This RHadoop tutorial resamples from a large data set in parallel. This blog is designed for beginners.
How-to: RHadoop (with R on Hadoop) to resample from a large data set
Reposted from Cloudera blog.
Internet-scale datasets present a unique challenge to traditional machine-learning techniques, such as fitting random forests or “bagging.” To fit a classifier to a large data set, it’s common to generate many smaller data sets derived from the initial large data set (i.e. resampling). There are two reasons for this:
- Large data sets typically live in a cluster, so any operations should have some level of parallelism. Separate models fit on separate nodes that contain different subsets of the initial data.
- Even if you could use the entire initial data set to fit a single model, it turns out that ensemble methods, where you fit multiple smaller models using subsets of the data, generally outperform single models. Indeed, fitting a single model with 100M data points can perform worse than fitting just a few models with 10M data points each (so less total data outperforms more total data; e.g. see this paper).
Furthermore, bootstrapping is another popular method that randomly chops up an initial data set to characterize distributions of statistics and also to build ensembles of classifiers (e.g., bagging). Parallelizing bootstrap sampling or ensemble learning can provide significant performance gains even when your data set is not so large that it must live in a cluster. The gains from purely parallelizing the random number generation are still significant.
Sampling with replacement
Sampling-with-replacement is the most popular method for sampling from the initial data set to produce a collection of samples for model fitting. This method is equivalent to sampling from a multinomial distribution where the probability of selecting any individual input data point is uniform over the entire data set.
Unfortunately, it is not possible to sample from a multinomial distribution across a cluster without using some kind of communication between the nodes (i.e., sampling from a multinomial is not embarrassingly parallel). But do not despair: we can approximate a multinomial distribution by sampling from an identical Poisson distribution on each input data point independently, lending itself to an embarrassingly parallel implementation.
Below, we will show you how to implement such a Poisson approximation to enable you to train a random forest on an enormous data set. As a bonus, we’ll be implementing it in R and RHadoop, as R is many people’s statistical tool of choice. Because this technique is broadly applicable to any situation involving resampling a large data set, we begin with a full general description of the problem and solution.
Formal problem statement for RHadoop
Our situation is as follows:
- We have N data points in our initial training set {xi}, where N is very large (106-109) and the data is distributed over a cluster.
- We want to train a set of M different models for an ensemble classifier, where M is anywhere from a handful to thousands.
- We want each model to be trained with K data points, where typically K << N. (For example, K may be 1–10% of.)
The number of training data points available to us, N, is fixed and generally outside of our control. However, K and M are both parameters that we can set and their product KM determines the total number of input vectors that will be consumed in the model fitting process. There are three cases to consider:
- KM < N, in which case we are not using the full amount of data available to us.
- KM = N, in which case we can exactly partition our data set to produce independent samples.
- KM > N, in which case we must resample some of our data with replacement.
The Poisson sampling method described below handles all three cases in the same framework. (However, note that for the case KM = N, it does not partition the data, but simply resamples it as well.)
(Note: The case where K = N corresponds exactly to bootstrapping the full initial data set, but this is often not desired for very large data sets. Nor is it practical from a computational perspective: performing a bootstrap of the full data set would require the generation of MN data points and M scans of an N-sized data set. However, in cases where this computation is desired, there exists an approximation called a “Bag of Little Bootstraps.”)
The goal
So our goal is to generate M data sets of size K from the original N data points where N can be very large and the data is sitting in a distributed environment. The two challenges we want to overcome are:
- Many resampling implementations perform M passes through the initial data set. which is highly undesirable in our case because the initial data set is so large.
- Sampling-with-replacement involves sampling from a multinomial distribution over the N input data points. However, sampling from a multinomial distribution requires message passing across the entire data set, so it is not possible to do so in a distributed environment in an embarrassingly parallel fashion (i.e., as a map-only MapReduce job).
Poisson-approximation resampling
Our solution to these issues is to approximate the multinomial sampling by sampling from a Poisson distribution for each input data point separately. For each input point xi, we sample M times from a Poisson(K / N) distribution to produce M values {mj}, one for each model j. For each data point xi and each model j, we emit the key-value pair *<j, xi>*a total of MJ times (where MJ can be zero). Because the sum of multiple Poisson variables is Poisson, the number of times a data point is emitted is distributed as Poisson(KM / N), and the size of each generated sample is distributed as Poisson(K), as desired. Because the Poisson sampling occurs for each input point independently, this sampling method can be parallelized in the map portion of a MapReduce job.
(Note that our approximation never guarantees that every single input data point is assigned to at least one of the models, but this is no worse than multinomial resampling of the full data set. However, in the case where KM = N, this is particularly bad in contrast to the alternative of partitioning the data, as partitioning will guarantee independent samples using all N training points, while resampling can only generate (hopefully) uncorrelated samples with a fraction of the data.)
Ultimately, each generated sample will have a size K on average, and so this method will approximate the exact multinomial sampling method with a single pass through the data in an embarrassingly parallel fashion, addressing both of the big data limitations described above. Because we are randomly sampling from the initial data set, and similarly to the “exact” method of multinomial sampling, some of the initial input vectors may never be chosen for any of the samples. We expect that approximately exp{–KM / N} of the initial data will be entirely missing from any of the samples (see figure below).
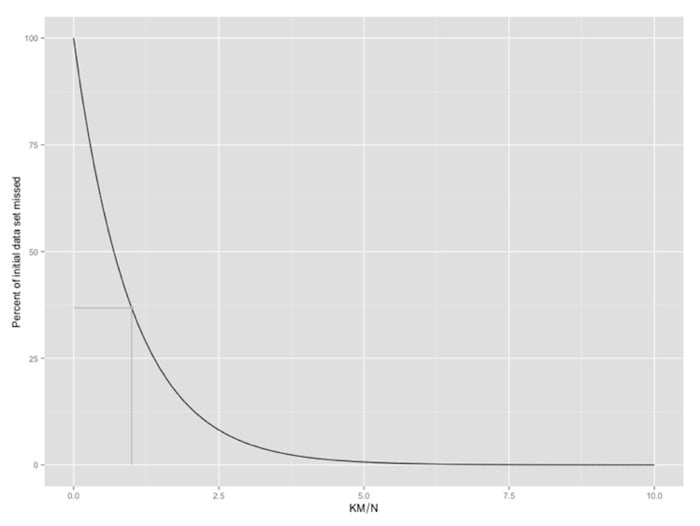
Amount of missed data as a function of KM / N. The value for KM = N is marked in gray.
Finally, the MapReduce shuffle distributes all the samples to the reducers and the model fitting or statistic computation is performed on the reduce side of the computation.
The algorithm for performing the sampling is presented below in pseudocode. Recall that there are three parameters —N, M, and K — where one is fixed; we choose to specify T = K / N as one of the parameters as it eliminates the need to determine the value of N in advance.
/# example sampling parameters
T = 0.1 # param 1: K / N; average fraction of input data in each model; 10%
M = 50 # param 2: number of models
def map(k, v): // for each input data point
for i in 1:M // for each model
m = Poisson(T) // num times curr point should appear in this sample
if m > 0
for j in 1:m // emit current input point proper num of times
emit (i, v)
def reduce(k, v):
fit model or calculate statistic with the sample in vNote that even more significant performance enhancements can be achieved if it is possible to use a combiner, but this is highly statistic/model-dependent.
Example: Kaggle Data Set on Bulldozer Sale Prices
We will apply this method to test out the training of a random forest regression model on a Kaggle data set found here. The data set comprises ~400k training data points. Each data point represents a sale of a particular bulldozer at an auction, for which we have the sale price along with a set of other features about the sale and the bulldozer. (This data set is not especially large, but will illustrate our method nicely.) The goal will be to build a regression model using an ensemble method (specifically, a random forest) to predict the sale price of a bulldozer from the available features.

Could be yours for $141,999.99
The data are supplied as two tables: a transaction table that includes the sale price (target variable) and some other features, including a reference to a specific bulldozer; and a bulldozer table, that contains additional features for each bulldozer. As this post does not concern itself with data munging, we will assume that the data come pre-joined. But in a real-life situation, we’d incorporate the join as part of the workflow by, for example, processing it with a Hive query or a Pig script. Since in this case, the data are relatively small, we simply use some R commands. The code to prepare the data can be found here.
Quick note on R and RHadoop
As so much statistical work is performed in R, it is highly valuable to have an interface to use R over large data sets in a Hadoop cluster. This can be performed with RHadoop, which is developed with the support of Revolution Analytics. (Another option for R and Hadoop is the RHIPE project.)
One of the nice things about RHadoop is that R environments can be serialized and shuttled around, so there is never any reason to explicitly move any side data through Hadoop’s configuration or distributed cache. All environment variables are distributed around transparently to the user. Another nice property is that Hadoop is used quite transparently to the user, and the semantics allow for easily composing MapReduce jobs into pipelines by writing modular/reusable parts.
The only thing that might be unusual for the “traditional” Hadoop user (but natural to the R user) is that the mapper function should be written to be fully vectorized (i.e., keyval() should be called once per mapper as the last statement). This is to maximize the performance of the mapper (since R’s interpreted REPL is quite slow), but it means that mappers receive multiple input records at a time and everything the mappers emit must be grouped into a single object.
Finally, I did not find the RHadoop installation instructions (or the documentation in general) to be in a very mature state, so here are the commands I used to install RHadoop on my small cluster.
Fitting an ensemble of Random forests with poisson sampling on RHadoop
We implement our Poisson sampling strategy with RHadoop. We start by setting global values for our parameters:
frac.per.model <- 0.1 # 10% of input data to each sample on avg num.models <- 50As mentioned previously, the mapper must deal with multiple input records at once, so there needs to be a bit of data wrangling before emitting the keys and values:
#MAPPER
poisson.subsample <- function(k, v) {
#parse data chunk into data frame
#raw is basically a chunk of a csv file
raw <- paste(v, sep="\n")
#convert to data.frame using read.table() in parse.raw()
input <- parse.raw(raw)
#this function is used to generate a sample from
#the current block of data
generate.sample <- function(i) {
#generate N Poisson variables
draws <- rpois(n=nrow(input), lambda=frac.per.model)
#compute the index vector for the corresponding rows,
#weighted by the number of Poisson draws
indices <- rep((1:nrow(input))[draws > 0], draws[draws > 0])
#emit the rows; RHadoop takes care of replicating the key appropriately
#and rbinding the data frames from different mappers together for the
#reducer
keyval(rep(i, length(indices)), input[indices, ])
}
#here is where we generate the actual sampled data
raw.output <- lapply(1:num.models, generate.sample)
#and now we must reshape it into something RHadoop expects
output.keys <- do.call(c, lapply(raw.output, function(x) {x$key}))
output.vals <- do.call(rbind, lapply(raw.output, function(x) {x$val}))
keyval(output.keys, output.vals)
}Because we are using R, the reducer can be incredibly simple: it takes the sample as an argument and simply feeds it to our model-fitting function, randomForest():
#REDUCE function
fit.trees <- function(k, v) {
#rmr rbinds the emited values, so v is a dataframe
#note that do.trace=T is used to produce output to stderr to keep
#the reduce task from timing out
rf <- randomForest(formula=model.formula,
data=v,
na.action=na.roughfix,
ntree=10, do.trace=TRUE)
#rf is a list so wrap it in another list to ensure that only
#one object gets emitted. this is because keyval is vectorized
keyval(k, list(forest=rf))
}Keep in mind that in our case, we are actually fitting 10 trees per sample, but we could easily only fit a single tree per “forest”, and merge the results from each sample into a single real forest.
Note that the choice of predictors has specified in the variable model. formula. R’s random forest implementation does not support factors that have more than 32 levels, as the optimization problem grows too fast. To illustrate the Poisson sampling method, we chose to simply ignore those features, even though they probably contain useful information for regression. In a future blog post, we will address various ways that we can get around this limitation.
The MapReduce job itself is initiated like so:
mapreduce(input="/poisson/training.csv",
input.format="text", map=poisson.subsample,
reduce=fit.trees,
output="/poisson/output")The resulting trees are dumped in HDFS at Poisson/output.
Finally, we can load the trees, merge them, and use them to classify new test points:
raw.forests <- from.dfs("/poisson/output")[["val"]]
forest <- do.call(combine, raw.forests)Conclusion
Each of the 50 samples produced a random forest with 10 trees, so the final random forest is an ensemble of 500 trees, fitted in a distributed fashion over a Hadoop cluster. The full set of source files is available here.
Hopefully, you have now learned a scalable approach for training ensemble classifiers or bootstrapping in a parallel fashion by using a Poisson approximation to multinomial sampling.