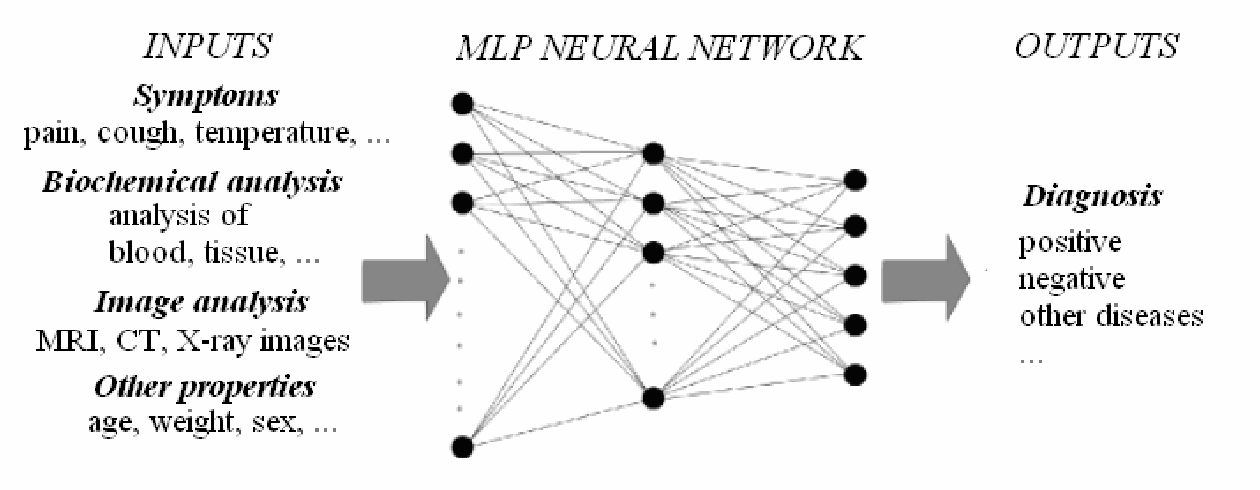
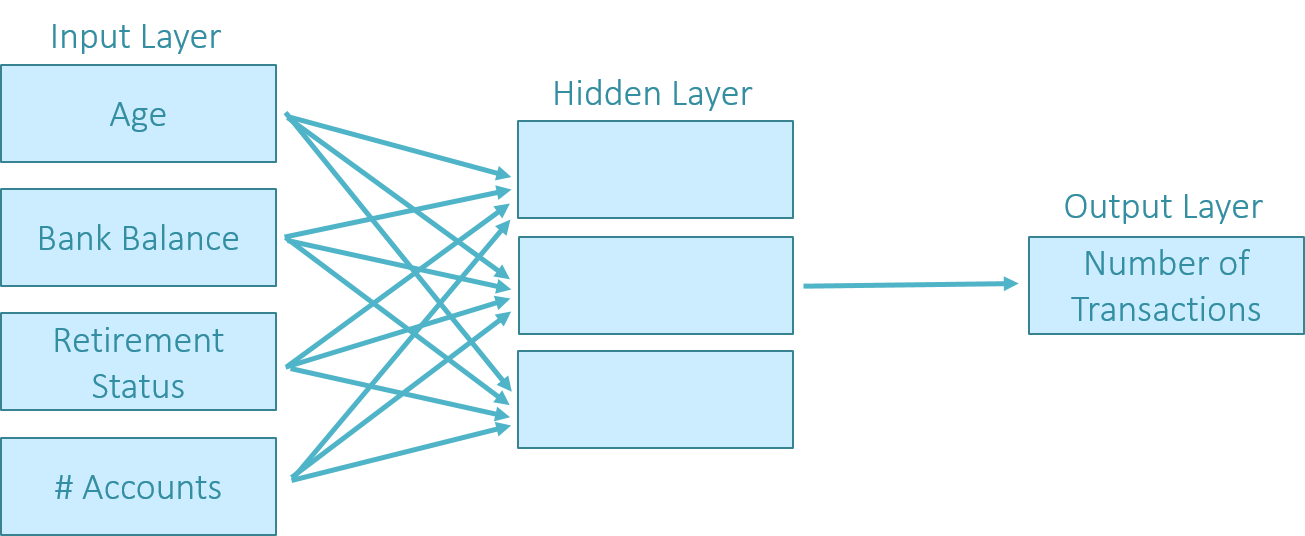
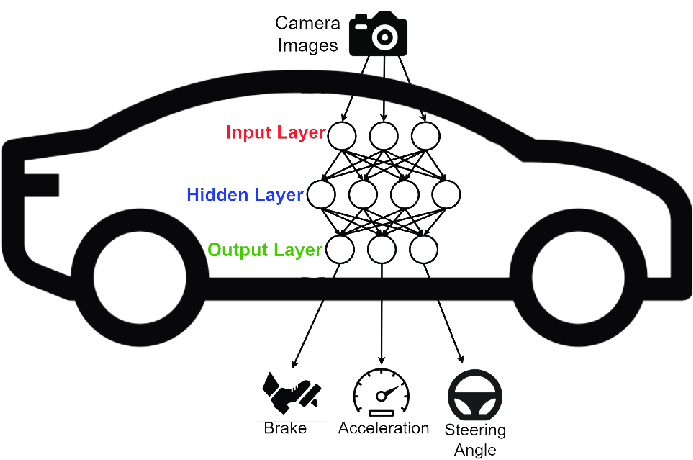
Neural networks have emerged as a transformative force across various sectors, revolutionizing industries such as healthcare, finance, and automotive technology.
Inspired by the human brain, artificial neural networks (ANNs) leverage bio-inspired computational models to solve complex problems and perform tasks previously exclusive to human intelligence.
The effectiveness of neural networks largely hinges on the quality and quantity of data used for training, underlining the significance of robust datasets in achieving high-performing models.
Ongoing research and development signal a future where neural network applications could expand even further, potentially uncovering new ways to address global challenges and drive progress in the digital age.
In this blog, we will explore the current applications of neural networks across 7 different industries, exploring the different enhanced aspects of each.
Customer Support
Chat Systems
They have transformed customer support through chat systems. By analyzing customer queries and past conversations, neural networks understand the context and provide relevant and accurate responses.
This technology, known as natural language processing (NLP), enables chatbots to interact with customers in a conversational manner, providing instant and personalized support.
Continuous Improvement
These systems learn from extensive datasets of customer interactions, empowering businesses to address inquiries efficiently, from basic FAQs to complex troubleshooting. Companies like Talla use neural networks to enhance their AI-driven customer support solutions.
Proactive Support
Neural networks anticipate potential issues based on historical interactions, improving the overall customer experience and reducing churn rates.This proactive approach ensures that businesses can address problems before they escalate, maintaining customer satisfaction.
Neural networks boost telecommunications performance, reliability, and service offerings by managing and controlling network operations. They also power intelligent customer service solutions like voice recognition systems.
Data Compression and Optimization
Neural networks optimize network functionality by compressing data for efficient transmission and acting as equalizers for clear signals. This improves communication experiences for users and ensures optimal network performance even under heavy load conditions.
Enhanced Communication
These network architectures enable real-time translation of spoken languages. For example, Google Translate uses neural networks to provide accurate translations instantly.
This technology excels at pattern recognition tasks like facial recognition, speech recognition, and handwriting recognition, making communication seamless across different languages and regions.
These networks drive advancements in medical diagnosis and treatment, such as skin cancer detection. Advanced algorithms can distinguish tissue growth patterns, enabling early and accurate detection of skin cancer.
For instance, SkinVision, an app that uses neural networks for skin cancer detection, has a specificity of 80% and a sensitivity of 94%, which is higher than most dermatologists.
An overview of neural network application in diagnostics – Source: Semantic Scholar
Personalized Medicine
They analyze genetic information and patient data to forecast treatment responses, enhancing treatment effectiveness and minimizing adverse effects. IBM Watson is an example that uses neural networks to analyze cancer patient data and suggest personalized treatment plans, tailoring interventions to individual patient needs.
Medical Imaging
Neural networks analyze data from MRI and CT scans to identify abnormalities like tumors with high precision, speeding up diagnosis and treatment planning.This capability reduces the time required for medical evaluations and increases the accuracy of diagnoses.
Drug Discovery
Neural networks predict interactions between chemical compounds and biological targets, reducing the time and costs associated with bringing new drugs to market. This accelerates the development of new treatments and ensures that they are both effective and safe.
Finance
Stock Market Prediction
These deep-learning architectures analyze historical stock data to forecast market trends, aiding investors in making informed decisions. Hedge funds use neural networks to predict stock performance and optimize investment strategies.
Fraud Detection
They scrutinize transaction data in real-time to flag suspicious activities, safeguarding financial institutions from potential losses. Companies like MasterCard and PayPal use neural networks to detect and prevent fraudulent transactions.
Risk Assessment
Neural networks evaluate factors such as credit history and income levels to predict the likelihood of default, helping lenders make sound loan approval decisions. This capability ensures that financial institutions can manage risk effectively while providing services to eligible customers.
Sample structure of a neural network at use in a financial setting – Source: Medium
Automotive
Autonomous Vehicles
The automotive industry harnesses these networks in autonomous vehicles and self-driving cars. These networks interpret sensor data to make real-time driving decisions, ensuring safe and efficient navigation. Tesla and Waymo are examples of companies using neural networks in autonomous driving technologies.
Traffic Management
Neural networks help manage traffic and prevent accidents by predicting congestion, optimizing signal timings, and providing real-time hazard information. This leads to smoother traffic flow and reduces the likelihood of traffic-related incidents.
Autonomous vehicles are an application of neural networks – Source: ResearchGate
Vehicle Maintenance
Neural networks predict mechanical failures before they occur, facilitating timely repairs and prolonging vehicle lifespan. This proactive approach helps manufacturers like BMW maintain vehicle reliability and performance.
Aerospace
Fault Detection
These networks detect faults in aircraft components before they become problems, minimizing the risk of in-flight failures.This enhances the safety and reliability of air travel by ensuring that potential issues are addressed promptly.
Autopilot Systems
They also enhance autopilot systems by constantly learning and adapting, contributing to smoother and more efficient autopiloting. This reduces the workload on human pilots and improves flight stability and safety.
Flight Path Optimization
Neural networks simulate various flight paths, allowing engineers to test and optimize routes for maximum safety and fuel efficiency. This capability helps in planning efficient flight operations and reducing operational costs.
These networks design new chemicals, optimize production processes, and predict the quality of finished products. This leads to better product design and fewer defects. Companies like General Electric use neural networks to enhance their manufacturing processes.
Predictive Maintenance
They can also identify potential equipment problems before they cause costly downtime, allowing for proactive maintenance and saving time and money. This application is used by companies like Unilever to maintain operational efficiency.
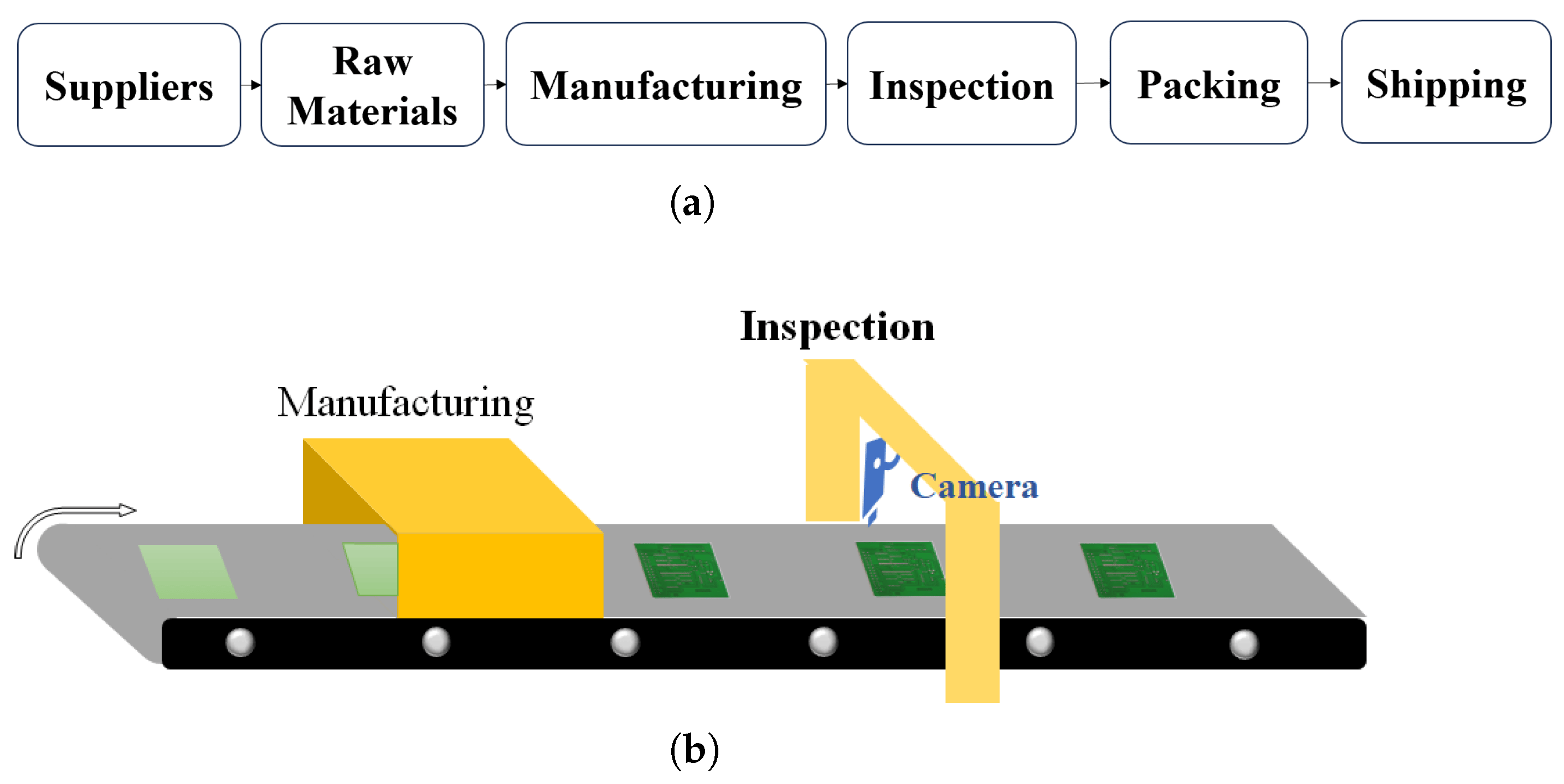
Neural networks play a crucial role in industrial manufacturing processes – Source: MDPI
Quality Inspection
They monitor production in real-time, ensuring consistent quality. They can even inspect visual aspects like welds, freeing up human workers for more complex tasks. This technology is widely used in the automotive and electronics industries.
What are the Future Applications of Neural Networks?
Integration with AI and Robotics
Combining neural networks with AI and robotics creates advanced autonomous systems capable of performing intricate tasks with human-like intelligence. This integration enhances productivity by allowing robots to adapt to new situations and learn from their environment.
Such systems can perform complex operations in manufacturing, healthcare, and defense, significantly improving efficiency and accuracy.
Virtual Reality
Integration with virtual reality (VR) technologies fosters more immersive and interactive experiences in fields such as entertainment and education. By leveraging neural networks, VR systems can create realistic simulations and responsive environments, providing users with a deeper sense of presence.
This technology is also being used in professional training programs to simulate real-world scenarios, enhancing learning outcomes.
Environmental Monitoring
These networks analyze data from sensors and satellites to predict natural disasters, monitor deforestation, and track climate change patterns. These systems aid in mitigating environmental impacts and preserving ecosystems by providing accurate and timely information to decision-makers.
As neural networks continue to expand into new domains, they offer innovative solutions to pressing challenges, shaping the future and creating new opportunities for growth.
Neural networks are computational models that learn to perform tasks by considering examples, generally without being pre-programmed with task-specific rules. Inspired by human brain structure, they are designed to perform as powerful tools for pattern recognition, classification, and prediction tasks.
There are several types of neural networks with vast and transformative applications spread across various sectors. These include image recognition, natural language processing, autonomous vehicles, financial services, healthcare, recommender systems, gaming and entertainment, and speech recognition.
Neural networks play a critical role in modern AI and machine learning due to their ability to model complex patterns and relationships within data. They are capable of learning and improving over time as they are exposed to more data. Hence, solving a wide array of complex and high-dimensional problems unlike traditional algorithms.
In this blog, we will discuss the 14 major types of neural networks that are put to practical use across industries. Before we dig deeper into each kind of neural network, let’s navigate their two major categories.
Shallow and Deep: Two Categories of Neural Networks
Neural networks are majorly divided into two categories: Deep neural networks and Shallow neural networks. Their distinction is based on the number of hidden layers in their architecture. As the names suggest, deep neural networks have a greater number of layers than their shallow counterparts.
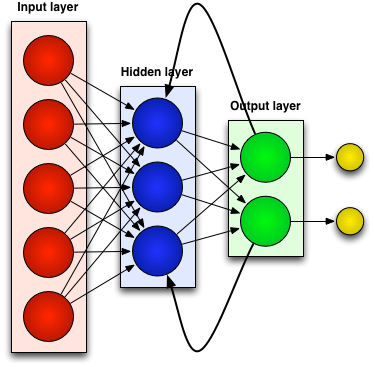
Shallow Neural Networks
These refer to a class of artificial neural networks that typically consist of an input layer and an output layer, with at most one hidden layer in between. Hence, they have a simpler structure and are used for less complex tasks as they are simpler to understand and implement.
Their simpler architecture also results in the need for less computational power and resources, making them quicker to train. However, it also results in their limitations as they struggle with complex modeling problems. Moreover, they possess the risk of overfitting.
Despite these limitations, shallow neural networks are a useful resource. Some of their practical applications in the world of data analysis include:
Linear Regression: Shallow neural networks are often used in linear regression problems where the relationship between the input and output variables is relatively simple
Classification Tasks: They are effective for simple classification tasks where the input data can be linearly separable or nearly so
Hence, shallow neural networks are crucial for AI and ML. Despite their simplicity, they lay the groundwork for understanding more intricate neural network architectures and remain a valuable tool for specific applications where simplicity and efficiency are paramount.
This category of neural networks is defined by several layers of neurons between the input and output layers. This depth of architecture enables them to model complex patterns and relationships within large sets of data, making them highly effective for a wide range of artificial intelligence tasks.
Thus, they offer enhanced accuracy when trained using sufficient amounts of data. Moreover, they have the ability to automatically detect and use relevant features from raw data, reducing the need for manual feature engineering. However, they also possess the risk of overfitting while also using extensive computational resources.
Owing to these benefits and limitations, deep neural networks have made their mark in the industry for the following uses:
Image Recognition: They are extensively used in image recognition tasks, enabling applications such as facial recognition and medical image analysis
Speech Recognition: They are pivotal in developing systems that convert spoken language into text, used in virtual assistants and automated transcription services
Natural Language Processing (NLP): They help in understanding and generating human language, applicable in translation services, sentiment analysis, and chatbots
Hence, deep neural networks are crucial in pushing the boundaries of what machines can learn and achieve, handling tasks that require understanding complex patterns, and making intelligent decisions based on large volumes of data.
Since we have now explored the two major categories of neural networks, let’s dig deeper into the 5 main types of architectures that belong to each.
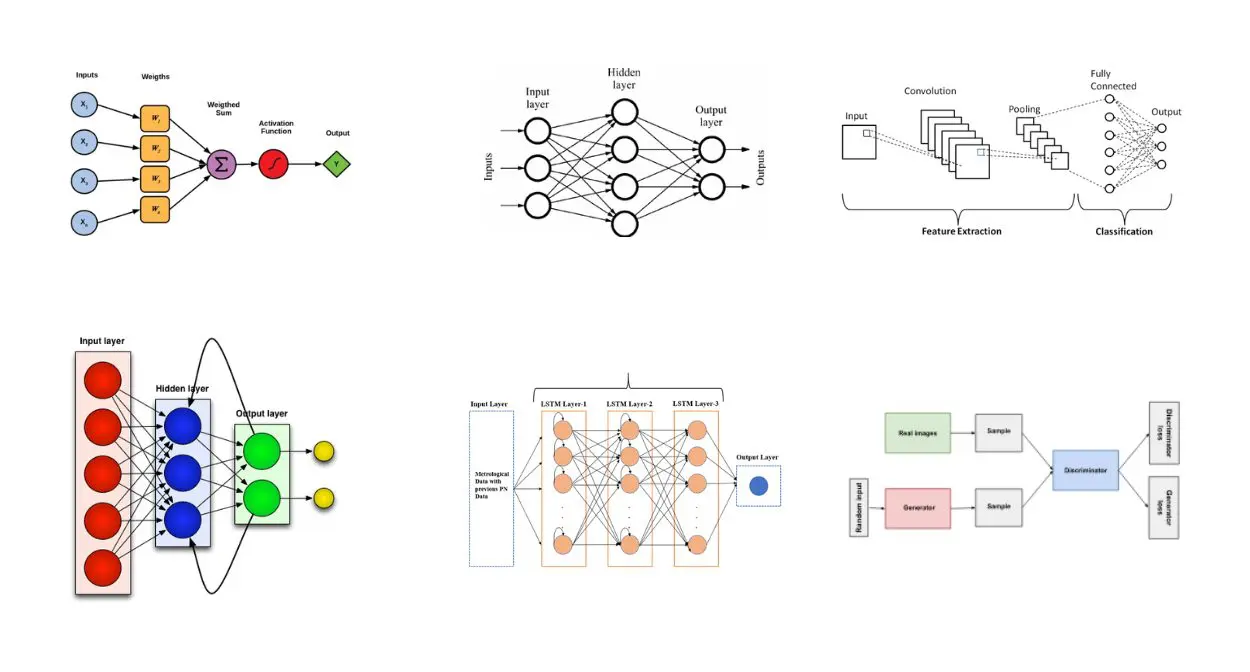
Perceptron
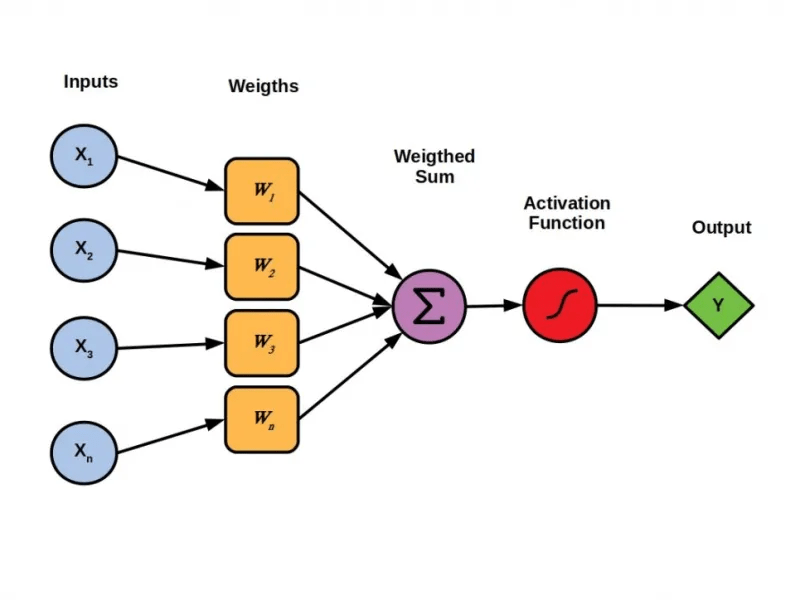
It is a shallow neural network with the simplest model consisting of just one hidden layer. Hence, it is also considered a fundamental building block for neural networks. It can perform certain computations to detect features or business intelligence in the input data.
Perceptrons take multiple numerical inputs and assign a weight to each to determine their influence on the output. The weighted inputs are then summed together and the value is passed through an activation function to determine the output.
They are also known as threshold logic units (TLUs) and serve as a supervised learning algorithm that classifies data into two categories, making them a binary classifier. The perceptron separates the input space into two categories by a hyperplane, determined by its weight and bias.
Real-world Applications of Perceptrons
While their simplicity makes them an excellent starting point for learning the basic principles of neural networks, they have several practical uses. Some of these include:
Simple Image Recognition: Distinguishing between handwritten digits (0-9) where the data is often somewhat linearly separable.
Spam Filtering: Classifying emails as spam or not spam based on a few key features (e.g., presence of certain keywords).
Limitations
Linear Problems Only: Perceptrons can only learn linearly separable problems, such as the boolean AND problem. They struggle with non-linear problems, exemplified by their inability to solve the boolean XOR problem. This limitation restricts their applicability to more complex decision boundaries.
Single Layer Limitation: Being a single-layer model, perceptrons are limited in their ability to process complex patterns or multiple layers of decision-making, a gap filled by more advanced neural network models like Multilayer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs).
Thus, perceptrons are a significant concept in neural networks and a valuable learning tool for understanding the core principles of neural networks. However, for real-world applications requiring complex pattern recognition or handling non-linear data, more advanced neural network architectures are necessary.
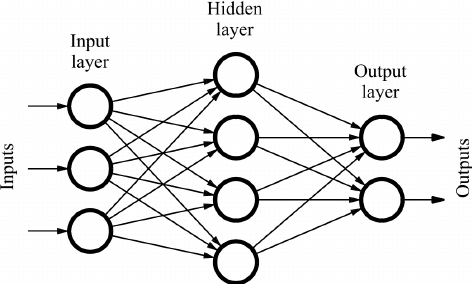
Feed Forward Neural Networks (FNNs)
Also known as feedforward networks, they are a type of shallow neural network where connections between the nodes do not form a cycle. They form a multi-layered network where information moves in only one direction—from input to output, through one or more layers of nodes, without any cycles or loops.
The basic learning process of feedforward networks remains the same as that of a perceptron, involving the forward pass of input data through the network to generate output with each layer transforming the data based on its weights and activation function.
During training, the network adjusts its weights to minimize the error between the predicted output and the actual target value.
Real-world Applications of FNNs
Facial Recognition: Feedforward neural networks are the foundation for facial recognition technologies, where they process large volumes of ‘noisy’ data to create ‘clean’ outputs for identifying faces.
Natural Language Processing (NLP): They are used in natural language processing (NLP) tasks, including speech recognition and text classification, enabling computers to understand and interpret human language.
Computer Vision: In the field of computer vision, feedforward networks are employed for image classification and object detection, aiding in the automation of visual understanding tasks.
Limitations
Lack of Feedback Connections: One of the primary limitations of feedforward neural networks is the absence of feedback connections, which means they are not suitable for tasks where previous outputs are needed to influence future outcomes, such as in sequence prediction problems.
Difficulty in Capturing Temporal Sequence Information: Due to their feedforward nature, these networks struggle with problems that involve time series data or any data where the sequence order is important.
Risk of Overfitting: With a large number of parameters (weights and biases) in complex FNNs, there’s a chance of overfitting the training data, leading to poor performance on unseen data.
Hence, FNNs represent a crucial development in the field of artificial intelligence and machine learning, providing the groundwork for more complex neural network models. Despite their limitations, they have found widespread application across various domains, demonstrating their versatility and effectiveness in solving real-world problems.
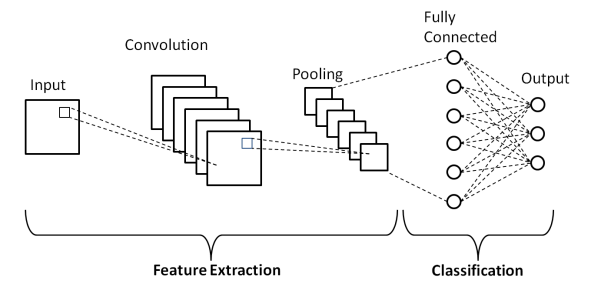
Convolutional Neural Networks (CNNs)
They are a specialized type of deep neural network used for processing data that has a grid-like topology, such as images. Hence, they excel at image recognition and analysis tasks. CNNs utilize a mathematical operation known as convolution, a specialized kind of linear operation.
Convolutional Neural Networks (CNNs) – Source: Medium
They can recognize patterns with extreme variability (such as handwritten characters), and thanks to their deep architecture, they can recognize patterns at different levels of abstraction (such as edges or shapes in the lower layers and more complex objects in the higher layers).
Real-world Applications of CNNs
Automated Driving: CNNs are used in self-driving cars for detecting objects such as stop signs and pedestrians to make driving decisions.
Facial Recognition: They are employed in security systems for facial recognition purposes, helping in identifying persons in surveillance videos.
Agriculture: In agriculture, CNNs help in crop and soil monitoring, disease detection, and automated harvesting systems.
Medical Image Analysis: They analyze medical scans for disease detection, tumor classification, and drug discovery.
Limitations
High Complexity: CNNs are quite complex to design and maintain. They require considerable expertise and knowledge to set up and tune properly.
Expensive Computation: They are computationally intensive, requiring significant resources, which can be a barrier in terms of hardware requirements for training on large datasets.
Overfitting Risk: Due to their deep and complex architecture, there’s a high risk of overfitting, especially when not enough training data is available.
Limited to Grid-like Data: CNNs are primarily designed for analyzing grid-like data like images. They might not be the best choice for tasks involving sequential data or non-grid-structured inputs.
However, despite their limitations, CNNs have revolutionized the field of machine vision by their ability to automatically learn the optimal features and structures from the training data, leading to numerous applications across various industries.
Recurrent Neural Networks (RNNs)
RNNs belong to the category of deep neural networks. They excel in processing sequential data for tasks such as speech recognition, natural language processing, and time series prediction.
They are known for their “memory” which allows them to retain information from previous inputs to influence the current output, making them ideal for applications where data points are interdependent.
They are built on the foundation of FNNs with hidden layers. The hidden layer output loops back into itself, creating a memory of past inputs that informs how the network processes new information. This internal state allows RNNs to handle sequential data like text or speech, where understanding the order is crucial.
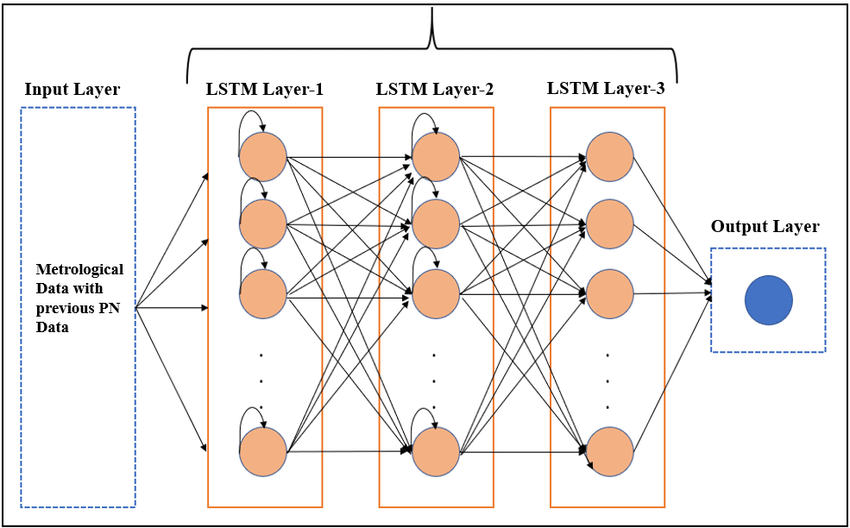
Long Short-Term Memory (LSTM) Networks – A Specific Type of RNN
They are a special kind of RNN that is capable of learning and remembering over long sequences. Unlike traditional RNNs, LSTMs are designed to avoid the long-term dependency problem, allowing them to remember information for longer periods of time.
It is achieved through special units called LSTM units that include components like input, output, and forget gates. These gates control the flow of information into and out of the cell, deciding what to keep in memory and what to discard, thus enabling the network to make more precise decisions based on historical data.
Visual representation of LSTM architecture – Source: ResearchGate
Real-world Applications of RNNs
Speech Recognition: RNNs are employed in speech recognition systems, enabling devices to understand and respond to spoken commands.
Text Generation: They are used in applications that generate human-like text, enabling features like chatbots or virtual assistants to provide more engaging user interactions.
Music Composition: RNNs can also be used to compose music by learning patterns in musical notations and predicting subsequent notes, thus generating new pieces of music.
Time Series Forecasting: They can predict future stock prices, weather patterns, or sales trends.
Limitations
Vanishing Gradient Problem: During training, RNNs can suffer from the vanishing gradient problem, where gradients shrink as they are propagated back through each timestep of the input sequence. This makes it difficult for RNNs to learn long-range dependencies within the input data.
High Computational Burden: Training RNNs is computationally intensive, particularly for long sequences, which can make them less scalable compared to other neural network architectures.
Difficulty in Parallelization: The sequential nature of RNNs means that they cannot be easily parallelized, which limits the speed of computation and training compared to networks like CNNs that can process inputs in parallel.
In summary, RNNs are powerful in handling sequential data with dependencies over time, making them invaluable in diverse fields such as language processing, financial forecasting, and creative applications like music generation. Despite their challenges, they are uniquely suited for tasks involving sequential data.
Generative Adversarial Networks (GANs)
GANs are a unique class of deep-learning architectures used for generative modeling through unsupervised learning. They utilize an adversarial training process to generate new, realistic data. GANs involve two main components:
Generator Network (G): This network creates synthetic data that is indistinguishable from real data but resembles its distribution.
Discriminator Network (D): This network plays the role of a critic, distinguishing between genuine and synthesized data.
Entertainment and Media: In the film industry, GANs can be used to create realistic special effects or to generate new content for video games. They are also used in virtual reality to enhance the user experience by generating immersive environments.
Fashion and Design: GANs assist in generating new clothing designs or in simulating how clothes would look on bodies of different shapes without actual physical production.
Medical Imaging: They are used to generate medical images for training healthcare professionals without exposing patient data, thus adhering to privacy concerns.
Limitations
Training Difficulty: GANs are notoriously difficult to train. The balance between the generator and discriminator can be delicate; if either the generator or discriminator becomes too good too quickly, the other may fail to learn effectively.
Mode Collapse: A common issue where the generator starts producing a limited diversity of samples or even the same sample repeatedly, which can reduce the usefulness of the generated data.
Evaluation Challenges: Assessing the performance of GANs is non-trivial as it often requires subjective human judgment, which can be inconsistent and unreliable.
Overall, GANs have shown remarkable success in generating realistic, high-quality outputs across various domains. Despite their challenges in training and evaluation, their potential to revolutionize fields such as media, design, and medicine makes them a fascinating area of ongoing research and application.
Hence, from the basic Perceptron to the more complex CNNs and RNNs, each type serves a unique purpose and has contributed significantly to the technological advancements we witness today.
How to Choose from Different Types of Neural Networks?
When choosing a type of neural network, several factors must be considered to ensure the selected model aligns with the specific needs of your application or the problem being addressed. These factors include:
Depth and Complexity of the Problem
Simpler problems may be by shallow networks like Perceptrons, while more complex problems, involving image or speech recognition, might necessitate deeper networks, such as CNNs or RNNs.
Type of Input Data
The nature of the input data is crucial in selecting the appropriate neural network. For instance, CNNs are well-suited for grid-like data, while RNNs are useful for sequential data.
Computational Resources
The availability of computational resources is another important consideration as the choice of a neural network might be constrained by the hardware available, influencing the decision towards more resource-efficient models.
Learning Task
Different neural networks are optimized for different types of learning tasks. For example, FNNs are widely used for straightforward prediction and classification problems, whereas networks like LSTM are designed to excel in tasks that require an understanding of long-term dependencies in the data.
Data Availability
The amount and quality of available training data can influence the choice of neural networks. Deep learning models, in general, require large amounts of data to perform well. However, some models are more efficient in learning from limited data through techniques like transfer learning or data augmentation.
Hence, it is important to consider these factors when navigating through the different types of neural networks to ensure their architecture is utilized optimally.
What is the Future of Neural Networks?
The practicality of neural networks lies in their ability to process and learn from large sets of data, making them invaluable tools for solving complex problems that were once thought to be the exclusive domain of human intelligence.
Hence, the impact of neural networks on the future of industrial growth is not just promising; it is inevitable. Their continued development and integration into various sectors will undoubtedly lead to more efficient processes, groundbreaking discoveries, and a deeper understanding of the world around us.
The evolution of the GPT Series culminates in ChatGPT, delivering more intuitive and contextually aware conversations than ever before.
What are chatbots?
AI chatbots are smart computer programs that can process and understand users’ requests and queries in voice and text. It mimics and generates responses in a human conversational manner. AI chatbots are widely used today from personal assistance to customer service and much more. They are assisting humans in every field making the work more productive and creative.
Deep learning And NLP
Deep Learning and Natural Language Processing (NLP) are like best friends in the world of computers and language. Deep Learning is when computers use their brains, called neural networks, to learn lots of things from a ton of information.
NLP is all about teaching computers to understand and talk like humans. When Deep Learning and NLP work together, computers can understand what we say, translate languages, make chatbots, and even write sentences that sound like a person. This teamwork between Deep Learning and NLP helps computers and people talk to each other better in the most efficient manner.
Chatbots and ChatGPT
How are chatbots built?
Building Chatbots involves creating AI systems that employ deep learning techniques and natural language processing to simulate natural conversational behavior.
The machine learning models are trained on huge datasets to figure out and process the context and semantics of human language and produce relevant results accordingly. Through deep learning and NLP, the machine can recognize the patterns from text and generate useful responses.
Transformers in chatbots
Transformersare advanced models used in AI for understanding and generating language. This efficient neural network architecture was developed by Google in 2015. They consist of two parts: the encoder, which understands input text, and the decoder, which generates responses.
The encoder pays attention to words’ relationships, while the decoder uses this information to produce a coherent text. These models greatly enhance chatbots by allowing them to understand user messages (encoding) and create fitting replies (decoding).
With Transformers, chatbots engage in more contextually relevant and natural conversations, improving user interactions. This is achieved by efficiently tracking conversation history and generating meaningful responses, making chatbots more effective and lifelike.
GPT Series – Generative pre trained transformer
GPT is a large language model (LLM) which uses the architecture of Transformers. I was developed by OpenAI in 2018. GPT is pre-trained on a huge amount of text dataset. This means it learns patterns, grammar, and even some reasoning abilities from this data. Once trained, it can then be “fine-tuned” on specific tasks, like generating text, answering questions, or translating languages.
This process of fine-tuning comes under the concept oftransfer learning. The “generative” part means it can create new content, like writing paragraphs or stories, based on the patterns it learned during training. GPT has become widely used because of its ability to generate coherent and contextually relevant text, making it a valuable tool in a variety of applications such as content creation, chatbots, and more.
The advent of ChatGPT:
ChatGPT is a chatbot designed by OpenAI. It uses the “Generative Pre-Trained Transformer” (GPT) series to chat with the user analogously as people talk to each other. This chatbot quickly went viral because of its unique capability to learn complications of natural language and interactions and give responses accordingly.
ChatGPT is a powerful chatbot capable of producing relevant answers to questions, text summarization, drafting creative essays and stories, giving coded solutions, providing personal recommendations, and many other things. It attracted millions of users in a noticeably short period.
ChatGPT’s story is a journey of growth, starting with earlier versions in the GPT series. In this blog, we will explore how each version from the series of GPT has added something special to the way computers understand and use language and how GPT-3 serves as the foundation for ChatGPT’s innovative conversational abilities.
Chat GPT Series evolution
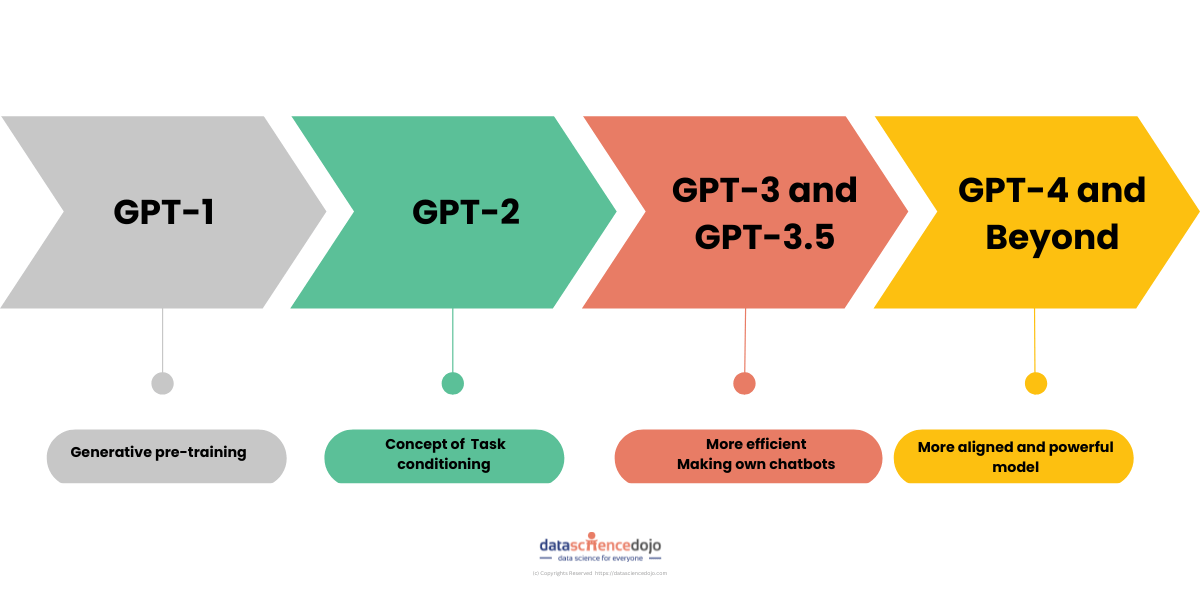
GPT-1:
GPT-1 was the first model of the GPT series developed by OpenAI. This innovative model demonstrated the concept that text can be generated using transformer design. GPT-1 introduced the concept of generative pre-training, where the model is first trained on a broad range of text data to develop a comprehensive understanding of language. It consisted of 117 million parameters and produced much more coherent results as compared to other models of its time. It was the foundation of the GPT series, and it paved a path for advancement and revolution in the domain of text generation.
GPT-2:
GPT-2 was much bigger as compared to GPT-1 trained on 1.5 billion parameters. It makes the model have a stronger grasp of the context and semantics of real-world language as compared to GPT-1. It introduces the concept of “Task conditioning.” This enables GTP-2 to learn multiple tasks within a single unsupervised model by conditioning its outputs on both input and task information.
GPT-2 highlighted zero-shot learning by carrying out tasks without prior examples, solely guided by task instructions. Moreover, it achieved remarkable zero-shot task transfer, demonstrating its capacity to seamlessly comprehend and execute tasks with minimal or no specific examples, highlighting its adaptability and versatile problem-solving capabilities.
As the ChatGPT model was getting more advanced it started to have new qualities of writing long creative essays, answering complex questions instead of just predicting the next word. So, it was becoming more human-like and attracted many users for their day-to-day tasks.
GPT-3:
GPT-3 was trained on an even larger dataset and has 175 billion parameters. It gives a more natural-looking response making the model conversational. It was better at common sense reasoning than the earlier models. GTP-3 can not only generate human-like text but is also capable of generating programming code snippets providing more innovative solutions.
GPT-3’s enhanced capacity, compared to GPT-2, extends its zero-shot and few-shot learning capabilities. It can give relevant and accurate solutions to uncommon problems, requiring training on minimal examples or even performing without prior training.
Instruct GPT:
An improved version of GPT-3 also known as InstructGPT(GPT-3.5) produces results that align with human expectations. It uses a “Human Feedback Model” to make the neural network respond in a way that is according to real-world expectations.
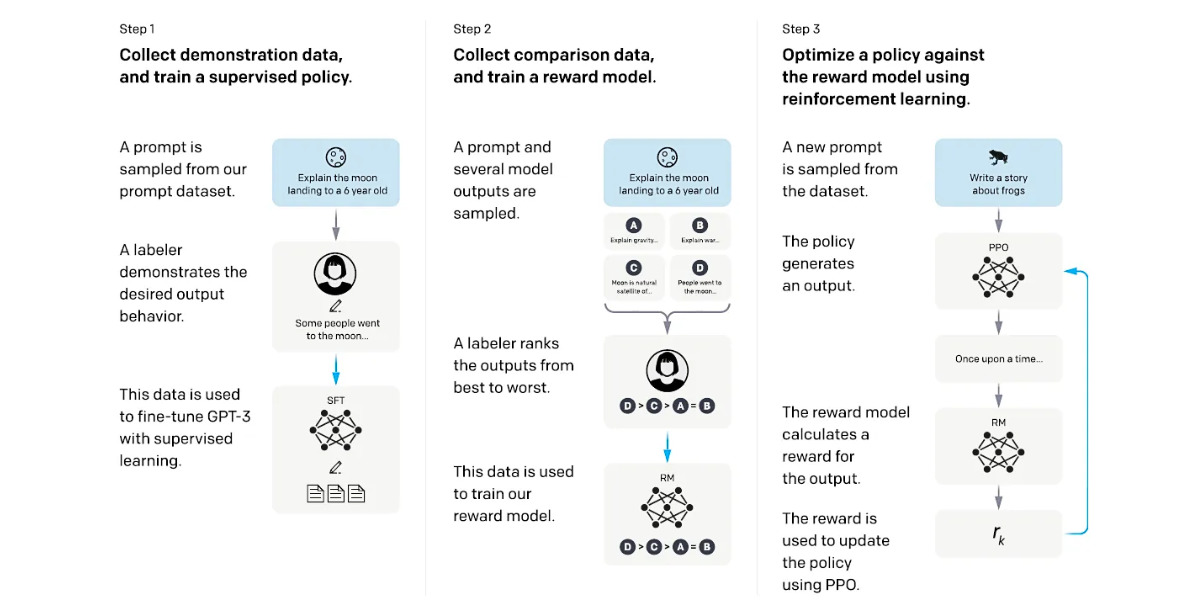
It begins by creating a supervised policy via demonstrations on input prompts. Comparison data is then collected to build a reward model based on human-preferred model outputs. This reward model guides the fine-tuning of the policy using Proximal Policy Optimization.
Iteratively, the process refines the policy by continuously collecting comparison data, training an updated reward model, and enhancing the policy’s performance. This iterative approach ensures that the model progressively adapts to preferences and optimizes its outputs to align with human expectations. The figure below gives a clearer depiction of the process discussed.
From Research paper ‘Training language models to follow instructions with human feedback’
GPT-3.5 stands as the default model for ChatGPT, while the GPT-3.5-Turbo Model empowers users to construct their own custom chatbots with similar abilities as ChatGPT. It is worth noting that large language models like ChatGPT occasionally generate responses that are inaccurate, impolite, or not helpful.
This is often due to their training in predicting subsequent words in sentences without always grasping the context. To remedy this, InstructGPT was devised to steer model responses toward better alignment with user preferences.
After GTP-3.5 comes GPT-4. According to some resources, GPT-4 is estimated to have 1.7 trillion parameters. These enormous number of parameters make the model more efficient and make it able to process up to 25000 words at once.
This means that GPT-4 can understand texts that are more complex and realistic. The model has multimodal capabilities which means it can process both images and text. It can not only interpret the images and label them but can also understand the context of images and give relevant suggestions and conclusions. The GPT-4 model is available in ChatGPT Plus, a premium version of ChatGPT.
So, after going through the developments that are currently done by OpenAI, we can expect that OpenAI will be making more improvements in the models in the coming years. Enabling it to handle voice commands, make changes to web apps according to user instruction, and aid people in the most efficient way that has never been done before.
This live presentation from Data Science Dojo gives more understanding of ChatGPT and its use cases. It demonstrates smart prompting techniques for ChatGPT to get the desired responses and ChatGPT’s ability to assist with tasks like data labeling and generating data for NLP models and applications. Additionally, the demo acknowledges the limitations of ChatGPT and explores potential strategies to overcome them.
Wrapping up:
ChatGPT developed by OpenAI is a powerful chatbot. It uses the GPT series as its neural network, which is improving quickly. From generating one-liner responses to generating multiple paragraphs with relevant information, and summarizing long detailed reports, the model is capable of interpreting and understanding visual inputs and generating responses that align with human expectations.
With more advancement, the GPT series is getting more grip on the structure and semantics of the human language. It not only relies on its training information but can also use real-time data given by the user to generate results. In the future, we expect to see more breakthrough advancements by OpenAI in this domain empowering this chatbot to assist us in the most effective manner like ever before.