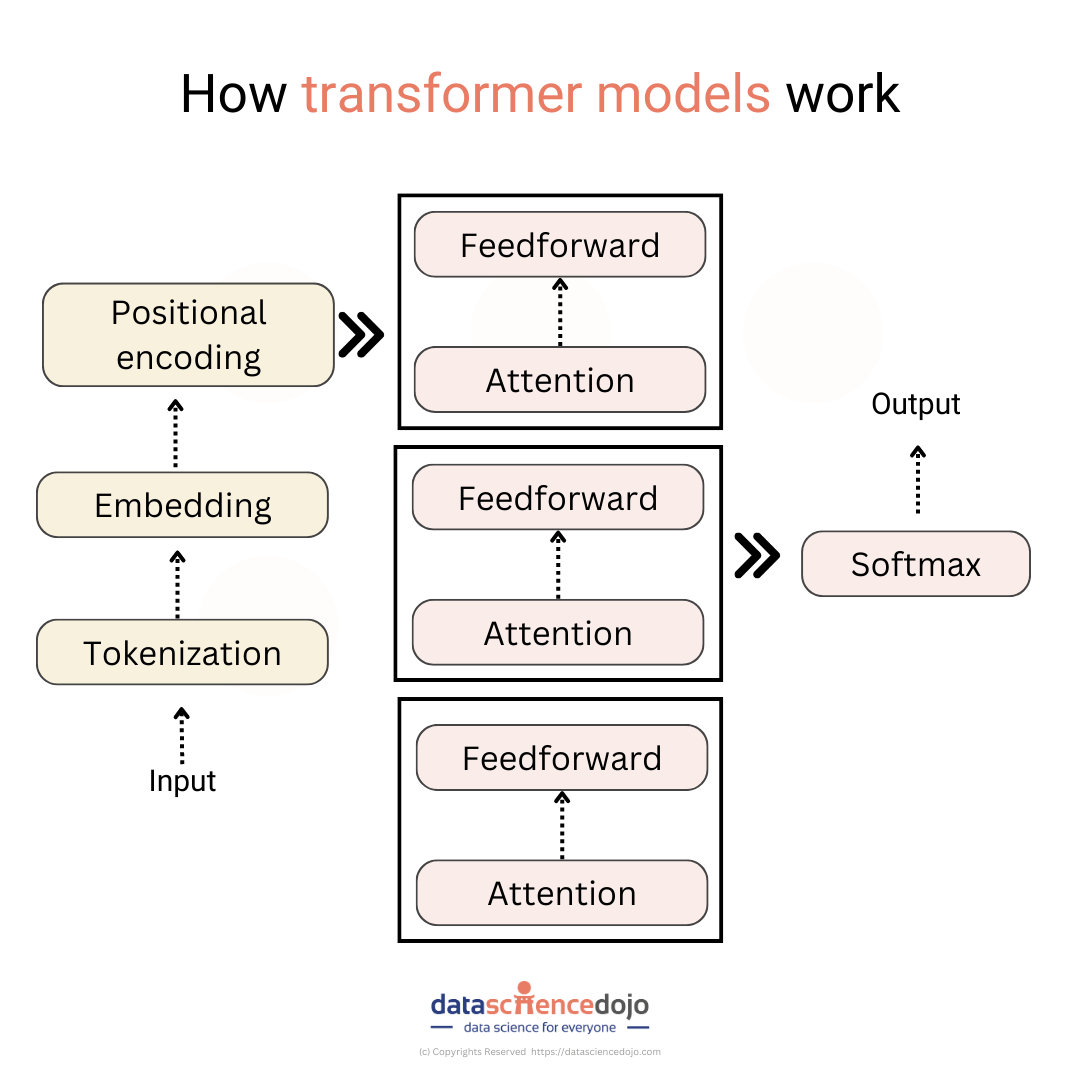
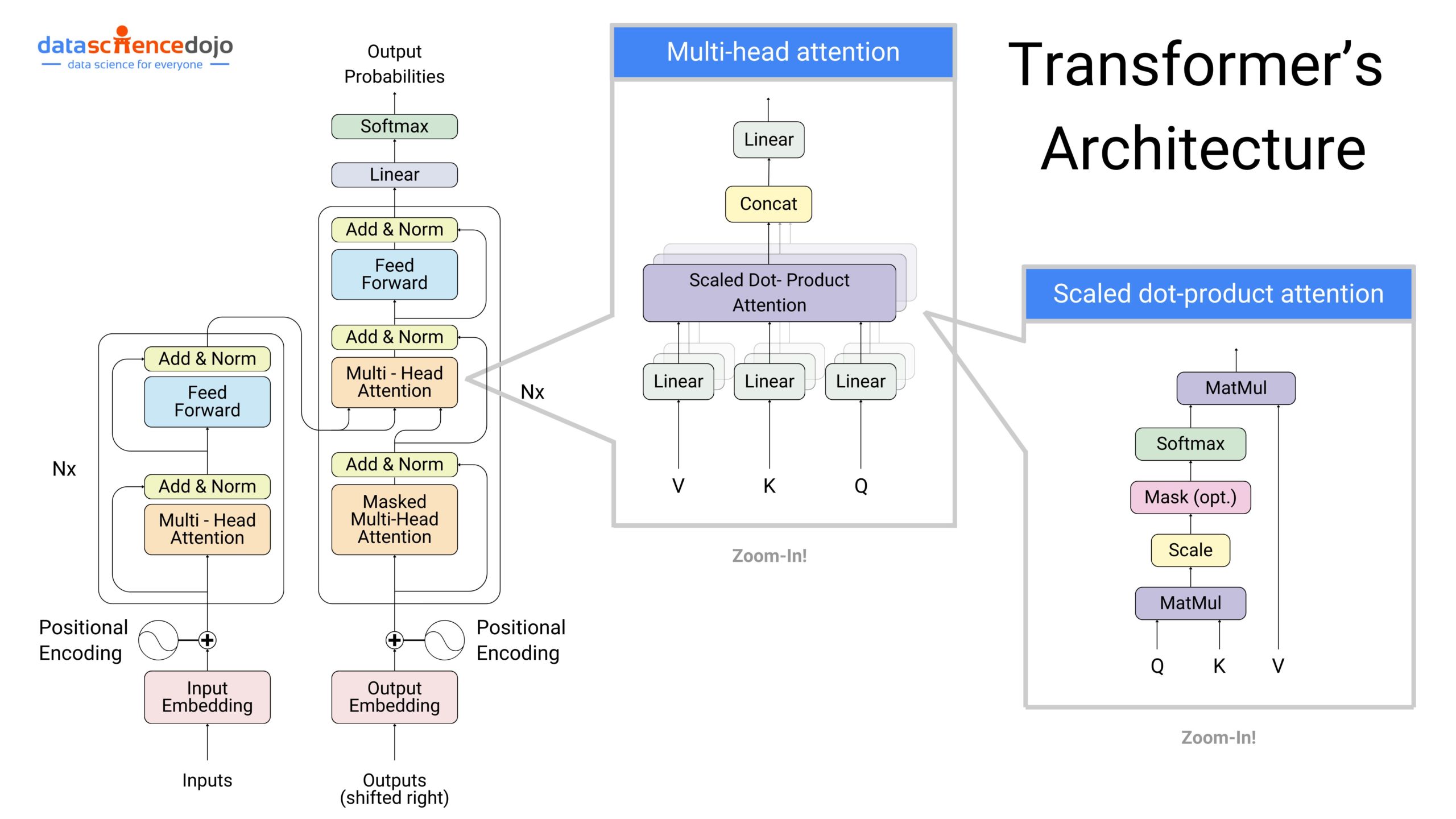
Natural language processing (NLP) and large language models (LLMs) have been revolutionized with the introduction of transformer models. These refer to a type of neural network architecture that excels at tasks involving sequences.
While we have talked about the details of a typical transformer architecture, in this blog we will explore the different types of the models.
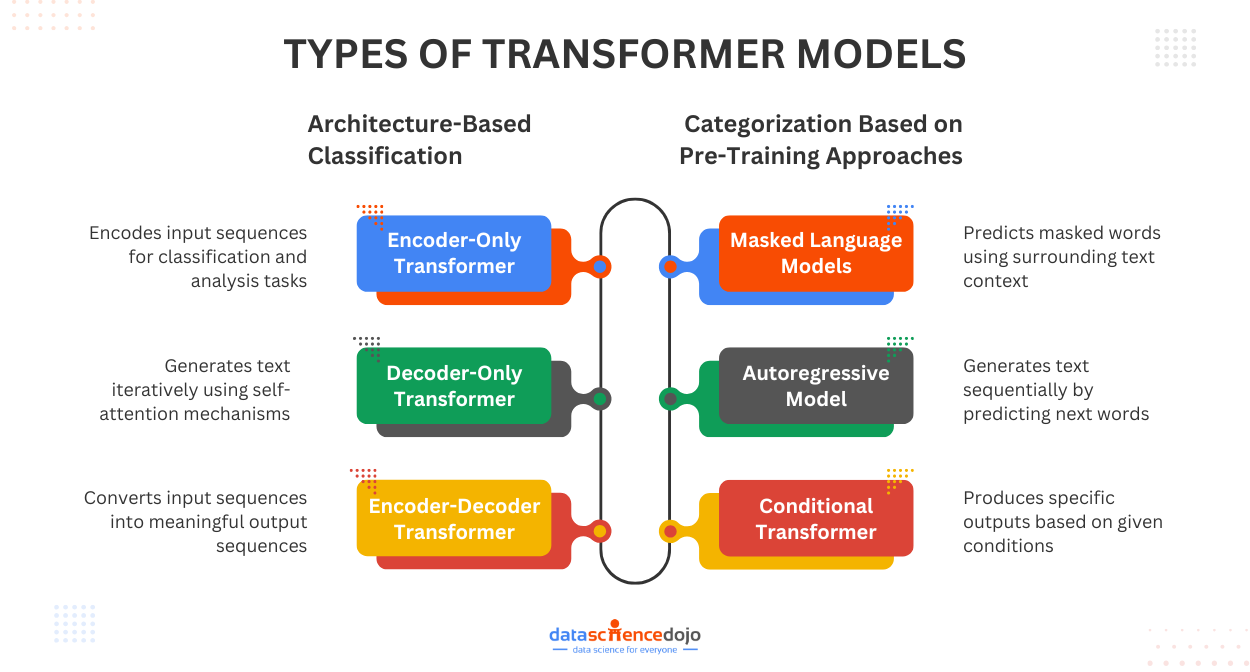
How to Categorize Transformer Models?
Transformers ensure the efficiency of LLMs in processing information. Their role is critical to ensure improved accuracy, faster training on data, and wider applicability. Hence, it is important to understand the different model types available to choose the right one for your needs.

However, before we delve into the many types of transformer models, it is important to understand the basis of their classification.
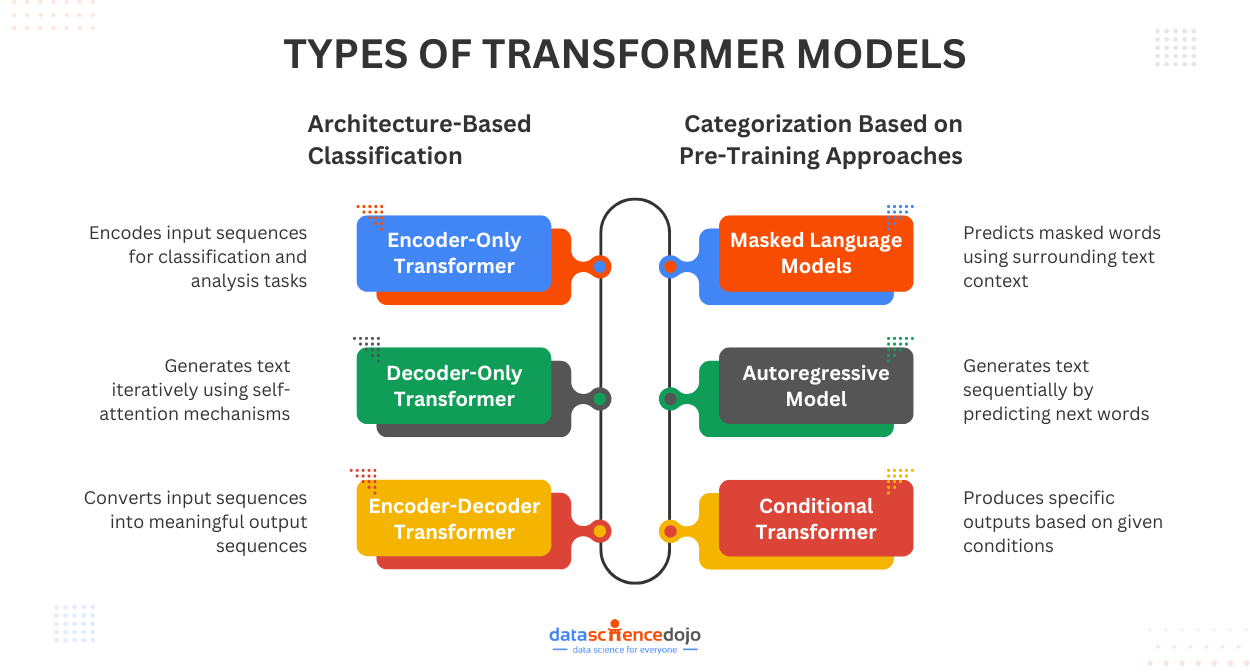
Classification by Transformer Architecture
The most fundamental categorization of transformer models is done based on their architecture. The variations are designed to perform specific tasks or cater to the limitations of the base architecture. The very common model types under this category include:
- encoder-only
- decoder-only
- encoder-decoder transformers
Categorization Based on Pre-Training Approaches
While architecture is a basic component of consideration, the training techniques are equally crucial components for transformers. Pre-training approaches refer to the techniques used to train a transformer on a general dataset before finetuning it to perform specific tasks.
Some common approaches that define classification under this category include:
- Masked Language Models (MLMs)
- autoregressive models
- conditional transformers
This presents a general outlook on classifying transformer models. While we now know the types present under the broader categories, let’s dig deeper into each transformer model type.
Read in detail about transformer architectures
Architecture-Based Classification
1. Encoder-Only Transformer
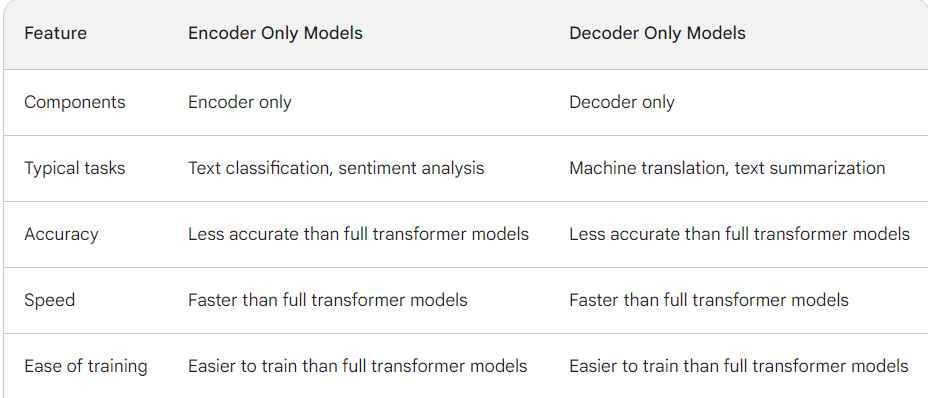
As the name suggests, this architectural type uses only the encoder part of the transformer, focusing on encoding the input sequence. For this model type, understanding the input sequence is crucial while generating an output sequence is not required.
Some common applications of an encoder-only transformer include:
Text Classification: It is focused on classifying the input data based on defined parameters. It is often used in email spam filters to categorize incoming emails. The transformer model can also train over the patterns for effective filtration of unwanted messages.
Sentimental Analysis: This feature makes it an appropriate choice for social media companies to analyze customer feedback and their emotion toward a service or product. It provides useful data insights, leading to the creation of effective strategies to enhance customer satisfaction.
Read about sentiment analysis in LLMs
Anomaly Detection: It is particularly useful for finance companies. The analysis of financial transactions allows the timely detection of anomalies. Hence, possible fraudulent activities can be addressed promptly.
Other uses of an encoder-only transformer include question-answering, speech recognition, and image captioning.
2. Decoder-Only Transformer
It is a less common type of transformer model that uses only the decoder component to generate text sequences based on input prompts. The self-attention mechanism allows the model to focus on previously generated outputs in the sequence, enabling it to refine the output and create more contextually aware results.
Some common uses of decoder-only transformers include:
Text Summarization: It can iteratively generate textual summaries of the input, focusing on including the important aspects of information.
Text Generation: It builds on a provided prompt to generate relevant textual outputs. The results cover a diverse range of content types, like poems, codes, and snippets. It is capable of iterating the process to create connected and improved responses.
Chatbots: It is useful to handle conversational interactions via chatbots. The decoder can also consider previous conversations to formulate relevant responses.
Explore the role of attention mechanism in transformers
3. Encoder-Decoder Transformer
This is a classic architectural type of transformer, efficiently handling sequence-to-sequence tasks, where you need to transform one type of sequence (like text) into another (like a translation or summary). An encoder processes the input sequence while a decoder is used to generate an output sequence.
Some common uses of an encoder-decoder transformer include:
Machine Translation: Since the sequence is important at both the input and output, it makes this transformer model a useful tool for translation. It also considers contextual references and relationships between words in both languages.
Text Summarization: While this use overlaps with that of a decoder-only transformer, text summarization differs from an encoder-decoder transformer due to its focus on the input sequence. It enables the creation of summaries that focus on relevant aspects of the text highlighted in an input prompt.
Question-Answering: It is important to understand the question before providing a relevant answer. An encoder-decoder transformer allows this focus on both ends of the communication, ensuring each question is understood and answered appropriately.
Learn how LlamaIndex can be used to build Q&A chatbots
This concludes our exploration of architecture-based transformer models. Let’s explore the classification from the lens of pre-training approaches.
Categorization Based on Pre-Training Approaches
While the architectural differences provide a basis for transformer types, the models can be further classified based on their techniques of pre-training.
Let’s explore the various transformer models segregated based on pre-training approaches.
1. Masked Language Models (MLMs)
Models with this pre-training approach are usually encoder-only in architecture. They are trained to predict a masked word in a sentence based on the contextual information of the surrounding words. The training enables these model types to become efficient in understanding language relationships.
Some common MLM applications are:
Boosting Downstream NLP Tasks: MLMs train on massive datasets, enabling the models to develop a strong understanding of language context and relationships between words. This knowledge enables MLM models to contribute and excel in diverse NLP applications.
General-Purpose NLP Tool: The enhanced learning, knowledge, and adaptability of MLMs make them a part of multiple NLP applications. Developers leverage this versatility of pre-trained MLMs to build a basis for different NLP tools.
Efficient NLP Development: The pre-trained foundation of MLMs reduces the time and resources needed for the deployment of NLP applications. It promotes innovation, faster development, and efficiency.

2. Autoregressive Models
Typically built using a decoder-only architecture, this pre-training model is used to generate sequences iteratively. It can predict the next word based on the previous one in the text you have written. Some common uses of autoregressive models include:
Text Generation: The iterative prediction from the model enables it to generate different text formats. From codes and poems to musical pieces, it can create all while iteratively refining the output as well.
Chatbots: The model can also be utilized in a conversational environment, creating engaging and contextually relevant responses,
Machine Translation: While encoder-decoder models are commonly used for translation tasks, some languages with complex grammatical structures are supported by autoregressive models.
Here’s a list of translation tools for you to explore
3. Conditional Transformer
This transformer model incorporates the additional information of a condition along with the main input sequence. It enables the model to generate highly specific outputs based on particular conditions, ensuring more personalized results.
Some uses of conditional transformers include:
Machine Translation with Adaptation: The conditional aspect enables the model to set the target language as a condition. It ensures better adjustment of the model to the target language’s style and characteristics.
Summarization with Constraints: Additional information allows the model to generate summaries of textual inputs based on particular conditions.
Speech Recognition with Constraints: With the consideration of additional factors like speaker ID or background noise, the recognition process enhances to produce improved results.
Future of Transformer Model Types
While numerous transformer model variations are available, the ongoing research promises their further exploration and growth. Some major points of further development will focus on efficiency, specialization for various tasks, and integration of transformers with other AI techniques.
Transformers can also play a crucial role in the field of human-computer interaction with their enhanced capabilities. The growth of transformers will definitely impact the future of AI. However, it is important to understand the uses of each variation of a transformer model before you choose the one that fits your requirements.