Regularization in machine learning is a technique that is used to prevent over fitting in ML models. In this article, we’ll explore what overfitting is and how regularization works to mitigate it, as well as the different types of regularization techniques used in machine learning.
Before we dive into the concept of regularization in machine learning, it’s important to first understand the related concepts of OVERFITTING and UNDERFITTING. These concepts are crucial for building accurate and reliable machine-learning models. If you want to know about machine learning in a layman manner please visit the below link as well.
What is Overfitting?
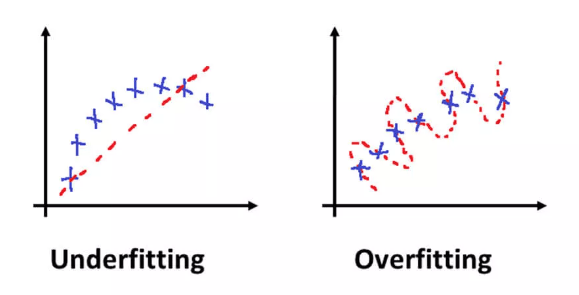
In machine learning, models are trained on a set of data called the training set. The goal is to create a model that can accurately predict outcomes on new data, called the test set. However, sometimes a model may become too complex and start fitting the training data too closely, essentially memorizing the data instead of learning from it. This is called overfitting, and it can lead to poor performance on new data.
What is Underfitting?
On the other hand, Underfitting occurs when a machine learning model is too simple to capture the complexity of the data it is trying to model. This can happen when the model is not trained for long enough, or when the training data is not diverse enough to capture all the variations in the data.
The ultimate goal of machine learning is to find the right balance between overfitting and underfitting, achieving a model that can generalize well to new data while still capturing the underlying patterns in the training data. This is known as achieving a “GENERALIZED” model.
How does regularization in machine learning work?
Regularization works by adding a penalty term to the loss function during training. The penalty term discourages the model from creating complex relationships between the input features and the output variable. Essentially, it encourages the model to choose simpler solutions that generalize better to new data. By doing so, regularization can help prevent overfitting.
Read more –> Machine learning model deployment 101: A comprehensive guide
Types of regularization
There are several types of regularization techniques used in machine learning, including L1, L2, and dropout.
| Regularization Type | Regularization Term | Formula |
|---|---|---|
| L1 (Lasso) |
L1 Norm
|
(\text{L1 Regularization Term} = \alpha \sum_{i=1}^{n} |
|
L2 (Ridge)
|
L2 Norm | L2 Regularization Term=α∑i=1nwi21. |
1. Lasso regularization (L1)
L1 regularization, commonly referred to as Lasso regularization, is a regularization technique extensively utilized in machine learning. It introduces a penalty term into the model’s cost function that is directly proportional to the absolute value of its weights. Consequently, larger weights incur a higher penalty.
By promoting the reduction of non-zero weights, L1 regularization facilitates feature selection. This approach effectively simplifies the model by prioritizing significant features while eliminating irrelevant ones. Through penalizing large weights, the model is compelled to reduce their magnitudes, resulting in a less complex and more interpretable model. Ultimately, L1 regularization serves as a potent tool for enhancing the performance and interpretability of machine learning models.
Code snippet for L1 regularization using Python and scikit-learn:
One noteworthy advantage of L1 regularization is its ability to streamline the model by reducing the number of utilized features. This can lead to faster training and improved generalization performance. However, it is essential to acknowledge that L1 regularization may not universally suit all data types and models, and alternative regularization techniques such as L2 regularization may be more suitable in certain scenarios.
All in all, L1 regularization significantly contributes to improving model performance and interpretability, making it a valuable asset in the realm of data science.
2. Ridge regularization (L2)
L2 regularization, commonly referred to as Ridge regularization, is a highly effective approach that enhances the performance of machine learning models. It achieves this by incorporating a penalty term that is directly proportional to the square of the model’s weights. This encourages the model to minimize the weight magnitudes, thereby preventing excessive complexity. As a result, L2 regularization effectively addresses the issue of overfitting and significantly improves the model’s ability to generalize to unseen data.
Code snippet for L2 regularization using Python and scikit-learn:
Compared to L1 regularization, L2 regularization does not perform feature selection by reducing the number of non-zero weights. Instead, it shrinks all the weights towards zero by a constant factor, thus making the model less sensitive to small fluctuations in the data. This technique is particularly useful when dealing with high-dimensional data, where the number of features is much larger than the number of observations, as it helps to avoid overfitting and improve the model’s generalization performance.
Benefits of regularization
Regularization offers several advantages for machine learning models. Firstly, it effectively combats overfitting, allowing for better generalization on unseen data. This improves the model’s accuracy and enhances its practical applicability.
Secondly, regularization aids in simplifying the model, making it more comprehensible and interpretable. This aspect is particularly valuable in domains like healthcare and finance, where model decisions have significant implications.
Lastly, regularization mitigates the risk of biases in the model. By encouraging simpler solutions, it prevents the model from capturing spurious correlations in the data, which can lead to biased predictions.
Conclusion
In a nutshell, regularization in machine learning plays a crucial role in machine learning as it helps address overfitting issues and enhances model accuracy, simplicity, and interpretability. It achieves this by introducing a penalty term to the loss function during training, promoting the selection of simpler solutions that can generalize well to unseen data.
Among the various regularization techniques, L2 regularization is widely employed in practice. In summary, regularization is an invaluable asset for machine learning practitioners and is expected to gain further prominence as the field advances.
Written by Muhammad Rizwan