
The next generation of Language Model Systems (LLMs) and LLM chatbots are expected to offer improved accuracy, expanded language support, enhanced computational efficiency, and seamless integration with emerging technologies. These advancements indicate a higher level of versatility and practicality compared to the previous models.
While AI solutions do present potential benefits such as increased efficiency and cost reduction, it is crucial for businesses and society to thoroughly consider the ethical and social implications before widespread adoption.
Recent strides in LLMs have been remarkable, and their future appears even more promising. Although we may not be fully prepared, the future is already unfolding, demanding our adaptability to embrace the opportunities it presents.
Back to basics: Understanding large language models
LLM, standing for Large Language Model, represents an advanced language model that undergoes training on an extensive corpus of text data. By employing deep learning techniques, LLMs can comprehend and produce human-like text, making them highly versatile for a range of applications.
These include text completion, language translation, sentiment analysis, and much more. One of the most renowned LLMs is OpenAI’s GPT-3, which has received widespread recognition for its exceptional language generation capabilities.
Large language models knowledge test
Challenges in traditional AI chatbot development: Role of LLMs
The current practices for building AI chatbots have limitations when it comes to scalability. Initially, the process involves defining intents, collecting related utterances, and training an NLU model to predict user intents. As the number of intents increases, managing and disambiguating them becomes difficult.

Additionally, designing deterministic conversation flows triggered by detected intents becomes challenging, especially in complex scenarios that require multiple interconnected layers of chat flows and intent understanding. To overcome these challenges, Large Language Models (LLMs) come to the rescue.
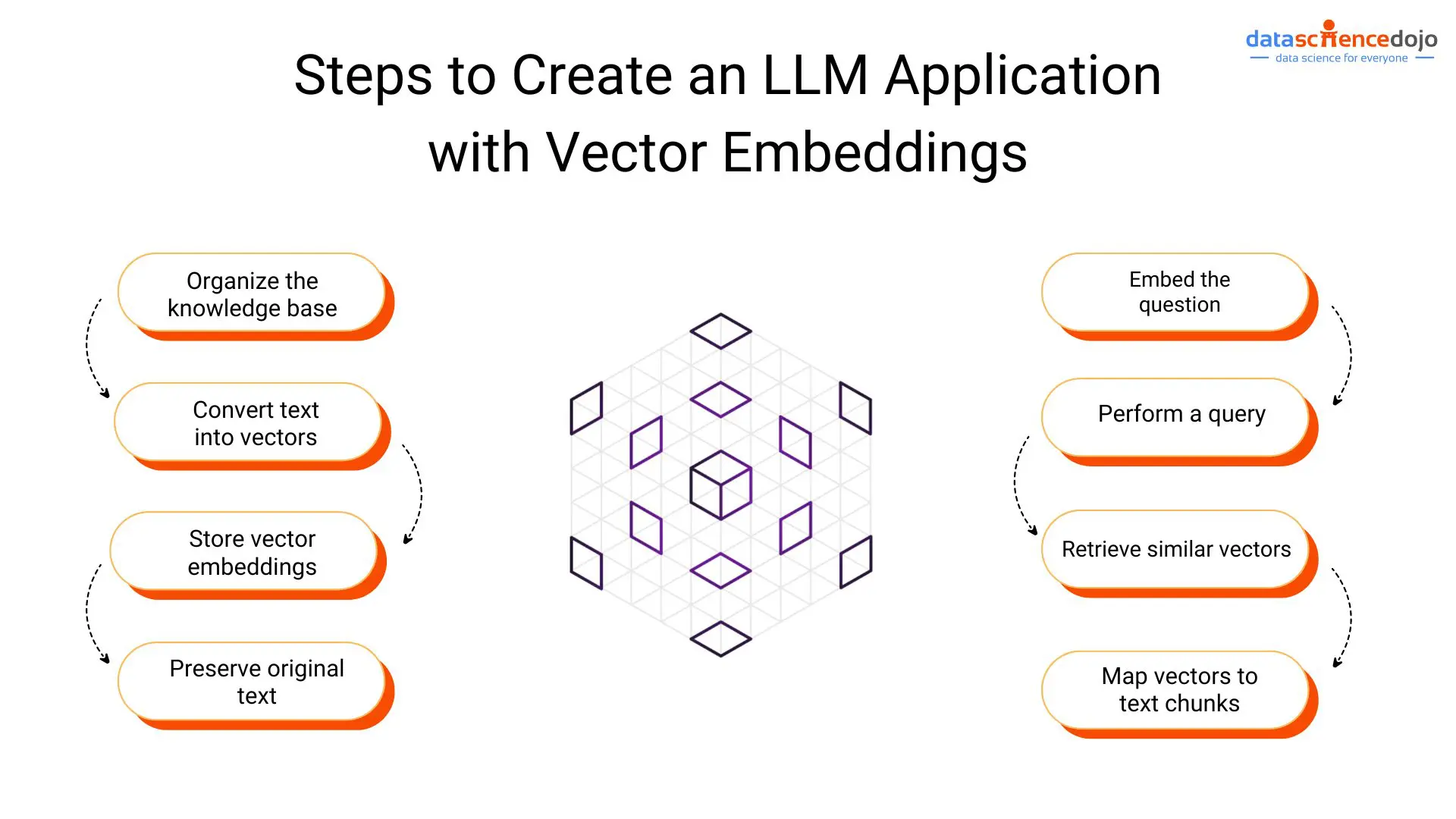
Building an efficient LLM application using vector embeddings
Vector embeddings are a type of representation that can be used to capture the meaning of text. They are typically created by training a machine learning model on a large corpus of text. The model learns to associate each word with a vector of numbers. These numbers represent the meaning of the word in relation to other words in the corpus.
LLM chatbots can be built using vector embeddings by first creating a knowledge base of text chunks. Each text chunk should represent a distinct piece of information that can be queried. The text chunks should then be embedded into vectors using a vector embedding model. The resulting vector representations can then be stored in a vector database.
Read more about —> Vector Databases

Step 1: Organizing knowledge base
- Break down your knowledge base into smaller, manageable chunks. Each chunk should represent a distinct piece of information that can be queried.
- Gather data from various sources, such as Confluence documentation and PDF reports.
- The chunks should be well-defined and have clear boundaries. This will make it easier to extract the relevant information when querying the knowledge base.
- The chunks should be stored in a way that makes them easy to access. This could involve using a hierarchical file system or a database.
Step 2: Text into vectors
- Use an embedding model to convert each chunk of text into a vector representation.
- The embedding model should be trained on a large corpus of text. This will ensure that the vectors capture the meaning of the text.
- The vectors should be of a fixed length. This will make it easier to store and query them.
Step 3: Store vector embeddings
- Save the vector embeddings obtained from the embedding model in a Vector Database.
- The Vector Database should be able to store and retrieve the vectors efficiently.
- The Vector Database should also be able to index the vectors so that they can be searched by keyword.
Step 4: Preserve original text
- Ensure you store the original text that corresponds to each vector embedding.
- This text will be vital for retrieving relevant information during the querying process.
- The original text can be stored in a separate database or file system.
Step 5: Embed the question
- Use the same embedding model to transform the question into a vector representation.
- The vector representation of the question should be similar to the vector representations of the chunks of text
- that contains the answer.
Step 6: Perform a query
- Query the Vector Database using the vector embedding generated from the question.
- Retrieve the relevant context vectors to aid in answering the query.
- The context vectors should be those that are most similar to the vector representation of the question.
Step 7: Retrieve similar vectors
- Conduct an Approximate Nearest Neighbor (ANN) search in the Vector Database to find the most similar vectors to the query embedding.
- Retrieve the most relevant information from the previously selected context vectors.
- The ANN search will return a list of vectors that are most similar to the query embedding.
- The most relevant information from these vectors can then be used to answer the question.
Step 8: Map vectors to text chunks
- Associate the retrieved vectors with their corresponding text chunks to link numerical representations to actual content.
- This will allow the LLM to access the original text that corresponds to the vector representations.
- The mapping between vectors and text chunks can be stored in a separate database or file system.
Step 9: Generate the answer
- Pass the question and retrieved-context text chunks to the Large Language Model (LLM) via a prompt.
- Instruct the LLM to use only the provided context for generating the answer, ensuring prompt engineering aligns with expected boundaries.
- The LLM will use the question and context text chunks to generate an answer.
- The answer will be in natural language and will be relevant to the question.
Building AI chatbots to address real challenges
We are actively exploring the AI chatbot landscape to help businesses tackle their past challenges with conversational automation.
Certain fundamental aspects of chatbot building are unlikely to change, even as AI-powered chatbot solutions become more prevalent. These aspects include:
- Designing task-specific conversational experiences: Regardless of where a customer stands in their journey, businesses must focus on creating tailored experiences for end users. AI-powered chatbots do not eliminate the need to design seamless experiences that alleviate pain points and successfully acquire, nurture, and retain customers.
- Optimizing chatbot flows based on user behavior: AI chatbots continually improve their intelligence over time, attracting considerable interest in the market. Nevertheless, companies still need to analyze the bot’s performance and optimize parts of the flow where conversion rates may drop, based on user interactions. This holds true whether the chatbot utilizes AI or not.
- Integrating seamlessly with third-party platforms: The development of AI chatbot solutions does not negate the necessity for easy integration with third-party platforms. Regardless of the data captured by the bot, it is crucial to handle and utilize that information effectively in the tech stacks or customer relationship management (CRM) systems used by the teams. Seamless integration remains essential.
- Providing chatbot assistance on different channels: AI-powered chatbots can and should be deployed across various channels that customers use, such as WhatsApp, websites, Messenger, and more. The use of AI does not undermine the fundamental requirement of meeting customers where they are and engaging them through friendly conversations.
Developing LLM chatbots with LangChain
Conversational chatbots have become an essential component of many applications, offering users personalized and seamless interactions. To build successful chatbots, the focus lies in creating ones that can understand and generate human-like responses.
With LangChain’s advanced language processing capabilities, you can create intelligent chatbots that outperform traditional rule-based systems.
Step 1: Import necessary libraries
To get started, import the required libraries, including LangChain’s LLMChain and OpenAI for language processing.
Step 2: Using prompt template
Utilize the PromptTemplate and ConversationBufferMemory to create a chatbot template that generates jokes based on user input. This allows the chatbot to store and retrieve chat history, ensuring contextually relevant responses.
Step 3: Setting up the chatbot
Instantiate the LLMChain class, leveraging the OpenAI language model for generating responses. Utilize the ‘llm_chain.predict()’ method to generate a response based on the user’s input.
By combining LangChain’s LLM capabilities with prompt templates and chat history, you can create sophisticated and context-aware conversational chatbots for a wide range of applications.
Customizing LLMs with LangChain’s finetuning
Finetuning is a crucial process where an existing pre-trained LLM undergoes additional training on specific datasets to adapt it to a particular task or domain. By exposing the model to task-specific data, it gains a deeper understanding of the target domain’s nuances, context, and complexities.
This refinement process allows developers to enhance the model’s performance, increase accuracy, and make it more relevant to real-world applications.
Introducing LangChain’s finetuning capabilities
LangChain elevates finetuning to new levels by offering developers a comprehensive framework to train LLMs on custom datasets. With a user-friendly interface and a suite of tools, the fine-tuning process becomes simplified and accessible.
LangChain supports popular LLM architectures, including GPT-3, empowering developers to work with cutting-edge models tailored to their applications. With LangChain, customizing and optimizing LLMs is now easily within reach.
The fine-tuning workflow with LangChain
1. Data Preparation
Customize your dataset to fine-tune an LLM for your specific task. Curate a labeled dataset aligning with your target application, containing input-output pairs or suitable format.
2. Configuring Parameters
In LangChain interface, specify desired LLM architecture, layers, size, and other parameters. Define model’s capacity and performance balance.
3. Training Process
LangChain utilizes distributed computing resources for efficient LLM training. Initiate training, optimizing the pipeline for resource utilization and faster convergence. The model learns from your dataset, capturing task-specific nuances and patterns.
To start the fine-tuning process with LangChain, import required libraries and dependencies. Initialize the pre-trained LLM and fine-tune on your custom dataset.
4. Evaluation
After the fine-tuning process of the LLM, it becomes essential to evaluate its performance. This step involves assessing how well the model has adapted to the specific task. Evaluating the fine-tuned model is done using appropriate metrics and a separate test dataset.
The evaluation results can provide insights into the effectiveness of the fine-tuned LLM. Metrics like accuracy, precision, recall, or domain-specific metrics can be measured to assess the model’s performance.
LLM-powered applications: Top 4 real-life use cases
Explore real-life examples and achievements of LLM-powered applications, demonstrating their impact across diverse industries. Discover how LLMs and LangChain have transformed customer support, e-commerce, healthcare, and content generation, resulting in enhanced user experiences and business success.
LLMs have revolutionized search algorithms, enabling chatbots to understand the meaning of words and retrieve more relevant content, leading to more natural and engaging customer interactions.

Companies must view chatbots and LLMs as valuable tools for specific tasks and implement use cases that deliver tangible benefits to maximize their impact. As businesses experiment and develop more sophisticated chatbots, customer support and experience are expected to improve significantly in the coming years
1. Customer support:
LLM-powered chatbots have revolutionized customer support, offering personalized assistance and instant responses. Companies leverage LangChain to create chatbots that comprehend customer queries, provide relevant information, and handle complex transactions. This approach ensures round-the-clock support, reduces wait times, and boosts customer satisfaction.
2. e-Commerce:
Leverage LLMs to elevate the e-commerce shopping experience. LangChain empowers developers to build applications that understand product descriptions, user preferences, and buying patterns. Utilizing LLM capabilities, e-commerce platforms deliver personalized product recommendations, address customer queries, and even generate engaging product descriptions, driving sales and customer engagement.
3. Healthcare:
In the healthcare industry, LLM-powered applications improve patient care, diagnosis, and treatment processes. LangChain enables intelligent virtual assistants that understand medical queries, provide accurate information, and assist in patient triaging based on symptoms. These applications grant faster access to healthcare information, reduce burdens on providers, and empower patients to make informed health decisions.
4. Content generation:
LLMs are valuable tools for content generation and creation. LangChain facilitates applications that generate creative and contextually relevant content, like blog articles, product descriptions, and social media posts. Content creators benefit from idea generation, enhanced writing efficiency, and maintaining consistent tone and style.
These real-world applications showcase the versatility and impact of LLM-powered solutions in various industries. By leveraging LangChain’s capabilities, developers create innovative solutions, streamline processes, enhance user experiences, and drive business growth.
Ethical and social implications of LLM chatbots:
- Privacy: LLM chatbots are trained on large amounts of data, which could include personal information. This data could be used to track users’ behavior or to generate personalized responses. It is important to ensure that this data is collected and used ethically.
- Bias: LLM chatbots are trained on data that reflects the biases of the real world. This means that they may be biased in their responses. For example, an LLM chatbot trained on data from the internet may be biased towards certain viewpoints or demographics. It is important to be aware of these biases and to take steps to mitigate them.
- Misinformation: LLM chatbots can be used to generate text that is misleading or false. This could be used to spread misinformation or to manipulate people. It is important to be aware of the potential for misinformation when interacting with LLM chatbots.
- Emotional manipulation: LLM chatbots can be used to manipulate people’s emotions. This could be done by using emotional language or by creating a sense of rapport with the user. It is important to be aware of the potential for emotional manipulation when interacting with LLM chatbots.
- Job displacement: LLM chatbots could potentially displace some jobs. For example, LLM chatbots could be used to provide customer service or to answer questions. It is important to consider the potential impact of LLM chatbots on employment when developing and deploying this technology.
Read more –> Empower your nonprofit with Responsible AI: Shape the future for positive impact!
In addition to the ethical and social implications listed above, there are also a few other potential concerns that need to be considered. For example, LLM chatbots could be used to create deepfakes, which are videos or audio recordings that have been manipulated to make it look or sound like someone is saying or doing something they never said or did. Deepfakes could be used to spread misinformation or to damage someone’s reputation.
Another potential concern is that LLM chatbots could be used to create addictive or harmful experiences. For example, an LLM chatbot could be used to create a virtual world that is very attractive to users, but that is also very isolating or harmful. It is important to be aware of these potential concerns and to take steps to mitigate them.
In a nutshell
Building a chatbot using Large Language Models is an exciting and promising endeavor. Despite the challenges ahead, the rewards, such as enhanced customer engagement, operational efficiency, and potential cost savings, are truly remarkable. So, it’s time to dive into the coding world, get to work, and transform your visionary chatbot into a reality!
The dojo way: Large language models bootcamp
Data Science Dojo’s LLM Bootcamp is a specialized program designed for creating LLM-powered applications. This intensive course spans just 40 hours, offering participants a chance to acquire essential skills.
Focused on the practical aspects of LLMs in natural language processing, the bootcamp emphasizes using libraries like Hugging Face and LangChain.
Participants will gain expertise in text analytics techniques, including semantic search and Generative AI. Additionally, they’ll gain hands-on experience in deploying web applications on cloud services. This program caters to professionals seeking to enhance their understanding of Generative AI, covering vital principles and real-world implementation without requiring extensive coding skills.
Jump onto the bandwagon: Learn to build and deploy custom LLM applications now!
