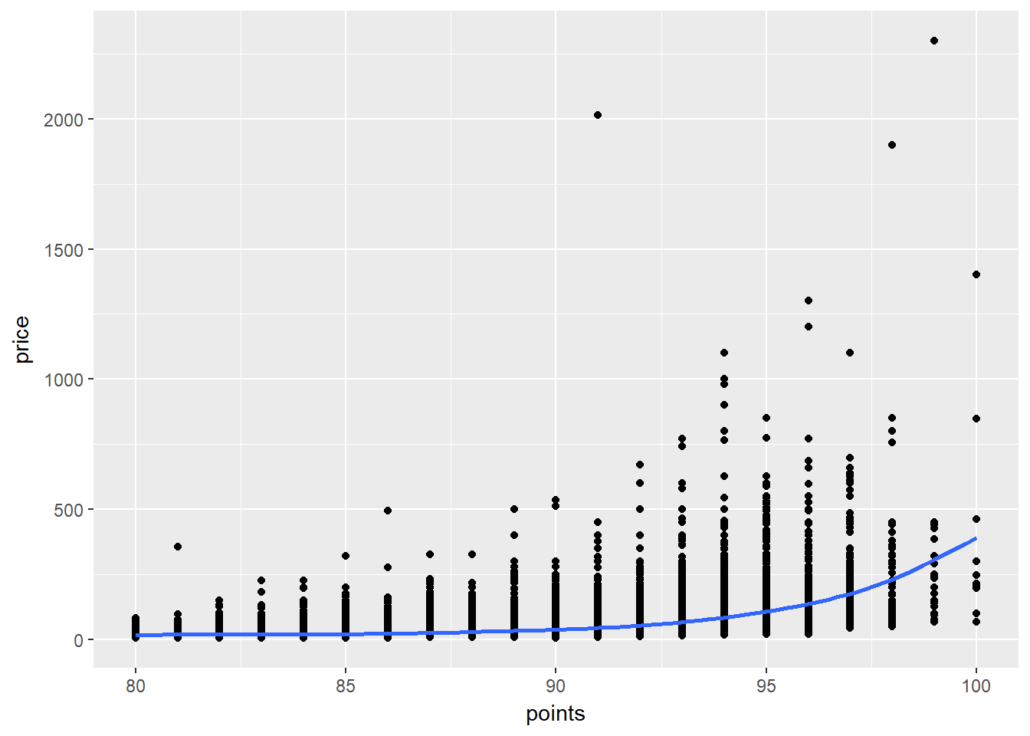
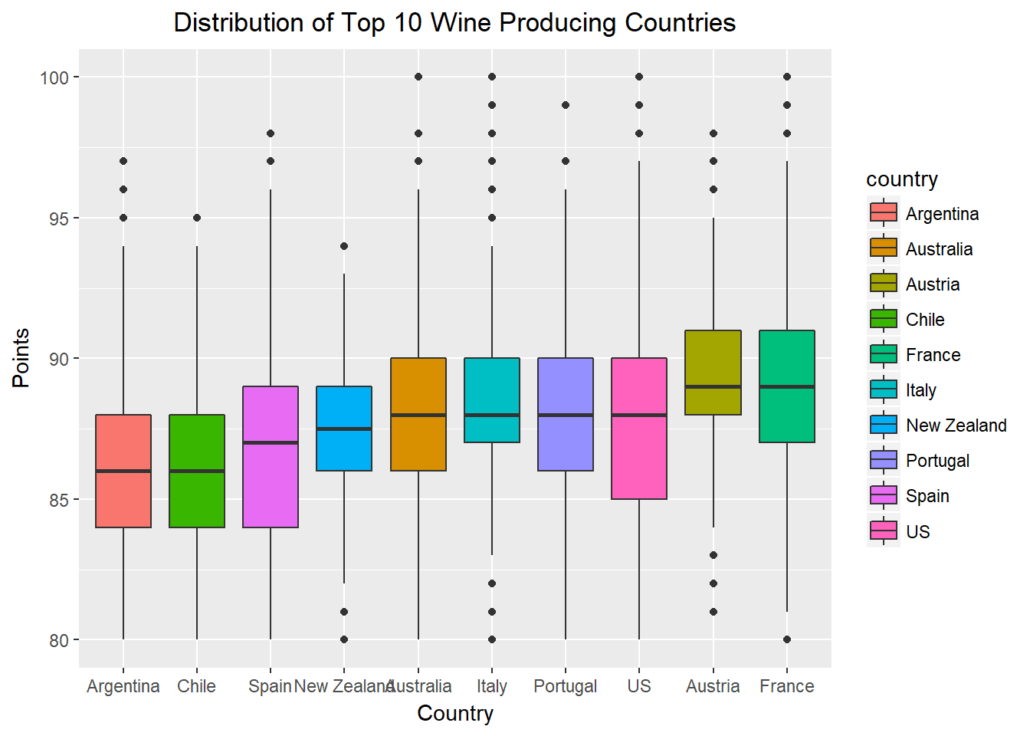
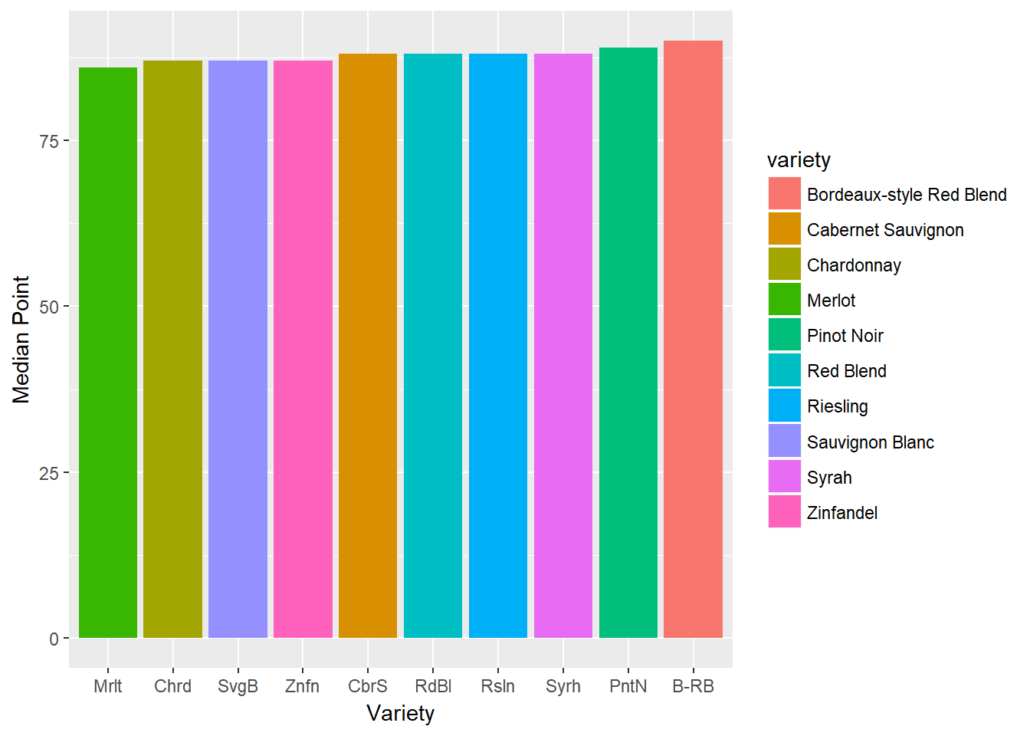
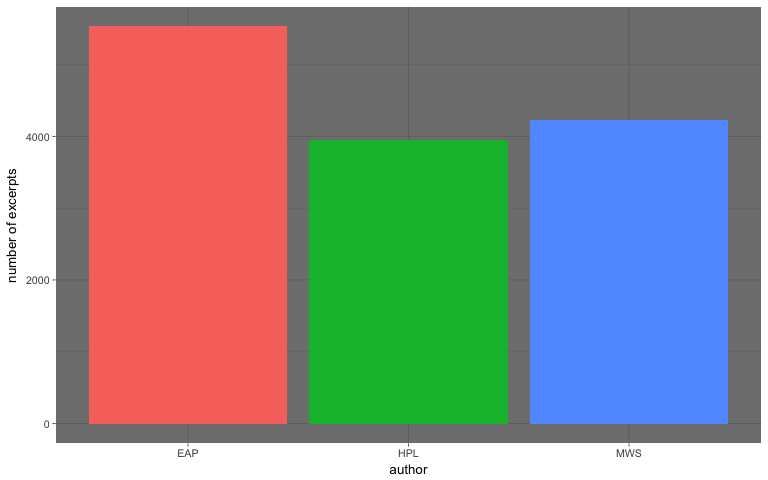
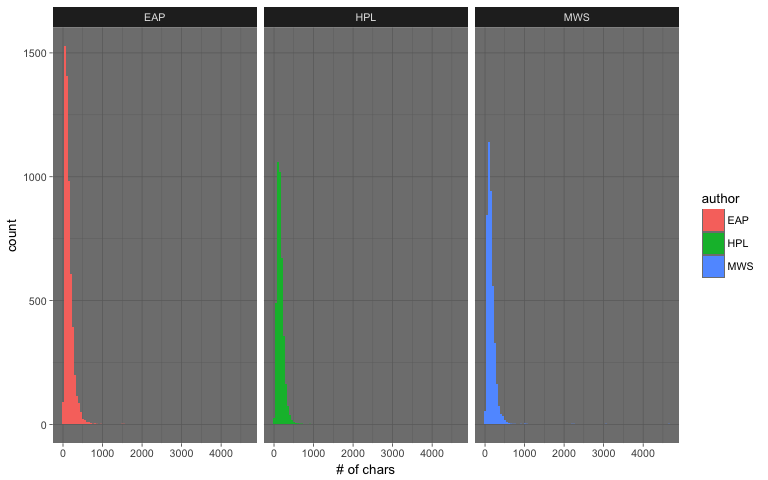
Programming has an extremely vast package ecosystem. It provides robust tools to master all the core skill sets of data science.
For someone like me, who has only some programming experience in Python, the syntax of R programming felt alienating, initially. However, I believe it’s just a matter of time before you adapt to the unique logicality of a new language. The grammar of R flows more naturally to me after having to practice for a while. I began to grasp its kind of remarkable beauty, a beauty that has captivated the heart of countless statisticians throughout the years.
If you don’t know what R programming is, it’s essentially a programming language created for statisticians by statisticians. Hence, it easily becomes one of the most fluid and powerful tools in the field of data science.
Here I’d like to walk through my study notes with the most explicit step-by-step directions to introduce you to the world of R.
Why learn R for data science?
Before diving in, you might want to know why should you learn R for Data Science. There are two major reasons:
1. Powerful analytic packages for data science
Firstly, R programming has an extremely vast package ecosystem. It provides robust tools to master all the core skill sets of Data Science, from data manipulation, and data visualization, to machine learning. The vivid community keeps the R language’s functionalities growing and improving.
2. High industry popularity and demand
With its great analytical power, R programming is becoming the lingua franca for data science. It is widely used in the industry and is in heavy use at several of the best companies that are hiring Data Scientists including Google and Facebook. It is one of the highly sought-after skills for a Data Science job.
You can also learn Python for data science.
Quickstart installation guide
To start programming with R on your computer, you need two things: R and RStudio.
Install R language
You have to first install the R language itself on your computer (It doesn’t come by default). To download R, go to CRAN, https://cloud.r-project.org/ (the comprehensive R archive network). Choose your system and select the latest version to install.
Install RStudio
You also need a hefty tool to write and compile R code. RStudio is the most robust and popular IDE (integrated development environment) for R. It is available on http://www.rstudio.com/download (open source and for free!).
Overview of RStudio
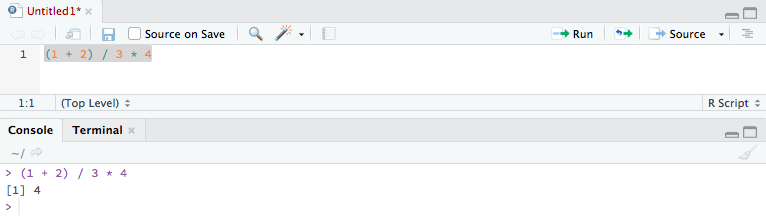
Now you have everything ready. Let’s have a brief overview at RStudio. Fire up RStudio, the interface looks as such:
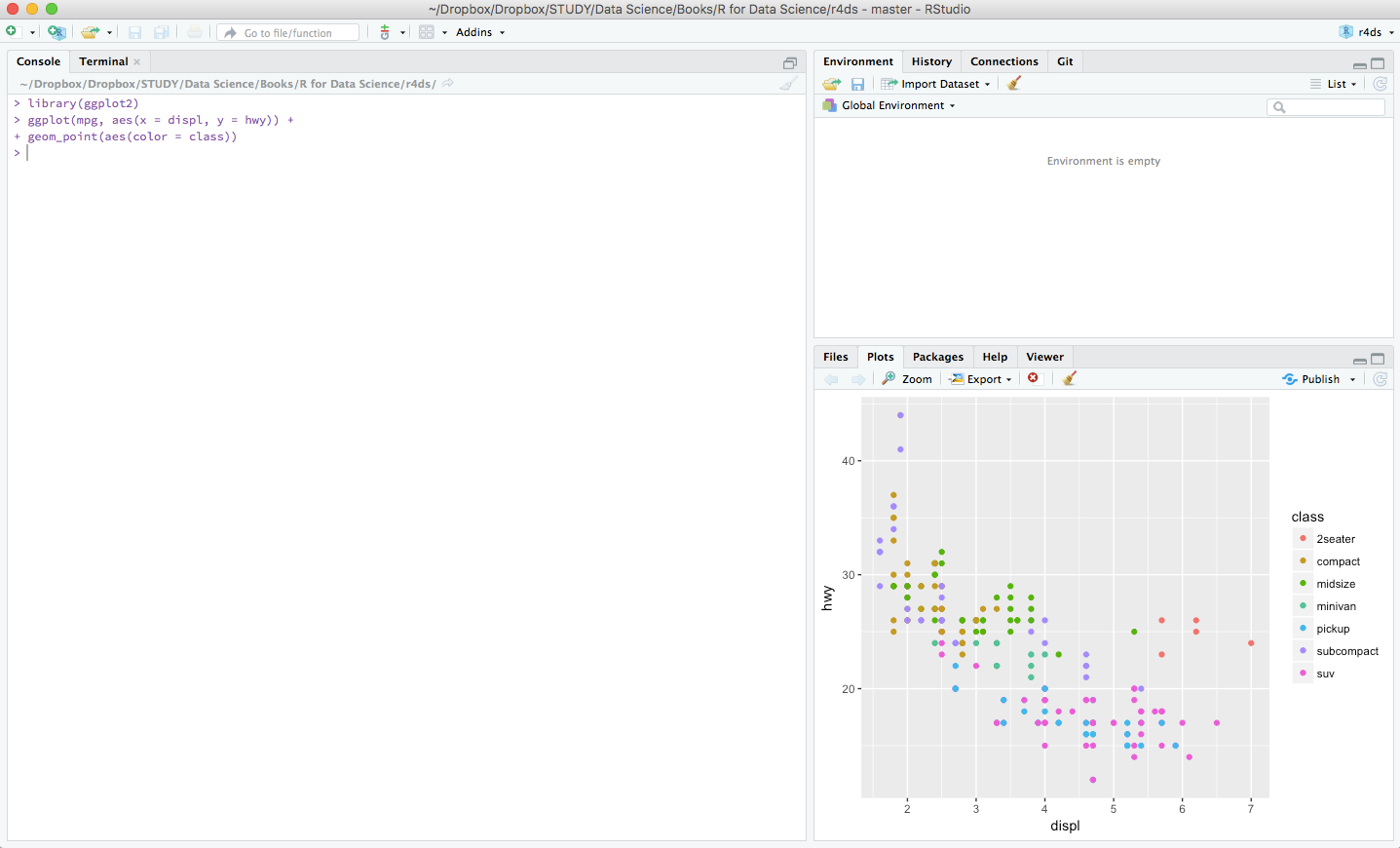
Go to File > New File > R Script to open a new script file. You’ll see a new section appear at the top left side of your interface. A typical RStudio workspace composes of the 4 panels you’re seeing right now:
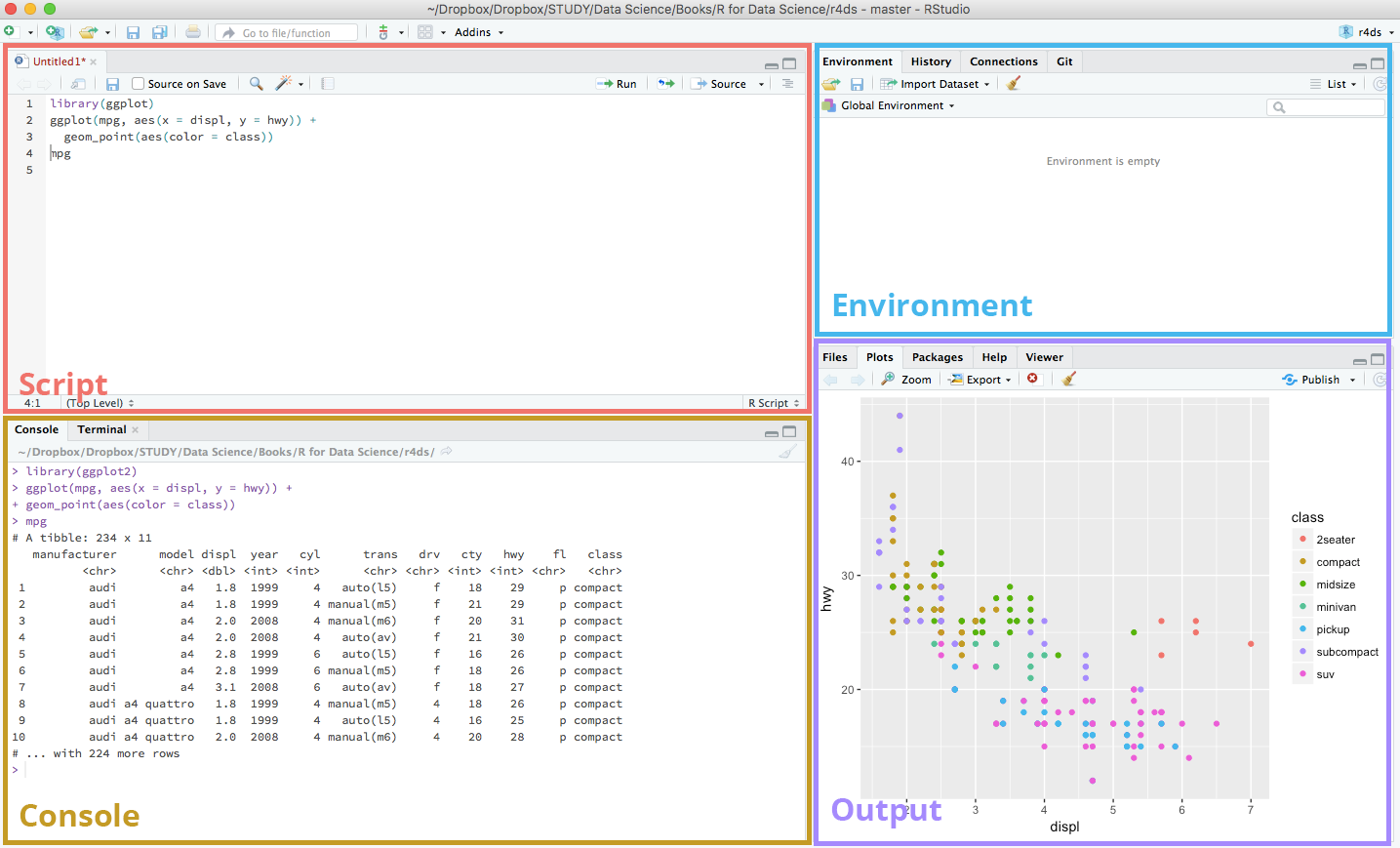
RStudio interface
Here’s a brief explanation of the use of the 4 panels in the RStudio interface:
Script
This is where your main R script located.
Console
This area shows the output of code you run from script. You can also directly write codes in the console.
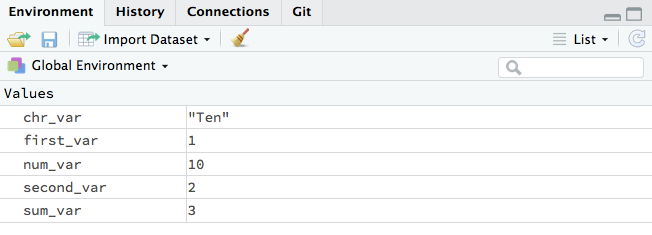
Environment
This space displays the set of external elements added, including dataset, variables, vectors, functions etc.
Output
This space displays the graphs created during exploratory data analysis. You can also seek help with embedded R’s documentation here.
Running R codes
After knowing your IDE, the first thing you want to do is to write some codes.
Using the console panel
You can use the console panel directly to write your codes. Hit Enter and the output of your codes will be returned and displayed immediately after. However, codes entered in the console cannot be traced later. (i.e. you can’t save your codes) This is where the script comes to use. But the console is good for the quick experiment before formatting your codes in the script.
Using the script panel
To write proper R programming codes, 
you start with a new script by going to File > New File > R Script, or hit Shift + Ctrl + N. You can then write your codes in the script panel. Select the line(s) to run and press Ctrl + Enter. The output will be shown in the console section beneath. You can also click on little Run button located at the top right corner of this panel. Codes written in script can be saved for later review (File > Save or Ctrl + S).
Basics of R programming
Finally, with all the set-ups, you can write your first piece of R script. The following paragraphs introduce you to the basics of R.
A quick tip before going: all lines after the symbol # will be treated as a comment and will not be rendered in the output.
Arithmetics
Let’s start with some basic arithmetics. You can do some simple calculations with the arithmetic operators:

Addition +, subtraction -, multiplication *, division / should be intuitive.
# Addition
1 + 1
#[1] 2
# Subtraction
2 - 2
#[1] 0
# Multiplication
3 * 2
#[1] 6
# Division
4 / 2
#[1] 2
The exponentiation operator ^ raises the number to its left to the power of the number to its right: for example 3 ^ 2 is 9.
# Exponentiation
2 ^ 4
#[1] 16
The modulo operator %% returns the remainder of the division of the number to the left by the number on its right, for example 5 modulo 3 or 5 %% 3 is 2.
# Modulo
5 %% 2
#[1] 1
Lastly, the integer division operator %/% returns the maximum times the number on the left can be divided by the number on its right, the fractional part is discarded, for example, 9 %/% 4 is 2.
# Integer division
5 %/% 2
#[1] 2
You can also add brackets () to change the order of operation. Order of operations is the same as in mathematics (from highest to lowest precedence):
- Brackets
- Exponentiation
- Division
- Multiplication
- Addition
- Subtraction
# Brackets (3 + 5) * 2 #[1] 16
Variable assignment
A basic concept in (statistical) programming is called a variable.
A variable allows you to store a value (e.g. 4) or an object (e.g. a function description) in R. You can then later use this variable’s name to easily access the value or the object that is stored within this variable.
Create new variables
Create a new object with the assignment operator <-. All R statements where you create objects and assignment statements have the same form: object_name <- value.
num_var <- 10
chr_var <- "Ten"
To access the value of the variable, simply type the name of the variable in the console.
num_var
#[1] 10
chr_var
#[1] "Ten"
You can access the value of the variable anywhere you call it in the R script, and perform further operations on them.
first_var <- 1
second_var <- 2
first_var + second_var
#[1] 3
sum_var <- first_var + second_var
sum_var
#[1] 3
Naming variables
Not all kinds of names are accepted in R programming. Variable names must start with a letter, and can only contain letters, numbers, . and _. Also, bear in mind that R is case-sensitive, i.e. Cat would not be identical to cat.
Your object names should be descriptive, so you’ll need a convention for multiple words. It is recommended to snake case where you separate lowercase words with _.
i_use_snake_case
otherPeopleUseCamelCase
some.people.use.periods
And_aFew.People_RENOUNCEconvention
Assignment operators
If you’ve been programming in other languages before, you’ll notice that the assignment operator in R programming is quite strange. It uses <- instead of the commonly used equal sign = to assign objects.
Indeed, using = will still work in R, but it will cause confusion later. So you should always follow the convention and use <- for assignment.
<- is a pain to type as you’ll have to make lots of assignments. To make life easier, you should remember RStudio’s awesome keyboard shortcut Alt + – (the minus sign) and incorporate it into your regular workflow.
Environments
Look at the environment panel in the upper right corner, you’ll find all of the objects that you’ve created.
Basic data types
You’ll work with numerous data types in R. Here are some of the most basic ones:

Knowing the data type of an object is important, as different data types work with different functions, and you perform different operations on them. For example, adding a numeric and a character together will throw an error.
To check an object’s data type, you can use the class() function.
# usage class(x)
# description Prints the vector of names of classes an object inherits from. # arguments : An R object. x
Here is an example:
int_var <- 10
class(int_var)
#[1] "numeric"
dbl_var <- 10.11
class(dbl_var)
#[1] "numeric"
lgl_var <- TRUE
class(lgl_var)
#[1] "logical"
chr_var <- "Hello"
class(chr_var)
#[1] "character"
Functions
Functions are the fundamental building blocks of R. In programming, a named section of a program that performs a specific task is a function. In this sense, a function is a type of procedure or routine.
R comes with a prewritten set of functions that are kept in a library. (class() as demonstrated in the previous section is a built-in function.) You can use additional functions in other libraries by installing packages.You can also write your own functions to perform specialized tasks.
Here is the typical form of an R function:
function_name(arg1 = val1, arg2 = val2, ...)
function_name is the name of the function. arg1 and arg2 are arguments. They’re variables to be passed into the function. The type and number of arguments depend on the definition of the function. val1 and val2 are values of the arguments correspondingly.
Passing arguments
R can match arguments both by position > and by name. So you don’t necessarily have to supply the names of the arguments if you have the positions of the arguments placed correctly.
class(x = 1)
#[1] "numeric"
class(1)
#[1] "numeric"
Functions are always accompanied with loads of arguments for configurations. However, you don’t have to supply all of the arguments for a function to work.
Here is documentation of the sum() function.
# usage
sum(..., na.rm = FALSE)
# description Returns the sum of all the values present in its arguments. # arguments ... : Numeric or complex or logical vectors. na.rm : Logical. Should missing values (including NaN) be removed?
From the documentation, we learned that there are two arguments for the sum() function: ... and na.rm Notice that na.rm contains a default value FALSE. This makes it an optional argument. If you don’t supply any values to the optional arguments, the function will automatically fill in the default value to proceed.
sum(2, 10)
#[1] 12
sum(2, 10, NaN)
#[1] NaN
sum(2, 10, NaN, na.rm = TRUE)
#[1] 12
Getting help
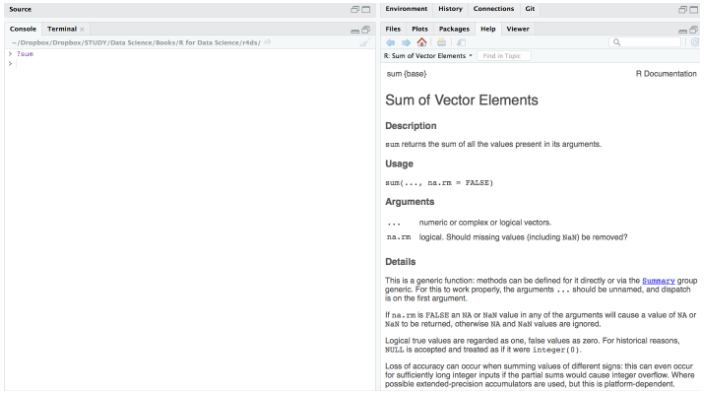
There is a large collection of functions in R and you’ll never remember all of them. Hence, knowing how to get help is important.
RStudio has a handy tool ? to help you in recalling the use of the functions:
?function_name
Look how magical it is to show the R documentation directly at the output panel for quick reference.
Last but not least, if you get stuck, Google it! For beginners like us, our confusions must have gone through numerous R learners before and there will always be something helpful and insightful on the web.
Contributors: Cecilia Lee
Cecilia Lee is a junior data scientist based in Hong Kong