
Azure Synapse provides a unified platform to ingest, explore, prepare, transform, manage, and serve data for BI (Business Intelligence) and machine learning needs.
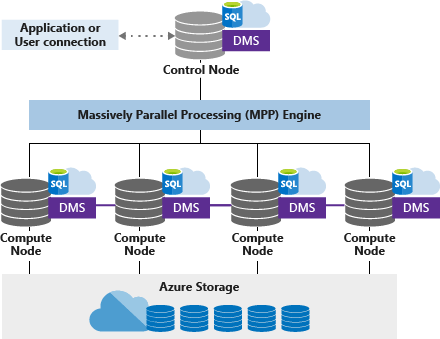
Introduction to SQL pools
Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs. DWUs (Data Warehouse Units) can customize resources and optimize performance and costs. In this blog, we will explore how to optimize performance and reduce costs when using dedicated SQL pools in Azure Synapse Analytics.
Loading data
When loading data, it is best to use PolyBase for substantial amounts of data or when speed is a priority. PolyBase is a feature that allows you to query and load data from different data sources, like Azure Blob Storage. This makes it optimal for handling large amounts of data or when speed is a priority.
Additionally, using a heap table for temporary data can improve loading speed. A heap table is a temporary table that only exists for a session and is useful when loading data to stage it before running more transformations.
Clustered column store index
When loading data to a clustered column store table, creating a clustered column store index is essential for query performance. A clustered column store index is created on a table with a clustered column store architecture. It is a highly compressed and in-memory storage format that stores each column of data separately, resulting in faster query processing and superior query performance. This helps to improve query performance by allowing the database engine to retrieve the required data pages more quickly.
Managing compute costs
Managing computer costs is also important when working with dedicated SQL pools. One way to do this is by pausing and scaling the dedicated SQL pool. This allows you to only pay for the resources you need and can help you avoid unnecessary expenses. Additionally, using the appropriate resource class can improve query performance.
SQL pools use resource groups to allocate memory to queries. Initially, all users are assigned to the small resource class, which grants 100 MB of memory per distribution. However, more significant memory allocations will benefit certain queries, like large joins or loads to clustered column store tables.
Maintaining statistics and performance tuning
To ensure optimal performance, it is essential to keep statistics updated when using dedicated SQL pools. The quality of the query plans generated by the optimizer depends on the accuracy of the statistics, so it is necessary to make sure statistics on columns used in queries are current. Performance tuning is another crucial aspect of working with dedicated SQL pools.
One way to improve query performance is using materialized views, ordered clustered column store index, and result set caching. Additionally, it is a good practice to group INSERT statements into batches to optimize large amounts of data loading.
Hash distributes large tables and partitioning data
When using dedicated SQL pools, it is recommended to hash-distribute large tables instead of relying on the default Round Robin distribution. It is also important to be mindful when partitioning data, as too many partitions can impact performance negatively. Partitioning can be beneficial for managing data through partition switching or optimizing scans, but it should be done carefully.
Conclusion
In conclusion, working with dedicated SQL pools in Azure Synapse Analytics requires a comprehensive understanding of best practices for loading data, managing compute costs, utilizing PolyBase, maintaining statistics, performance tuning, hash distributing large tables, and partitioning data.
By following these best practices, you can achieve optimal performance and reduce costs with your dedicated SQL pools in Azure Synapse Analytics. It is important to remember that Azure Synapse Analytics is a complex platform. These best practices will help you in your data processing and analytics journey.
