Data Science Dojo is offering Apache Druid for FREE on Azure Marketplace packaged with a pre-configured web environment of Druid with support of various data sources.
What is data ingestion?
Data ingestion is the method involved with shipping information from at least one source to an objective site for additional handling and examination. This information can begin from a scope of sources, including data lakes, IoT gadgets, on-premises data sets, and other applications, and arrive in various environments, for example, cloud warehouse or our very own Druid data store.
OLAP
Online Analytical Processing (OLAP) is a method for quickly responding to multidimensional analytical questions in computing. OLAP frameworks are usually utilized in numerous BI and data science programs. It involves ingesting data in real-time, whether it’s streaming or in batches, for drawing analytics. OLAP systems usually maintain a data warehouse having redundancy along with maintaining time-series of datasets. They require customized queries to be computed at fast speeds.
Pro Tip: Join our 6-months instructor-led Data Science Bootcamp to master data science & engineering
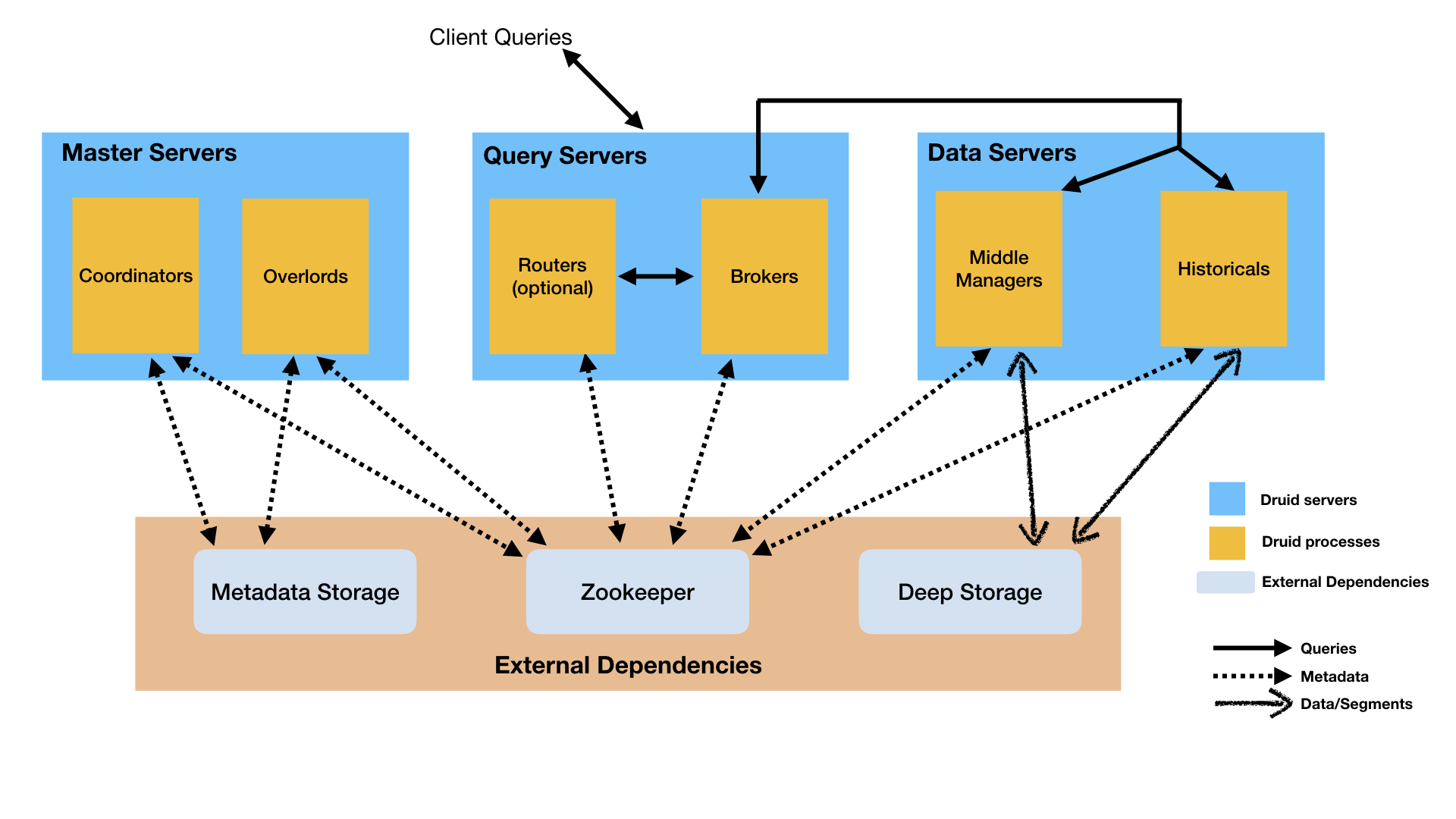
Backend services of Apache Druid
- Middle Manager: This process is responsible for ingesting the data
- Broker: This process is responsible for retrieving queries from external clients
- Coordinator: It assigns segments to specific nodes
- Overlord: It assigns ingestion tasks to middle managers
- Historical: It handles the storage and querying of data
- Router: Optional component to provide single API gateway for coordinators, overlords and brokers
Obstacles for data engineers & developers
Collection and maintenance of data from different sources was a hectic task for data engineers and developers. The organization of schema and its monitoring was another challenge in case of huge data. The requirement to response efficiently to complex OLAP queries and any sort of quick calculation was a nightmare.
In this scenario, a unified environment to deal with the ad-hoc queries, management of different data sets, keeping the time-series of data and quick data ingestions from various sources all from one place would be enough to tackle the mentioned challenges.
Methodology of Apache Druid
Apache Druid is an interactive real-time database backend environment for ingesting, maintaining, and segmenting data from a variety of sources either streaming or in batches, thus making it flexible. It is a scalable distributed system with parallel processing for queries and has a column-based structure for storing datasets, indicating the properties of each ingestion.
Druid stores the data safely in deep storage and provides indexing and time-based partitioning for faster filtering and searching performance. Users can query the ingested datasets with Druid’s optimized SQL engine. It also provides automatic summarization and algorithmic approximation of data.
Major features
- Apache Druid has a fast and optimized user interface. Druid UI makes it easy to supervise, refresh and troubleshoot your datasets. The column-oriented organization provides ease of control to the users
- Any ingested data can be subjected to queries with the help of an in-browser SQL editor. It delivers the results with low latency
- It is an open-source tool. Developers, data engineers, DevOps, companies focusing on web and mobile analytics, solutions architects who want to monitor network performance, and anyone interested in data science can use this offer
- Druid provides the feature of maintaining logs of each activity. In case of failure of any operation, the logs are updated, and the user can check them on the same web server
- You can monitor the status of your datasets oriented in a column via the web server
What does Data Science Dojo provide?
Apache Druid instance packaged by Data Science Dojo serves as a pre-configured data store for managing and monitoring ingested data along with SQL support to query data without the burden of installation. It offers efficient storage, quick sifting on dimensions of data, and querying of data at a sub-second normal reaction time. It supports a variety of data sources to ingest data from.
Features included in this offer:
- A Druid service that is easily accessible from the web, having a rich user interface
- Easy to operate and user friendly
- In-browser SQL coding environment to query ingested data sets
- Low latency automated data aggregations and approximations using algorithms
- Quick responsiveness and high uptime
- Time-based data partitioning
- Feature of schema configuration and data tuning at the time of ingestion
Our instance of Apache Druid supports the following data sources:
- Apache Kafka
- HDFS
- HTTP(s)
- Local disk
- Azure Event Hub
- Paste Data
- Other custom sources
By specifying credentials and adding extensions you can also ingest from :
- Azure Data Lake
- Google Cloud Storage
- Amazon S3 & Kinesis
Conclusion
Apache Druid is majorly used for OLAP systems because of its time series data ingestion, and the way the services perform indexing, and response to queries in real-time. It has a flexible and fault-tolerant architecture. When coupled with Microsoft cloud services, responsiveness and processing speed outperform their traditional counterparts because data-intensive computations aren’t performed locally, but in the cloud.
Install the Apache Druid offer now from the Azure Marketplace by Data Science Dojo, your ideal companion in your journey to learn data science!
Click on the button below to head over to the Azure Marketplace and deploy Apache Druid for FREE by clicking on “Try now”.

Note: You’ll have to sign up to Azure, for free, if you do not have an existing account.