
Retrieval-augmented generation (RAG) has already reshaped how large language models (LLMs) interact with knowledge. But now, we’re witnessing a new evolution: the rise of RAG agents—autonomous systems that don’t just retrieve information, but plan, reason, and act.
In this guide, we’ll walk through what a rag agent actually is, how it differs from standard RAG setups, and why this new paradigm is redefining intelligent problem-solving.
Want to dive deeper into agentic AI? Explore our full breakdown in this blog.
What is Agentic RAG?
At its core, agentic rag (short for agentic retrieval-augmented generation) combines traditional RAG methods with the decision-making and autonomy of AI agents.
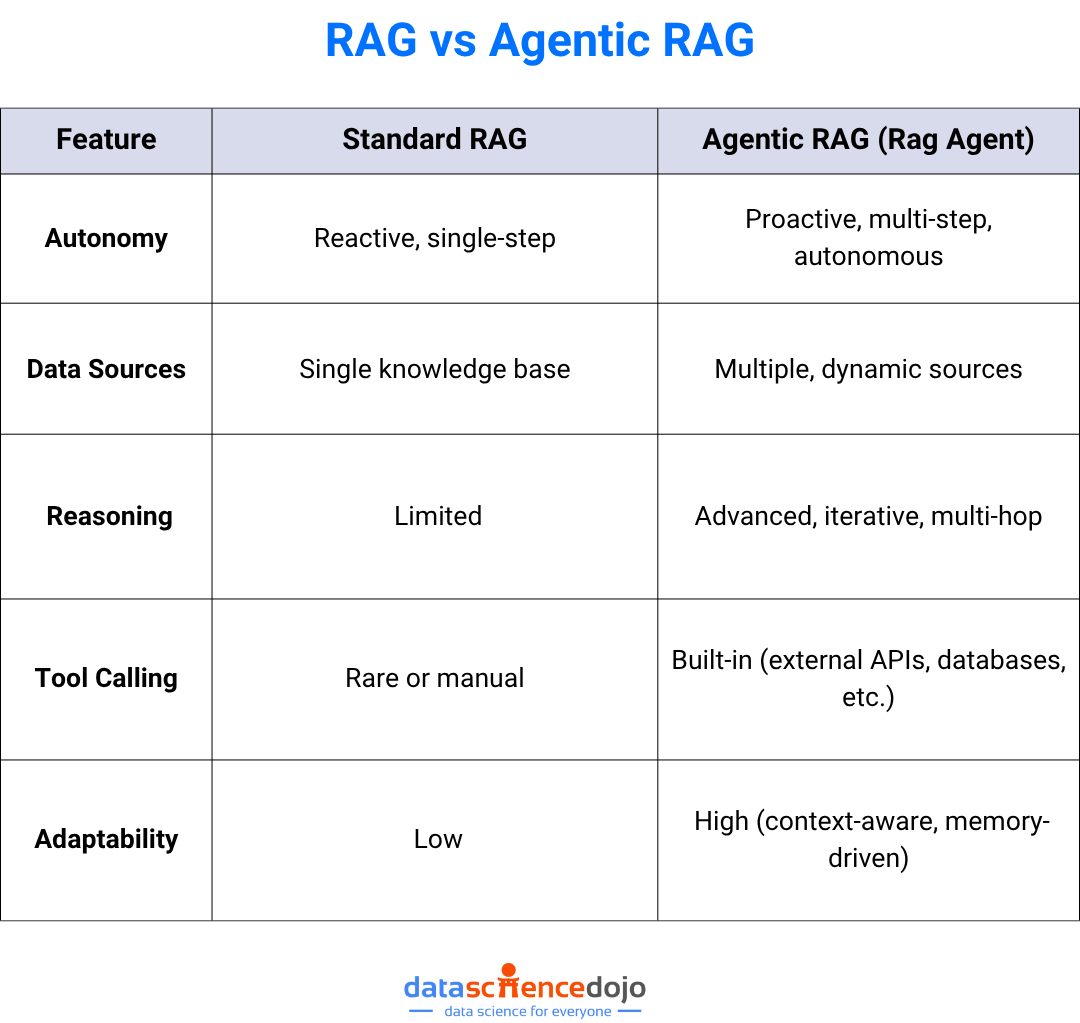
While classic RAG systems retrieve relevant knowledge to improve the responses of LLMs, they remain largely reactive, they answer what you ask but don’t think ahead. A rag agent pushes beyond this. It autonomously breaks down tasks, plans multiple reasoning steps, and dynamically interacts with tools, APIs, and multiple data sources—all with minimal human oversight.
In short: agentic rag isn’t just answering questions; it’s solving problems.
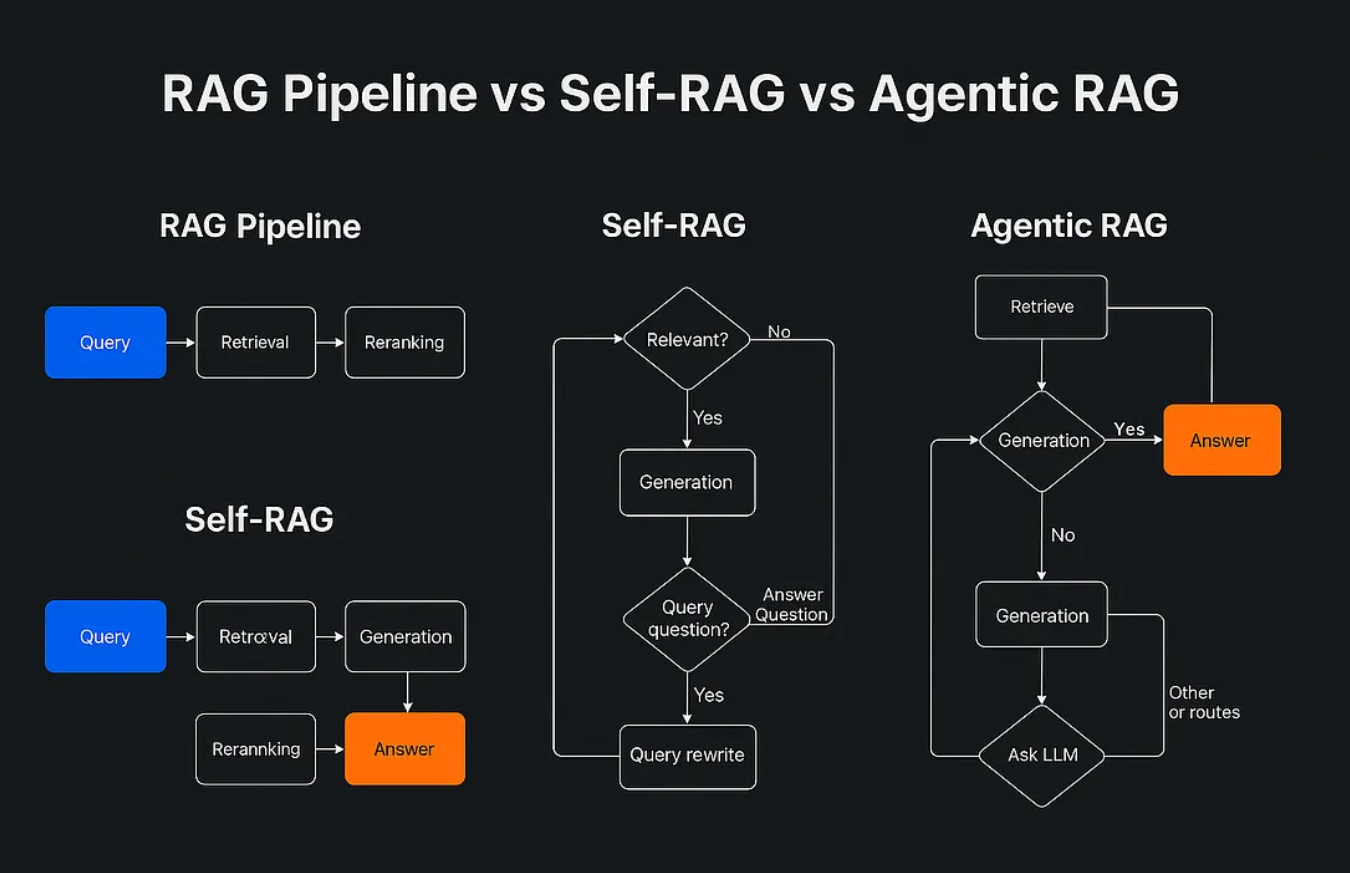
Standard RAG vs. Agentic RAG: What’s the Real Difference?
How Standard RAG Works
Standard RAG pairs an LLM with a retrieval system, usually a vector database, to ground its responses in real-world, up-to-date information. Here’s what typically happens:
-
Retrieval: Query embeddings are matched against a vector store to pull in relevant documents.
-
Augmentation: These documents are added to the prompt context.
-
Generation: The LLM uses the combined context to generate a more accurate, grounded answer.
This flow works well, especially for answering straightforward questions or summarizing known facts. But it’s fundamentally single-shot—there’s no planning, no iteration, no reasoning loop.
How Agentic RAG Steps It Up
Agentic RAG injects autonomy into the process. Now, you’re not just retrieving information, you’re orchestrating an intelligent agent to:
-
Break down queries into logical sub-tasks.
-
Strategize which tools or APIs to invoke.
-
Pull data from multiple knowledge bases.
-
Iterate on outputs, validating them step-by-step.
-
Incorporate multimodal data when needed (text, images, even structured tables).
Here’s how the two stack up:
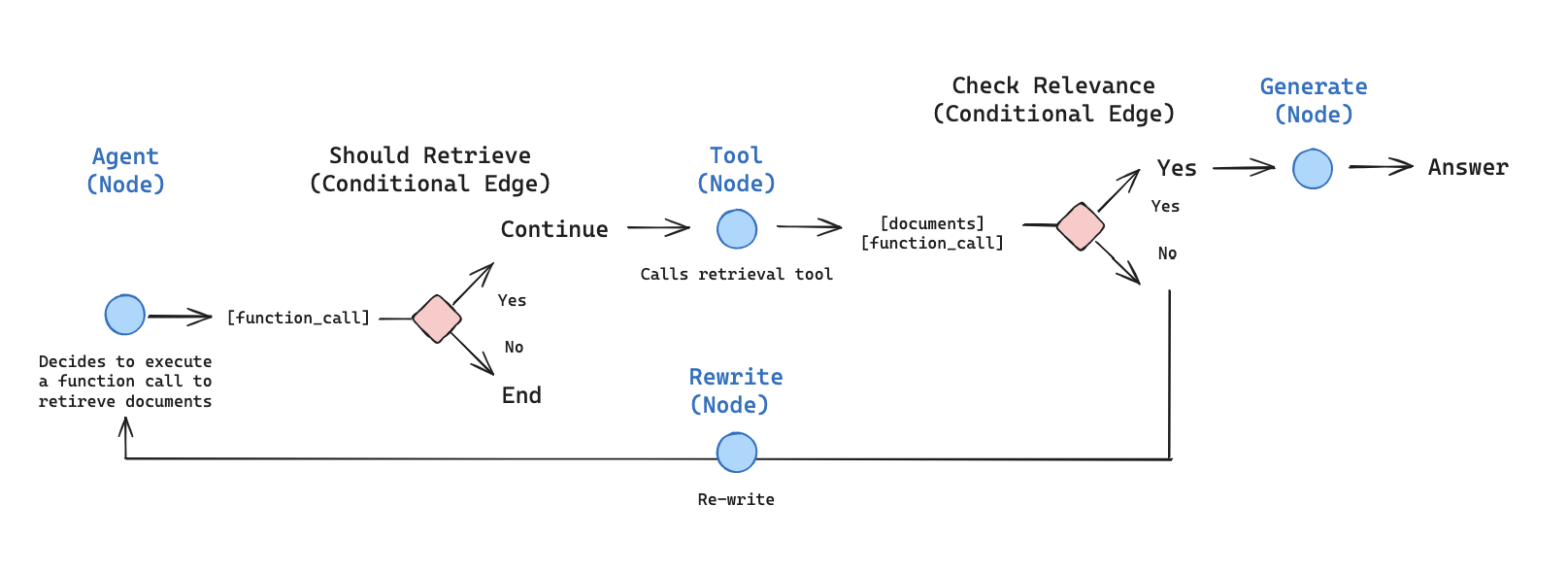
Technical Architecture of Rag Agents
Let’s break down the tech stack that powers rag agents.
Core Components
-
AI Agent Framework: The backbone that handles planning, memory, task decomposition, and action sequencing. Common tools: LangChain, LlamaIndex, LangGraph.
-
Retriever Module: Connects to vector stores or hybrid search systems (dense + sparse) to fetch relevant content.
-
Generator Model: A large language model like GPT-4, Claude, or T5, used to synthesize and articulate final responses.
-
Tool Calling Engine: Interfaces with APIs, databases, webhooks, or code execution environments.
-
Feedback Loop: Incorporates user feedback and internal evaluation to improve future performance.
How It All Comes Together
-
User submits a query say, “Compare recent trends in GenAI investments across Asia and Europe.”
-
The rag agent plans its approach: decompose the request, decide on sources (news APIs, financial reports), and select retrieval strategy.
-
It retrieves data from multiple sources—maybe some from a vector DB, others from structured APIs.
-
It iterates, verifying facts, checking for inconsistencies, and possibly calling a summarization tool.
-
It returns a comprehensive, validated answer—possibly with charts, structured data, or follow-up recommendations.
Benefits of Agentic RAG
Why go through the added complexity of building rag agents? Because they unlock next-level capabilities:
-
Flexibility: Handle multi-step, non-linear workflows that mimic human problem-solving.
-
Accuracy: Validate intermediate outputs, reducing hallucinations and misinterpretations.
-
Scalability: Multiple agents can collaborate in parallel—ideal for enterprise-scale workflows.
-
Multimodality: Support for image, text, code, and tabular data.
-
Continuous Learning: Through memory and feedback loops, agents improve with time and use.
Challenges and Considerations
Of course, this power comes with trade-offs:
-
System Complexity: Orchestrating agents, tools, retrievers, and LLMs can introduce fragility.
-
Compute Costs: More retrieval steps and more tool calls mean higher resource use.
-
Latency: Multi-step processes can be slower than simple RAG flows.
-
Reliability: Agents may fail, loop indefinitely, or return conflicting results.
-
Data Dependency: Poor-quality data or sparse knowledge bases degrade agent performance.
Rag agents are incredibly capable, but they require careful engineering and observability.
Real-World Use Cases
1. Enterprise Knowledge Retrieval
Employees can use rag agents to pull data from CRMs, internal wikis, reports, and dashboards—then get a synthesized answer or auto-generated summary.
2. Customer Support Automation
Instead of simple chatbots, imagine agents that retrieve past support tickets, call refund APIs, and escalate intelligently based on sentiment.
3. Healthcare Intelligence
Rag agents can combine patient history, treatment guidelines, and the latest research to suggest evidence-based interventions.
4. Business Intelligence
From competitor benchmarking to KPI tracking, rag agents can dynamically build reports across multiple structured and unstructured data sources.
5. Adaptive Learning Tools
Tutoring agents can adjust difficulty levels, retrieve learning material, and provide instant feedback based on a student’s knowledge gaps.
Future Trends in Agentic RAG Technology
Here’s where the field is heading:
-
Multi-Agent Collaboration: Agents that pass tasks to each other—like departments in a company.
-
Open Source Growth: Community-backed frameworks like LangGraph and LlamaIndex are becoming more powerful and modular.
-
Verticalized Agents: Domain-specific rag agents for law, finance, medicine, and more.
-
Improved Observability: Tools for debugging reasoning chains and understanding agent behavior.
-
Responsible AI: Built-in mechanisms to ensure fairness, interpretability, and compliance.
Conclusion & Next Steps
Rag agents are more than an upgrade to RAG—they’re a new class of intelligent systems. By merging retrieval, reasoning, and tool execution into one autonomous workflow, they bridge the gap between passive Q&A and active problem-solving.
If you’re looking to build AI systems that don’t just answer but truly act—this is the direction to explore.
Next steps:
-
Dive into open-source agentic RAG tools like LangChain, LlamaIndex, and LangGraph.
-
Explore Data Science Dojo’s blogs and bootcamps like the LLM Bootcamp and Agentic AI Bootcamp
-
Stay updated on emerging practices in agent evaluation, orchestration, and observability.
Frequently Asked Questions (FAQ)
Q1: What is a agentic rag?
Agentic rag combines retrieval-augmented generation with multi-step planning, memory, and tool usage—allowing it to autonomously tackle complex tasks.
Q2: How does agentic RAG differ from standard RAG?
Standard RAG retrieves documents and augments the LLM prompt. Agentic RAG adds reasoning, planning, memory, and tool calling—making the system autonomous and iterative.
Q3: What are the benefits of rag agents?
Greater adaptability, higher accuracy, multi-step reasoning, and the ability to operate across modalities and APIs.
Q4: What challenges should I be aware of?
Increased complexity, higher compute costs, and the need for strong observability and quality data.
Q5: Where can I learn more?
Start with open-source tools like LangChain and LlamaIndex, and explore educational content from Data Science Dojo and beyond.