
Are you a data scientist looking to streamline your development process and ensure consistent results across different environments? Need information on Docker for Data Science? Well, this blog post delves into the concept of Docker and how it helps developers ship their code effortlessly in the form of containers.
We will explore the underlying principle of virtualization, comparing Docker containers with virtual machines (VMs) to understand their differences. Plus, we will provide a hands-on Docker tutorial for data science using Python scripts, running on Windows OS, and integrated with Visual Studio Code (VS Code).
But that is not all! We will also uncover the power of Docker Hub and show you how to set up a Docker container registry, publish your images, and effortlessly share your data science projects across different environments. Let us embark on this containerization journey together!
Understanding the concept of Docker and Containers
The concept of Docker for Data Science is to help developers develop and ship their code easily, in the form of containers. These containers can be deployed anywhere, making the process of setting up a project much simpler, ensuring consistency and reproducibility across different environments.
The structure of a Docker Image is that it contains instructions for creating a container. It is a snapshot of a filesystem with application code and all its dependencies. Docker Container, however, is a runnable instance of a Docker Image. You can play around with both using CLI, or GUI using Docker Desktop.
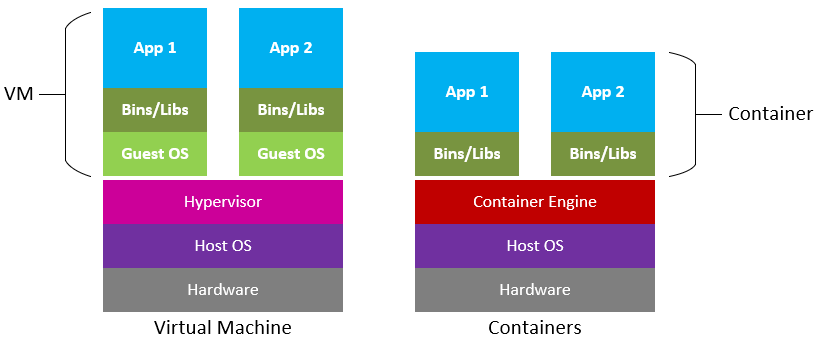
The underlying principle used to create isolated environments for running applications is called Virtualization. You may already have an idea of virtual machines which use the same concept. Both Docker and VMs aim to achieve isolation, but they use different approaches to accomplish this.
VMs provide stronger isolation by running complete operating systems, while Docker containers leverage the host OS’s kernel, making them more lightweight and efficient in terms of resource usage. Docker containers are well-suited for deploying applications consistently across various environments, while VMs are better for running different operating systems on the same physical hardware.
Docker for data science: A tutorial
Prerequisites:
- Install Docker Desktop for Windows: Download and install Docker Desktop for Windows from the official website.
- Install Visual Studio Code: Download and install Visual Studio Code from the official website: https://code.visualstudio.com/
Step 1: Set Up Your Project Directory
Create a project directory for your data science project. Inside the project directory, create a Python script (e.g., code_1.py) that contains your data science code.
Let us suppose you have a file named code_1.py which contains:
This is just a simple example to demonstrate data analysis and machine learning operations
Read more –> Machine learning roadmap: 5 Steps to a successful career
Step 2: Dockerfile
Create a file in the project directory. The file contains instructions to build the image for your data science application.
Step 3: Build the Docker Image
Open a terminal or command prompt and navigate to your project directory. Build the image using the following command:
Note: Remember to not skip the “.” as it serves as a positional argument.
Step 4: Run the Docker Container
Once the image is built, you can run the Docker container with the following command:
This will execute the Python script inside the container, and you will see the output in the terminal.
Step 5: VS Code Integration
To run and debug your data science code inside the container directly from VS Code, follow these steps:
- Install the “Remote – Containers” extension in VS Code. This extension allows you to work with development containers directly from VS Code.
- Open your project directory in VS Code.
- Click on the green icon at the bottom-left corner of the VS Code window. It should say “Open a Remote Window.” Select “Remote-Containers: Reopen in Container” from the menu that appears.
- VS Code will now reopen inside the Docker container. You will have access to all the tools and dependencies installed in the container.
- Open your code_1.py script in VS Code and start working on your data science code as usual.
- When you are ready to run the Python script, simply open a terminal in VS Code and execute it using the command:
You can also use the VS Code debugger to set breakpoints, inspect variables, and debug your data science code inside the container. With this setup, you can develop and run your data science code using Docker and VS Code locally.
Next, let us move toward the Docker Hub and Docker Container Registry, which will show us its power. By setting up a Docker container registry, publishing your Docker images, and pulling them from Docker Hub, you can easily share your data science projects with others or deploy them on different machines while ensuring consistency across environments. Docker Hub serves as a central repository for Docker images, making it convenient to manage and distribute your containers.
Step 6: Set Up Docker Container Registry (Docker Hub):
- Create an account on Docker Hub (https://hub.docker.com/).
- Login to Docker Hub using the following command in your terminal or command prompt:
Step 7: Tag and push the Docker Image to Docker Hub:
After building the image, tag it with your Hub username and the desired repository name. The repository name can be anything you choose. It is good practice to include a version number as well.
Step 8: Pull and Run the Docker Image from Docker Hub:
Now, let us demonstrate how to pull the Docker image from Docker Hub on a different machine or another environment:
- On the new machine, install it and ensure it is running.
- Pull the Docker image from Docker Hub using the following command:
This will execute the same script we initially had inside the container, and you should see the same output as before.
Final takeaways
In conclusion, Docker for data science is a game-changer for data scientists, streamlining development and ensuring consistent results across environments. Its lightweight containers outshine traditional VMs, making deployment effortless. With Docker Hub’s central repository, sharing projects becomes seamless.
Embrace Docker’s power and elevate your data science journey!
Written by Syed Muhammad Hani
