Simplify complex modern life with problem-solving tools. Digital tech created an abundance of tools, but a simple set can solve everything.
In last week’s post, DS-Dojo introduced our readers to this blog series’ three focus areas, namely:
1) software development
2) project management
3) data science.
This week, we continue that metaphorical (learning) journey with a fun fact. Better yet, a riddle. What do ALL jobs have in common?
One can (correctly) argue that essentially, all jobs require the worker in question to accomplish one basic or vital goal: solve (a) problem(s). Indeed, one can earnestly argue that the three interdisciplinary fields of this series (software development, project management, and data science) are iconic vis-a-vis their problem-solving characteristics.
Advanced problem-solving tools for a (post-) modern world
One of the paradoxes of our (post-)modern era is this fact: our lives have become so much easier, safer, and much more enjoyable, thanks to digital technology. And yet simultaneously, our lives have gotten so complicated, with an overwhelming glut of technological tools at our disposal.
And I suppose one can view this as a “rich person-problem,” akin to a kid in a candy store, indeed. In any case, here is the good news: “As luck would have it,” we can utilize a simple (set of) tool(s), with which we can both solve problems expansively and/or simplify our lives as needed.
To the rescue (!): Google, checklists, algorithms and data structures, and project management
Incidentally, a Google search using search terms related to the topic at hand suggests a consensus vis-a-vis best practices for solving problems, and/or simplifying our lives.
Ultimately, we can use two or three vital tools: 1) [either] a simple checklist, 2) [or,] the interdisciplinary field of project management, and 3) algorithms and data structures.
Here’s a fun question for you, dear reader: can you think of a tool that can simplify both simple and complex tasks such as i) grocery shopping, ii) surgery, and iii) safely flying an airplane? If you answered, “a checklist,” you’re correct.
But for more complicated problems, the interdisciplinary field of project management might be useful–i.e., via the 12 (project-management) elements introduced in last week’s post. To recap, those twelve elements (e.g. as defined by Belinda Goodrich, 2021) are:
Project life cycle,
Integration,
Scope,
Schedule,
Cost,
Quality,
Resources,
Communications,
Risk,
Procurement,
Stakeholders, and
Professional responsibility/ethics.
In addition to the mindful use of the above twelve elements, our Google search might reveal that various authors suggest some vital algorithms for data science. For instance, in the table below, we juxtapose four authors’ professional opinions with DS-Dojo’s curriculum.
What problem-solving tools next digital age have to offer
Thanks to Moore’s law (e.g., as described via the relevant Wikipedia article about Moore’s law and other factors, the digital age will keep producing hardware and software tools that are both wondrous and/or overwhelming (e.g., IoT, Web 3.0, metaverse, quantum-computing, etc.).
In this blog post, DS-Dojo provides a potential remedy to our readers vis-a-vis finding easier solutions to our world’s problems, and the avoidance of that “spoilt for choice” dilemma.
By using checklists and tools derived from the three interdisciplinary fields of this blog series, we can solve our world’s ever-growing/evolving problems, and/or simplify our lives as needed.
Here’s an analysis of Game of Thrones data to identify character importance, factions, and gender interactions using Network Theory and Python.
Game of Thrones is arguably one of the biggest pop culture phenomena to hit the public consciousness in the last decade. Since the hype for the final season’s arrival has gone down a bit, especially mine after episode three, I thought I could use this time to finally explore a side of Data Science that has always intrigued me – Network Theory and combine it with a topic I am very invested in – Game of Thrones. Just to be clear I won’t be making any claims or predictions about the plot of the show – No Spoilers. I just want to use Game of Thrones as a hopefully relatable context for discussing the analysis techniques.
At a high level, Network Theory is the study of relationships between objects, more specifically it is a subfield of Graph Theory with extra attributes attached to the nodes and edges. If you’re confused by these terms, don’t worry I’ll explain everything in a bit. For the rest, you might be familiar with graph theory and have not-so-fond memories associated with it but bear with me for a while. I first learned basic graph theory in my university’s algorithms course and, I’ll be honest, I found absolutely nothing of interest in the entire topic.
Sure, I could find the shortest path between two cities or find the best way to lay down routers in a computer network, but these topics never seemed fun to me. That is until I started exploring data science and joined a Data Science Bootcamp where I learned about a lot of things related to data including network analysis. That really opened my eyes to what the graph theory concepts were capable of. I encourage you to check out
video about exploring opposing factions and their effects on each other using graphs.
I will go about my exploration using two separate but related lines. The first will be a theoretical overview of each topic, and the second will be some implementation to see the concepts in action.
What is network theory?
Let’s get some basic definitions out of the way so everyone is on the same page and we can get to the fun bits.
Network Theory is the study of objects and their relationships with each other. This setup is often represented as a Graph which is just a collection of nodes and edges. Nodes are the individual objects in a network and Edges are the links representing the relationships between nodes.
Undirected, directed, and weighted graphs
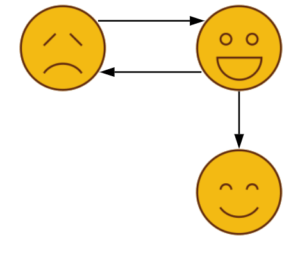
I want to clarify something right in the beginning, a graph is one model of a given situation or system, but that does not mean that the graph is the only model. What a node or edge represents is your choice (or informed by the data). In this case, I can determine that each node is a person and an edge between them means that they are friends with each other. This is called an Undirected Graph.
Now consider the same situation but I tell you that it is possible for a person to be friends with someone who’s not friends with them, a one-sided friendship. This changes the situation, and we need a different (more informative) model to represent it. Enter Directed Graphs:
This graph tells a completely different story from the first one. Now I will give you even more information, I tell you how much a person values their friendship with the other person. This means there is a notion of edges being heavier or more important than other edges. This is represented using a Weighted graph which can be either directed or undirected.
Getting our feet wet
I will be using Python to implement the algorithms since I’m more comfortable with it and while learning a new topic I don’t want to be bogged down by language specifics.
Starting with the data, it is available on Andrew Beveridge’s GitHub. He (in his own words) does maths for fun, which I feel is a very appropriate mindset for me too. The data contains records of character interactions for all seasons (up to 7). I am only using the latest season’s data but I encourage you to explore the temporal information in the dataset. You could even create animations to show how the data has changed over time.
Let’s discuss the packages I will be using briefly. Numpy, pandas, matplotlib (and seaborn) are the usual companions in any Data Science project. I also use the defaultdict data structure here.
The interesting stuff is in the last three lines. I will be using networks for the general purpose of graph handling, nxviz to do the heavy-lifting visualization tasks, and the community package used for one particular algorithm.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from collections import defaultdict
import networkx as nx
import nxviz as nxv
import community
A brief note about loading a graph dataset before we continue our exploration further. You might be familiar with common data formats like CSV or JSON which can be loaded as a data frame object using the pandas library. Graphs are a bit different in this regard since they’re usually saved as 2 separate files (one each for nodes and edges) which need to be loaded and combined into a graph object manually. The object is provided by the networkx library but the exact mechanics of constructing the graph will be different for each dataset. I’ve added my code here for you to see.
def make_graph(nodes_df, edges_df):
g = nx.Graph()
for i,row in nodes.iterrows():
keys = row.index.tolist()
values = row.values
# The dict contains all attributes
g.add_node(row['Id'], **dict(zip(keys,values)))
for i,row in edges.iterrows():
keys = row.index.tolist()
values = row.values
g.add_edge(row['Source'], row['Target'],
**dict(zip(keys,values)))
return g
nodes = pd.read_csv('data/got-s7-nodes_merged.csv', index_col=0)
edges = pd.read_csv('data/got-s7-edges-filtered.csv')
g = make_graph(nodes, edges)
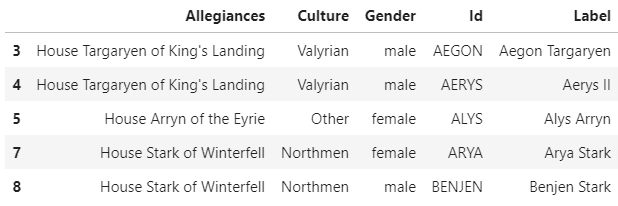
Now let’s get to know the dataset. The network we have is for interactions between the characters on the show. These interactions are set up using the fan-made script of the show, and details can be seen in the original source. I’ve modified the data a bit by adding categorical variables to the nodes (gender, allegiance, and culture). The nodes represent characters and have some attributes like their gender and house. The edges just have a ‘weight’ which is the number of interactions between the characters. You should always look at the original source of the data to understand how it was collected (remember this when you see interactions between characters who’ve never met in the show).
Each row describes a single character of the data
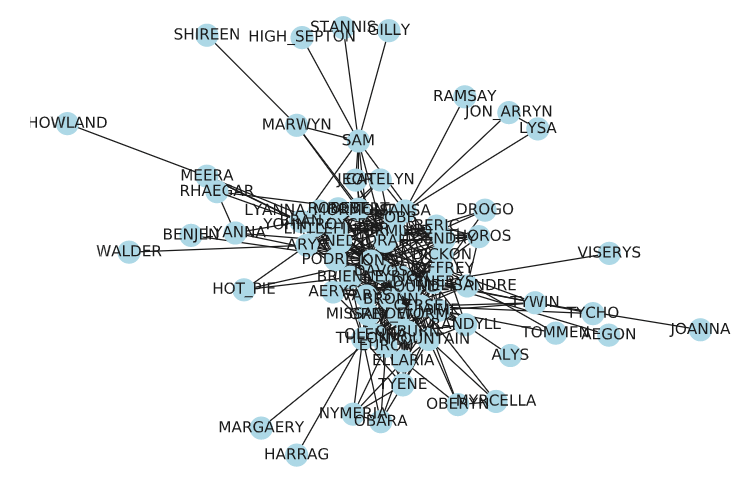
We previously saw a very simple graph visualization (the one with the emoji faces). It’s called a node-link diagram. It’s very easy to read and get an overview of the data, but it gets very unwieldy for slightly bigger networks. Let’s see how our data turns out:
nx.draw(g, with_labels=True)
Node link diagram representing a bigger network
As expected, the nodes are shown as a jumbled mess with too much overlap and absolutely no thought given to the arrangement. The locations of the individual nodes can be tweaked using the pos argument of the nx.draw function, but it is too much work to manually figure out the best arrangement.
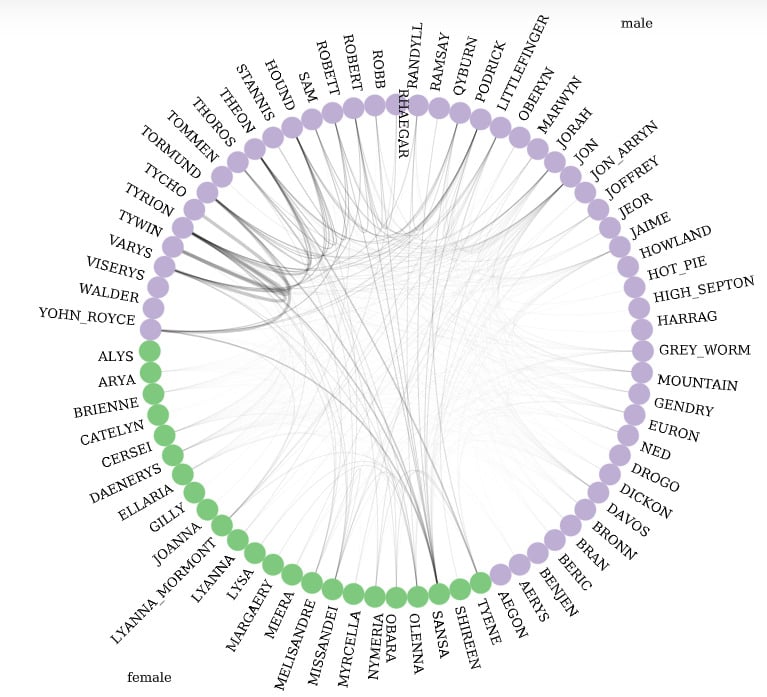
Circos Plot with a very simple library called nxviz
This plot has slightly less overall information (it shows fewer edges), but it is much easier to read. We can see patterns in the connectivity of different houses and the relative sizes of different houses.
Which gender has more interactions?
Let’s try to explore this data further. I want to see how males and females interact with each other. For this, we can create a transformed version of our original graph. Which kind of graph would be most suitable to represent this information? We know we have two genders, and we want to model relationships between them. This means we have two nodes. We have four possible kinds of interactions:
female -> female
male -> male
female -> male
male -> female
which means we will have 4 edges but note that these are directed edges and not undirected ones like in our original graph. So, I have created a weighted, directed graph with two nodes, one for each gender in the data.
The weights will be the sum of all interactions in the data for that pair. This means the weight of the female -> female edge will be the sum of weights for all edges in the original graph where the people on both ends were female.
I’ll introduce another useful graph concept here, the adjacency list. For a graph with nn nodes, this is an n×nn×n matrix where the entry at index (u,v)(u,v) contains the weight for the edge between nodes uu and vv. For an unweighted graph, this is a binary matrix, just containing 1 and 0, and is symmetric for undirected graphs (think about why this is).
I’ll plot this matrix as a heatmap and normalize the values because there are overall more males in the show’s cast.
counter = defaultdict(int)
for frm, to in g.edges:
link_type = g.nodes[frm]['Gender'],g.nodes[to]['Gender']
counter[link_type] += g.edges[(frm,to)]['Weight']
sg = nx.DiGraph()
for (frm,to),w in counter.items():
sg.add_edge(frm, to, weight=w)
sg.edges[('male', 'female')]
m = nx.to_numpy_matrix(sg, nodelist=sg.nodes)
sns.heatmap(m/m.sum(), annot=True,
xticklabels=list(sg.nodes), yticklabels=list(sg.nodes));
plt.gca().set_aspect('equal')
We can see that 45% of the interactions in the show happen between males and 33% happen between males and females. All in all, males are part of about 80% of all interactions in the show.
This might be a good time to remind you to keep in mind how an ‘interaction’ has been defined for this dataset.
Nevertheless, this result can be explained by the fact that the show is based in a Medieval setting of Kings, Lords, and Knights – all of whom used to be males. So, the results we have obtained make sense in the context of the show.
Which character is most important?
Now I want to find out who the most important characters are in the show. The condition for there being an edge between two nodes is that the two characters must have interacted, and the weight of the edge represents the number of interactions. It is reasonable to say that more important characters will have more interactions with various characters overall.
Intuitively, the more the weights of edges connected to a given node, the higher the node’s importance. So, to represent importance I can sum the weights of all edges a node has. This is called the Degree Centrality of the node, formally defined as the number of edges that are incident upon a node (for an undirected graph this is the same as the outgoing nodes). There are other measures of Centrality defined in graph theory, each is useful to identify different characteristics of a network.
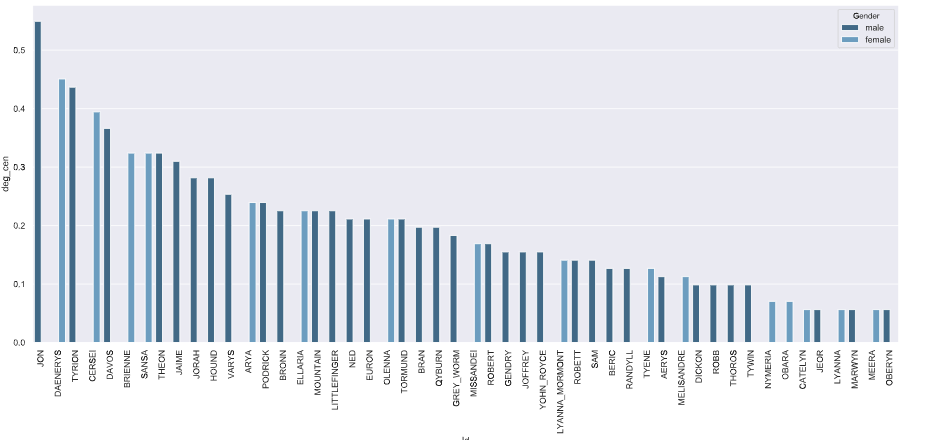
Let’s look at the trend of degree centrality measured in our data.
The trend of degree centrality measured in our data
Fans of the show should be able to immediately identify that the main characters are indeed in the lead here – Jon, Dany, Tyrion, Cersei, and Sansa make up for most of the screen time of the show.
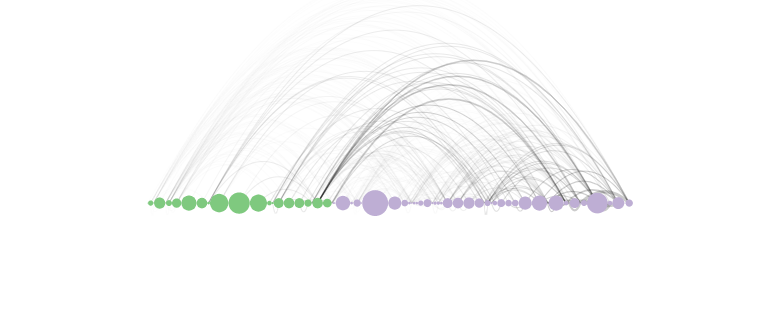
This is not the only way to visualize degree centrality. There is another type of plot, called Arc Plot which could be more informative. Let’s see:
a = nxv.ArcPlot(g, node_color='Gender', node_grouping='Gender',
node_size=[10*g.nodes[n]['deg_cen'] for n in g.nodes],
edge_width=(edges['Weight'] / edges['Weight'].quantile(.95)).tolist(),
figsize=(10,10))
a.draw()
Here the size of the node is based on the degree of centrality and the edge thickness is based on its weight. The nodes are also colored based on gender.
Which characters are in the same faction?
If you’ve seen or even heard about the show, you know that it features some serious political rivalries and factions. Is there a way to visualize these alliances? Can we draw some lines on a graph to indicate these alliances? Drawing these lines is known as Graph Partitioning.
Finding Graph Partitions is a very common task in graph theory. One very simple algorithm to achieve this is the min-cut method. A cut is a partition of the nodes of a graph into 2 disjoint sets. The weight of this cut (for weighted graphs only) is the sum of weights of all edges which cross the cut. This means that there will always be some cut of a graph that has the minimum weight.
So, the problem of finding the two factions in Game of Thrones now becomes a problem of finding the min-cut of the graph. We can extend this into a k-cut problem to find an arbitrary number of partitions.
While I will not be using the min-cut method to find partitions, I find the graph cut definition to be the most intuitive explanation for the process. The reason I use a different method is that the min-cut method does not generate good partitions for the Game of Thrones dataset.
The implementation I use comes from the community package in Python.
cmt = community.best_partition(g, weight='Weight')
nodes['cmt'] = [v for c,v in cmt.items()]
g = make_graph(nodes, edges)
c = nxv.CircosPlot(g, node_color='cmt', node_grouping='cmt',
node_labels=True, node_label_layout='rotation',
edge_width=(edges['Weight'] / edges['Weight'].quantile(0.98)).tolist(),
figsize=(8,8))
c.draw()
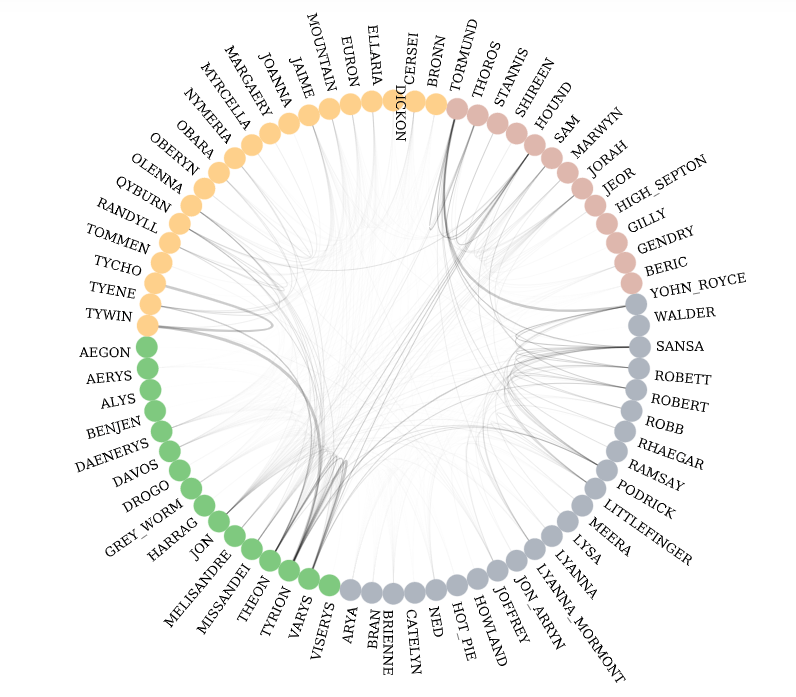
4 communities identified in Circos plot
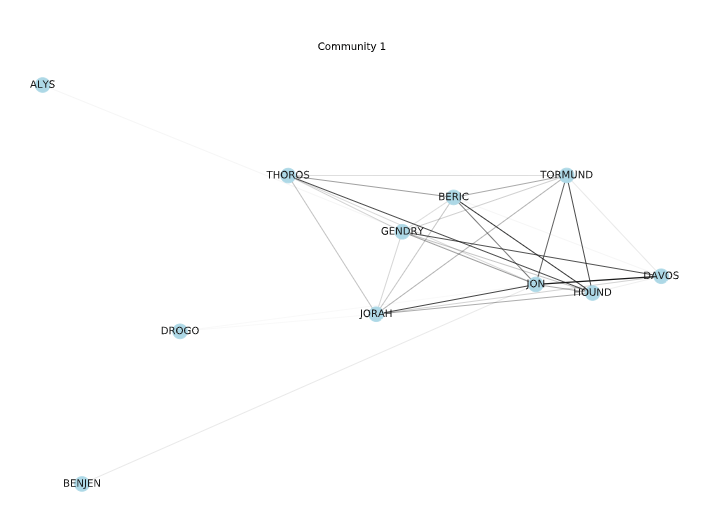
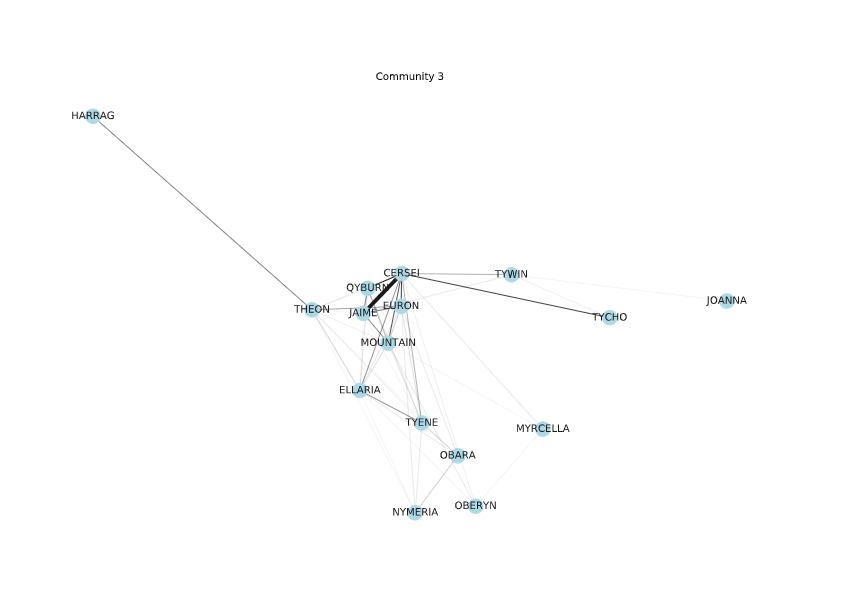
We have identified 4 communities. There are some interesting things we have extracted. All the Martells/Sands are in the same community (so is the Mountain ). The Starks are in the same community, except for Jon who is with Dany and Tyrion’s group. These groupings make sense if we think about the plot of the show. Jon has been with Dany’s group more than with the Starks.
Since we have split the graph into 4 partitions, maybe looking at the node-link diagrams for each partition separately isn’t such a bad idea anymore.
pos = nx.spring_layout(g) # compute graph layout
for cmt_num in np.unique([v for c,v in cmt.items()]):
partition = community.best_partition(g)
nodelist = []
# one community against the others
for node, c in partition.items():
if c == cmt_num:
nodelist.append(node)
else:
partition[node] = -1 # put all the other communities in one communitiy
sg = g.subgraph(nodelist)
edge_widths = [sg.edges[e]['Weight'] for e in sg.edges]
edge_widths = [w/np.quantile(edge_widths, 0.9) for w in edge_widths]
fig, ax = plt.subplots(figsize=(15,10))
nx.draw(sg, pos, with_labels=True, width=edge_widths)
ax.set_title(f'Community {cmt_num}');
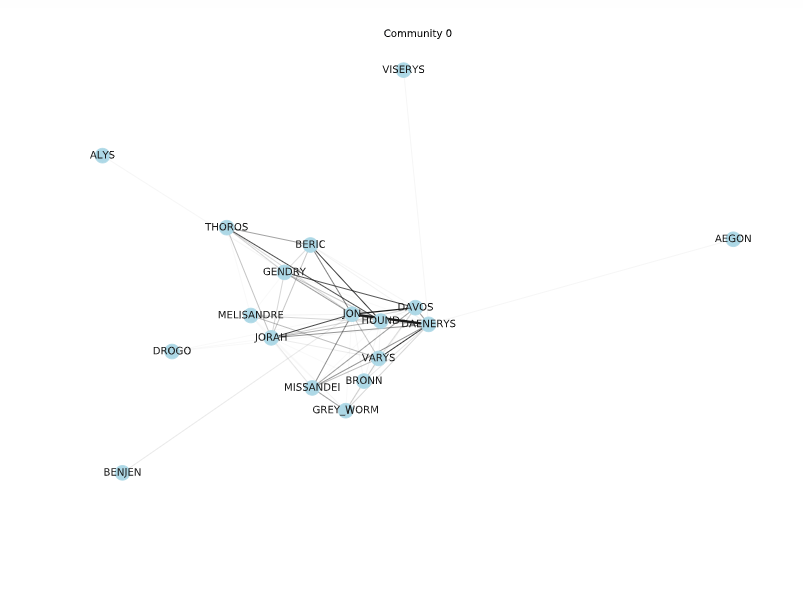
Node-link diagram of Community 0
Node-link diagram of Community 1
Node-link diagram of Community 2
Node-link diagram of Community 3
For these smaller sub-graphs, these diagrams are much easier to read. The edges are shaded based on their weight and for the first 3 communities, we can see a sort of central cluster connected with thick edges – basically supporting the rest of the nodes in the partition. The last community is less well-knit in this regard.
Like I said in the beginning, I just wanted to learn more about network analysis and share my exploration with you, and I think I succeeded in doing that. Do not consider the analysis or insights from this blog to be any kind of prediction. If you have some knowledge about the show, then you might have noticed that there were a few results that don’t exactly match the show’s storyline. A more thorough analysis is required to make any form of claims based on the data.
One of my inspirations to learn network analysis was a SciPy 2018 talk by Eric Ma and Mridul Seth, titles
.
It goes over the basics of the data structures and libraries along with a few slightly advanced topics in the end that I did not cover here.
I hope this blog has helped you learn some fundamental concepts of Network Theory. I am hoping you will use network theory in a project soon!




{kind=link}