Understanding the AI Integration Problem
When ChatGPT launched on November 30, 2022, it took just five days to reach one million users and two months to hit 100 million. This wasn’t just another software launch. It marked the beginning of a fundamental shift in how we work with technology.
Since then, we’ve witnessed three distinct waves of AI adoption. First came the wave of pure wonder, where people asked AI to explain quantum physics from a cat’s perspective or write Shakespearean songs about pizza. Then professionals discovered practical applications. Lawyers summarizing contracts, developers debugging code, teachers creating lesson plans. Finally, the API revolution arrived, embedding AI into our everyday tools like Microsoft Office, Google Workspace, and spawning new AI-first applications like Cursor and Perplexity.
But this rapid adoption created an unexpected problem: fragmentation.
The Fragmentation Problem
Today’s knowledge workers find themselves living in multiple AI worlds. The AI assistant in Notion can’t communicate with the one in Slack. Your VS Code coding assistant has no awareness of conversations happening in Microsoft Teams. You’re constantly juggling between different AI tools, each operating in its own isolated bubble.
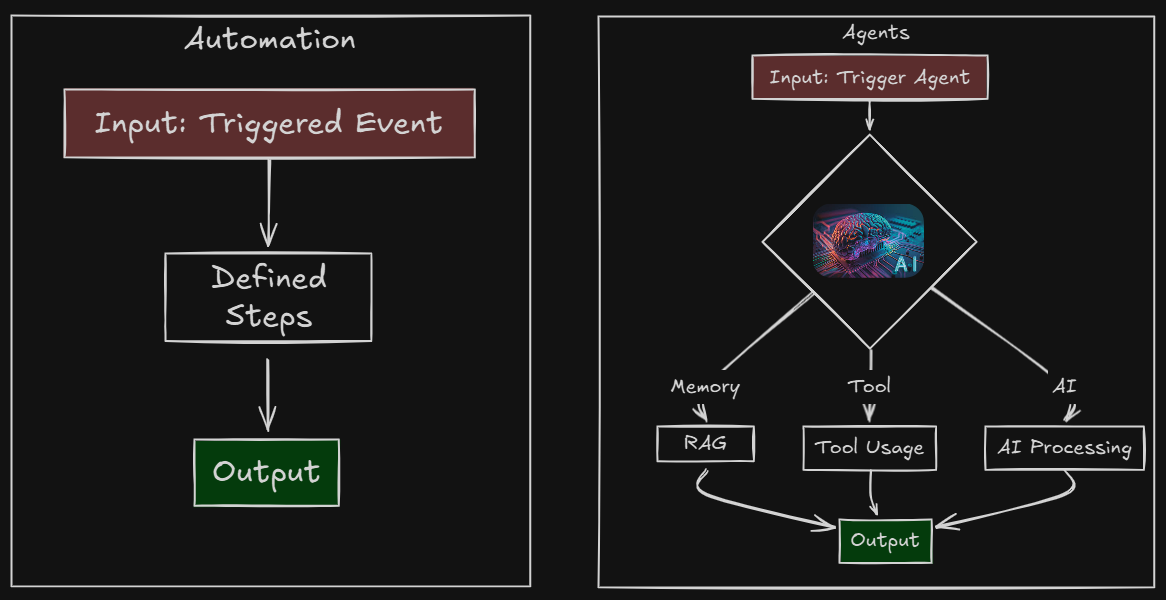
Users never wanted five different AI assistants. They wanted one unified AI partner that understands their entire work context and can solve any problem seamlessly. But building such a unified system faces a fundamental challenge: the problem of context.
What Is Context?
Context is everything an AI can “see” when it generates a response. More formally, context refers to the information such as conversation history, external documents, or system state that an LLM uses to generate meaningful responses. When you chat with ChatGPT, the past messages form the context.
For software engineers, this creates what I call “copy-paste hell.” Need to ask a simple question about your codebase? You’re pasting thousands of lines of code. Developers have essentially become human APIs, spending more time assembling context than actually developing. The context assembly time exceeds the development time itself.
The Evolution: From Function Calling to Model Context Protocol
Function Calling: The First Solution
In mid-2023, OpenAI introduced function calling, a way for LLMs to interact with external functions and tools. This was revolutionary. Instead of just generating text, AI could now take actions: query databases, send emails, fetch weather data, or interact with APIs.
This gave rise to the concept of “tools” in AI systems. Suddenly, AI assistants could do more than just chat. They could accomplish real tasks.
The Integration Nightmare
But function calling created a new problem: the N×M integration problem.
Every AI tool was building its own way to call every API. If you had N AI applications and M services, you needed N×M separate integrations. Each integration came with:
- Different authentication methods
- Different data formats and API patterns
- Different error handling mechanisms
- Ongoing maintenance overhead
- Security fragmentation
- Massive cost and time wastage
Imagine GitHub building separate integrations for Claude, ChatGPT, Copilot, Gemini, and every other AI tool. Then Google Drive doing the same. Then Slack, Notion, and hundreds of other services. The complexity was unsustainable.
Enter Model Context Protocol (MCP): The Elegant Solution
This is where Model Context Protocol (MCP) comes in.
Instead of every AI tool building integrations with every service, Model Context Protocol introduces a standardized protocol. GitHub builds one MCP server that any AI tool can connect to. Google Drive builds one MCP server. Slack builds one MCP server.
Now the equation changes from N×M to N+M integrations. A massive reduction in complexity.
The network effects are powerful: More AI chatbots supporting Model Context Protocol makes it more valuable for services to build MCP servers. More MCP servers available makes it more valuable for AI tools to support MCP. More adoption leads to more standardization, which creates more ecosystem value. Not supporting MCP means being cut off from a rapidly growing ecosystem.
Explore how LLM-agents convert language models into action-capable tools and why that matters.
Understanding Model Context Protocol (MCP) Architecture
The Simplest Version
At its core, MCP has three components:
- Host/Client: The AI application (like Claude Desktop, ChatGPT, or a custom AI assistant)
- MCP Server: A program that provides access to specific services or data
- Communication Protocol: The standardized way they talk to each other
Here’s a simple example: You ask Claude, “Are there any new commits on the GitHub repo?” Claude (the Host) sends a request to the GitHub MCP Server, which fetches the information and sends it back.
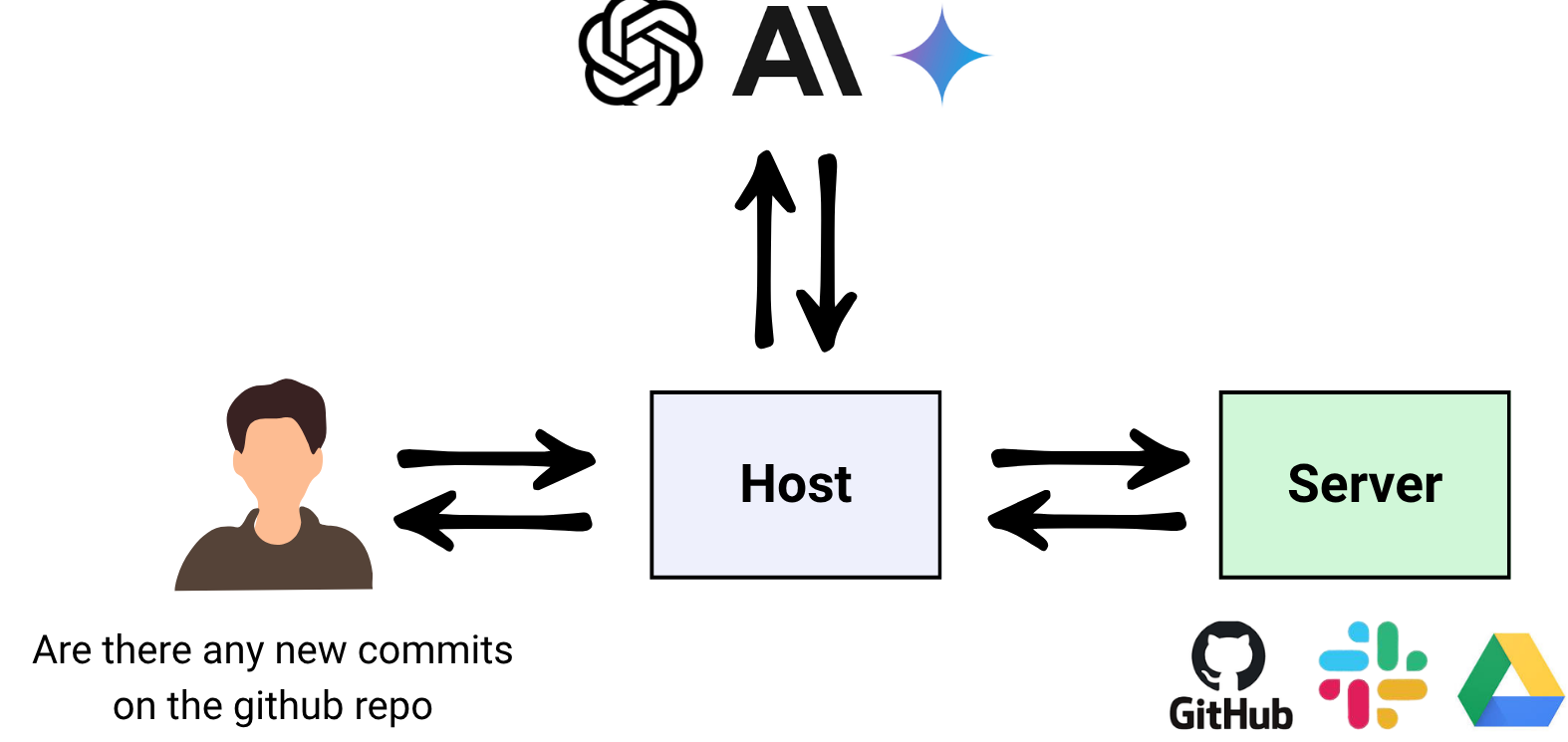
Key Benefits of This Architecture
- Decoupling: The Host doesn’t need to know how GitHub’s API works. The MCP Server handles all the complexity.
- Safety: The Server can implement security controls, rate limiting, and access policies independent of the Host.
- Scalability: Multiple Hosts can connect to the same Server without modification.
- Parallelism: Hosts can query multiple Servers simultaneously.
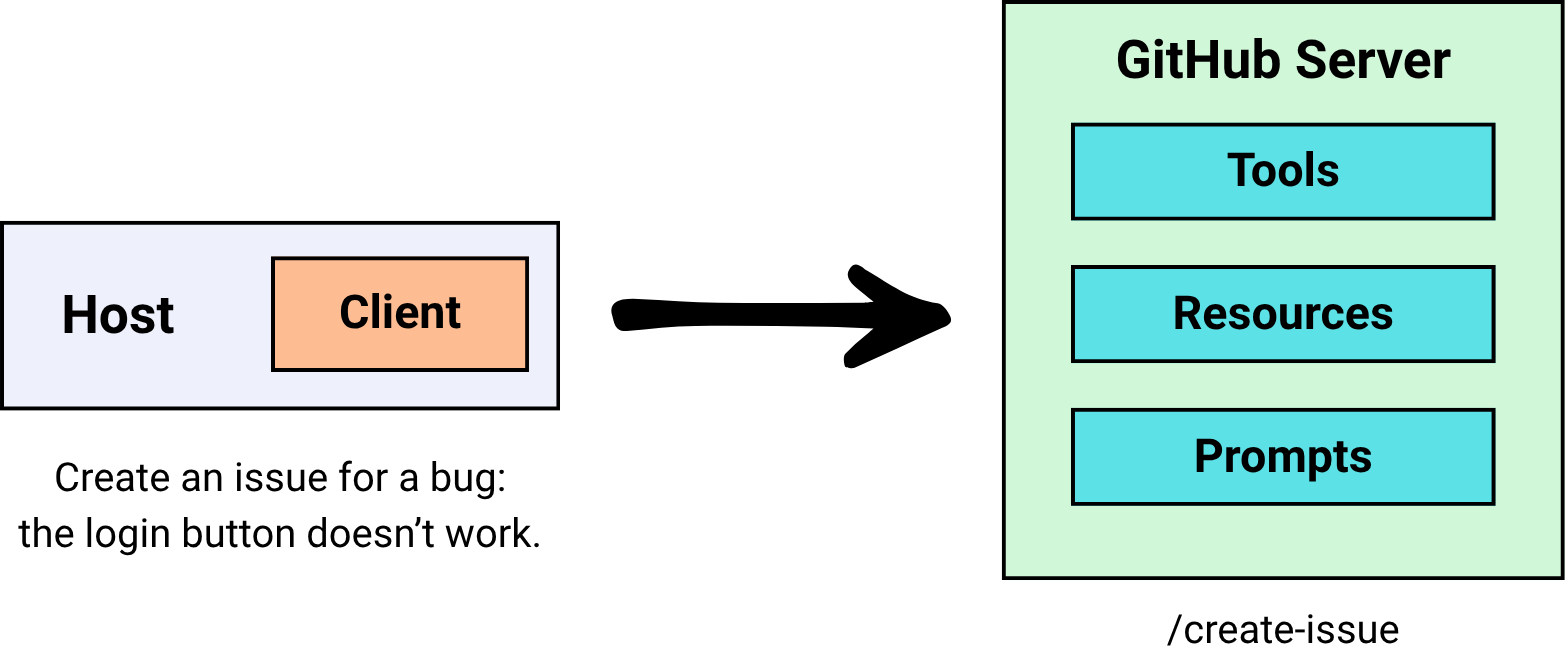
Model Context Protocol (MCP) Primitives: The Building Blocks
Model Context Protocol defines three core primitives, things a server can offer to a host:
1. Tools
Tools are actions the AI can ask the server to perform. Think of them as functions the AI can call.
Examples:
- create_github_issue: Create a new issue in a repository
- send_email: Send an email through Gmail
- search_documents: Search through Google Drive files
2. Resources
Resources are structured data sources that the AI can read. These provide context without requiring active queries.
Examples:
- Current contents of a file
- List of recent commits
- Database schema
- User profile information
3. Prompts
Prompts are predefined templates or instructions that help shape the AI’s behavior for specific tasks.
For example, instead of the user saying, “Create an issue for a bug: the login button doesn’t work” (which is too vague), an MCP Server can provide a structured prompt template:
This ensures consistency and quality in how the AI formulates requests.
The Data Layer: JSON-RPC 2.0
The data layer is the language and grammar that everyone in the Model Context Protocol ecosystem agrees upon to communicate. MCP uses JSON-RPC 2.0 as its foundation.
What Is JSON-RPC?
JSON-RPC stands for JavaScript Object Notation – Remote Procedure Call. An RPC allows a program to execute a function on another computer as if it were local, hiding the complexity of network communication. Instead of writing add(2, 3) locally, you send a request to a server saying “please run add with parameters 2 and 3.”
JSON-RPC combines remote procedure calls with the simplicity of JSON, creating a standardized format for requests and responses.
Why JSON-RPC for Model Context Protocol?
- Bi-directional communication: Both client and server can initiate requests
- Transport-agnostic: Works over different connection types
- Supports batching: Multiple requests in one message
- Supports notifications: One-way messages that don’t require responses
- Lightweight: Minimal overhead
Request Structure
Response Structure
The Transport Layer: Moving Messages
The transport layer is the mechanism that physically moves JSON-RPC messages between the client and server. Model Context Protocol supports two main types of servers, each with its own transport:
Local Servers: STDIO
STDIO (Standard Input/Output) is used for servers running on your own computer.
Every program has built-in streams:
- stdin: Input the program reads
- stdout: Output the program writes
In Model Context Protocol, the host launches the server as a subprocess and uses these streams for communication. The host writes JSON-RPC messages to the server’s stdin, and the server writes responses to its stdout.
Benefits:
- Fast: Data passes directly between processes
- Secure: No open network ports; communication is only local
- Simple: Every language supports stdin/stdout; no extra libraries required
Remote Servers: HTTP + SSE
For servers running elsewhere on the network, Model Context Protocol uses HTTP with Server-Sent Events (SSE).
The host sends JSON-RPC requests as HTTP POST requests with JSON payloads. The transport supports standard HTTP authentication methods like API keys.
SSE extends HTTP to allow the server to send multiple messages to the client over a single open connection. Instead of one large JSON blob, the server can stream chunks of data as they become available. This is ideal for long-running tasks or incremental updates.
The Model Context Protocol Lifecycle
The Model Context Protocol lifecycle describes the complete sequence of steps governing how a host and server establish, use, and end a connection.
Phase 1: Initialization
Initialization must be the first interaction between client and server. Its purpose is to establish protocol version compatibility and exchange capabilities.
Step 1 – Client Initialize Request: The client sends an initialize request containing its implementation info, MCP protocol version, and capabilities.
Step 2 – Server Response: The server responds with its own implementation info, protocol version, and capabilities.
Step 3 – Initialized Notification: After successful initialization, the client must send an initialized notification to indicate it’s ready for normal operations.
Important Rules:
- The client should not send requests (except pings) before the server responds to initialization
- The server should not send requests (except pings and logging) before receiving the initialized notification
Version Negotiation
Both sides declare which protocol versions they support. They then agree to use the highest mutually supported version. If no common version exists, the connection fails immediately.
Capability Negotiation
Client and server capabilities establish which protocol features will be available during the session. Each side declares what it can do, and only mutually supported features can be used.
For example, if a client doesn’t declare support for prompts, the server won’t offer any prompt templates.
Phase 2: Operation
During the operation phase, the client and server exchange messages according to negotiated capabilities.
Capability Discovery: The client can ask “what tools do you have?” or “what resources can you provide?”
Tool Calling: The client can invoke tools, and the server executes them and returns results.
Throughout this phase, both sides must respect the negotiated protocol version and only use capabilities that were successfully negotiated.
Discover key design patterns behind AI agents built on LLMs and learn how to apply them effectively.
Phase 3: Shutdown
One side (typically the client) initiates shutdown. No special JSON-RPC shutdown message is defined—the transport layer signals termination.
For STDIO: The client closes the input stream to the server process, waits for the server to exit, and sends termination signals (SIGTERM, then SIGKILL if necessary) if the server doesn’t exit gracefully.
For HTTP: The client closes HTTP connections, or the server may close from its side. The client must detect dropped connections and handle them appropriately.
Special Cases in MCP
1. Pings
Ping is a lightweight request/response method to check whether the other side is still alive and the connection is responsive.
When is it used?
- Before full initialization to check if the other side is up
- Periodically during inactivity to maintain the connection
- To prevent connections from being dropped by the OS, proxies, or firewalls
2. Error Handling
MCP inherits JSON-RPC’s standard error object format.
Common causes of errors:
- Unsupported or mismatched protocol version
- Calling a method for a capability that wasn’t negotiated
- Invalid arguments to a tool
- Internal server failure during processing
- Timeout exceeded leading to request cancellation
- Malformed JSON-RPC messages
Error Object Structure:
3. Timeout and Cancellation
Timeouts protect against unresponsive servers and ensure resources aren’t held indefinitely.
The client sets a per-request timeout (for example, 30 seconds). If the deadline passes with no result, the client triggers a timeout and sends a cancellation notification to tell the server to stop processing.
4. Progress Notifications
For long-running requests, the server can send progress updates to let the client know work is continuing.
The client includes a progressToken in the request metadata. The server then sends progress notifications while working, keeping the user informed instead of leaving them wondering if anything is happening.
Getting Started with Model Context Protocol
Using Claude Desktop
The easiest way to experience Model Context Protocol is through Claude Desktop, which has built-in support for MCP servers.
There are two types of connections you can set up:
- Local Servers: Configure MCP servers that run on your machine using a configuration file. These use STDIO transport and are perfect for accessing local resources, development tools, or services that require local execution.
- Remote Servers: Connect to MCP servers hosted elsewhere using HTTP/SSE transport. These are ideal for cloud services and APIs.
Configuration vs. Connectors
Configuration File Method: You manually edit a configuration file to specify which MCP servers Claude should connect to. This gives you complete control and allows you to use any MCP server, whether it’s official or community-built.
Connectors: Built-in features that link Claude to MCP servers automatically, without manual setup. Think of Connectors as the “App Store” for MCP servers—user-friendly, click-based, and pre-curated.
Connectors are officially built, hosted, and maintained by Anthropic. They come with OAuth login flows, managed security, rate limits, and guaranteed stability. Most Claude Desktop users are non-technical end-users who just want Claude to “talk” to their apps (Notion, Google Drive, GitHub, Slack) without running servers or editing JSON.
Why Not Use Connectors Always?
Model Context Protocol is an open standard designed so anyone can write a server. If every MCP server were required to be a Connector, Anthropic would need to review, host, and secure every possible server. This approach does not scale.
Forcing everything through Connectors would close the ecosystem and create dependency on Anthropic to approve or publish servers. The configuration file method keeps Model Context Protocol truly open while Connectors provide convenience for mainstream users.
Building Your Own MCP Server
The beauty of Model Context Protocol is that anyone can build a server. Anthropic provides SDKs for both clients and servers, making development straightforward.
Key considerations when building a server:
- Choose your primitives: Will you expose tools, resources, prompts, or a combination?
- Implement security: Add authentication, rate limiting, and access controls
- Handle errors gracefully: Provide clear error messages and proper status codes
- Support the lifecycle: Properly implement initialization, operation, and shutdown phases
- Document you capabilities: Make it clear what your server can do
Explore the internal mechanics of LLMs so you can better understand what agents are building on.
The Future of Model Context Protocol
Model Context Protocol represents a fundamental shift in how AI systems integrate with the digital world. Instead of every AI tool building its own integrations with every service, we now have a standardized protocol that dramatically reduces complexity.
The network effects are already building momentum. As more AI platforms support Model Context Protocol and more services build MCP servers, the ecosystem becomes increasingly valuable for everyone. Organizations that don’t support Model Context Protocol risk being left out of this growing interconnected AI ecosystem.
For developers, Model Context Protocol opens up possibilities to create servers that work across all MCP-compatible AI platforms. For users, it means AI assistants that can seamlessly access and interact with all your tools and services through a unified interface.
We’re moving from a world of fragmented AI assistants to one where AI truly understands your entire work context, not because it’s been trained on your data, but because it can dynamically access what it needs through standardized, secure protocols.
Conclusion
Model Context Protocol solves one of the most pressing challenges in the AI era: enabling AI systems to access the context they need without creating an integration nightmare.
By understanding Model Context Protocol’s architecture, from its primitives and data layer to its transport mechanisms and lifecycle, you’re now equipped to both use existing MCP servers and build your own. Whether you’re a developer creating integrations, a business leader evaluating AI tools, or a power user wanting to maximize your AI assistant’s capabilities, Model Context Protocol is the standard that will shape how AI systems connect to the world.
The age of fragmented AI tools is ending. The age of unified, context-aware AI assistance is just beginning.
Ready to build the next generation of agentic AI?
Explore our Large Language Models Bootcamp and Agentic AI Bootcamp for hands-on learning and expert guidance.