

The GPT series has come a long way since its inception, significantly advancing the way artificial intelligence processes and generates language. Starting with the simpler GPT-1, each new version—GPT-2, GPT-3, and GPT-4—has demonstrated increasing sophistication and effectiveness in real-world tasks.
This blog takes a closer look at the progression of the GPT models, diving into the technical improvements, challenges faced, and how these developments have shaped the AI technology we use today. Let’s explore how each version has contributed to the broader field of natural language understanding and transformation.
What are Chatbots?
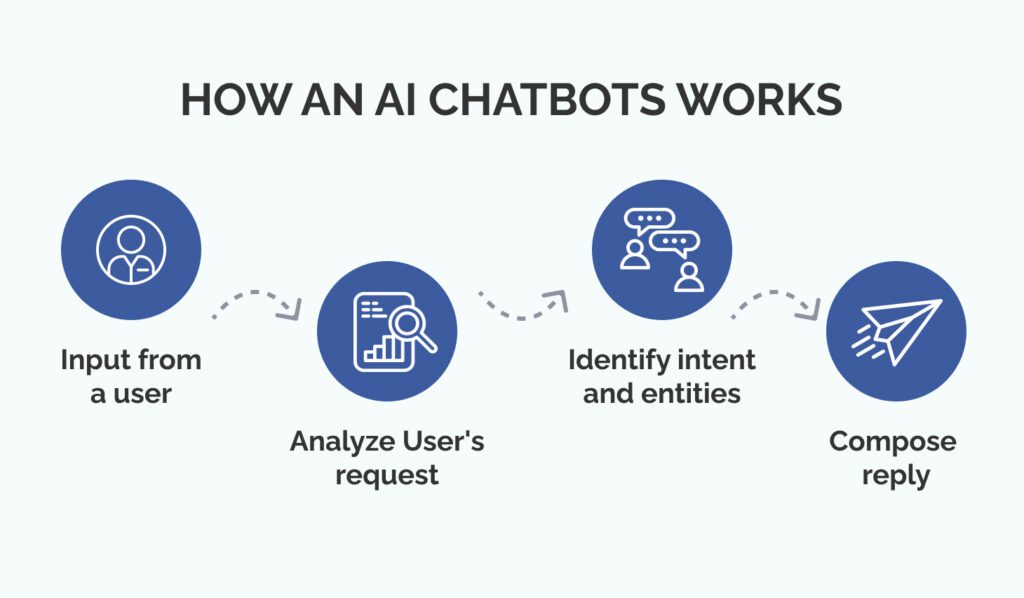
AI chatbots are smart computer programs that can process and understand users’ requests and queries in voice and text. It mimics and generates responses in a human conversational manner. AI chatbots are widely used today from personal assistance to customer service and much more. They are assisting humans in every field making the work more productive and creative.
Deep Learning And NLP
Deep Learning and Natural Language Processing (NLP) are like best friends in the world of computers and language. Deep Learning is when computers use their brains, called neural networks, to learn lots of things from a ton of information.
NLP is all about teaching computers to understand and talk like humans. When Deep Learning and NLP work together, computers can understand what we say, translate languages, make chatbots, and even write sentences that sound like a person. This teamwork between Deep Learning and NLP helps computers and people talk to each other better in the most efficient manner.

How are Chatbots Built?
Building Chatbots involves creating AI systems that employ deep learning techniques and natural language processing to simulate natural conversational behavior.
The machine learning models are trained on huge datasets to figure out and process the context and semantics of human language and produce relevant results accordingly. Through deep learning and NLP, the machine can recognize the patterns from text and generate useful responses.
Also learn how to create voice controlled python chatbot
Transformers in Chatbots
Transformers are advanced models used in AI for understanding and generating language. This efficient neural network architecture was developed by Google in 2015. They consist of two parts: the encoder, which understands input text, and the decoder, which generates responses.
The encoder pays attention to words’ relationships, while the decoder uses this information to produce a coherent text. These models greatly enhance chatbots by allowing them to understand user messages (encoding) and create fitting replies (decoding).
With Transformers, chatbots engage in more contextually relevant and natural conversations, improving user interactions. This is achieved by efficiently tracking conversation history and generating meaningful responses, making chatbots more effective and lifelike.
GPT Series – Generative Pre-Trained Transformer
GPT is a large language model (LLM) which uses the architecture of Transformers. I was developed by OpenAI in 2018. GPT is pre-trained on a huge amount of text dataset. This means it learns patterns, grammar, and even some reasoning abilities from this data. Once trained, it can then be “fine-tuned” on specific tasks, like generating text, answering questions, or translating languages.
This process of fine-tuning comes under the concept of transfer learning. The “generative” part means it can create new content, like writing paragraphs or stories, based on the patterns it learned during training. GPT has become widely used because of its ability to generate coherent and contextually relevant text, making it a valuable tool in a variety of applications such as content creation, chatbots, and more.
The Advent of ChatGPT:
ChatGPT is a chatbot designed by OpenAI. It uses the “Generative Pre-Trained Transformer” (GPT) series to chat with the user analogously as people talk to each other. This chatbot quickly went viral because of its unique capability to learn complications of natural language and interactions and give responses accordingly.
ChatGPT is a powerful chatbot capable of producing relevant answers to questions, text summarization, drafting creative essays and stories, giving coded solutions, providing personal recommendations, and many other things. It attracted millions of users in a noticeably short period.
ChatGPT’s story is a journey of growth, starting with earlier versions in the GPT series. In this blog, we will explore how each version from the series of GPT has added something special to the way computers understand and use language and how GPT-3 serves as the foundation for ChatGPT’s innovative conversational abilities.
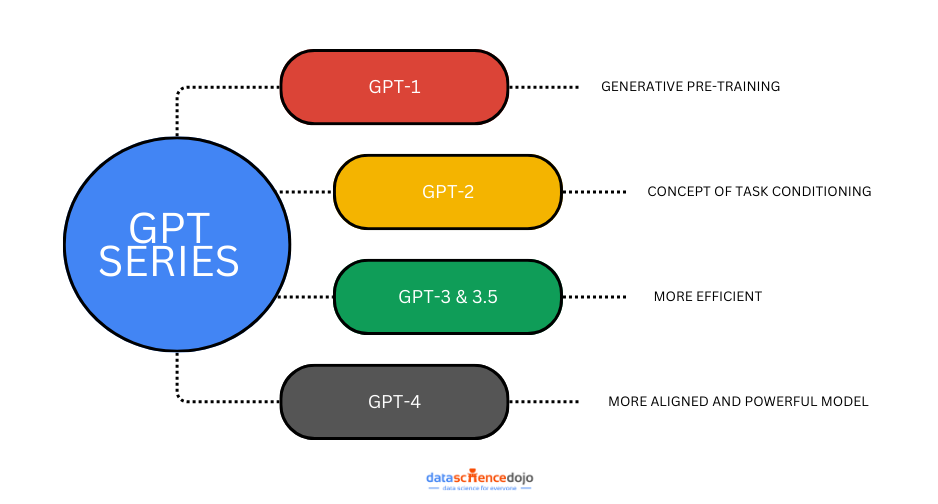
GPT-1:
GPT-1 was the first model of the GPT series developed by OpenAI. This innovative model demonstrated the concept that text can be generated using transformer design. GPT-1 introduced the concept of generative pre-training, where the model is first trained on a broad range of text data to develop a comprehensive understanding of language. It consisted of 117 million parameters and produced much more coherent results as compared to other models of its time. It was the foundation of the GPT series, and it paved a path for advancement and revolution in the domain of text generation.
GPT-2:
GPT-2 was much bigger as compared to GPT-1 trained on 1.5 billion parameters. It makes the model have a stronger grasp of the context and semantics of real-world language as compared to GPT-1. It introduces the concept of “Task conditioning.” This enables GPT-2 to learn multiple tasks within a single unsupervised model by conditioning its outputs on both input and task information.
GPT-2 highlighted zero-shot learning by carrying out tasks without prior examples, solely guided by task instructions. Moreover, it achieved remarkable zero-shot task transfer, demonstrating its capacity to seamlessly comprehend and execute tasks with minimal or no specific examples, highlighting its adaptability and versatile problem-solving capabilities.
As the ChatGPT model was getting more advanced it started to have new qualities of writing long creative essays, answering complex questions instead of just predicting the next word. So, it was becoming more human-like and attracted many users for their day-to-day tasks.

GPT-3:
GPT-3 was trained on an even larger dataset and has 175 billion parameters. It gives a more natural-looking response making the model conversational. It was better at common sense reasoning than the earlier models. GPT-3 can not only generate human-like text but is also capable of generating programming code snippets providing more innovative solutions.
GPT-3’s enhanced capacity, compared to GPT-2, extends its zero-shot and few-shot learning capabilities. It can give relevant and accurate solutions to uncommon problems, requiring training on minimal examples or even performing without prior training.
Instruct GPT:
An improved version of GPT-3 also known as InstructGPT (GPT-3.5) produces results that align with human expectations. It uses a “Human Feedback Model” to make the neural network respond in a way that is according to real-world expectations.
It begins by creating a supervised policy via demonstrations on input prompts. Comparison data is then collected to build a reward model based on human-preferred model outputs. This reward model guides the fine-tuning of the policy using Proximal Policy Optimization.
Iteratively, the process refines the policy by continuously collecting comparison data, training an updated reward model, and enhancing the policy’s performance. This iterative approach ensures that the model progressively adapts to preferences and optimizes its outputs to align with human expectations. The figure below gives a clearer depiction of the process discussed.
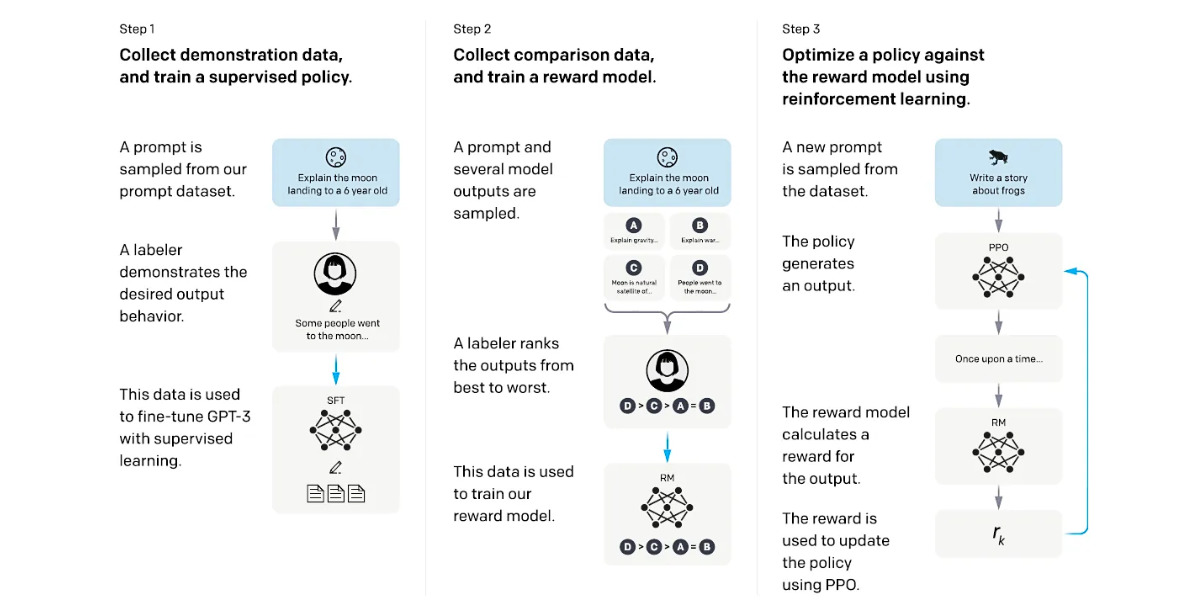
GPT-3.5 stands as the default model for ChatGPT, while the GPT-3.5-Turbo Model empowers users to construct their own custom chatbots with similar abilities as ChatGPT. It is worth noting that large language models like ChatGPT occasionally generate responses that are inaccurate, impolite, or not helpful.
This is often due to their training in predicting subsequent words in sentences without always grasping the context. To remedy this, InstructGPT was devised to steer model responses toward better alignment with user preferences.
Read more –> FraudGPT: Evolution of ChatGPT into an AI weapon for cybercriminals in 2023
GPT-4 and Beyond:
After GTP-3.5 comes GPT-4. According to some resources, GPT-4 is estimated to have 1.7 trillion parameters. These enormous number of parameters make the model more efficient and make it able to process up to 25000 words at once.
This means that GPT-4 can understand texts that are more complex and realistic. The model has multimodal capabilities which means it can process both images and text. It can not only interpret the images and label them but can also understand the context of images and give relevant suggestions and conclusions. The GPT-4 model is available in ChatGPT Plus, a premium version of ChatGPT.
So, after going through the developments that are currently done by OpenAI, we can expect that OpenAI will be making more improvements in the models in the coming years. Enabling it to handle voice commands, make changes to web apps according to user instruction, and aid people in the most efficient way that has never been done before.
Watch: ChatGPT Unleashed: Live Demo and Best Practices for NLP Applications
This live presentation from Data Science Dojo gives more understanding of ChatGPT and its use cases. It demonstrates smart prompting techniques for ChatGPT to get the desired responses and ChatGPT’s ability to assist with tasks like data labeling and generating data for NLP models and applications. Additionally, the demo acknowledges the limitations of ChatGPT and explores potential strategies to overcome them.
Wrapping Up:
ChatGPT developed by OpenAI is a powerful chatbot. It uses the GPT series as its neural network, which is improving quickly. From generating one-liner responses to generating multiple paragraphs with relevant information, and summarizing long detailed reports, the model is capable of interpreting and understanding visual inputs and generating responses that align with human expectations.
With more advancement, the GPT series is getting more grip on the structure and semantics of the human language. It not only relies on its training information but can also use real-time data given by the user to generate results. In the future, we expect to see more breakthrough advancements by OpenAI in this domain empowering this chatbot to assist us in the most effective manner like ever before.
