Large language models (LLMs) have taken the world by storm with their ability to understand and generate human-like text. These AI marvels can analyze massive amounts of data, answer your questions in comprehensive detail, and even create different creative text formats, like poems, code, scripts, musical pieces, emails, letters, etc.
It’s like having a conversation with a computer that feels almost like talking to a real person!
However, LLMs on their own exist within a self-contained world of text. They can’t directly interact with external systems or perform actions in the real world. This is where LLM agents come in and play a transformative role.

LLM agents act as powerful intermediaries, bridging the gap between the LLM’s internal world and the vast external world of data and applications. They essentially empower LLMs to become more versatile and take action on their behalf. Think of an LLM agent as a personal assistant for your LLM, fetching information and completing tasks based on your instructions.
For instance, you might ask an LLM, “What are the next available flights to New York from Toronto?” The LLM can access and process information but cannot directly search the web – it is reliant on its training data.
An LLM agent can step in, retrieve the data from a website, and provide the available list of flights to the LLM. The LLM can then present you with the answer in a clear and concise way.
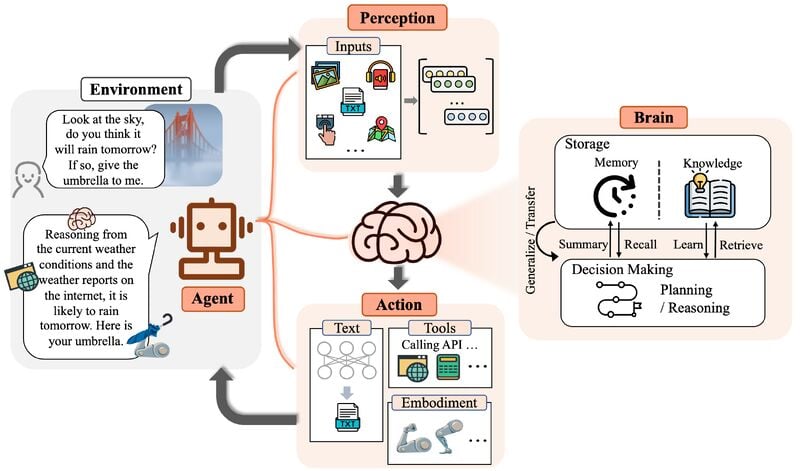
By combining LLMs with agents, we unlock a new level of capability and versatility. In the following sections, we’ll dive deeper into the benefits of using LLM agents and explore how they are revolutionizing various applications.
Benefits and Use Cases of LLM Agents
Let’s explore in detail the transformative benefits of LLM agents and how they empower LLMs to become even more powerful.
Enhanced Functionality: Beyond Text Processing
LLMs excel at understanding and manipulating text, but they lack the ability to directly access and interact with external systems. An LLM agent bridges this gap by allowing the LLM to leverage external tools and data sources.
You might also want to look at: Text Analytics
Imagine you ask an LLM, “What is the weather forecast for Seattle this weekend?” The LLM can understand the question but cannot directly access weather data. An LLM agent can step in, retrieve the forecast from a weather API, and provide the LLM with the information it needs to respond accurately.
This empowers LLMs to perform tasks that were previously impossible, like:
- Accessing and processing data from databases and APIs
- Executing code
- Interacting with web services
Increased Versatility: A Wider Range of Applications
By unlocking the ability to interact with the external world, LLM agents significantly expand the range of applications for LLMs. Here are just a few examples:
- Data Analysis and Processing: LLMs can be used to analyze data from various sources, such as financial reports, social media posts, and scientific papers. LLM agents can help them extract key insights, identify trends, and answer complex questions.
- Content Generation and Automation: LLMs can be empowered to create different kinds of content, like articles, social media posts, or marketing copy. LLM agents can assist them by searching for relevant information, gathering data, and ensuring factual accuracy.
- Custom Tools and Applications: Developers can leverage LLM agents to build custom tools that combine the power of LLMs with external functionalities. Imagine a tool that allows an LLM to write and execute Python code, search for information online, and generate creative text formats based on user input.
Explore the dynamics and working of agents in LLM
Improved Performance: Context and Information for Better Answers
LLM agents don’t just expand what LLMs can do, they also improve how they do it. By providing LLMs with access to relevant context and information, LLM agents can significantly enhance the quality of their responses:
- More Accurate Responses: When an LLM agent retrieves data from external sources, the LLM can generate more accurate and informative answers to user queries.
- Enhanced Reasoning: LLM agents can facilitate a back-and-forth exchange between the LLM and external systems, allowing the LLM to reason through problems and arrive at well-supported conclusions.
- Reduced Bias: By incorporating information from diverse sources, LLM agents can mitigate potential biases present in the LLM’s training data, leading to fairer and more objective responses.
Enhanced Efficiency: Automating Tasks and Saving Time
LLM agents can automate repetitive tasks that would otherwise require human intervention. This frees up human experts to focus on more complex problems and strategic initiatives. Here are some examples:
- Data Extraction and Summarization: LLM agents can automatically extract relevant data from documents and reports, saving users time and effort.
- Research and Information Gathering: LLM agents can be used to search for information online, compile relevant data points, and present them to the LLM for analysis.
- Content Creation Workflows: LLM agents can streamline content creation workflows by automating tasks like data gathering, formatting, and initial drafts.
Explore more use cases of LLMs
In conclusion, LLM agents are a game-changer, transforming LLMs from powerful text processors to versatile tools that can interact with the real world. By unlocking enhanced functionality, increased versatility, improved performance, and enhanced efficiency, LLM agents pave the way for a new wave of innovative applications across various domains.
In the next section, we’ll explore how LangChain, a framework for building LLM applications, can be used to implement LLM agents and unlock their full potential.
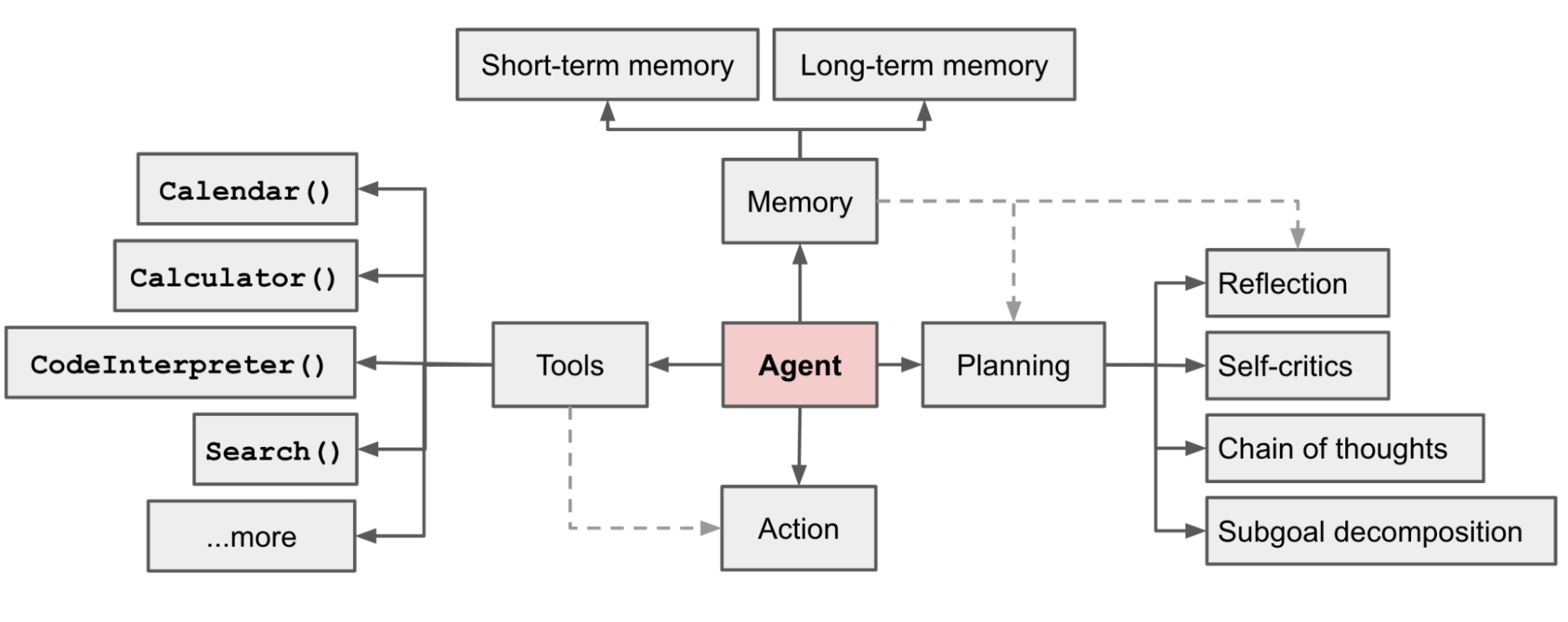
Implementing LLM Agents with LangChain
Now, let’s explore how LangChain, a framework specifically designed for building LLM applications, empowers us to implement LLM agents.
What is LangChain?
LangChain is a powerful toolkit that simplifies the process of building and deploying LLM applications. It provides a structured environment where you can connect your LLM with various tools and functionalities, enabling it to perform actions beyond basic text processing. Think of LangChain as a Lego set for building intelligent applications powered by LLMs.
Implementing LLM Agents with LangChain: A Step-by-Step Guide
Let’s break down the process of implementing LLM agents with LangChain into manageable steps:
Setting Up the Base LLM
The foundation of your LLM agent is the LLM itself. You can either choose an open-source model like Llama2 or Mixtral, or a proprietary model like OpenAI’s GPT or Cohere.
Another interesting read: PaLM vs Llama 2
Defining the Tools
Identify the external functionalities your LLM agent will need. These tools could be:
- APIs: Services that provide programmatic access to data or functionalities (e.g., weather API, stock market API)
- Databases: Collections of structured data your LLM can access and query (e.g., customer database, product database)
- Web Search Tools: Tools that allow your LLM to search the web for relevant information (e.g., duckduckgo, serper API)
- Coding Tools: Tools that allow your LLM to write and execute actual code (e.g., Python REPL Tool)
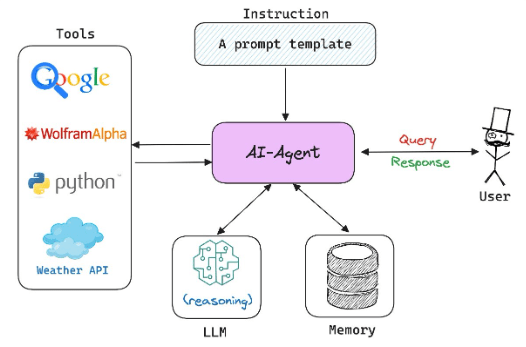
You can check out LangChain’s documentation to find a comprehensive list of tools and toolkits provided by LangChain that you can easily integrate into your agent, or you can easily define your own custom tool such as a calculator tool.
Creating an Agent
This is the brain of your LLM agent, responsible for communication and coordination. The agent understands the user’s needs, selects the appropriate tool based on the task, and interprets the retrieved information for response generation.
You might also find this useful: Understanding LangChain
Defining the Interaction Flow
Establish a clear sequence for how the LLM, agent, and tools interact. This flow typically involves:
- Receiving a user query
- The agent analyzes the query and identifies the necessary tools
- The agent passes in the relevant parameters to the chosen tool(s)
- The LLM processes the retrieved information from the tools
- The agent formulates a response based on the retrieved information
Integration with LangChain
LangChain provides the platform for connecting all the components. You’ll integrate your LLM and chosen tools within LangChain, creating an agent that can interact with the external environment.
Testing and Refining
Once everything is set up, it’s time to test your LLM agent! Put it through various scenarios to ensure it functions as expected. Based on the results, refine the agent’s logic and interactions to improve its accuracy and performance.
By following these steps and leveraging LangChain’s capabilities, you can build versatile LLM agents that unlock the true potential of LLMs.

LangChain Implementation of an LLM Agent with tools
In the next section, we’ll delve into a practical example, walking you through a Python Notebook that implements a LangChain-based LLM agent with retrieval (RAG) and web search tools. OpenAI’s GPT-4 has been used as the LLM of choice here. This will provide you with a hands-on understanding of the concepts discussed here.
The agent has been equipped with two tools:
- A retrieval tool that can be used to fetch information from a vector store of Data Science Dojo blogs on the topic of RAG. LangChain’s PyPDFLoader is used to load and chunk the PDF blog text, OpenAI embeddings are used to embed the chunks of data, and Weaviate client is used for indexing and storage of data.
- A web search tool that can be used to query the web and bring up-to-date and relevant search results based on the user’s question. Google Serper API is used here as the search wrapper – you can also use duckduckgo search or Tavily API.
Below is a diagram depicting the agent flow:
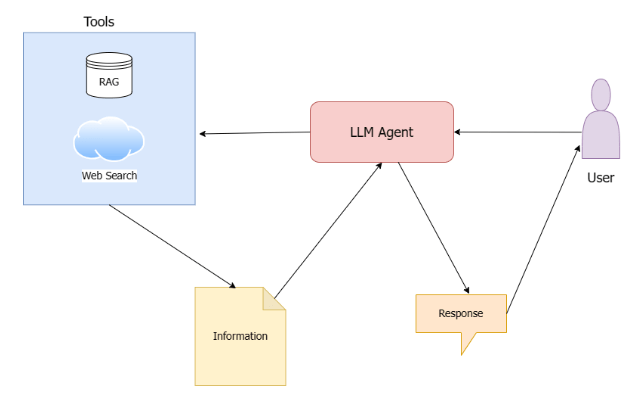
Let’s now start going through the code step-by-step.
Installing Libraries
Let’s start by downloading all the necessary libraries that we’ll need. This includes libraries for handling language models, API clients, and document processing.
Importing and Setting API Keys
Now, we’ll ensure our environment has access to the necessary API keys for OpenAI and Serper by importing them and setting them as environment variables.
Documents Preprocessing: Mounting Google Drive and Loading Documents
Let’s connect to Google Drive and load the relevant documents. I‘ve stored PDFs of various Data Science Dojo blogs related to RAG, which we’ll use for our tool. Following are the links to the blogs I have used:
Extracting Text from PDFs
Using the PyPDFLoader from Langchain, we’ll extract text from each PDF by breaking them down into individual pages. This helps in processing and indexing them separately.
Embedding and Indexing through Weaviate: Embedding Text Chunks
Now we’ll use Weaviate client to turn our text chunks into embeddings using OpenAI’s embedding model. This prepares our text for efficient querying and retrieval.
Setting Up the Retriever
With our documents embedded, let’s set up the retriever which will be crucial for fetching relevant information based on user queries.
Defining Tools: Retrieval and Search Tools Setup
Next, we define two key tools: one for retrieving information from our indexed blogs, and another for performing web searches for queries that extend beyond our local data.
Adding Tools to the List
We then add both tools to our tool list, ensuring our agent can access these during its operations.
Setting up the Agent: Creating the Prompt Template
Let’s create a prompt template that guides our agent on how to handle different types of queries using the tools we’ve set up.
Initializing the LLM with GPT-4
For the best performance, I used GPT-4 as the LLM of choice as GPT-3.5 seemed to struggle with routing to tools correctly and would go back and forth between the two tools needlessly.
Creating and Configuring the Agent
With the tools and prompt template ready, let’s construct the agent. This agent will use our predefined LLM and tools to handle user queries.
Invoking the Agent: Agent Response to a RAG-related Query
Let’s put our agent to the test by asking a question about RAG and observing how it uses the tools to generate an answer.
Agent Response to an Unrelated Query
Now, let’s see how our agent handles a question that’s not about RAG. This will demonstrate the utility of our web search tool.
That’s all for the implementation of an LLM Agent through LangChain. You can find the full code here.

This is, of course, a very basic use case but it is a starting point. There is a myriad of stuff you can do using agents and LangChain has several cookbooks that you can check out. The best way to get acquainted with any technology is to actually get your hands dirty and use the technology in some way.
I’d encourage you to look up further tutorials and notebooks using agents and try building something yourself. Why not try delegating a task to an agent that you yourself find irksome – perhaps an agent can take off its burden from your shoulders!
LLM agents: A building block for LLM applications
To sum it up, LLM agents are a crucial element for building LLM applications. As you navigate through the process, make sure to consider the role and assistance they have to offer.