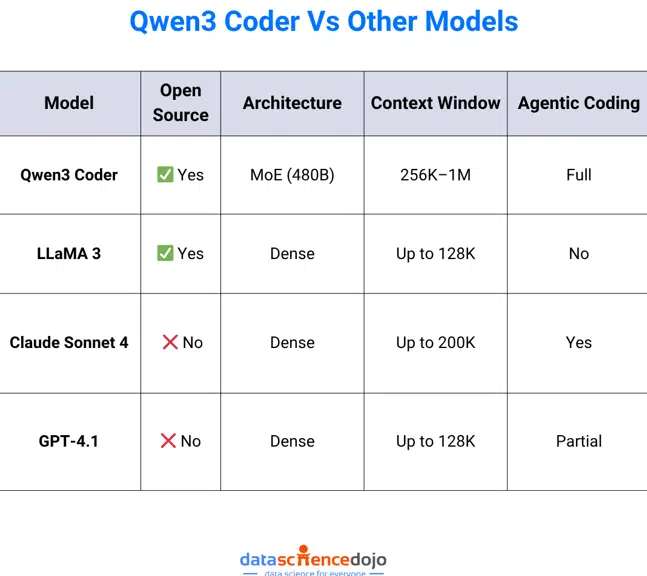
Qwen3 Coder vs. Other Coding Models
Getting Started with Qwen3 Coder
Deployment Options:
-
Cloud Deployment:
- Available via Alibaba Cloud Model Studio and OpenRouter for API access.
- Hugging Face hosts downloadable models for custom deployment.
Local Deployment:
- Quantized models (2-bit, 4-bit) can run on high-end workstations.
- Requires 24GB+ VRAM and 128GB+ RAM for the 480B variant; smaller models available for less powerful hardware.
CLI and IDE Integration:
- Qwen Code CLI (npm package) for command-line workflows.
- Compatible with VS Code, CLINE, and other IDE extensions.
Frequently Asked Questions (FAQ)
Q: What makes Qwen3 Coder different from other LLMs?
A: Qwen3 Coder combines the scalability of MoE, agentic reinforcement learning, and long-context understanding in a single open-source model.
Q: Can I run Qwen3 Coder on my own hardware?
A: Yes. Smaller variants are available for local deployment, including 7B, 14B, and 30B parameter models.
Q: Is the model production-ready?
A: Yes. It has been tested on industry-grade benchmarks and supports integration into development pipelines.
Q: How secure is the model’s output?
A: While not formally audited, Qwen3 Coder offers basic security insights and best practice recommendations.
Conclusion
Qwen3 Coder is redefining what’s possible with open-source AI in software engineering. Its Mixture-of-Experts design, deep reinforcement learning training, and massive context window allow it to tackle the most complex coding challenges. Whether you’re building next-gen dev tools, automating code review, or powering agentic AI systems, Qwen3 Coder delivers the intelligence, scale, and flexibility to accelerate your development process.
For developers and organizations looking to stay ahead in the AI-powered software era, Qwen3 Coder is not just an option—it’s a necessity.
Read more expert insights on Data Science Dojo’s blog.