In the second article of this chatbot series, learn how to build a rule-based chatbot and discuss their business applications.
Chatbots have surged in popularity, becoming pivotal in text-based customer interactions, especially in support services. It’s expected that nearly 25% of customer service operations will use them by 2020.
In the first part of A Beginners Guide to Chatbots, we discussed what chatbots were, their rise to popularity, and their use cases in the industry. We also saw how the technology has evolved over the past 50 years.
In this second part of the series, we’ll take you through the process of building a simple Rule-based chatbot in Python. Before we start with the tutorial, we need to understand the different types of chatbots and how they work.
Types of chatbots
Chatbots can be classified into two different types based on how they are built:
Rule-based Chatbots
Rule-based chatbots are pretty straightforward. They use a predefined response database and follow set rules to determine appropriate replies. Although they can’t generate answers independently, their effectiveness hinges on the depth of the response database and the efficiency of their rules.
The simplest form of Rule-based Chatbots has one-to-one tables of inputs and their responses. These bots are extremely limited and can only respond to queries if they are an exact match with the inputs defined in their database.
AI-based chatbots
With the rise in the use of machine learning in recent years, a new approach to building chatbots has emerged. With the use of artificial intelligence, creating extremely intuitive and precise chatbots tailored to specific purposes has become possible.
Unlike their rule-based kin, AI-based chatbots are based on complex machine-learning models that enable them to self-learn.
Libraries for building a rule-based chatbot
Now that we’re familiar with how chatbots work, we’ll be looking at the libraries that will be used to build our simple Rule-based Chatbot.
Natural Language Toolkit (NLTK)
Natural Language Toolkit is a Python library that makes it easy to process human language data. It provides easy-to-use interfaces to many language-based resources such as the Open Multilingual Wordnet, and access to a variety of text-processing libraries.
Regular Expression (RegEx) in Python
A regular expression is a special sequence of characters that helps you search for and find patterns of words/sentences/sequences of letters in sets of strings, using a specialized syntax. They are widely used for text searching and matching in UNIX.
Python includes support for regular expression through the re package.
Want to upgrade your Python abilities? Check out Data Science Dojo’s Introduction to Python for Data Science.
Building a rule-based chatbot
This very simple rule-based chatbot will work by searching for specific keywords in user input. The keywords will help determine the desired action of the user (user’s intent). Once the intent is identified, the bot will pick out an appropriate response.
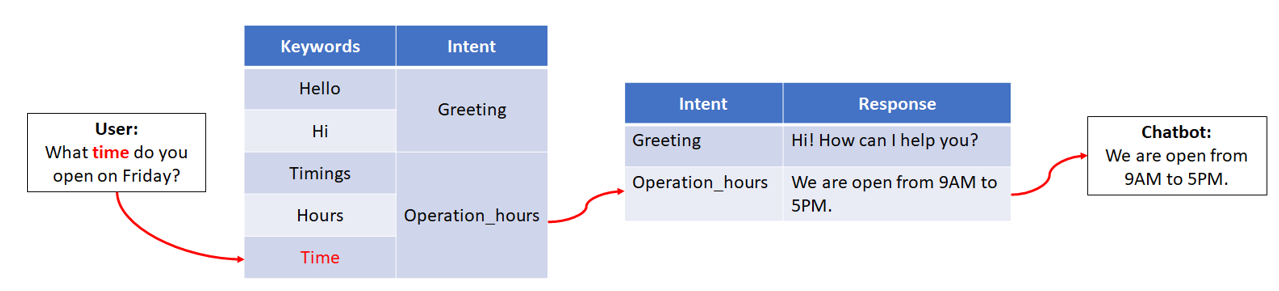
The list of keywords and a dictionary of responses will be built up manually based on the specific use case for the chatbot.
We’ll be designing a very simple chatbot for a bank that can respond to greetings (Hi, Hello, etc.) and answer questions about the bank’s hours of operation.
A flow of how the chatbot would process inputs is shown below:

We will be following the steps below to build our chatbot
- Importing Dependencies
- Building the Keyword List
- Building a dictionary of Intents
- Defining a dictionary of responses
- Matching Intents and Generating Responses
Importing dependencies
First, we will import needed the packages/libraries. The re package handles regular expressions in Python. We’ll also use WordNet from NLTK, a lexical database that defines semantic relationships between words, to build a dictionary of synonyms for our keywords. This will expand our list of keywords without manually introducing every possible word a user could use.
# Importing modules
import re
from nltk.corpus import wordnet
Building a list of keywords
Once we have imported our libraries, we’ll need to build up a list of keywords that our chatbot will look for. This list can be as exhaustive as you want. The more keywords you have, the better your chatbot will perform.
As discussed previously, we’ll be using WordNet to build up a dictionary of synonyms to our keywords. For details about how WordNet is structured, visit their website.
Code:
# Building a list of Keywords
list_words=['hello','timings']
list_syn={}
for word in list_words:
synonyms=[]
for syn in wordnet.synsets(word):
for lem in syn.lemmas():
# Remove any special characters from synonym strings
lem_name = re.sub('[^a-zA-Z0-9 \n\.]', ' ', lem.name())
synonyms.append(lem_name)
list_syn[word]=set(synonyms)
print (list_syn)
Output:
hello
{'hello', 'howdy', 'hi', 'hullo', 'how do you do'}
timings
{'time', 'clock', 'timing'}
Here, we first defined a list of words list_words that we will be using as our keywords. We used WordNet to expand our initial list with synonyms of the keywords. This list of keywords is stored in list_syn.
New keywords can simply be added to list_words. The chatbot will automatically pull their synonyms and add them to the keywords dictionary. You can also edit list_syn directly if you want to add specific words or phrases that you know your users will use.
Building a dictionary of intents
Once our keywords list is complete, we need to build up a dictionary that matches our keywords to intents. We also need to reformat the keywords in a special syntax that makes them visible to Regular Expression’s search function.
Code:
# Building dictionary of Intents & Keywords
keywords={}
keywords_dict={}
# Defining a new key in the keywords dictionary
keywords['greet']=[]
# Populating the values in the keywords dictionary with synonyms of keywords formatted with RegEx metacharacters
for synonym in list(list_syn['hello']):
keywords['greet'].append('.*\\b'+synonym+'\\b.*')
# Defining a new key in the keywords dictionary
keywords['timings']=[]
# Populating the values in the keywords dictionary with synonyms of keywords formatted with RegEx metacharacters
for synonym in list(list_syn['timings']):
keywords['timings'].append('.*\\b'+synonym+'\\b.*')
for intent, keys in keywords.items():
# Joining the values in the keywords dictionary with the OR (|) operator updating them in keywords_dict dictionary
keywords_dict[intent]=re.compile('|'.join(keys))
print (keywords_dict)
Output:
{'greet': re.compile('.*\\bhello\\b.*|.*\\bhowdy\\b.*|.*\\bhi\\b.*|.*\\bhullo\\b.*|.*\\bhow-do-you-do\\b.*'), 'timings': re.compile('.*\\btime\\b.*|.*\\bclock\\b.*|.*\\btiming\\b.*')}
The updated and formatted dictionary is stored in keywords_dict. The intent is the key and the string of keywords is the value of the dictionary.
Let’s look at one key-value pair of the keywords_dict dictionary to understand the syntax of Regular Expression;
{'greet': re.compile('.*\\bhullo\\b.*|.*\\bhow-do-you-do\\b.*|.*\\bhowdy\\b.*|.*\\bhello\\b.*|.*\\bhi\\b.*')
Regular Expression uses specific patterns of special Meta-Characters to search for strings or sets of strings in an expression.
Since we need our chatbot to search for specific words in larger input strings we use the following sequences of meta-characters:
.*\\bhullo\\b.*
In this specific sequence, the keyword (hullo) is encased between a \b sequence. This tells the RegEx Search function that the search parameter is the keyword (hullo).
The first sequence \bhullo\b is encased between a period star .* sequence. This sequence tells the RegEx Search function to search the entire input string from beginning to end for the search parameter (hullo).
In the dictionary, multiple such sequences are separated by the OR | operator. This operator tells the search function to look for any of the mentioned keywords in the input string.
More details about Regular Expression and its syntax can be found here. You can add as many key-value pairs to the dictionary as you want to increase the functionality of the chatbot.
Defining responses
The next step is defining responses for each intent type. This part is very straightforward. The responses are described in another dictionary with the intent being the key.
We’ve also added a fallback intent and its response. This is a fail-safe response in case the chatbot is unable to extract any relevant keywords from the user input.
Code:
# Building a dictionary of responses
responses={
'greet':'Hello! How can I help you?',
'timings':'We are open from 9AM to 5PM, Monday to Friday. We are closed on weekends and public holidays.',
'fallback':'I dont quite understand. Could you repeat that?',
}
Matching intents and generating responses
Now that we have the back end of the chatbot completed, we’ll move on to taking input from the user and searching the input string for our keywords.
We use the RegEx Search function to search the user input for keywords stored in the value field of the keywords_dict dictionary. If you recall, the values in the keywords_dict dictionary were formatted with special sequences of meta-characters.
RegEx’s search function uses the sequences to compare the character patterns in the keywords with the input string. If a match is found, the current intent is selected and used as a key to the responses dictionary to select the correct response.
Code:
print ("Welcome to MyBank. How may I help you?")
# While loop to run the chatbot indefinetely
while (True):
# Takes the user input and converts all characters to lowercase
user_input = input().lower()
# Defining the Chatbot's exit condition
if user_input == 'quit':
print ("Thank you for visiting.")
break
matched_intent = None
for intent,pattern in keywords_dict.items():
# Using the regular expression search function to look for keywords in user input
if re.search(pattern, user_input):
# if a keyword matches, select the corresponding intent from the keywords_dict dictionary
matched_intent=intent
# The fallback intent is selected by default
key='fallback'
if matched_intent in responses:
# If a keyword matches, the fallback intent is replaced by the matched intent as the key for the responses dictionary
key = matched_intent
# The chatbot prints the response that matches the selected intent
print (responses[key])
The chatbot picked the greeting from the first user input (‘Hi’) and responded according to the matched intent.
The same happened when it located the word (‘time’) in the second user input.
The third user input (‘How can I open a bank account’) didn’t have any keywords that were present in Bankbot’s database so it went to its fallback intent.
You can add multiple keywords/phrases/sentences and intents to build a robust chatbot for human interaction.
Building chatbot in Python – the next step
This blog was a hands-on introduction to building a basic chatbot in Python. We only worked with 2 intents in this tutorial for simplicity. You can easily expand the functionality of this chatbot by adding more keywords, intents, and responses.
Building a rule-based chatbot is a laborious process, especially in a business environment where it requires increased complexity. It makes rule-based chatbots impractical for enterprises due its limited conversational capabilities. AI-based Chatbots are a more practical solution for real-world scenarios.
In the next blog in the series, we’ll learn how to build a simple AI-based Chatbot in Python.
Do you want to learn more about machine learning and its applications? Check out Data Science Dojo’s online data science certificate program!
To learn more Python and Data Science, check out Data Science Dojo’s introduction to Python for Data Science.