

Imagine you’re running a customer support center, and your AI chatbot not only answers queries but does so by pulling the most up-to-date information from a live database. This isn’t science fiction—it’s the magic of Retrieval Augmented Generation (RAG)!

It is an innovative approach that bridges the gap between static knowledge and evolving information, enhancing the capabilities of large language models (LLM) with real-time access to external knowledge sources. This significantly reduces the chances of AI hallucinations and increases the reliability of generated content.
By integrating a powerful retrieval mechanism, RAG empowers AI systems to deliver informed, trustworthy, and up-to-date outputs, making it a game-changer for applications ranging from customer support to complex problem-solving in specialized domains.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) is an advanced technique in the field of generative AI that enhances the capabilities of LLMs by integrating a retrieval mechanism to access external knowledge sources in real-time.
Instead of relying solely on static, pre-loaded training data, RAG dynamically fetches the most current and relevant information to generate precise, contextually accurate responses. Hence, integrating RAG’s retrieval-based and generation-based approaches provides a robust database for LLMs.
Using RAG as one of the NLP techniques helps to ensure that the responses are grounded in factual information, reducing the likelihood of generating incorrect or misleading answers (hallucinations). Additionally, it provides the ability to access the latest information without the need for frequent retraining of the model.
Hence, retrieval augmented generation has redefined the standard for information search and navigation with LLMs.
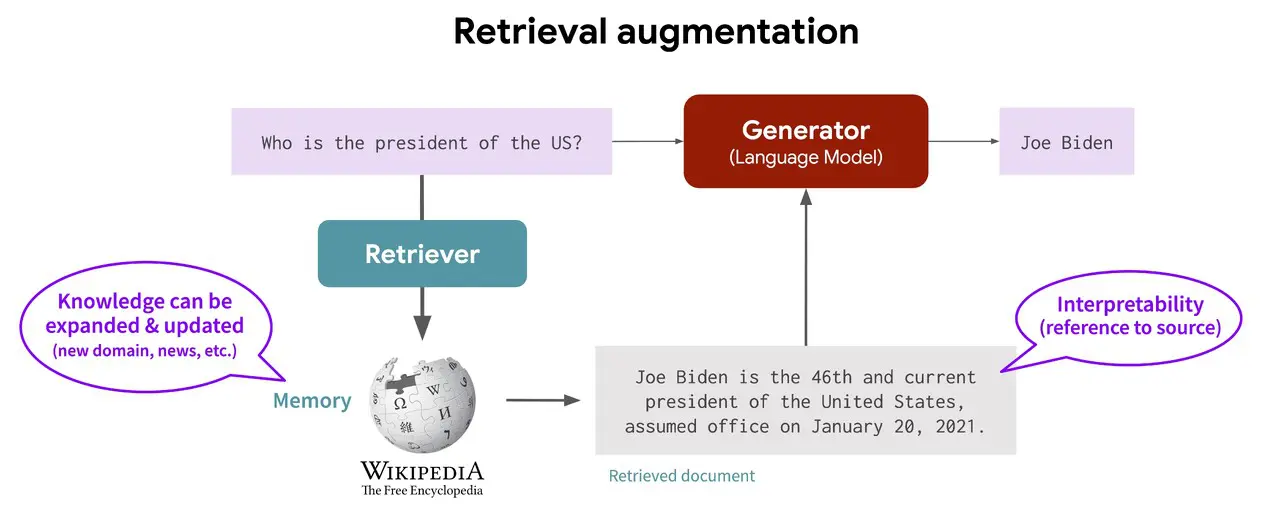
How Does RAG Work?
A RAG model operates in two main phases: the retrieval phase and the generation phase. These phases work together to enhance the accuracy and relevance of the generated responses.
1. Retrieval Phase
The retrieval phase fetches relevant information from an external knowledge base. This phase is crucial because it provides contextually relevant data to the LLM. Algorithms search for and retrieve snippets of information that are relevant to the user’s query.
These snippets come from various sources like databases, document repositories, and the internet. The retrieved information is then combined with the user’s prompt and passed on to the LLM for further processing.
This leads to the creation of high-performing LLM applications that have access to the latest and most reliable information, minimizing the chances of generating incorrect or misleading responses. Some key components of the retrieval phase include:
Learn all you need to know about embeddings and their role in LLMs
Use of Embedding Models
Embedding models play a vital role in the retrieval phase by converting user queries and documents into numerical representations, known as vectors. This conversion process is called embedding. The embeddings capture the semantic meaning of the text, allowing for efficient searching within a vector database.
By representing both the query and the documents as vectors, the system can perform mathematical operations to find the closest matches, ensuring that the most relevant information is retrieved.
Vector Database and Knowledge Library
The vector database is specialized to store these embeddings as it can handle high-dimensional data representations. The database can quickly search through these vectors to retrieve the most relevant information.
This fast and accurate retrieval is made possible because the vector database indexes the embeddings in a way that allows for efficient similarity searches. This setup ensures that the system can provide timely and accurate responses based on the most relevant data from the knowledge library.
Read more about the optimized use of vector databases in LLMs
Semantic Search Capabilities
Unlike traditional keyword searches, semantic search understands the intent behind the user’s query. It uses embeddings to find contextually appropriate information, even if the exact keywords are not present.
This capability ensures that the retrieved information is not just a literal match but is also semantically relevant to the query. By focusing on the meaning and context of the query, semantic search improves the accuracy and relevance of the information retrieved from the knowledge library.
2. Generation Phase
In the generation phase, the retrieved information is combined with the original user query and fed into the LLM. This process ensures that the LLM has access to both the context provided by the user’s query and the additional, relevant data fetched during the retrieval phase.
This integration allows the LLM to generate responses that are more accurate and contextually relevant, as it can draw from the most current and authoritative information available. These responses are generated through the following steps:
Augmented Prompt Construction
To construct an augmented prompt, the retrieved information is combined with the user’s original query. This involves appending the relevant data to the query in a structured format that the LLM can easily interpret.
This augmented prompt provides the LLM with all the necessary context, ensuring that it has a comprehensive understanding of the query and the related information.
Response Generation Using the Augmented Prompt
Once the augmented prompt is prepared, it is fed into the LLM. The language model leverages its pretrained capabilities along with the additional context provided by the retrieved information to better understand the query.
The combination enables the LLM to generate responses that are not only accurate but also contextually enriched, drawing from both its internal knowledge and the external data provided.
Explore how LLM RAG works to make language models enterprise-ready
Hence, the two phases are closely interlinked.
The retrieval phase provides the essential context and factual grounding needed for the generation phase to produce accurate and relevant responses. Without the retrieval phase, the LLM might rely solely on its training data, leading to outdated or less accurate answers.
Meanwhile, the generation phase uses the context provided by the retrieval phase to enhance its outputs, making the entire system more robust and reliable. Hence, the two phases work together to enhance the overall accuracy of LLM responses.
Technical Components in Retrieval Augmented Generation
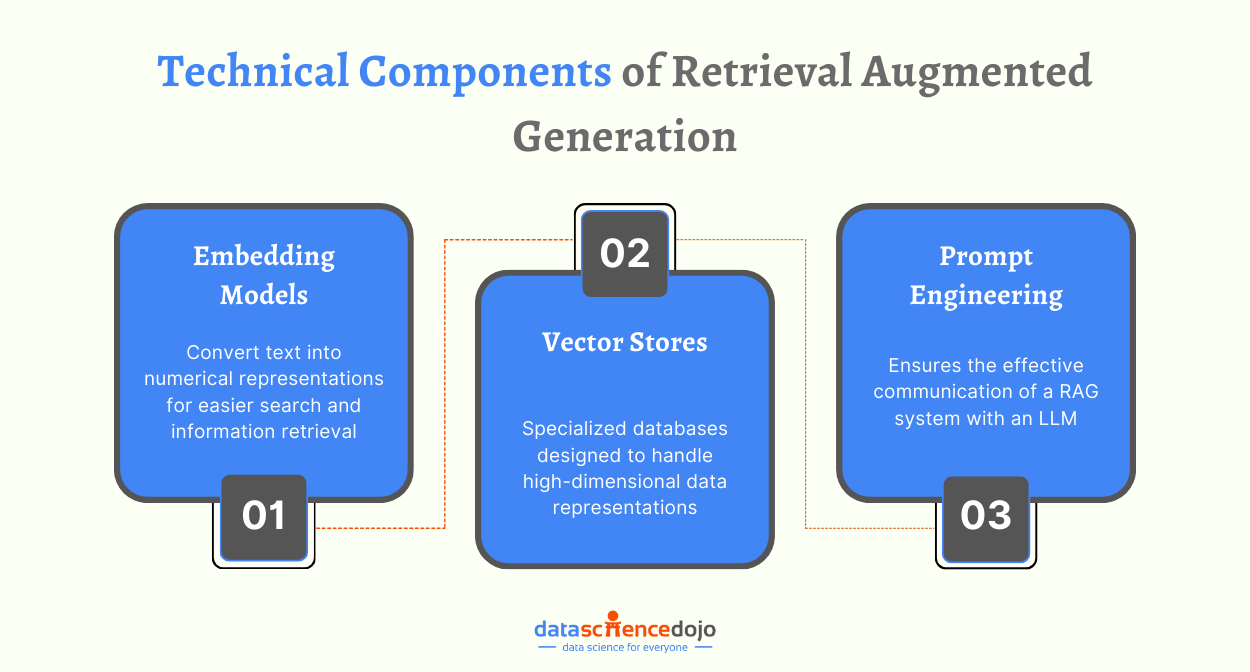
While we understand how RAG works, let’s take a closer look at the key technical components involved in the process.
Embedding Models
Embedding models are essential in ensuring a high RAG performance with efficient search and retrieval responses. Some popular embedding models in RAG are:
-
OpenAI’s text-embedding-ada-002: This model generates high-quality text embeddings suitable for various applications.
-
Jina AI’s jina-embeddings-v2: Offered by Jina AI, this model creates embeddings that capture the semantic meaning of text, aiding in efficient retrieval tasks.
-
SentenceTransformers’ multi-QA models: These models are part of the SentenceTransformers library and are optimized for producing embeddings effective in question-answering scenarios.
These embedding models help in converting text into numerical representations, making it easier to search and retrieve relevant information in RAG systems.
Vector Stores
Vector stores are specialized databases designed to handle high-dimensional data representations. Here are some common vector stores used in RAG implementations:

Facebook’s FAISS
FAISS is a library for efficient similarity search and clustering of dense vectors. It helps in storing and retrieving large-scale vector data quickly and accurately.
Chroma DB
Chroma DB is another vector store that specializes in handling high-dimensional data representations. It is optimized for quick retrieval of vectors.
Pinecone
Pinecone is a fully managed vector database that allows you to handle high-dimensional vector data efficiently. It supports fast and accurate retrieval based on vector similarity.
Weaviate
Weaviate is an open-source vector search engine that supports various data formats. It allows for efficient vector storage and retrieval, making it suitable for RAG implementations.
Learn more about the top vector databases in the market
Prompt Engineering
Prompt engineering is a crucial component in RAG as it ensures effective communication with an LLM. High-quality prompting skills train your language model to generate high-quality responses that are well-aligned with the user’s needs.
Here’s how prompt engineering can enhance your LLM performance:
Tailoring Functionality
A well-crafted prompt helps in tailoring the LLM’s functionalities to better align with the user’s intent. This ensures that the model understands the query precisely and generates a relevant response.
Contextual Relevance
In Retrieval-Augmented Generation (RAG) systems, the prompt includes the user’s query along with relevant contextual information retrieved from the semantic search layer. This enriched prompt helps the LLM to generate more accurate and contextually relevant responses.
Reducing Hallucinations
Effective prompt engineering can reduce the chances of the LLM generating inaccurate or hallucinated responses. By providing clear and specific instructions, the prompt guides the LLM to focus on the relevant information.
Improving Interaction
A good prompt structure can improve the interaction between the user and the LLM. For example, a prompt that clearly sets the context and intent will enable the LLM to understand and respond correctly, enhancing the overall user experience.
Here’s a 10-step guide for you to become an expert prompt engineer
Bringing these components together ensures an effective implementation of RAG to enhance the overall efficiency of a language model.
Comparing RAG and Fine-Tuning
While RAG LLM integrates real-time external data to improve responses, Fine-Tuning sharpens a model’s capabilities through specialized dataset training. Understanding the strengths and limitations of each method is essential for developers and researchers to fully leverage AI.
Some key points of comparison are listed below.
Adaptability to Dynamic Information
RAG is great at keeping up with the latest information. It pulls data from external sources, making it super responsive to changes—perfect for things like news updates or financial analysis. Since it uses external databases, you get accurate, up-to-date answers without needing to retrain the model constantly.
On the flip side, fine-tuning needs regular updates to stay relevant. Once you fine-tune a model, its knowledge is as current as the last training session. To keep it updated with new info, you have to retrain it with fresh datasets. This makes fine-tuning less flexible, especially in fast-changing fields.
Customization and Linguistic Style
Fine-tuning is great for personalizing models to specific domains or styles. It trains on curated datasets, making it perfect for creating outputs that match unique terminologies and tones.
This is ideal for applications like customer service bots that need to reflect a company’s specific communication style or educational content aligned with a particular curriculum.
Meanwhile, RAG focuses on providing accurate, up-to-date information from external sources. While it excels in factual accuracy, it doesn’t tailor linguistic style as closely to specific user preferences or domain-specific terminologies without extra customization.
Data Efficiency and Requirements
RAG is efficient with data because it pulls information from external datasets, so it doesn’t need a lot of labeled training data. Instead, it relies on the quality and range of its connected databases, making the initial setup easier. However, managing and querying these extensive data repositories can be complex.
Fine-tuning, on the other hand, requires a large amount of well-curated, domain-specific training data. This makes it less data-efficient, especially when high-quality labeled data is hard to come by.

Efficiency and Scalability
RAG is generally considered cost-effective and efficient for many applications. It can access and use up-to-date information from external sources without needing constant retraining, making it scalable across diverse topics. However, it requires sophisticated retrieval mechanisms and might introduce some latency due to real-time data fetching.
Fine-tuning needs a significant initial investment in time and resources to prepare the domain-specific dataset. Once tuned, the model performs efficiently within its specialized area. However, adapting it to new domains requires additional training rounds, which can be resource-intensive.
Domain-Specific Performance
RAG excels in versatility, handling queries across various domains by fetching relevant information from external databases. It’s robust in scenarios needing access to a wide range of continuously updated information.
Fine-tuning is perfect for achieving precise and deep domain-specific expertise. Training on targeted datasets, ensures highly accurate outputs that align with the domain’s nuances, making it ideal for specialized applications.
Hybrid Approach
A hybrid model that blends the benefits of RAG and fine-tuning is an exciting development. This method enriches LLM responses with current information while also tailoring outputs to specific tasks.
It can function as a versatile system or a collection of specialized models, each fine-tuned for particular uses. Although it adds complexity and demands more computational resources, the payoff is in better accuracy and deep domain relevance.
Read more for an in-depth discussion on RAG vs Fine-tuning
Hence, both RAG and fine-tuning have distinct advantages and limitations, making them suitable for different applications based on specific needs and desired outcomes. Plus, there is always a hybrid approach to explore and master as you work through the wonders of RAG and fine-tuning.
Benefits of RAG
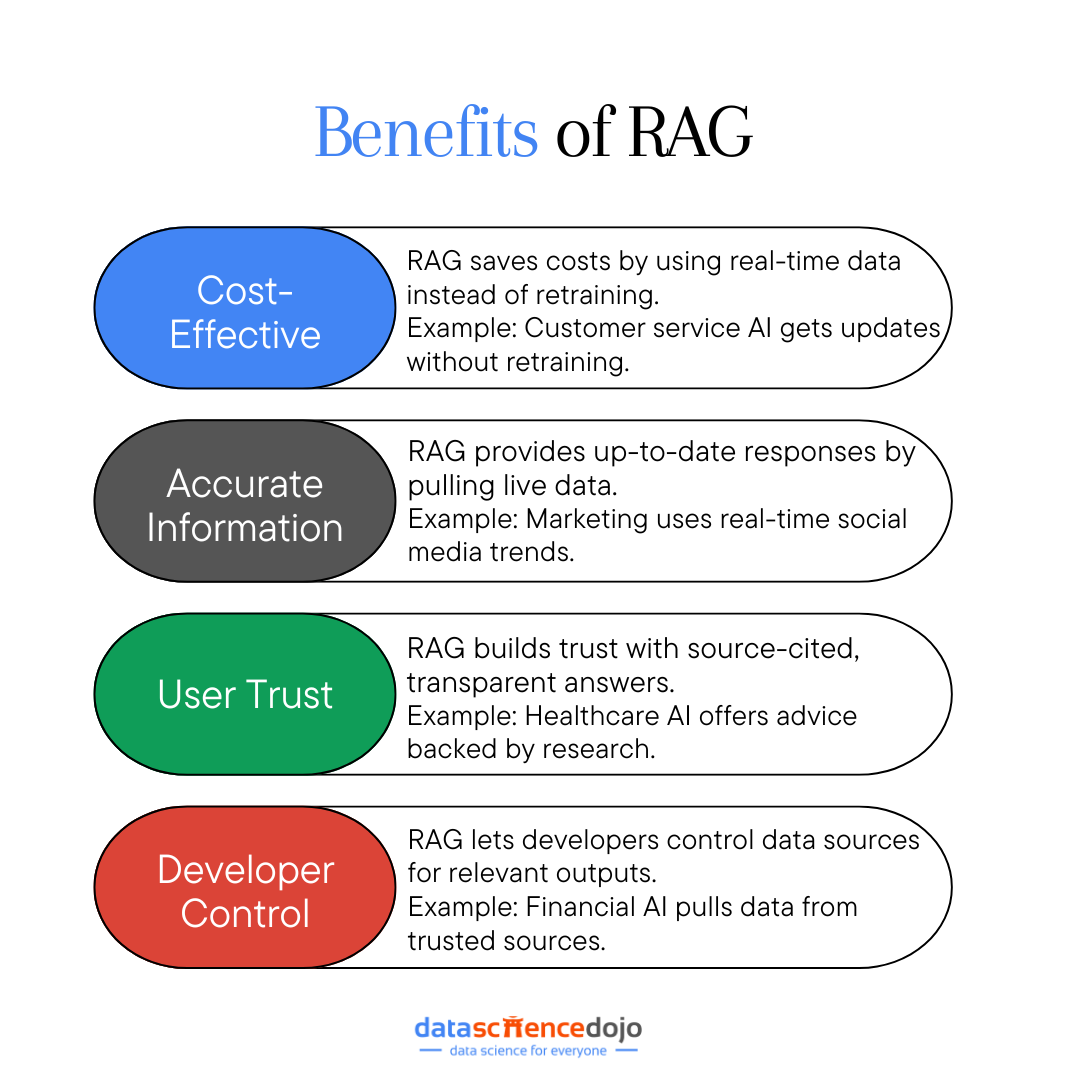
While retrieval augmented generation improves LLM responses, it offers multiple benefits to enhance an enterprise’s experience with generative AI integration. Let’s look at some key advantages of RAG in the process.
Explore RAG and its benefits, trade-offs, use cases, and enterprise adoption, in detail with our podcast!
Cost-Effective Implementation
RAG is a game-changer when it comes to cutting costs. Unlike traditional LLMs that need expensive and time-consuming retraining to stay updated, RAG pulls the latest information from external sources in real time.
By tapping into existing databases and retrieval systems, RAG provides a more affordable and accessible solution for keeping generative AI up-to-date and useful across various applications.
Example
Imagine a customer service department using an LLM to handle inquiries. Traditionally, they would need to retrain the model regularly to keep up with new product updates, which is costly and resource-intensive.
With RAG, the model can instantly pull the latest product information from the company’s database, providing accurate answers without the hefty retraining costs. This not only saves money but also ensures customers always get the most current information.

Providing Current and Accurate Information
RAG shines in delivering up-to-date information by connecting to external data sources. Unlike static LLMs, which rely on potentially outdated training data, RAG continuously pulls relevant info from live databases, APIs, and real-time data streams. This ensures that responses are both accurate and current.
Example
Imagine a marketing team that needs the latest social media trends for their campaigns. Without RAG, they would rely on periodic model updates, which might miss the latest buzz.
However, RAG gives instant access to live social media feeds and trending news, ensuring their strategies are always based on the most current data. It keeps the campaigns relevant and effective by integrating the latest research and statistics.
Enhancing User Trust
RAG boosts user trust by ensuring accurate responses and citing sources. This transparency lets users verify the information, building confidence in the AI’s outputs. It reduces the chances of presenting false information, a common problem with traditional LLMs. This traceability enhances the AI’s credibility and trustworthiness.
Example
Consider a healthcare organization using AI to offer medical advice. Traditionally, the AI might give outdated or inaccurate advice due to old training data. With RAG, the AI can pull the latest medical research and guidelines, citing these sources in its responses.
Read more about precision medicine with vector databases
This ensures patients receive accurate, up-to-date information and can trust the advice given, knowing it’s backed by reliable sources. This transparency and accuracy significantly enhance user trust in the AI system.
Offering More Control for Developers
RAG gives developers more control over the information base and the quality of outputs. They can tailor the data sources accessed by the LLM, ensuring that the information retrieved is relevant and appropriate.
This flexibility allows for better alignment with specific organizational needs and user requirements. Developers can also restrict access to sensitive data, ensuring it is handled properly. This control also extends to troubleshooting and optimizing the retrieval process, enabling refinements for better performance and accuracy.
Example
For instance, developers at a financial services company can use RAG to ensure the AI pulls data only from trusted financial news sources and internal market analysis reports.
Learn more about the upscaling of financial sector with LLM finance
They can also restrict access to confidential client data. This tailored approach ensures the AI provides relevant, accurate, and secure investment advice that meets both company standards and client needs.
Thus, RAG brings several benefits that make it a top choice for improving LLMs. As organizations look for more reliable and adaptable AI solutions, RAG efficiently meets these needs.
Frameworks for Retrieval Augmented Generation
A RAG system combines a retrieval model with a generation model. Developers use frameworks and libraries available online to implement the required retrieval system. Let’s take a look at some of the common resources used for it.
Hugging Face Transformers
It is a popular library of pre-trained models for different tasks. It includes retrieval models like Dense Passage Retrieval (DPR) and generation models like GPT. The transformer allows the integration of these systems to generate a unified retrieval augmented generation model.
Facebook AI Similarity Search (FAISS)
FAISS is used for similarity search and clustering dense vectors. It plays a crucial role in building retrieval components of a system. Its use is preferred in models where vector similarity is crucial for the system.
PyTorch and TensorFlow
These are commonly used deep learning frameworks that offer immense flexibility in building RAG models. They enable the developers to create retrieval and generation models separately. Both models can then be integrated into a larger framework to develop a RAG model.
Haystack
It is a Python framework that is built on Elasticsearch. It is suitable to build end-to-end conversational AI systems. The components of the framework are used for storage of information, retrieval models, and generation models.

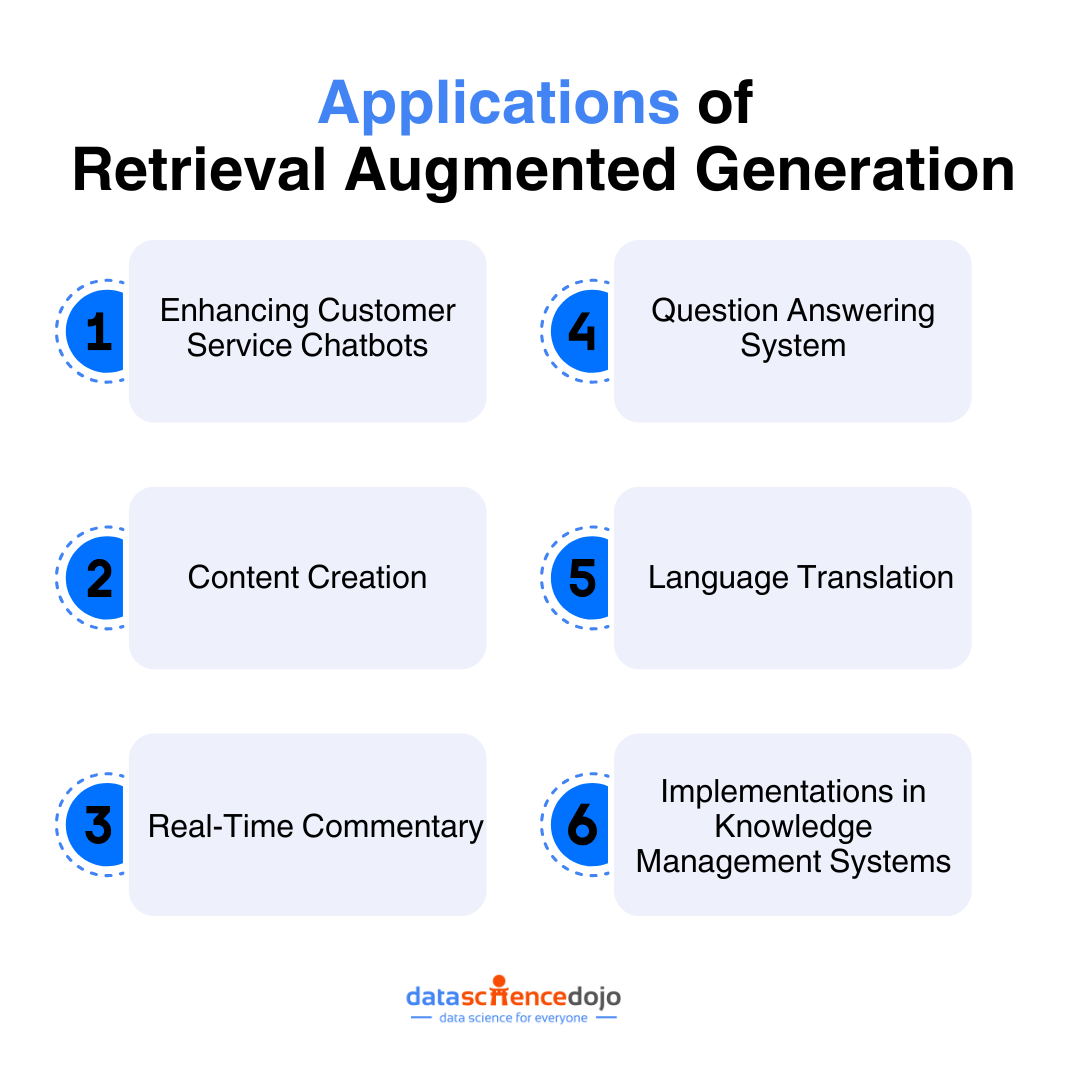
Applications of Retrieval-Augmented Generation
Building LLM applications has never been more exciting, thanks to the revolutionary approach known as Retrieval Augmented Generation (RAG). By merging the strengths of information retrieval and text generation, RAG is significantly enhancing the capabilities of LLMs.
This innovative technique is transforming various domains, making LLM applications more accurate, reliable, and contextually aware. Let’s explore how RAG is making a profound impact across multiple fields.
Enhancing Customer Service Chatbots
Customer service chatbots are one of the most prominent beneficiaries of RAG. By leveraging RAG, these chatbots can provide more accurate and reliable responses, greatly enhancing user experience.
RAG lets chatbots pull up-to-date information from various sources. For example, a retail chatbot can access the latest inventory and promotions, giving customers precise answers about product availability and discounts.
By using verified external data, RAG ensures chatbots provide accurate information, building user trust. Imagine a financial services chatbot offering real-time market data to give clients reliable investment advice.
Learn about the top 5 customer service AI tools to boost your revenue
Content Creation
It primarily deals with writing articles and blogs. It is one of the most common uses of LLM where the retrieval models are used to generate coherent and relevant content. It can lead to personalized results for users that include real-time trends and relevant contextual information.
Real-Time Commentary
A retriever uses APIs to connect real-time information updates with an LLM. It is used to create a virtual commentator which can be integrated further to create text-to-speech models. IBM used this mechanism during the US Open 2023 for live commentary.
Question Answering System
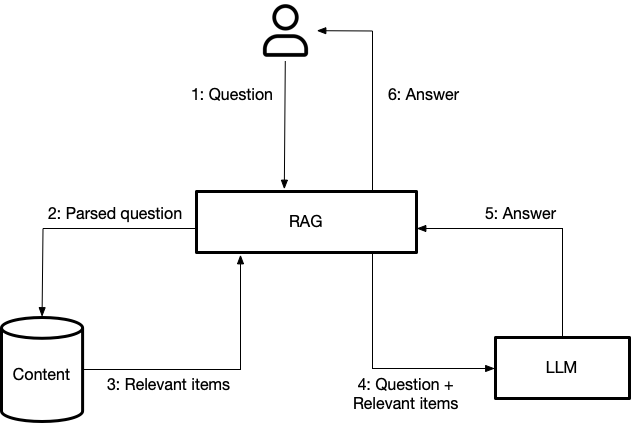
The ability of LLMs to generate contextually relevant content enables the retrieval model to function as a question-answering machine. It can retrieve factual information from an extensive knowledge base to create a comprehensive answer.
Language Translation
Translation is a tricky process. A retrieval model can detect the context of phrases and words, enabling the generation of relevant translations. Access to external databases ensures the results are accurate and fluent for the users. The extensive information on available idioms and phrases in multiple languages ensures this use case of the retrieval model.
Implementations in Knowledge Management Systems
Knowledge management systems greatly benefit from the implementation of RAG, as it aids in the efficient organization and retrieval of information.
RAG can be integrated into knowledge management systems to improve the search and retrieval of information. For example, a corporate knowledge base can use RAG to provide employees with quick access to the latest company policies, project documents, and best practices.
Also explore the power of combining knowledge graphs and LLMs
The educational arena can also use these RAG-based knowledge management systems to extend their question-answering functionality. This RAG application uses the system for educational queries of users, generating academic content that is more comprehensive and contextually relevant.
As organizations look for reliable and flexible AI solutions, RAG’s uses will keep growing, boosting innovation and efficiency.
Challenges and Solutions in RAG
Let’s explore common issues faced during the implementation of the RAG framework and provide practical solutions and troubleshooting tips to overcome these hurdles.
Common Issues Faced During Implementation
One significant issue is the knowledge gap within organizations since RAG is a relatively new technology, leading to slow adoption rates and potential misalignment with business goals.
Moreover, the high initial investment and ongoing operational costs associated with setting up specialized infrastructure for information retrieval and vector databases make RAG less accessible for smaller enterprises.
Another challenge is the complexity of data modeling for both structured and unstructured data within the knowledge library and vector database. Incorrect data modeling can result in inefficient retrieval and poor performance, reducing the effectiveness of the RAG system.
Furthermore, handling inaccuracies in retrieved information is crucial, as errors can erode trust and user satisfaction. Scalability and performance also pose challenges; as data volume grows, ensuring the system scales without compromising performance can be difficult, leading to potential bottlenecks and slower response times.
Explore the major challenges in building RAG-based LLM applications
Solutions and Troubleshooting Tips
You can start by improving the knowledge of RAG at an organizational level through collaboration with experts. A team can be dedicated to pilot RAG projects, allowing them to develop expertise and share knowledge across the organization.
Moreover, RAG proves more cost-effective than frequently retraining LLMs. Focus on the long-term benefits and ROI of a more accurate and reliable system, and consider using cloud-based solutions like Oracle’s OCI Generative AI service for predictable performance and pricing.
You can also develop clear data modeling strategies that integrate both structured and unstructured data, utilizing vector databases like FAISS or Chroma DB for high-dimensional data representations. Regularly review and update data models to align with evolving RAG system needs, and use embedding models for efficient retrieval.
Another aspect is establishing feedback loops to monitor user responses and flag inaccuracies for review and correction.
Learn how to master LangChain for RAG applications
While implementing RAG can present several challenges, understanding these issues and proactively addressing them can lead to a successful deployment. Organizations must harness the full potential of RAG to deliver accurate, contextually relevant, and up-to-date information.
Future of RAG
RAG is rapidly evolving, and its future looks exciting. Some key aspects include:
- RAG incorporates various data types like text, images, audio, and video, making AI responses richer and more human-like.
- Enhanced retrieval techniques such as Hybrid Search combine keyword and semantic searches to fetch the most relevant information.
- Parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA) are making it cheaper and easier for organizations to customize AI models.
Looking ahead, RAG is expected to excel in real-time data integration, making AI responses more current and useful, especially in dynamic fields like finance and healthcare. We’ll see its expansion into new areas such as law, education, and entertainment, providing specialized content tailored to different needs.
Moreover, as RAG technology becomes more powerful, ethical AI development will gain focus, ensuring responsible use and robust data privacy measures. The integration of RAG with other AI methods like reinforcement learning will further enhance AI’s adaptability and intelligence, paving the way for smarter, more accurate systems.
Hence, retrieval augmented generation is an important aspect of large language models within the arena of generative AI. It has improved the overall content processing and promises an improved architecture of LLMs in the future.