If you’ve been following developments in open-source LLMs, you’ve probably heard the name Kimi K2 pop up a lot lately. Released by Moonshot AI, this new model is making a strong case as one of the most capable open-source LLMs ever released.
From coding and multi-step reasoning to tool use and agentic workflows, Kimi K2 delivers a level of performance and flexibility that puts it in serious competition with proprietary giants like GPT-4.1 and Claude Opus 4. And unlike those closed systems, Kimi K2 is fully open source, giving researchers and developers full access to its internals.
In this post, we’ll break down what makes Kimi K2 so special, from its Mixture-of-Experts architecture to its benchmark results and practical use cases.
Kimi K2 is an open-source large language model developed by Moonshot AI, a rising Chinese AI company. It’s designed not just for natural language generation, but for agentic AI, the ability to take actions, use tools, and perform complex workflows autonomously.
At its core, Kimi K2 is built on a Mixture-of-Experts (MoE) architecture, with a total of 1 trillion parameters, of which 32 billion are active during any given inference. This design helps the model maintain efficiency while scaling performance on-demand.
Moonshot released two main variants:
Kimi-K2-Base: A foundational model ideal for customization and fine-tuning.
Kimi-K2-Instruct: Instruction-tuned for general chat and agentic tasks, ready to use out-of-the-box.
Under the Hood: Kimi K2’s Architecture
What sets Kimi K2 apart isn’t just its scale—it’s the smart architecture powering it.
1. Mixture-of-Experts (MoE)
Kimi K2 activates only a subset of its full parameter space during inference, allowing different “experts” in the model to specialize in different tasks. This makes it more efficient than dense models of a similar size, while still scaling to complex reasoning or coding tasks when needed.
Token volume: Trained on a whopping 15.5 trillion tokens
Optimizer: Uses Moonshot’s proprietary MuonClip optimizer to ensure stable training and avoid parameter blow-ups.
Post-training: Fine-tuned with synthetic data, especially for agentic scenarios like tool use and multi-step problem solving.
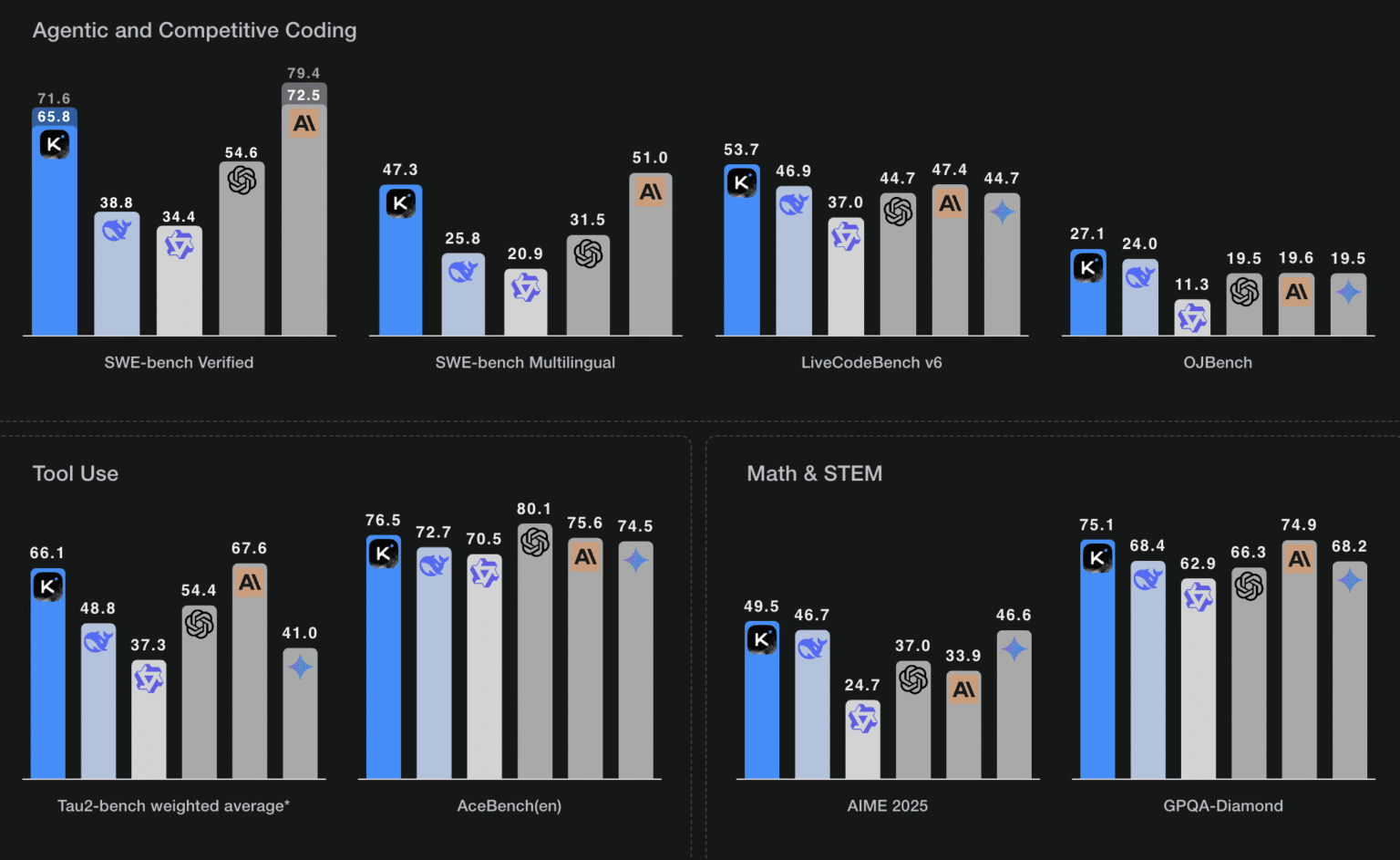
Performance Benchmarks: Does It Really Beat GPT-4.1?
Early results suggest that Kimi K2 isn’t just impressive, it’s setting new standards in open-source LLM performance, especially in coding and reasoning tasks.
Here are some key benchmark results (as of July 2025):
Key takeaway:
Kimi k2 outperforms GPT-4.1 and Claude Opus 4 in several coding and reasoning benchmarks.
Excels in agentic tasks, tool use, and complex STEM challenges.
Delivers top-tier results while remaining open-source and cost-effective.
Kimi k2 is not just a chatbot, it’s an agentic AI capable of executing shell commands, editing and deploying code, building interactive websites, integrating with APIs and external tools, and orchestrating multi-step workflows. This makes kimi k2 a powerful tool for automation and complex problem-solving.
2. Tool Use Training
The model was post-trained on synthetic agentic data to simulate real-world scenarios like:
Booking a flight
Cleaning datasets
Building and deploying websites
Self-evaluation using simulated user feedback
3. Open Source + Cost Efficiency
Free access via Kimi’s web/app interface
Model weights available on Hugging Face and GitHub
Inference compatibility with popular engines like vLLM, TensorRT-LLM, and SGLang
API pricing: Much lower than OpenAI and Anthropic—about $0.15 per million input tokens and $2.50 per million output tokens
Real-World Use Cases
Here’s how developers and teams are putting Kimi K2 to work:
Software Development
Generate, refactor, and debug code
Build web apps via natural language
Automate documentation and code reviews
Data Science
Clean and analyze datasets
Generate reports and visualizations
Automate ML pipelines and SQL queries
Business Automation
Automate scheduling, research, and email
Integrate with CRMs and SaaS tools via APIs
Education
Tutor users on technical subjects
Generate quizzes and study plans
Power interactive learning assistants
Research
Conduct literature reviews
Auto-generate technical summaries
Fine-tune for scientific domains
Example: A fintech startup uses Kimi K2 to automate exploratory data analysis (EDA), generate SQL from English, and produce weekly business insights—reducing analyst workload by 30%.
How to Access and Fine-Tune Kimi K2
Getting started with Kimi K2 is surprisingly simple:
Access Options
Web/App: Use the model via Kimi’s chat interface
API: Integrate via Moonshot’s platform (supports agentic workflows and tool use)
Local: Download weights (via Hugging Face or GitHub) and run using:
vLLM
TensorRT-LLM
SGLang
KTransformers
Fine-Tuning
Use LoRA, QLoRA, or full fine-tuning techniques
Customize for your domain or integrate into larger systems
Moonshot and the community are developing open-source tools for production-grade deployment
What the Community Thinks
So far, Kimi K2 has received an overwhelmingly positive response—especially from developers and researchers in open-source AI.
Praise: Strong coding performance, ease of integration, solid benchmarks
Concerns: Like all LLMs, it’s not immune to hallucinations, and there’s still room to grow in reasoning consistency
The release has also stirred broader conversations about China’s growing AI influence, especially in the open-source space.
Final Thoughts
Kimi K2 isn’t just another large language model. It’s a statement—that open-source AI can be state-of-the-art. With powerful agentic capabilities, competitive benchmark performance, and full access to weights and APIs, it’s a compelling choice for developers looking to build serious AI applications.
If you care about performance, customization, and openness, Kimi K2 is worth exploring.
Generative AI research is rapidly transforming the landscape of artificial intelligence, driving innovation in large language models, AI agents, and multimodal systems. Staying current with the latest breakthroughs is essential for data scientists, AI engineers, and researchers who want to leverage the full potential of generative AI. In this comprehensive roundup, we highlight this week’s top 4 research papers in generative AI research, each representing a significant leap in technical sophistication, practical impact, and our understanding of what’s possible with modern AI systems.
The Pulse of Generative AI Research
Generative AI research is at the heart of the artificial intelligence revolution, fueling advances in large language models (LLMs), AI agents, multimodal AI, and domain-specific foundation models. This week’s top research papers in generative AI research exemplify the technical rigor, creativity, and ambition that define the field today. Whether you’re interested in machine learning automation, memory-augmented models, or medical AI, these papers offer deep insights and actionable takeaways for anyone invested in the future of generative AI.
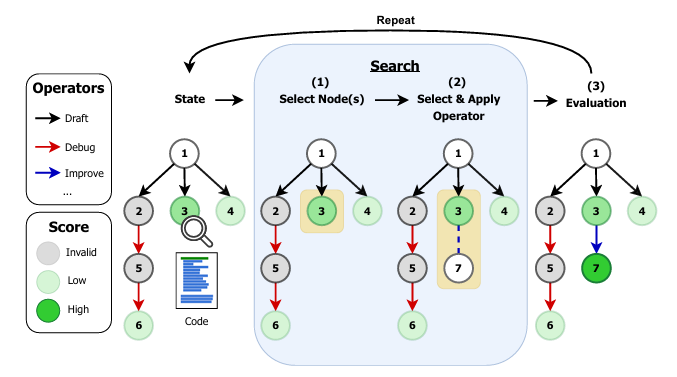
This paper introduces a systematic framework for designing, evaluating, and benchmarking AI research agents—autonomous systems that automate the design, implementation, and optimization of machine learning models. The focus is on the MLE-bench, a challenging benchmark where agents compete in Kaggle-style competitions to solve real-world ML problems. By formalizing research agents as search policies navigating a space of candidate solutions, the study disentangles the impact of search strategies (Greedy, MCTS, Evolutionary) and operator sets (DRAFT, DEBUG, IMPROVE, MEMORY, CROSSOVER) on agent performance.
Key Insights
Operator Design is Critical:
Study finds that the choice and design of operators (the actions agents can take to modify solutions) are more influential than the search policy itself. Operators such as DRAFT, DEBUG, IMPROVE, MEMORY, and CROSSOVER allow agents to iteratively refine solutions, debug code, and recombine successful strategies.
State-of-the-Art Results:
The best combination of search strategy and operator set achieves a Kaggle medal success rate of 47.7% on MLE-bench lite, up from 39.6%. This is a significant improvement in benchmark evaluation for machine learning automation.
Generalization Gap:
The paper highlights the risk of overfitting to validation metrics and the importance of robust evaluation protocols for scalable scientific discovery. The generalization gap between validation and test scores can mislead the search process, emphasizing the need for regularization and robust final-node selection strategies.
AIRA-dojo Framework:
Introduction of AIRA-dojo, a scalable environment for benchmarking and developing AI research agents, supporting reproducible experiments and custom operator design. The framework allows for controlled experiments at scale, enabling systematic exploration of agentic policies and operator sets.
Main Takeaways
AI agents can automate and accelerate the scientific discovery process in machine learning, but their effectiveness hinges on the interplay between search strategies and operator design.
The research underscores the need for rigorous evaluation and regularization to ensure robust, generalizable results in generative AI research.
The AIRA-dojo framework is a valuable resource for the community, enabling systematic exploration of agentic policies and operator sets.
Why It’s Revolutionary
This work advances generative AI research by providing a principled methodology for building and evaluating AI agents that can autonomously explore, implement, and optimize machine learning solutions. It sets a new standard for transparency and reproducibility in agent-based generative AI systems, and the introduction of AIRA-dojo as a benchmarking environment accelerates progress by enabling the community to systematically test and improve AI agents.
GenSI MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
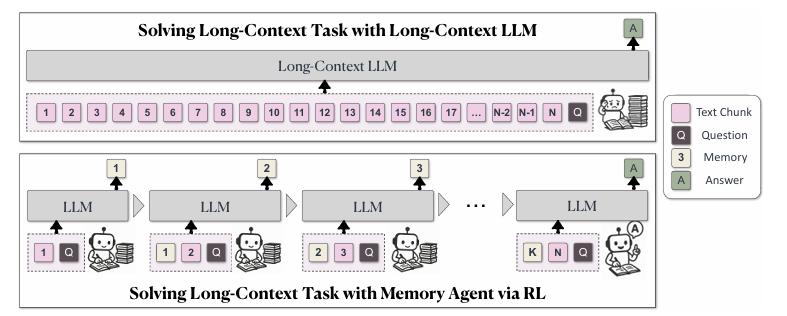
This paper addresses one of the most pressing challenges in generative AI research: enabling large language models (LLMs) to process and reason over extremely long contexts efficiently. The authors introduce MEMAGENT, a novel agent workflow that reads text in segments and updates a fixed-length memory using an overwrite strategy, trained end-to-end with reinforcement learning (RL).
Key Insights
Linear Complexity for Long Contexts:
MEMAGENT achieves nearly lossless performance extrapolation from 8K to 3.5M tokens, maintaining <5% performance loss and 95%+ accuracy on the 512K RULER test. This is a major breakthrough for long-context LLMs and memory-augmented models.
Human-Inspired Memory:
The agent mimics human note-taking by selectively retaining critical information and discarding irrelevant details, enabling efficient long-context reasoning. The memory is a sequence of ordinary tokens inside the context window, allowing the model to flexibly handle arbitrary text lengths while maintaining a linear time complexity during processing.
Multi-Conversation RL Training:
The paper extends the DAPO algorithmfor multi-conversation RL, optimizing memory updates based on verifiable outcome rewards. This enables the model to learn what information to retain and what to discard dynamically.
Empirical Superiority:
MEMAGENT outperforms state-of-the-art long-context LLMs in both in-domain and out-of-domain tasks, including QA, variable tracking, and information extraction. The architecture is compatible with existing transformer-based LLMs, making it a practical solution for real-world applications.
Main Takeaways
Memory-augmented models with RL-trained memory can scale to process arbitrarily long documents with linear computational cost, a major leap for generative AI research.
The approach generalizes across diverse tasks, demonstrating robust zero-shot learning and strong out-of-distribution performance.
MEMAGENT’s architecture is compatible with existing transformer-based LLMs, making it a practical solution for real-world applications.
W hy It’s Revolutionary
By solving the long-context bottleneck in generative AI, MEMAGENT paves the way for LLMs that can handle entire books, complex reasoning chains, and lifelong learning scenarios—key requirements for next-generation AI agents and foundation models. The integration of reinforcement learning for memory management is particularly innovative, enabling models to learn what information to retain and what to discard dynamically.
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
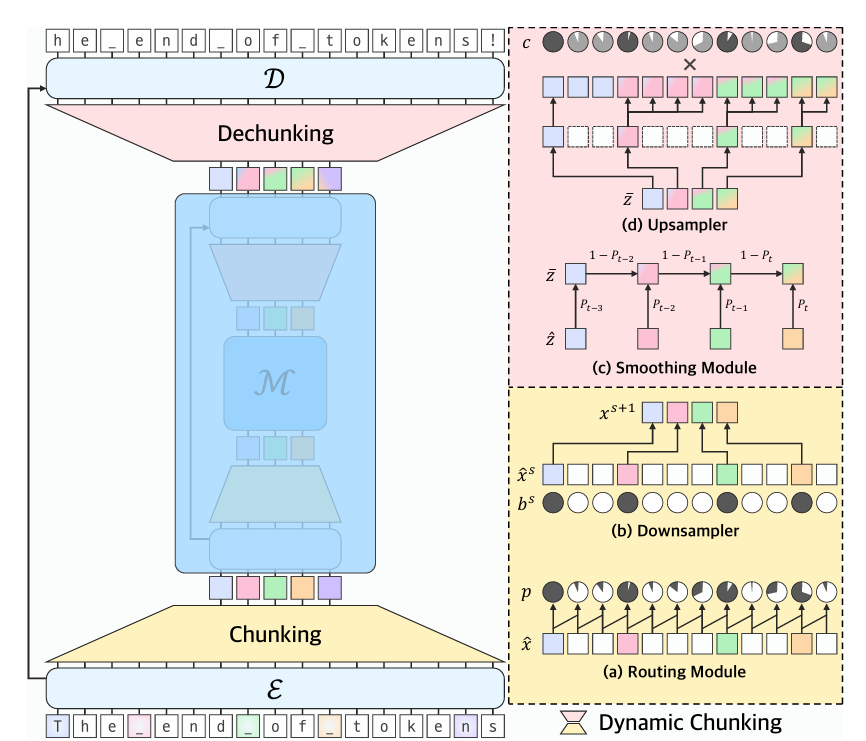
This paper addresses a fundamental limitation in current generative AI research: the reliance on tokenization as a preprocessing step for language models. The authors propose H-Net, a dynamic chunking mechanism that learns content- and context-dependent segmentation strategies end-to-end, replacing the traditional tokenization-LM-detokenization pipeline with a single hierarchical model.
Key Insights
Tokenization-Free Modeling:
H-Net learns to segment raw data into meaningful chunks, outperforming strong BPE-tokenized Transformers at equivalent compute budgets.
Hierarchical Abstraction:
Iterating the hierarchy to multiple stages enables the model to capture multiple levels of abstraction, improving scaling with data and matching the performance of much larger token-based models.
Robustness and Interpretability:
H-Nets show increased robustness to character-level noise and learn semantically coherent boundaries without explicit supervision.
Cross-Language and Modality Gains:
The benefits are even greater for languages and modalities with weak tokenization heuristics (e.g., Chinese, code, DNA), achieving up to 4x improvement in data efficiency.
Main Takeaways
Dynamic chunking enables true end-to-end generative AI models that learn from unprocessed data, eliminating the biases and limitations of fixed-vocabulary tokenization.
H-Net’s architecture is modular and scalable, supporting hybrid and multi-stage designs for diverse data types.
The approach enhances both the efficiency and generalization of foundation models, making it a cornerstone for future generative AI research.
Why It’s Revolutionary
H-Net represents a paradigm shift in generative AI research, moving beyond handcrafted preprocessing to fully learnable, hierarchical sequence modeling. This unlocks new possibilities for multilingual, multimodal, and domain-agnostic AI systems.
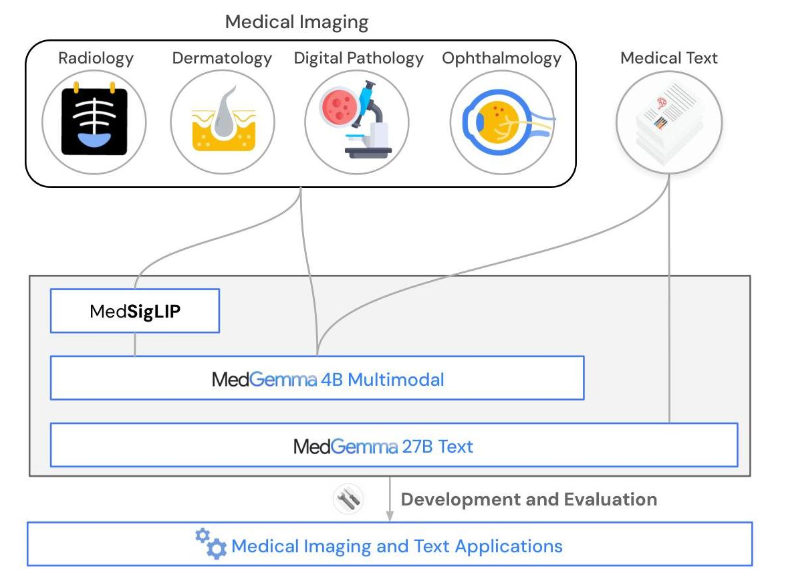
MedGemma: Medical Vision-Language Foundation Models
MedGemma introduces a suite of medical vision-language foundation models based on the Gemma 3 architecture, optimized for advanced medical understanding and reasoning across images and text. The collection includes multimodal and text-only variants, as well as MedSigLIP, a specialized vision encoder.
Key Insights
Domain-Specific Foundation Models:
MedGemma models outperform similar-sized generative models and approach the performance of task-specific models on medical benchmarks. The 4B variant accepts both text and images, excelling at vision question answering, chest X-ray classification, and histopathology analysis.
Fine-Tuning and Adaptability:
MedGemma can be fine-tuned for subdomains, achieving state-of-the-art results in electronic health record retrieval, pneumothorax classification, and histopathology patch classification.
Zero-Shot and Data-Efficient Learning:
MedSigLIP enables strong zero-shot and linear probe performance across multiple medical imaging domains.
Benchmark Evaluation:
MedGemma demonstrates superior performance on medical multimodal question answering, chest X-ray finding classification, and agentic evaluations compared to the base models.
Main Takeaways
MedGemma demonstrates that specialized foundation models can deliver robust, efficient, and generalizable performance in medical AI, a critical area for real-world impact.
The models are openly released, supporting transparency, reproducibility, and community-driven innovation in generative AI research.
MedGemma’s architecture and training methodology set a new benchmark for multimodal AI in healthcare.
Why It’s Revolutionary
By bridging the gap between general-purpose and domain-specific generative AI, MedGemma accelerates the development of trustworthy, high-performance medical AI systems—showcasing the power of foundation models in specialized domains. The model’s ability to integrate multimodal data, support zero-shot and fine-tuned applications, and deliver state-of-the-art performance in specialized tasks demonstrates the versatility and impact of generative AI research.
Conclusion: The Road Ahead for Generative AI Research
Generative AI research is evolving at an extraordinary pace, with breakthroughs in large language models, multimodal AI, and foundation models redefining the boundaries of artificial intelligence. The four papers highlighted this week exemplify the field’s rapid progress toward more autonomous, scalable, and domain-adaptable AI systems.
From agentic search and memory-augmented models to medical foundation models, these advances are not just academic—they are shaping the future of AI in industry, healthcare, science, and beyond. As researchers continue to innovate, we can expect even more breakthroughs in generative AI research, driving the next wave of intelligent, adaptable, and impactful AI solutions.
Q1: What is the significance of memory-augmented models in generative AI research?
Memory-augmented models like MEMAGENT enable LLMs to process arbitrarily long contexts with linear computational cost, supporting complex reasoning and lifelong learning scenarios.
Q2: How do AI agents accelerate machine learning automation?
AI agents automate the design, implementation, and optimization of machine learning models, accelerating scientific discovery and enabling scalable, reproducible research.
Q3: Why are domain-specific foundation models important?
Domain-specific foundation models like MedGemma deliver superior performance in specialized tasks (e.g., medical AI) while retaining general capabilities, supporting both zero-shot and fine-tuned applications.
Q4: Where can I read more about generative AI research?
Visit the Data Science Dojo blog for the latest in generative AI research, technical deep dives, and expert analysis.
Artificial intelligence is evolving fast, and Grok 4, developed by xAI (Elon Musk’s AI company), is one of the most ambitious steps forward. Designed to compete with giants like OpenAI’s GPT-4, Google’s Gemini, and Anthropic’s Claude, Grok 4 brings a unique flavor to the large language model (LLM) space: deep reasoning, multimodal understanding, and real-time integration with live data.
But what exactly is Grok 4? How powerful is it, and what can it really do? In this post, we’ll walk you through Grok 4’s architecture, capabilities, benchmarks, and where it fits into the future of AI.
source: xAi
What is Grok 4?
Grok 4 is the latest LLM from xAI, officially released in July 2025. At its core, Grok 4 is designed for advanced reasoning tasks—math, logic, code, and scientific thinking. Unlike earlier Grok versions, Grok 4 comes in two flavors:
Grok 4 (standard): A powerful single-agent language model.
Grok 4 Heavy: A multi-agent architecture for complex collaborative reasoning (think several AI minds working together on a task).
And yes, it’s big—Grok 4 boasts around 1.7 trillion parameters and was trained with 100× more compute than Grok 2, including heavy reinforcement learning, placing it firmly in the top tier of today’s models.
Technical Architecture and Capabilities
Let’s unpack what makes Grok 4 different from other LLMs.
1. Hybrid Neural Design
Grok 4 uses a modular architecture. That means it has specialized subsystems for tasks like code generation, language understanding, and mathematical reasoning. These modules are deeply integrated but operate with some autonomy—especially in the “Heavy” version, which simulates multi-agent collaboration.
2. Large Context Window
Context windows matter—especially for reasoning over long documents. Grok 4 supports up to 128,000 tokens in-app, and 256,000 tokens via API, allowing for detailed, multi-turn interactions and extended memory.
3. Multimodal AI
Grok 4 isn’t just about text. It can understand and reason over text and images, with voice capabilities as well (it features a British-accented voice assistant called Eve). Future updates are expected to add image generation and deeper visual reasoning.
5. Powered by Colossus
xAI trained Grok 4 using its Colossus supercomputer, which reportedly runs on 200,000 Nvidia GPUs—a serious investment in compute infrastructure.
Key Features That Stand Out
Reasoning & Scientific Intelligence
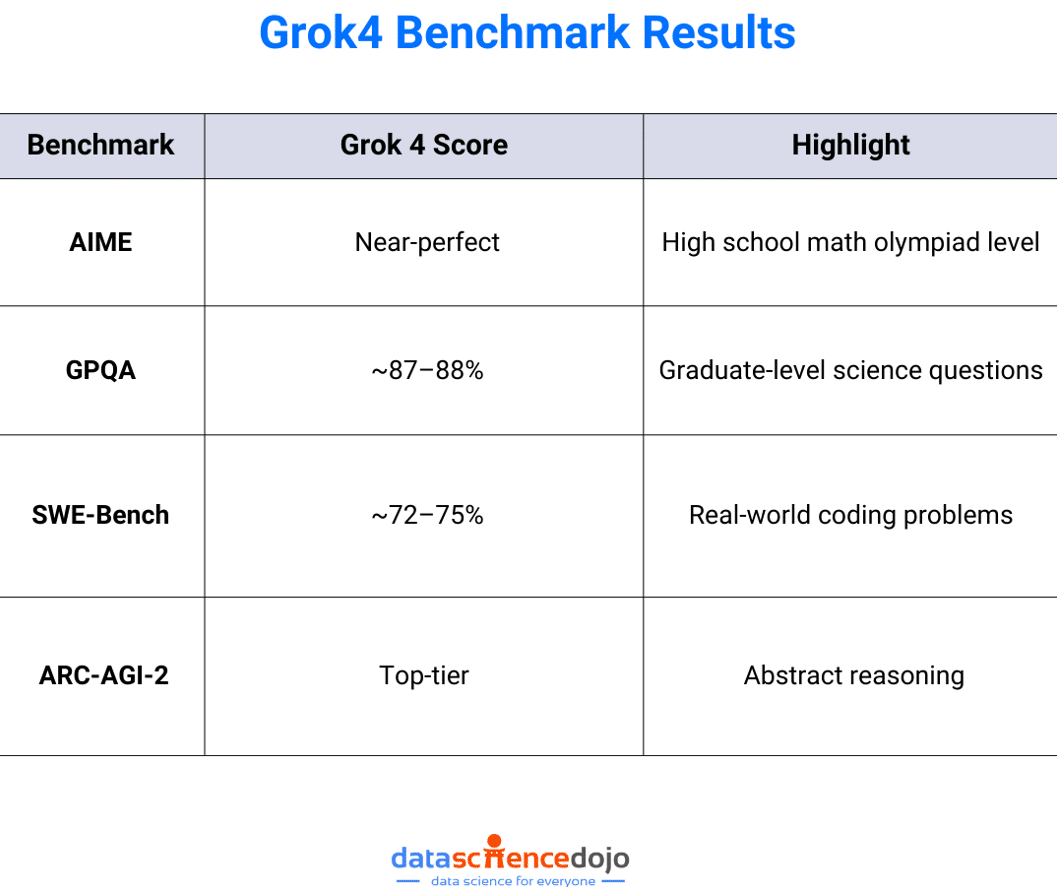
Grok 4 is built for deep thinking. It performs strongly in multi-step math, logic problems, and graduate-level scientific questions. On internal benchmarks like GPQA, AIME, and ARC-AGI, Grok 4 matches or surpasses other frontier models.
Code Generation with Grok 4 Code
The specialized Grok 4 Code variant targets developers. It delivers smart code suggestions, debugging help, and even software design ideas. It scores ~72–75% on SWE-Bench, a benchmark for real-world coding tasks—placing it among the best models for software engineering.
Real-Time Data via X
Here’s something unique: Grok 4 can access real-time data from X (formerly Twitter). That gives it a dynamic edge for tasks like market analysis, news summarization, and live sentiment tracking.
(Note: Despite some speculation, there’s no confirmed integration with live Tesla or SpaceX data.)
Benchmark Performance: Where Grok 4 Shines
Here’s how Grok 4 compares on key LLM benchmarks:
Compared to competitors like GPT-4 and Gemini, Grok 4 is especially strong in math, logic, and coding. The most notable result was from Humanit’s Last Exam, a benchmark comprising of 2500 hand-curated PhD level questions spanning math, physics, chemistry, linguistics and engineering. Grok 4 was able to solve about 38.6% of thw problems
source: xAI
Real-World Use Cases
Whether you’re a data scientist, developer, or researcher, Grok 4 opens up a wide range of possibilities:
Exploratory Data Analysis: Grok 4 can automate EDA, identify patterns, and suggest hypotheses.
Software Development: Generate, review, and optimize code with the Grok 4 Code variant.
Document Understanding: Summarize long documents, extract key insights, and answer questions in context.
Real-Time Analytics: Leverage live data from X for trend analysis, event monitoring, and anomaly detection.
Collaborative Research: In its “Heavy” form, Grok 4 supports multi-agent collaboration on scientific tasks like literature reviews and data synthesis.
Developer Tools and API Access
Developers can tap into Grok 4’s capabilities via APIs. It supports:
Structured outputs (like JSON)
Function calling
Multimodal inputs (text + image)
Voice interaction via integrated assistant (in Grok 4 web app)
The API is accessible via a “SuperGrok” plan ($30/month) for Grok 4 and $300/month for Grok 4 Heavy (SuperGrok Heavy).
Ethics, Bias, and Environmental Impact
No powerful model is without trade-offs. Here’s what to watch:
Bias and Content Moderation: Earlier versions of Grok generated problematic or politically charged content. xAI has since added filters, but content safety remains an active concern.
Accessibility: The price point may limit access for independent researchers and small teams.
Environmental Footprint: Training Grok 4 required massive compute power. xAI’s Colossus supercomputer raises valid questions about energy efficiency and sustainability.
Challenges and Limitations
While Grok 4 is impressive, it’s not without challenges:
Speed: Especially for the multi-agent “Heavy” model, latency can be noticeable.
Visual Reasoning: While it supports images, Grok 4’s vision capabilities still trail behind dedicated models like Gemini or Claude Opus.
Scalability: Managing collaborative agents at scale (in Grok 4 Heavy) is complex and still evolving.
What’s Next for Grok?
xAI has big plans:
Specialized Models: Expect focused versions for coding, multimodal generation, and even video reasoning.
Open-Source Releases: Smaller Grok variants may be open-sourced to support research and transparency.
Human-AI Collaboration: Musk envisions Grok as a step toward AGI, capable of teaming with humans to solve tough scientific and societal problems.
FAQ
Q1: What makes Grok 4 different from previous large language models?
Grok 4’s hybrid, multi-agent architecture and advanced reasoning capabilities set it apart, enabling superior performance in mathematical, coding, and multimodal tasks.
Q2: How does Grok 4 handle real-time data?
Grok 4 integrates live data from platforms like X, supporting real-time analytics and decision-making.
Q3: What are the main ethical concerns with Grok 4?
Unfiltered outputs and potential bias require robust content moderation and ethical oversight.
Q4: Can developers integrate Grok 4 into their applications?
Yes, Grok 4 offers comprehensive API access and documentation for seamless integration.
Q5: What’s next for Grok 4?
xAI plans to release specialized models, enhance multimodal capabilities, and introduce open-source variants to foster community research.
Grok 4 is more than just another LLM—it’s xAI’s bold bet on the future of reasoning-first AI. With cutting-edge performance in math, code, and scientific domains, Grok 4 is carving out a unique space in the AI ecosystem.
Yes, it has limitations. But if you’re building advanced AI applications or exploring the frontiers of human-machine collaboration, Grok 4 is a model to watch—and maybe even build with.
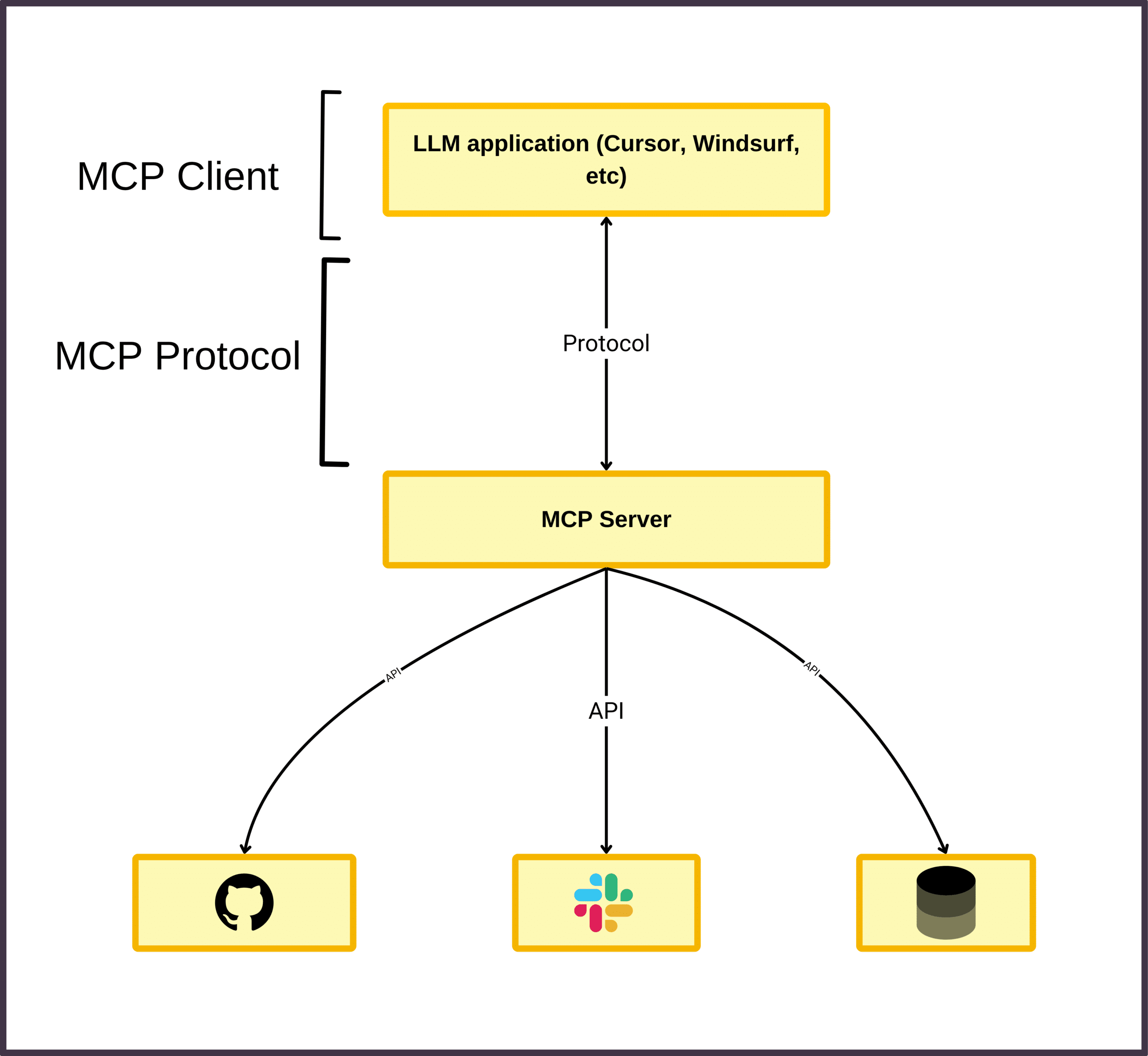
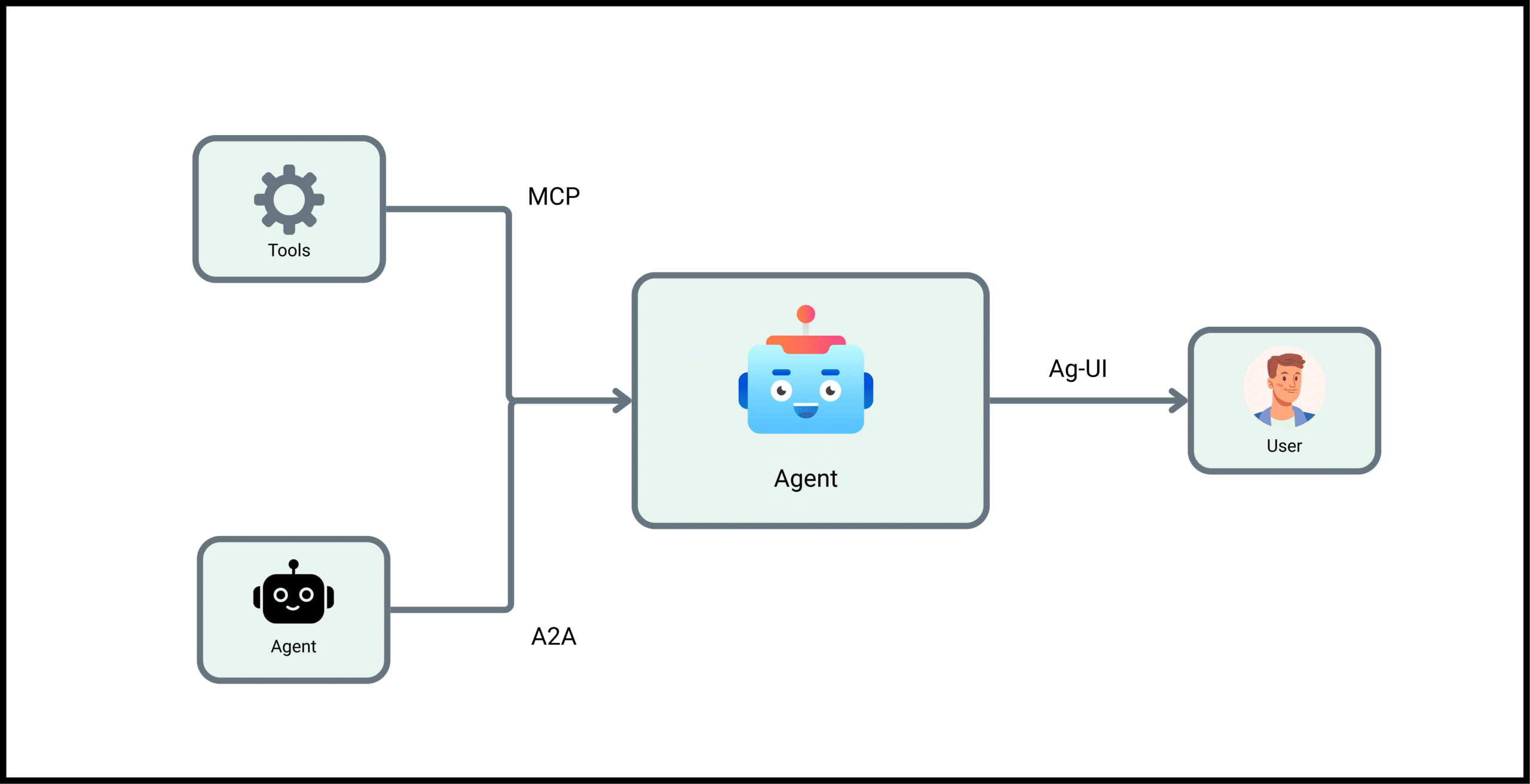
Model Context Protocol (MCP) is rapidly emerging as the foundational layer for intelligent, tool-using AI systems, especially as organizations shift from prompt engineering to context engineering. Developed by Anthropic and now adopted by major players like OpenAI and Microsoft, MCP provides a standardized, secure way for large language models (LLMs) and agentic systems to interface with external APIs, databases, applications, and tools. It is revolutionizing how developers scale, govern, and deploy context-aware AI applications at the enterprise level.
As the world embraces agentic AI, where models don’t just generate text but interact with tools and act autonomously, MCP ensures those actions are interoperable, auditable, and secure, forming the glue that binds agents to the real world.
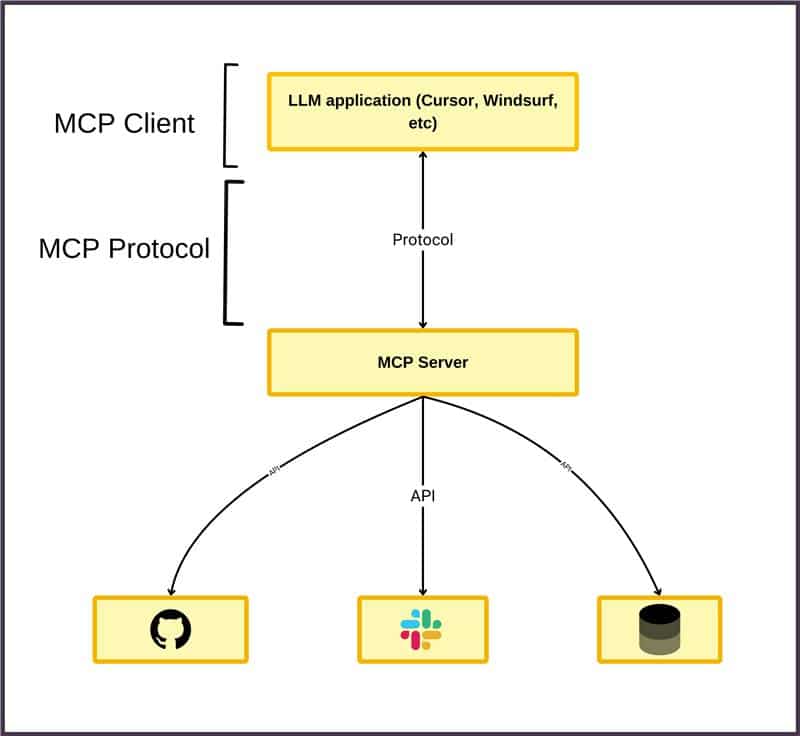
Model Context Protocol is an open specification that standardizes the way LLMs and AI agents connect with external systems like REST APIs, code repositories, knowledge bases, cloud applications, or internal databases. It acts as a universal interface layer, allowing models to ground their outputs in real-world context and execute tool calls safely.
Key Objectives of MCP:
Standardize interactions between models and external tools
Enable secure, observable, and auditable tool usage
Reduce integration complexity and duplication
Promote interoperability across AI vendors and ecosystems
Unlike proprietary plugin systems or vendor-specific APIs, MCP is model-agnostic and language-independent, supporting multiple SDKs including Python, TypeScript, Java, Swift, Rust, Kotlin, and more.
Why MCP Matters: Solving the M×N Integration Problem
Before MCP, integrating each of M models (agents, chatbots, RAG pipelines) with N tools (like GitHub, Notion, Postgres, etc.) required M × N custom connections—leading to enormous technical debt.
MCP collapses this to M + N:
Each AI agent integrates one MCP client
Each tool or data system provides one MCP server
All components communicate using a shared schema and protocol
This pattern is similar to USB-C in hardware: a unified protocol for any model to plug into any tool, regardless of vendor.
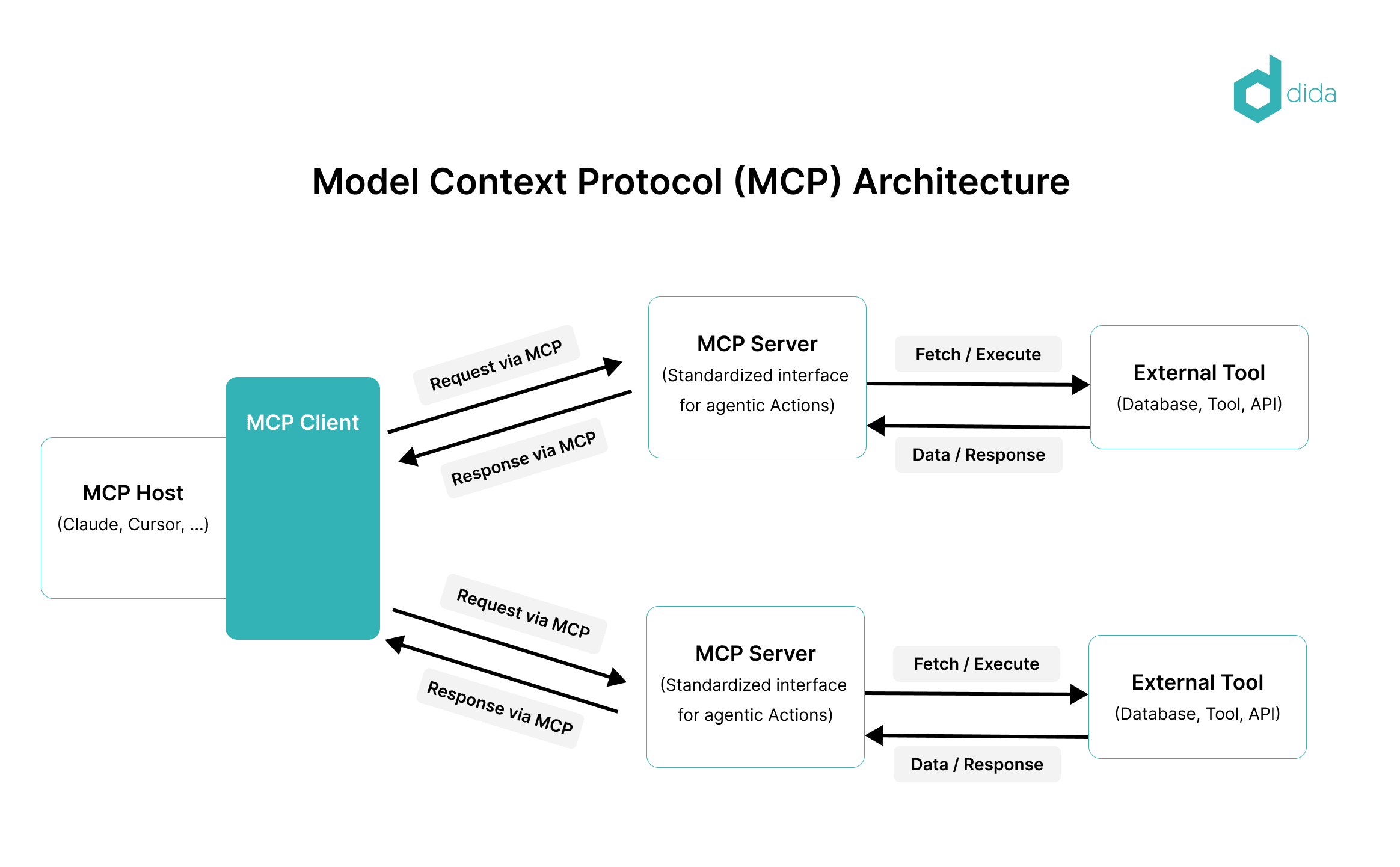
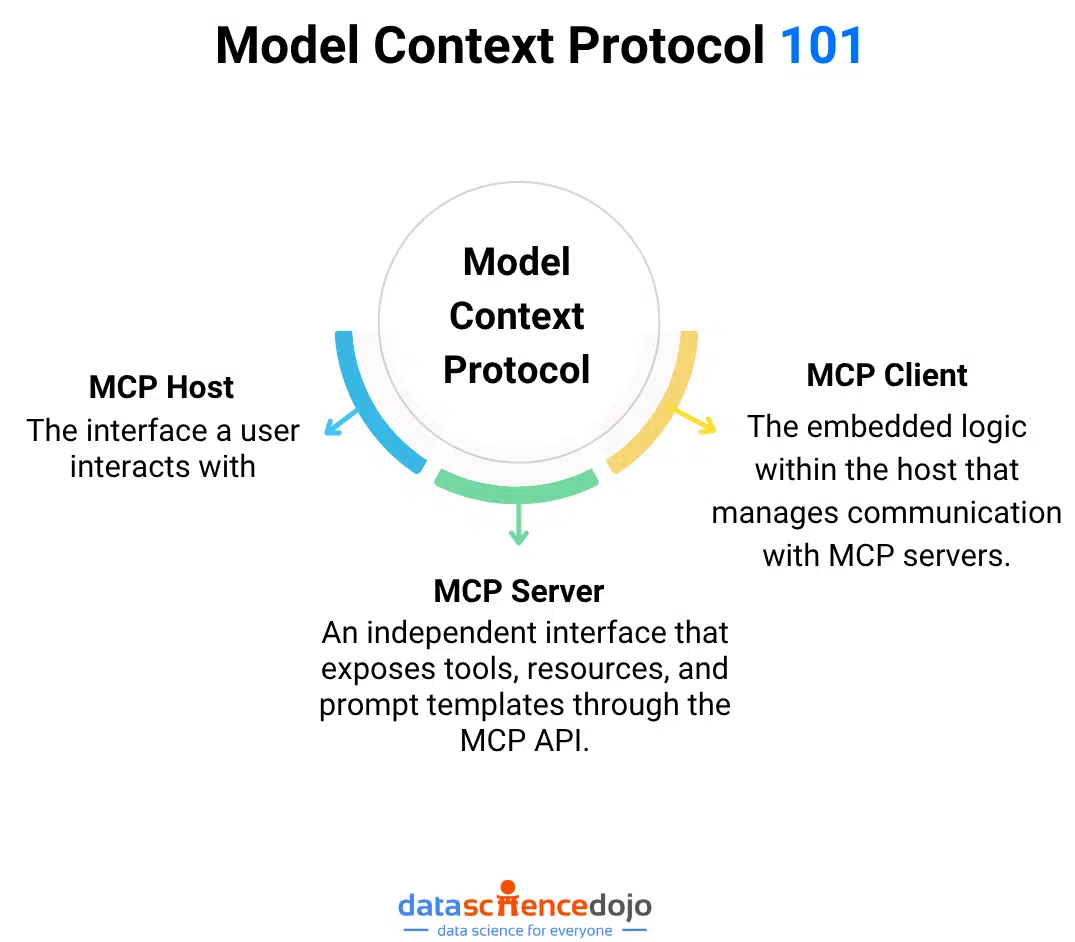
Architecture: Clients, Servers, and Hosts
source: dida.do
MCP is built around a structured host–client–server architecture:
1. Host
The interface a user interacts with—e.g., an IDE, a chatbot UI, a voice assistant.
2. Client
The embedded logic within the host that manages communication with MCP servers. It mediates requests from the model and sends them to the right tools.
3. Server
An independent interface that exposes tools, resources, and prompt templates through the MCP API.
Supported Transports:
stdio: For local tool execution (high trust, low latency)
HTTP/SSE: For cloud-native or remote server integration
Example Use Case:
An AI coding assistant (host) uses an MCP client to connect with:
A GitHub MCP server to manage issues or PRs
A CI/CD MCP server to trigger test pipelines
A local file system server to read/write code
All these interactions happen via a standard protocol, with complete traceability.
Key Features and Technical Innovations
A. Unified Tool and Resource Interfaces
Tools: Executable functions (e.g., API calls, deployments)
Resources: Read-only data (e.g., support tickets, product specs)
Prompts: Model-guided instructions on how to use tools or retrieve data effectively
This separation makes AI behavior predictable, modular, and controllable.
B. Structured Messaging Format
MCP defines strict message types:
user, assistant, tool, system, resource
Each message is tied to a role, enabling:
Explicit context control
Deterministic tool invocation
Preventing prompt injection and role leakage
C. Context Management
MCP clients handle context windows efficiently:
Trimming token history
Prioritizing relevant threads
Integrating summarization or vector embeddings
This allows agents to operate over long sessions, even with token-limited models.
D. Security and Governance
MCP includes:
OAuth 2.1, mTLS for secure authentication
Role-based access control (RBAC)
Tool-level permission scopes
Signed, versioned components for supply chain security
E. Open Extensibility
Dozens of public MCP servers now exist for GitHub, Slack, Postgres, Notion, and more.
SDKs available in all major programming languages
Supports custom toolchains and internal infrastructure
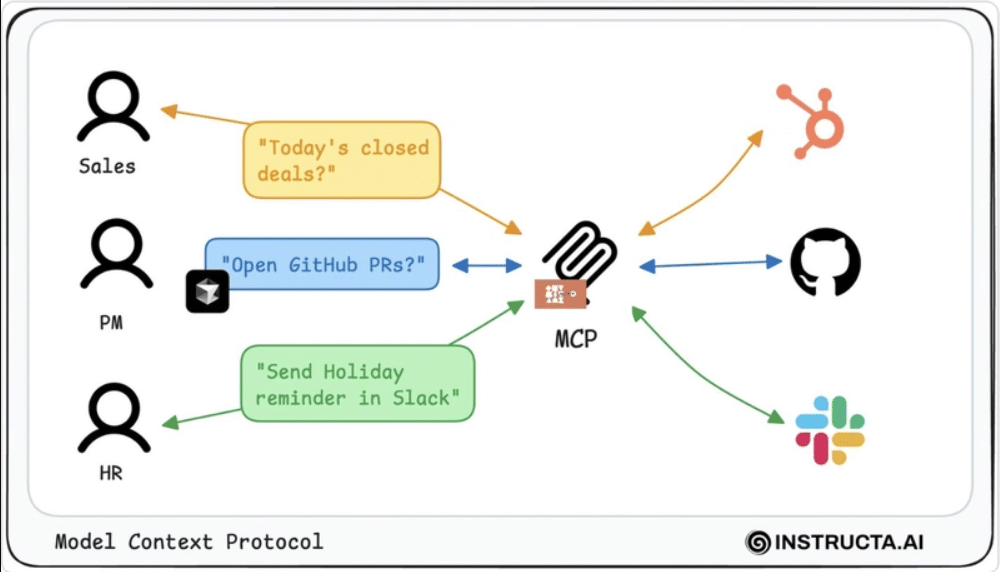
Model Context Protocol in Practice: Enterprise Use Cases
source: Instructa.ai
1. AI Assistants
LLMs access user history, CRM data, and company knowledge via MCP-integrated resources—enabling dynamic, contextual assistance.
2. RAG Pipelines
Instead of static embedding retrieval, RAG agents use MCP to query live APIs or internal data systems before generating responses.
3. Multi-Agent Workflows
Agents delegate tasks to other agents, tools, or humans, all via standardized MCP messages—enabling team-like behavior.
4. Developer Productivity
LLMs in IDEs use MCP to:
Review pull requests
Run tests
Retrieve changelogs
Deploy applications
5. AI Model Evaluation
Testing frameworks use MCP to pull logs, test cases, and user interactions—enabling automated accuracy and safety checks.
Challenges, Limitations, and the Future of Model Context Protocol
Known Challenges:
Managing long context histories and token limits
Multi-agent state synchronization
Server lifecycle/versioning and compatibility
Future Innovations:
Embedding-based context retrieval
Real-time agent collaboration protocols
Cloud-native standards for multi-vendor compatibility
Secure agent sandboxing for tool execution
As agentic systems mature, MCP will likely evolve into the default interface layer for enterprise-grade LLM deployment, much like REST or GraphQL for web apps.
FAQ
Q: What is the main benefit of MCP for enterprises?
A: MCP standardizes how AI models connect to tools and data, reducing integration complexity, improving security, and enabling scalable, context-aware AI solutions.
Q: How does MCP improve security?
A: MCP enforces authentication, authorization, and boundary controls, protecting against prompt/tool injection and unauthorized access.
Q: Can MCP be used with any LLM or agentic AI system?
A: Yes, MCP is model-agnostic and supported by major vendors (Anthropic, OpenAI), with SDKs for multiple languages.
Q: What are the best practices for deploying MCP?
A: Use vector databases, optimize context windows, sandbox local servers, and regularly audit/update components for security.
Conclusion:
Model Context Protocol isn’t just another spec, it’s the API standard for agentic intelligence. It abstracts away complexity, enforces governance, and empowers AI systems to operate effectively across real-world tools and systems.
Want to build secure, interoperable, and production-grade AI agents?
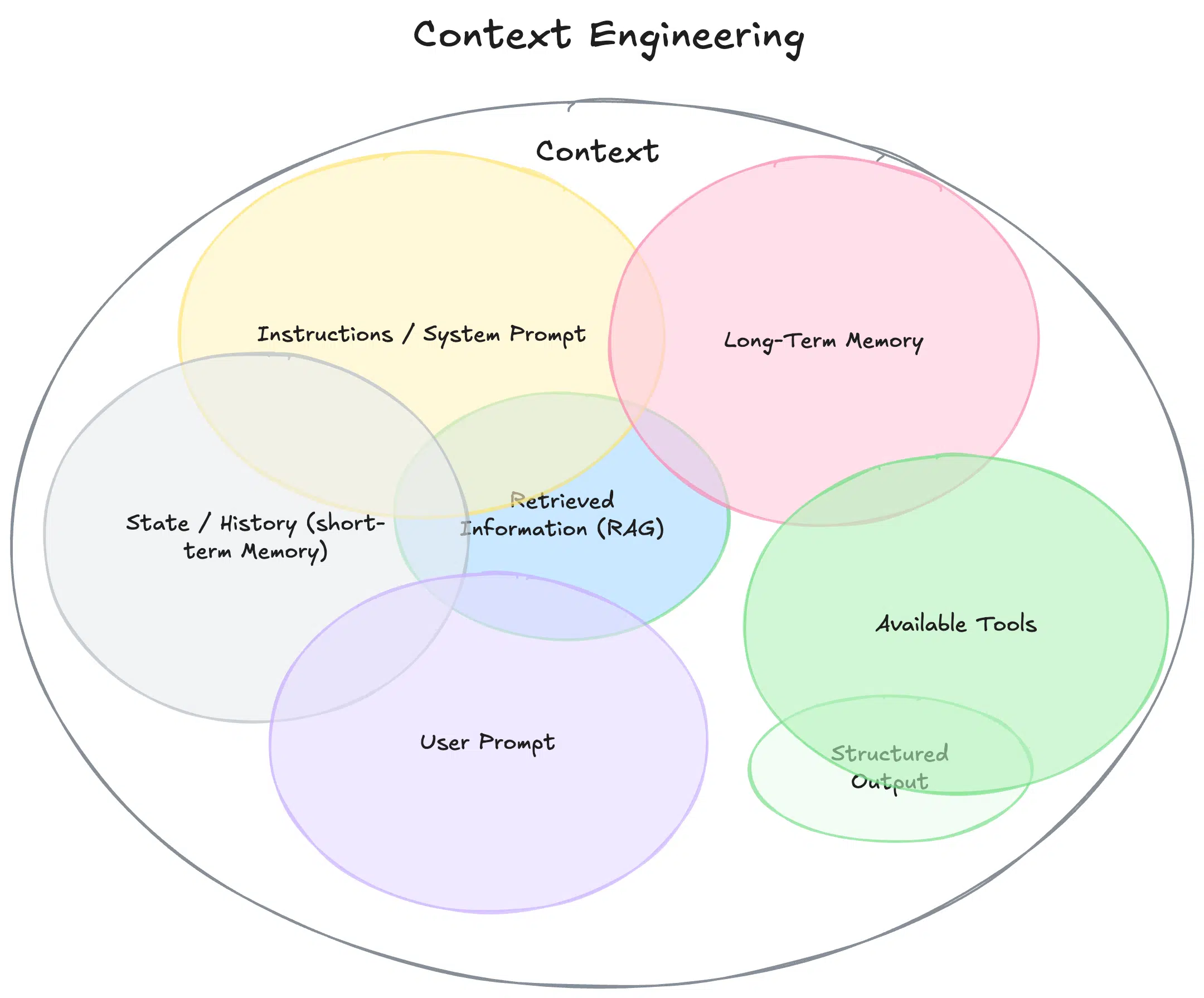
Context engineering is quickly becoming the new foundation of modern AI system design, marking a shift away from the narrow focus on prompt engineering. While prompt engineering captured early attention by helping users coax better outputs from large language models (LLMs), it is no longer sufficient for building robust, scalable, and intelligent applications. Today’s most advanced AI systems—especially those leveraging Retrieval-Augmented Generation (RAG) and agentic architectures—demand more than clever prompts. They require the deliberate design and orchestration of context: the full set of information, memory, and external tools that shape how an AI model reasons and responds.
This blog explores why context engineering is now the core discipline for AI engineers and architects. You’ll learn what it is, how it differs from prompt engineering, where it fits in modern AI workflows, and how to implement best practices—whether you’re building chatbots, enterprise assistants, or autonomous AI agents.
source: Philschmid
What is Context Engineering?
Context engineering is the systematic design, construction, and management of all information—both static and dynamic—that surrounds an AI model during inference. While prompt engineering optimizes what you say to the model, context engineering governs what the model knows when it generates a response.
In practical terms, context engineering involves:
Assembling system instructions, user preferences, and conversation history
Dynamically retrieving and integrating external documents or data
Managing tool schemas and API outputs
Structuring and compressing information to fit within the model’s context window
In short, context engineering expands the scope of model interaction to include everything the model needs to reason accurately and perform autonomously.
Why Context Engineering Matters in Modern AI
The rise of large language models and agentic AI has shifted the focus from model-centric optimization to context-centric architecture. Even the most advanced LLMs are only as good as the context they receive. Without robust context engineering, AI systems are prone to hallucinations, outdated answers, and inconsistent performance.
Context engineering solves foundational AI problems:
Hallucinations → Reduced via grounding in real, external data
Statelessness → Replaced by memory buffers and stateful user modelling
Stale knowledge → Solved via retrieval pipelines and dynamic knowledge injection
Weak personalization → Addressed by user state tracking and contextual preference modeling
Security and compliance risks → Mitigated via context sanitization and access controls
As Sundeep Teki notes, “The most capable models underperform not due to inherent flaws, but because they are provided with an incomplete, ‘half-baked view of the world’.” Context engineering fixes this by ensuring AI models have the right knowledge, memory, and tools to deliver meaningful results.
Context Engineering vs. Prompt Engineering
While prompt engineering is about crafting the right question, context engineering is about ensuring the AI has the right environment and information to answer that question. Every time, in every scenario.
Dynamically assembles all relevant background- the prompt, retrieved docs, conversation history, tool metadata, internal memory, and more
Supports multi-turn, stateful, and agentic workflows
Enables retrieval of external knowledge and integration with APIs
In short, prompt engineering is a subset of context engineering. As AI systems become more complex, context engineering becomes the primary differentiator for robust, production-grade solutions.
The Pillars of Context Engineering
To build effective context engineering pipelines, focus on these core pillars:
1. Dynamic Context Assembly
Context is built on the fly, evolving as conversations or tasks progress. This includes retrieving relevant documents, maintaining memory, and updating user state.
2. Comprehensive Context Injection
The model should receive:
Instructions (system + role-based)
User input (raw + refined)
Retrieved documents
Tool output / API results
Prior conversation turns
Memory embeddings
3. Context Sharing
In multi-agent systems, context must be passed across agents to maintain task continuity and semantic alignment. This requires structured message formats, memory synchronization, and agent protocols (e.g., A2A protocol).
4. Context Window Management
With fixed-size token limits (e.g., 32K, 100K, 1M), engineers must compress and prioritize information intelligently using:
Retrieval-Augmented Generation (RAG) is the foundational pattern of context engineering. RAG combines the static knowledge of LLMs with dynamic retrieval from external knowledge bases, enabling AI to “look up” relevant information before generating a response.
Documents are chunked and embedded into a vector database.
Retrieval:
At query time, the system finds the most semantically relevant chunks.
Augmentation:
Retrieved context is concatenated with the prompt and fed to the LLM.
Generation:
The model produces a grounded, context-aware response.
Benefits of RAG in Context Engineering:
Reduces hallucinations
Enables up-to-date, domain-specific answers
Provides source attribution
Scales to enterprise knowledge needs
Advanced Context Engineering Techniques
1. Agentic RAG
Embed RAG into multi-step agent loops with planning, tool use, and reflection. Agents can:
Search documents
Summarize or transform data
Plan workflows
Execute via tools or APIs
This is the architecture behind assistant platforms like AutoGPT, BabyAGI, and Ejento.
2. Context Compression
With million-token context windows, simply stuffing more data is inefficient. Use proxy models or scoring functions (e.g., Sentinel, ContextRank) to:
Prune irrelevant context
Generate summaries
Optimize token usage
3. Graph RAG
For structured enterprise data, Graph RAG retrieves interconnected entities and relationships from knowledge graphs, enabling multi-hop reasoning and richer, more accurate responses.
Enterprises often struggle with knowledge fragmented across countless silos: Confluence, Jira, SharePoint, Slack, CRMs, and various databases. Context engineering provides the architecture to unify these disparate sources. An enterprise AI assistant can use a multi-agent RAG system to query a Confluence page, pull a ticket status from Jira, and retrieve customer data from a CRM to answer a complex query, presenting a single, unified, and trustworthy response.
Developer Platforms
The next evolution of coding assistants is moving beyond simple autocomplete. Systems are being built that have full context of an entire codebase, integrating with Language Server Protocols (LSP) to understand type errors, parsing production logs to identify bugs, and reading recent commits to maintain coding style. These agentic systems can autonomously write code, create pull requests, and even debug issues based on a rich, real-time understanding of the development environment.
Hyper-Personalization
In sectors like e-commerce, healthcare, and finance, deep context is enabling unprecedented levels of personalization. A financial advisor bot can provide tailored advice by accessing a user’s entire portfolio, their stated risk tolerance, and real-time market data. A healthcare assistant can offer more accurate guidance by considering a patient’s full medical history, recent lab results, and even data from wearable devices.
Best Practices for Context Engineering
source: Langchain
Treat Context as a Product:
Version control, quality checks, and continuous improvement.
Start with RAG:
Use RAG for external knowledge; fine-tune only when necessary.
Structure Prompts Clearly:
Separate instructions, context, and queries for clarity.
Leverage In-Context Learning:
Provide high-quality examples in the prompt.
Iterate Relentlessly:
Experiment with chunking, retrieval, and prompt formats.
Monitor and Benchmark:
Use hybrid scorecards to track both AI quality and engineering velocity.
More context isn’t always better—balance breadth and relevance.
Context Consistency:
Dynamic updates and user corrections require robust context refresh logic.
Security:
Guard against prompt injection, data leakage, and unauthorized tool use.
Scaling Context:
As context windows grow, efficient compression and navigation become critical.
Ethics and Privacy:
Context engineering must address data privacy, bias, and responsible AI use.
Emerging Trends:
Context learning systems that adapt context strategies automatically
Context-as-a-service platforms
Multimodal context (text, audio, video)
Contextual AI ethics frameworks
Frequently Asked Questions (FAQ)
Q: How is context engineering different from prompt engineering?
A: Prompt engineering is about crafting the immediate instruction for an AI model. Context engineering is about assembling all the relevant background, memory, and tools so the AI can respond effectively—across multiple turns and tasks.
Q: Why is RAG important in context engineering?
A: RAG enables LLMs to access up-to-date, domain-specific knowledge by retrieving relevant documents at inference time, reducing hallucinations and improving accuracy.
Q: What are the biggest challenges in context engineering?
A: Managing context window limits, ensuring context quality, maintaining security, and scaling context across multimodal and multi-agent systems.
Q: What tools and frameworks support context engineering?
A: Popular frameworks include LangChain, LlamaIndex, which offer orchestration, memory management, and integration with vector databases.
Conclusion: The Future is Context-Aware
Context engineering is the new foundation for building intelligent, reliable, and enterprise-ready AI systems. By moving beyond prompt engineering and embracing dynamic, holistic context management, organizations can unlock the full potential of LLMs and agentic AI.
Open source tools for agentic AI are transforming how organizations and developers build intelligent, autonomous agents. At the forefront of the AI revolution, open source tools for agentic AI development enable rapid prototyping, transparent collaboration, and scalable deployment of agentic systems across industries. In this comprehensive guide, we’ll explore the most current and trending open source tools for agentic AI development, how they work, why they matter, and how you can leverage them to build the next generation of autonomous AI solutions.
What Are Open Source Tools for Agentic AI Development?
Open source tools for agentic AI are frameworks, libraries, and platforms that allow anyone to design, build, test, and deploy intelligent agents—software entities that can reason, plan, act, and collaborate autonomously. These tools are freely available, community-driven, and often integrate with popular machine learning, LLM, and orchestration ecosystems.
Key features:
Modularity:
Build agents with interchangeable components (memory, planning, tool use, communication).
Interoperability:
Integrate with APIs, databases, vector stores, and other agents.
Transparency:
Access source code for customization, auditing, and security.
Community Support:
Benefit from active development, documentation, and shared best practices.
Why Open Source Tools for Agentic AI Development Matter
Accelerated Innovation:
Lower the barrier to entry, enabling rapid experimentation and iteration.
Cost-Effectiveness:
No licensing fees or vendor lock-in—open source tools for agentic AI development are free to use, modify, and deploy at scale.
Security and Trust:
Inspect the code, implement custom guardrails, and ensure compliance with industry standards.
Scalability:
Many open source tools for agentic AI development are designed for distributed, multi-agent systems, supporting everything from research prototypes to enterprise-grade deployments.
Ecosystem Integration:
Seamlessly connect with popular LLMs, vector databases, cloud platforms, and MLOps pipelines.
The Most Trending Open Source Tools for Agentic AI Development
Below is a curated list of the most impactful open source tools for agentic AI development in 2025, with actionable insights and real-world examples.
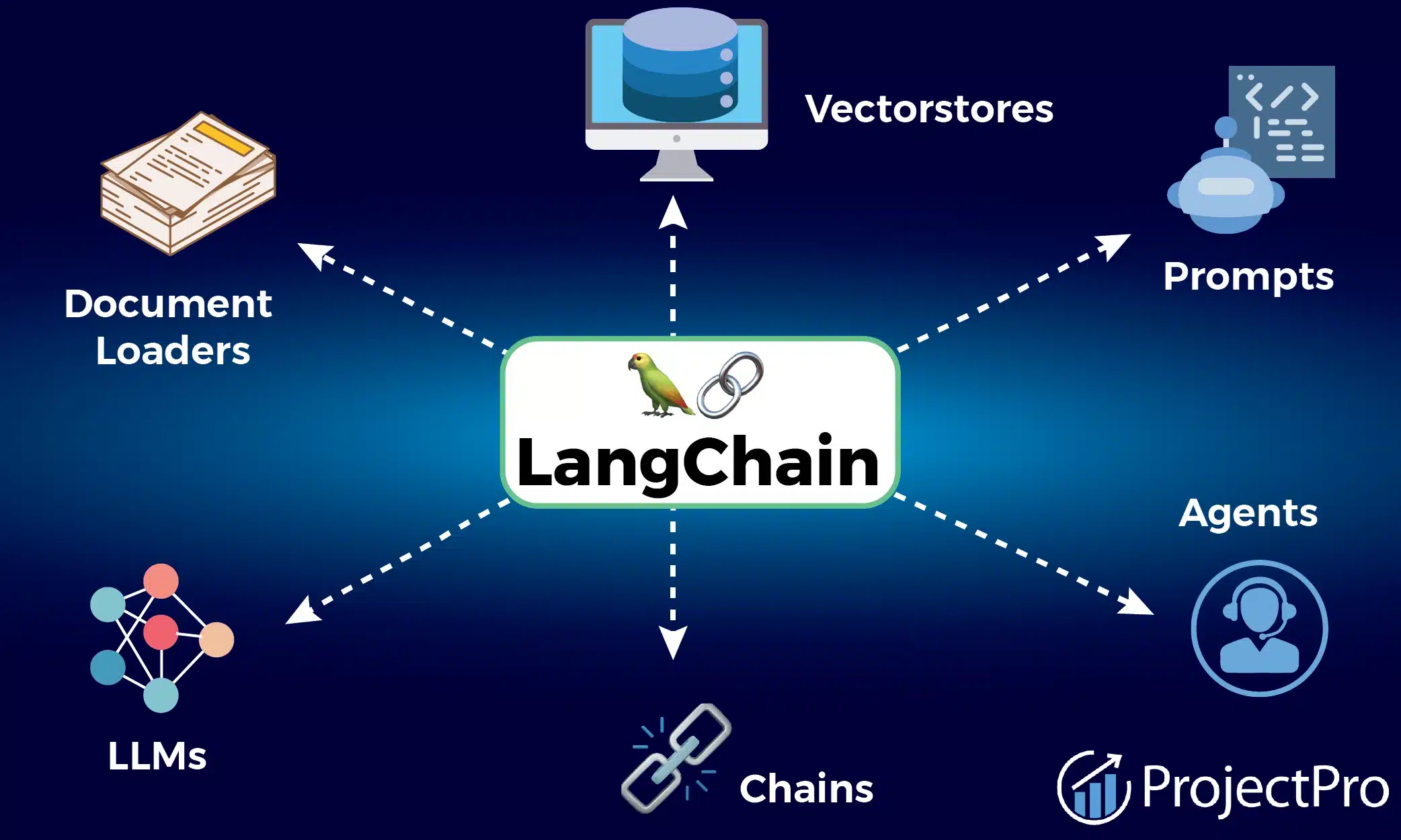
1. LangChain
source: ProjectPro
What it is:
The foundational Python/JS framework for building LLM-powered applications and agentic workflows.
Key features:
Modular chains, memory, tool integration, agent orchestration, support for vector databases, and prompt engineering.
Use case:
Build custom agents that can reason, retrieve context, and interact with APIs.
Ensure compatibility with your preferred LLMs, vector stores, and APIs.
Community and Documentation:
Look for active projects with robust documentation and support.
Security and Compliance:
Open source means you can audit and customize for your organization’s needs.
Real-World Examples: Open Source Tools for Agentic AI Development in Action
Healthcare:
Use LlamaIndex and LangChain to build agents that retrieve and summarize patient records for clinical decision support.
Finance:
Deploy CrewAI and AutoGen for fraud detection, compliance monitoring, and risk assessment.
Customer Service:
Integrate SuperAGI and LangFlow to automate multi-channel support with context-aware agents.
Frequently Asked Questions (FAQ)
Q1: What are the advantages of using open source tools for agentic AI development?
A: Open source tools for agentic AI development offer transparency, flexibility, cost savings, and rapid innovation. They allow you to customize, audit, and scale agentic systems without vendor lock-in.
Q2: Can I use open source tools for agentic AI development in production?
A: Yes. Many open source tools for agentic AI development (e.g., LangChain, LlamaIndex, SuperAGI) are production-ready and used by enterprises worldwide.
Q3: How do I get started with open source tools for agentic AI development?
A: Start by identifying your use case, exploring frameworks like LangChain or CrewAI, and leveraging community tutorials and documentation. Consider enrolling in the Agentic AI Bootcamp for hands-on learning.
Conclusion: Start Building with Open Source Tools for Agentic AI Development
Open source tools for agentic AI development are democratizing the future of intelligent automation. Whether you’re a developer, data scientist, or business leader, these tools empower you to build, orchestrate, and scale autonomous agents for real-world impact. Explore the frameworks, join the community, and start building the next generation of agentic AI today.
Agentic AI communication protocols are at the forefront of redefining intelligent automation. Unlike traditional AI, which often operates in isolation, agentic AI systems consist of multiple autonomous agents that interact, collaborate, and adapt to complex environments. These agents, whether orchestrating supply chains, powering smart homes, or automating enterprise workflows, must communicate seamlessly to achieve shared goals.
But how do these agents “talk” to each other, coordinate actions, and access external tools or data? The answer lies in robust communication protocols. Just as the internet relies on TCP/IP to connect billions of devices, agentic AI depends on standardized protocols to ensure interoperability, security, and scalability.
In this blog, we will explore the leading agentic AI communication protocols, including MCP, A2A, and ACP, as well as emerging standards, protocol stacking strategies, implementation challenges, and real-world applications. Whether you’re a data scientist, AI engineer, or business leader, understanding these protocols is essential for building the next generation of intelligent systems.
What Are Agentic AI Communication Protocols?
Agentic AI communication protocols are standardized rules and message formats that enable autonomous agents to interact with each other, external tools, and data sources. These protocols ensure that agents, regardless of their underlying architecture or vendor, can:
Discover and authenticate each other
Exchange structured information
Delegate and coordinate tasks
Access real-time data and external APIs
Maintain security, privacy, and observability
Without these protocols, agentic systems would be fragmented, insecure, and difficult to scale, much like the early days of computer networking.
Legacy Protocols That Paved the Way:
Before agentic ai communication protocols, there were legacy communication protocols, such as KQML and FIPA-ACL, which were developed to enable autonomous software agents to exchange information, coordinate actions, and collaborate within distributed systems. Their main purpose was to establish standardized message formats and interaction rules, ensuring that agents, often built by different developers or organizations, could interoperate effectively. These protocols played a foundational role in advancing multi-agent research and applications, setting the stage for today’s more sophisticated and scalable agentic AI communication standards. Now that we have a brief idea on what laid the foundation for the agentic ai communication protocols we see so much these days, let’s dive deep into some of the most used ones.
Deep Dive: MCP, A2A, and ACP Explained
MCP (Model Context Protocol)
Overview:
MCP, or Model Context Protocol, one of the most popular agentic ai communication protocol, is designed to standardize how AI models, especially large language models (LLMs), connect to external tools, APIs, and data sources. Developed by Anthropic, MCP acts as a universal “adapter,” allowing models to ground their responses in real-time context and perform actions beyond text generation.
Key Features:
Universal integration with APIs, databases, and tools
Secure, permissioned access to external resources
Context-aware responses for more accurate outputs
Open specification for broad developer adoption
Use Cases:
Real-time data retrieval (e.g., weather, stock prices)
Enterprise knowledge base access
Automated document analysis
IoT device control
Comparison to Legacy Protocols:
Legacy agent communication protocols like FIPA-ACL and KQML focused on structured messaging but lacked the flexibility and scalability needed for today’s LLM-driven, cloud-native environments. MCP’s open, extensible design makes it ideal for modern multi-agent systems.
Learn more about context-aware agentic applications in our LangGraph tutorial.
A2A (Agent-to-Agent Protocol)
Overview:
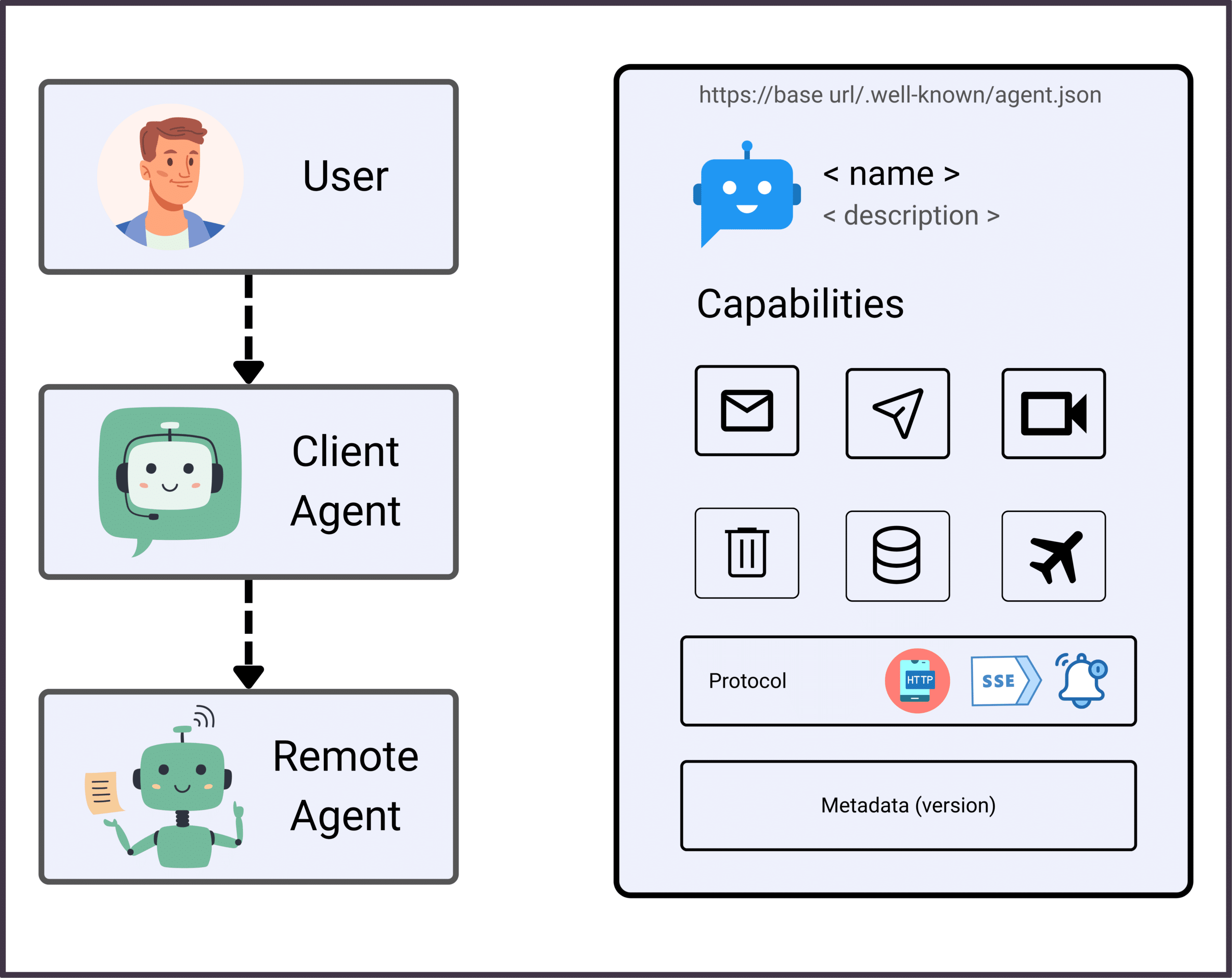
A2A, or Agent-to-Agent Protocol, is an open standard (spearheaded by Google) for direct communication between autonomous agents. It enables agents to discover each other, advertise capabilities, negotiate tasks, and collaborate—regardless of platform or vendor.
Key Features:
Agent discovery via “agent cards”
Standardized, secure messaging (JSON, HTTP/SSE)
Capability negotiation and delegation
Cross-platform, multi-vendor support
Use Cases:
Multi-agent collaboration in enterprise workflows
Cross-platform automation (e.g., integrating agents from different vendors)
Federated agent ecosystems
Comparison to Legacy Protocols:
While legacy protocols provided basic messaging, A2A introduces dynamic discovery and negotiation, making it suitable for large-scale, heterogeneous agent networks.
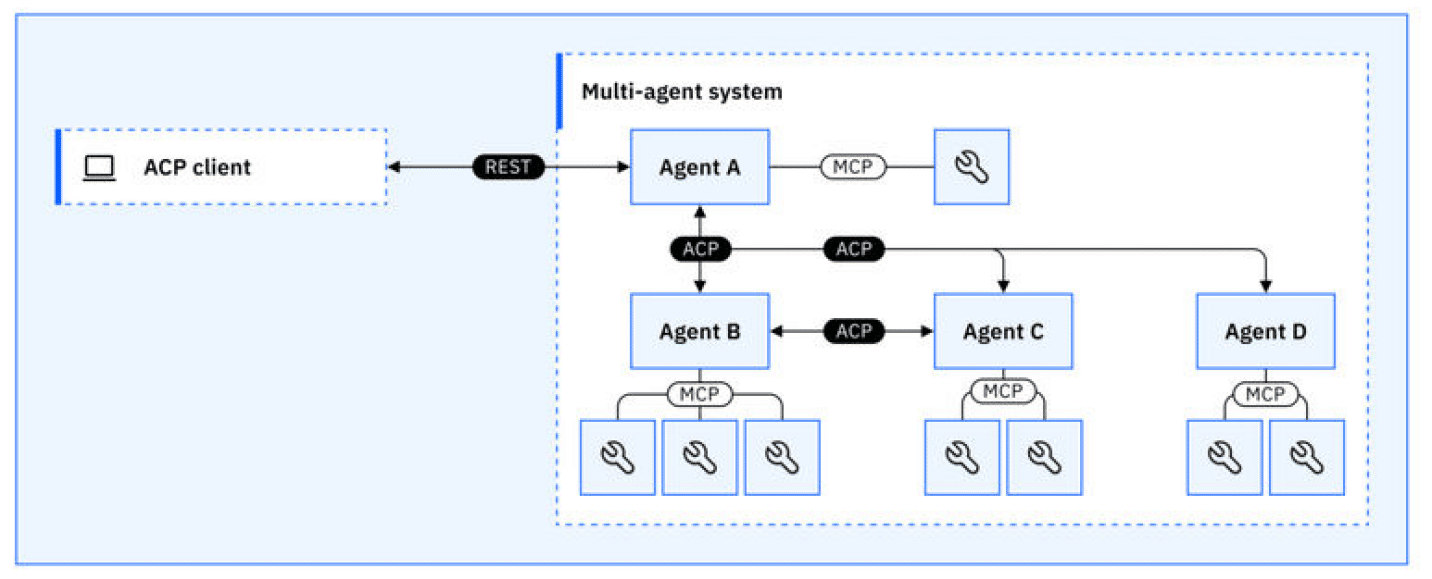
ACP (Agent Communication Protocol)
Overview:
ACP, developed by IBM, focuses on orchestrating workflows, delegating tasks, and maintaining state across multiple agents. It acts as the “project manager” of agentic systems, ensuring agents work together efficiently and securely.
source: IBM
Key Features:
Workflow orchestration and task delegation
Stateful sessions and observability
Structured, semantic messaging
Enterprise integration and auditability
Use Cases:
Enterprise automation (e.g., HR, finance, IT operations)
Security incident response
Research coordination
Supply chain management
Comparison to Legacy Protocols:
Agent Communication Protocol builds on the foundations of FIPA-ACL and KQML but adds robust workflow management, state tracking, and enterprise-grade security.
Emerging Protocols in the Agentic AI Space
The agentic AI ecosystem is evolving rapidly, with new communication protocols emerging to address specialized needs:
Vertical Protocols:Tailored for domains like healthcare, finance, and IoT, these protocols address industry-specific requirements for compliance, privacy, and interoperability.
Open-Source Initiatives:Community-driven projects are pushing for broader standardization and interoperability, ensuring that agentic AI remains accessible and adaptable.
Hybrid Protocols:Combining features from MCP, A2A, and ACP, hybrid protocols aim to offer “best of all worlds” solutions for complex, multi-domain environments.
As the field matures, expect to see increased convergence and cross-compatibility among protocols.
Protocol Stacking: Integrating Protocols in Agentic Architectures
What Is Protocol Stacking?
Protocol stacking refers to layering multiple communication protocols to address different aspects of agentic AI:
MCP connects agents to tools and data sources.
A2A enables agents to discover and communicate with each other.
ACP orchestrates workflows and manages state across agents.
How Protocols Fit Together:
Imagine a smart home energy management system:
MCP connects agents to weather APIs and device controls.
A2A allows specialized agents (HVAC, solar, battery) to coordinate.
ACP orchestrates the overall optimization workflow.
This modular approach enables organizations to build scalable, interoperable systems that can evolve as new protocols emerge.
For a hands-on guide to building agentic workflows, see our LangGraph tutorial.
Key Challenges in Implementing and Scaling Agentic AI Protocols
Interoperability:Ensuring agents from different vendors can communicate seamlessly is a major hurdle. Open standards and rigorous testing are essential.
Security & Authentication:Managing permissions, data privacy, and secure agent discovery across domains requires robust encryption, authentication, and access control mechanisms.
Scalability:Supporting thousands of agents and real-time, cross-platform workflows demands efficient message routing, load balancing, and fault tolerance.
Standardization:Aligning on schemas, ontologies, and message formats is critical to avoid fragmentation and ensure long-term compatibility.
Observability & Debugging:Monitoring agent interactions, tracing errors, and ensuring accountability are vital for maintaining trust and reliability.
Agents optimize energy usage by coordinating with weather APIs, grid pricing, and user preferences using MCP, A2A, and ACP. For example, the HVAC agent communicates with the solar panel agent to balance comfort and cost.
Enterprise Document Processing
Agents ingest, analyze, and route documents across departments, leveraging MCP for tool access, A2A for agent collaboration, and ACP for workflow orchestration.
Supply Chain Automation
Agents representing procurement, logistics, and inventory negotiate and adapt to real-time changes using ACP and A2A, ensuring timely deliveries and cost optimization.
Customer Support Automation
Agents across CRM, ticketing, and communication platforms collaborate via A2A, with MCP providing access to knowledge bases and ACP managing escalation workflows.
Agentic AI communication protocols are the foundation for scalable, interoperable, and secure multi-agent systems. By understanding and adopting MCP, A2A, and ACP, organizations can unlock new levels of automation, collaboration, and innovation. As the ecosystem matures, protocol stacking and standardization will be key to building resilient, future-proof agentic architectures.
Have you ever wondered what possibilities agentic AI systems will unlock as they evolve into true collaborators in work and innovation? It opens up a world where AI does not just follow instructions. It thinks, plans, remembers, and adapts – just like a human would.
With the rise of agentic AI, machines are beginning to bridge the gap between reactive tools and autonomous collaborators. That is the driving force behind the Future of Data and AI: Agentic AI Conference 2025.
This event gathers leading experts to explore the key innovations fueling this shift. From building flexible, memory-driven agents to designing trustworthy, context-aware AI systems, the conference dives deep into the foundational elements shaping the next era of intelligent technology.
In this blog, we’ll give you an inside look at the major panels, the core topics each will cover, and the groundbreaking expertise you can expect. Whether you’re just starting to explore what are AI agents or you are building the next generation of intelligent systems, these discussions will offer insights you won’t want to miss.
Ready to see how AI is evolving into something truly remarkable? Register now and be part of the conversation that’s defining the future!
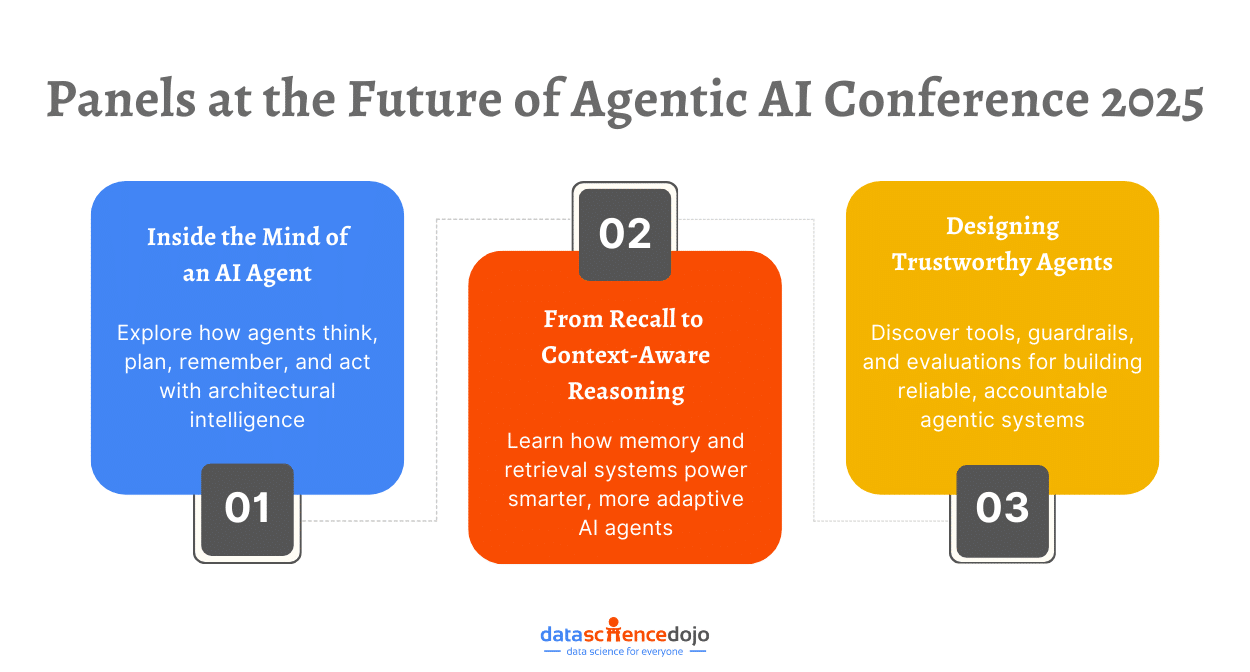
Panel 1: Inside the Mind of an AI Agent
Agentic Frameworks, Planning, Memory, and Tools
Speakers: Luis Serrano, Zain Hasan, Kartik Talamadupula
This panel discussion marks the start of the conference and dives deep into the foundational components that make today’s agentic AI systems functional, powerful, and adaptable. At the heart of this discussion is a closer look at how these agents are built, from their internal architecture to how they plan, remember, and interact with tools in the real world.
1. Agentic Frameworks
We begin with architectures, the structural blueprints that define how an AI agent operates. Modern agentic frameworks like ReAct, Reflexion, and AutoGPT-inspired agents are designed with modularity in mind, enabling different parts of the agent to work independently yet cohesively.
These systems do not just respond to prompts; they evaluate, revise, and reflect on their actions, often using past experiences to guide current decisions. But to solve more complex, multi-step problems, agents need structure. That’s where hierarchical and recursive designs come into play.
Hierarchical frameworks allow agents to break down large goals into smaller, manageable tasks, similar to how a manager might assign sub-tasks to a team. Recursive models add another layer of sophistication by allowing agents to revisit and refine previous steps, making them better equipped to handle dynamic or evolving objectives.
Planning and reasoning are also essential capabilities in agentic AI. The panel will explore how agents leverage tools like PDDL (Planning Domain Definition Language), a symbolic planning language that helps agents define and pursue specific goals with precision.
You will also hear about chain-of-thought prompting, which guides agents to reason step-by-step before arriving at an answer. This makes their decisions more transparent and logical. Combined with tool integration, such as calling APIs, accessing code libraries, or querying databases, these techniques enhance an agent’s ability to solve real-world problems.
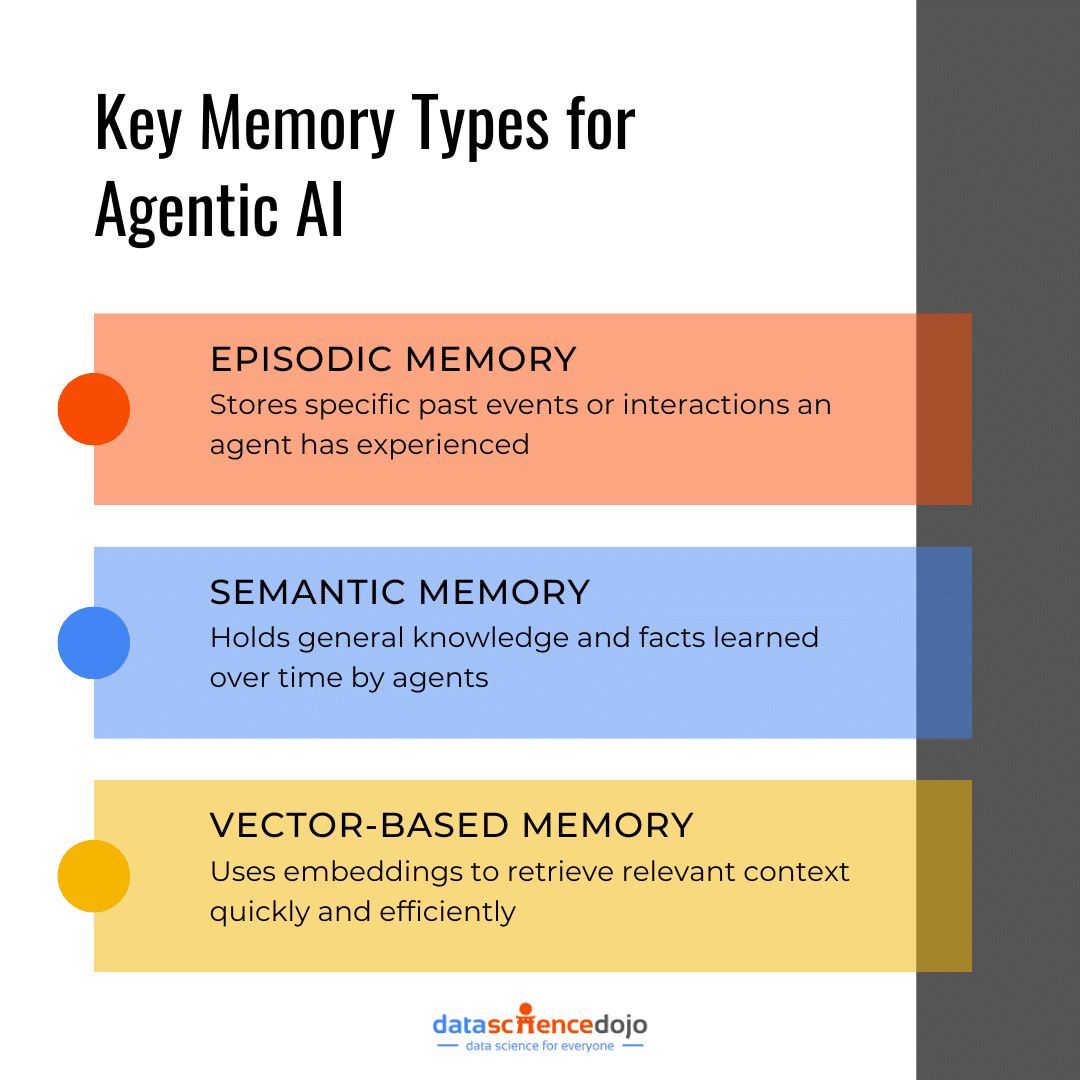
3. Memory
Memory is another key piece of the puzzle. Just like humans rely on short-term and long-term memory, agents need ways to store and recall information. The panel will unpack strategies like:
episodic memory, which stores specific events or interactions
semantic memory, that is, general knowledge
vector-based memory, which helps retrieve relevant information quickly based on context
You will also learn how these memory systems support adaptive learning, allowing agents to grow smarter over time by refining what they store and how they use it, often compressing older data to make room for newer, more relevant insights.
Together, these components – architecture, planning, memory, and tool use – form the driving force behind today’s most advanced AI agents. This session will offer both a technical roadmap and a conceptual framework for anyone looking to understand or build intelligent systems that think, learn, and act with purpose.
Panel 2: From Recall to Context-Aware Reasoning
Architecting Retrieval Systems for Agentic AI
Speakers: Raja Iqbal, Bob Van Luijt, Jerry Liu
Intelligent behavior in both humans and AI is marked by memory playing a central role. In agentic AI, memory is more than just about storing data. It is about retrieving the right information at the right time to make informed decisions.
This panel takes you straight into the core of these memory systems, focusing on retrieval mechanisms, from static and dynamic vector stores to context-aware reasoning engines that help agents act with purpose and adaptivity.
1. Key Themes
At the center of this conversation is how agentic AI uses episodic and semantic memory.
Episodic memory allows an agent to recall specific past interactions or events, like remembering the steps it took to complete a task last week.
Semantic memory is more like general knowledge, helping an agent understand broader concepts or facts that it has learned over time.
These two memory types work together to help agents make smarter, more context-aware decisions. However, these strategies are only focused on storing data, while agentic systems also need to retrieve relevant memories and integrate them into their planning process.
The panel explores how this retrieval is embedded directly into an agent’s reasoning and action loops. For example, an AI agent solving a new problem might first query its vector database for similar tasks it has encountered before, then use that context to shape its strategy moving forward.
2. Real-World Insights to Understand What are AI Agents
The conversation will also dive into practical techniques for managing memory, such as pruning irrelevant or outdated information and using compression to reduce storage overhead while retaining useful patterns. These methods help agents stay efficient and scalable, especially as their experience grows.
You can also expect insights into how retrievers themselves can be fine-tuned based on agent behavior. By learning what kinds of information are most useful in different contexts, agents can evolve to retrieve smartly.
The panel will also spotlight real-world use cases of Retrieval-Augmented Generation (RAG) in agentic systems, where retrieval directly enhances the agent’s ability to generate accurate, relevant outputs across tasks and domains. Hence, this session offers a detailed look at how intelligent agents remember, reason, and act with growing sophistication.
Observability, Guardrails, and Evaluation in Agentic Systems
Speakers: Aparna Dhinakaran, Sage Elliot
This final panel tackles one of the most pressing questions in the development of agentic AI: How can we ensure that these systems are not only powerful but also safe, transparent, and reliable? As AI agents grow more autonomous, their decisions impact real-world outcomes. Hence, trust and accountability are just as important as intelligence and adaptability.
1. Observability
The conversation begins with a deep dive into observability, that is, how we “see inside” an AI agent’s mind. Developers need visibility into how agents make decisions. Tools that trace decision paths and log internal states offer crucial insights into what the agent is thinking and why it acted a certain way.
While these insights are useful for debugging, they serve a greater purpose. They build the reliability of these agentic systems, enabling users to operate them confidently in high-stake environments.
Next, the panel will explore behavioral guardrails for agentic AI systems. These are mechanisms that keep AI agents within safe and expected boundaries, ensuring the agents operate in a way that is ethically acceptable.
Whether it is a healthcare agent triaging patients or an enterprise chatbot handling sensitive data, agents must be able to follow rules, reject harmful instructions, and recover gracefully from mistakes. Setting these constraints up front and continuously updating them is key to responsible deployment.
3. Evaluation
However, a bunch of rules and constant monitoring is not the only solution. You need an evaluation strategy for your agentic systems to ensure their reliability and practical use. The panelists will shed light on best practices of evaluation, like:
Simulation-based testing, where agents are placed in controlled, complex environments to see how they behave under different scenarios
Agent-specific benchmarks, which are designed to measure how well an agent is performing beyond just accuracy or completion rates
While these are some evaluation methods, the goal is to find the answer to important questions during the process. These questions can be like: Are the agent’s decisions explainable? Does it improve with feedback? These are the kinds of deeper questions that effective evaluation must answer.
The most important part is, you will also get to learn from our experts as they share their lessons from real-world deployments. They will reflect on what it takes to scale trustworthy agentic AI systems without compromising performance.
Ranging from practical trade-offs and what works in production, to how organizations are navigating the complex balance between oversight and autonomy. For developers, product leads, and AI researchers, this session offers actionable insights into building agents that are credible, safe, and ready for the real world.
The Future of AI Is Agentic – Are You Ready?
As we move into an era where AI systems are not just tools but thinking partners, the ideas explored in these panels offer a clear signal: agentic AI is no longer a distant concept, but is already shaping how we work, innovate, and solve problems.
The topics of discussion at the Agentic AI Conference 2025 show what is possible when AI starts to think, plan, and adapt with intent. Whether you are just learning what an AI agent is or you are deep into developing the next generation of intelligent systems, this conference is your front-row seat to the future.
Don’t miss your chance to be part of this pivotal moment in AI evolution and register now to join the conversation of defining what’s next!
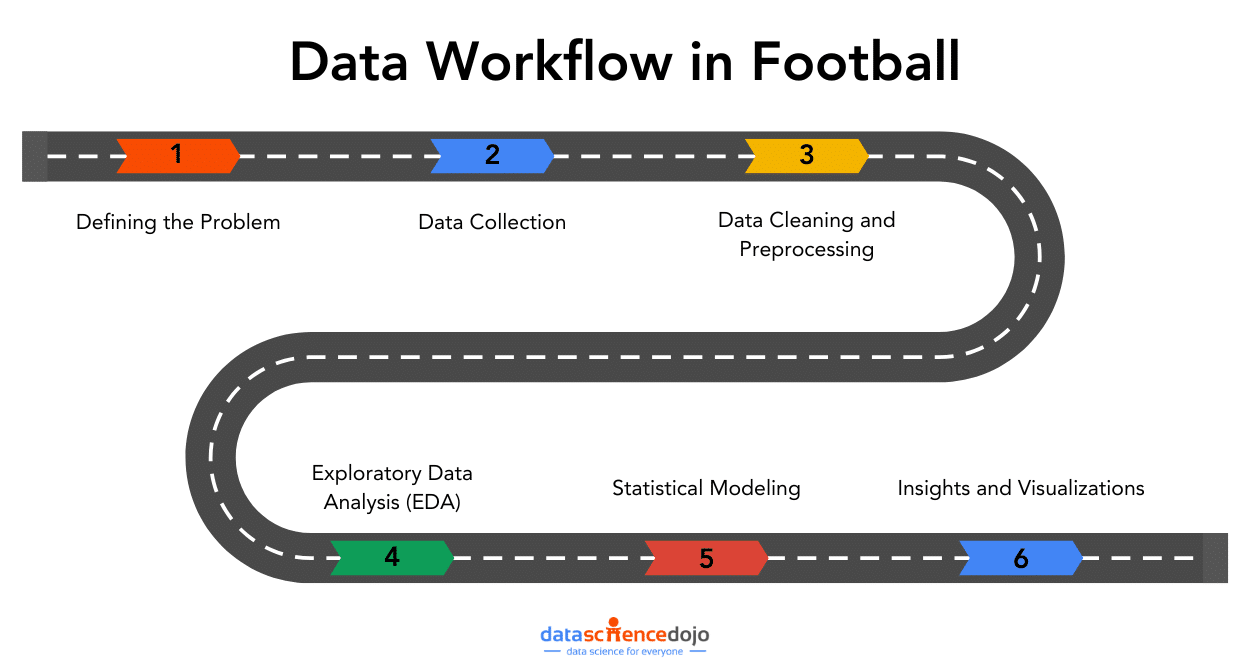
In the world of data, data workflows are essential to providing the ideal insights. Similarly, in football, these workflows will help you gain a competitive edge and optimize team performance.
Imagine you’re the data analyst for a top football club, and after reviewing the performance from the start of the season, you spot a key challenge: the team is creating plenty of chances, but the number of goals does not reflect those opportunities.
The coaching team is now counting on you to find a data-driven solution. This is where a data workflow is essential, allowing you to turn your raw data into actionable insights.
In this article, we’ll explore how that workflow – covering aspects from data collection to data visualizations – can tackle the real-world challenges. Whether you’re passionate about football or data, this journey highlights how smart analytics can increase performance.
1. Defining the Problem
The starting point for any successful data workflow is problem definition. For a football data analyst, this involves turning the team’s goals or challenges into specific, measurable questions that can be analyzed with data.
Problem
The football team you work for has struggled in front of the goal lately. With one of the lowest goal tallies in the league, this has seen them slip down into the bottom half of the table.
Using this problem, your question might become:“How can we increase our shot conversion rate to score more goals?”
Techniques
Stakeholder Meetings: Scheduling regular meetings with coaches, scouts, and analysts might help you pinpoint the problem. Coaches might identify that players are not taking high-percentage shots, while analysts can frame this into a data-driven question.
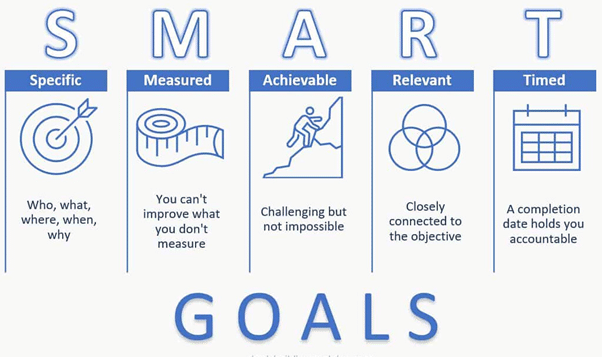
SMART: Using the SMART (Specific, Measurable, Achievable, Relevant, and Time-Bound) framework, you can provide a clear and measurable goal. For instance, “Increase shot conversion rate by 10% over the next 5 matches”.
A well-defined question helps focus data collection and analysis on solving a tangible issue that can be measured and tracked.
2. Data Collection
Once the problem is defined, the next step in the data workflow is collecting relevant data. In football analytics, this could mean pulling data from several sources, including event and player performance data.
Types of Football Data
Event Data: Shot locations, types (on-target/off-target), and outcomes (goal or miss).
Tracking Data: Player movements and positioning.
Player Metrics: Shot accuracy, shot attempts, and other similar metrics.
Techniques
Data Integration: Often, you might need to pull data from multiple sources and combine these datasets. Providers like Opta, Statsbomb, and Wyscout provide users with data from different leagues all over the world. FBRef provides users with football statistics for free, while Statsbomb offers a few free resources for event data for practice. In Power BI, you can merge these sources through data transformation, while in Python, libraries like pandas are used to integrate and join different datasets.
Real-Time Data Collection: Football teams increasingly use real-time tracking and wearable technologies to capture live player data during matches, which can be analyzed post-game for immediate insights.
You may combine event data (e.g., shot types and results) with tracking data (e.g., player positioning) to see where players are when they take the shot, allowing you to assess the quality of the shooting opportunity.
Effective data collection ensures you have all the necessary information to begin the analysis, setting the stage for reliable insights into improving shot conversion rates or any other defined problem.
3. Data Cleaning and Preprocessing
After collecting data, the next critical step in the data workflow is data cleaning. Typically, datasets can have errors, missing values, or inconsistencies, so ensuring your data is clean and well-structured is essential for accurate analysis.
Before diving into cleaning, it’s important to first understand the data’s structure and quality through data profiling. Data profiling helps identify issues such as missing values, duplicates, or outliers.
In Power BI: You can use the ‘Column Profile’ option to quickly view data completeness, data types, and patterns, helping you detect any inconsistencies early.
In Python: Data profiling, such as pandas-profiling (now renamed to ydata-profiling), generate reports that highlight potential problems, giving you a detailed overview of the dataset.
Key Data Cleaning Techniques
Handling Missing Data:
Imputation: Estimate missing values using the mean or median.
Removal: Exclude rows or columns with excessive missing values.
Data Normalization:
Normalize metrics to per 90 to fairly compare players with different playing times.
You might come across certain matches that have missing data on shot outcomes, or any other metric. Correcting these issues ensures your analysis is based on clean, reliable data.
4. Exploratory Data Analysis (EDA)
With clean data in hand, the next step is Exploratory Data Analysis (EDA). This phase is crucial for uncovering trends and relationships that will help explain why the team’s shot conversion rate is low.
Techniques for EDA
Descriptive Statistics: Start by calculating average shot distance, conversion rates, and shot success inside vs. outside the penalty area.
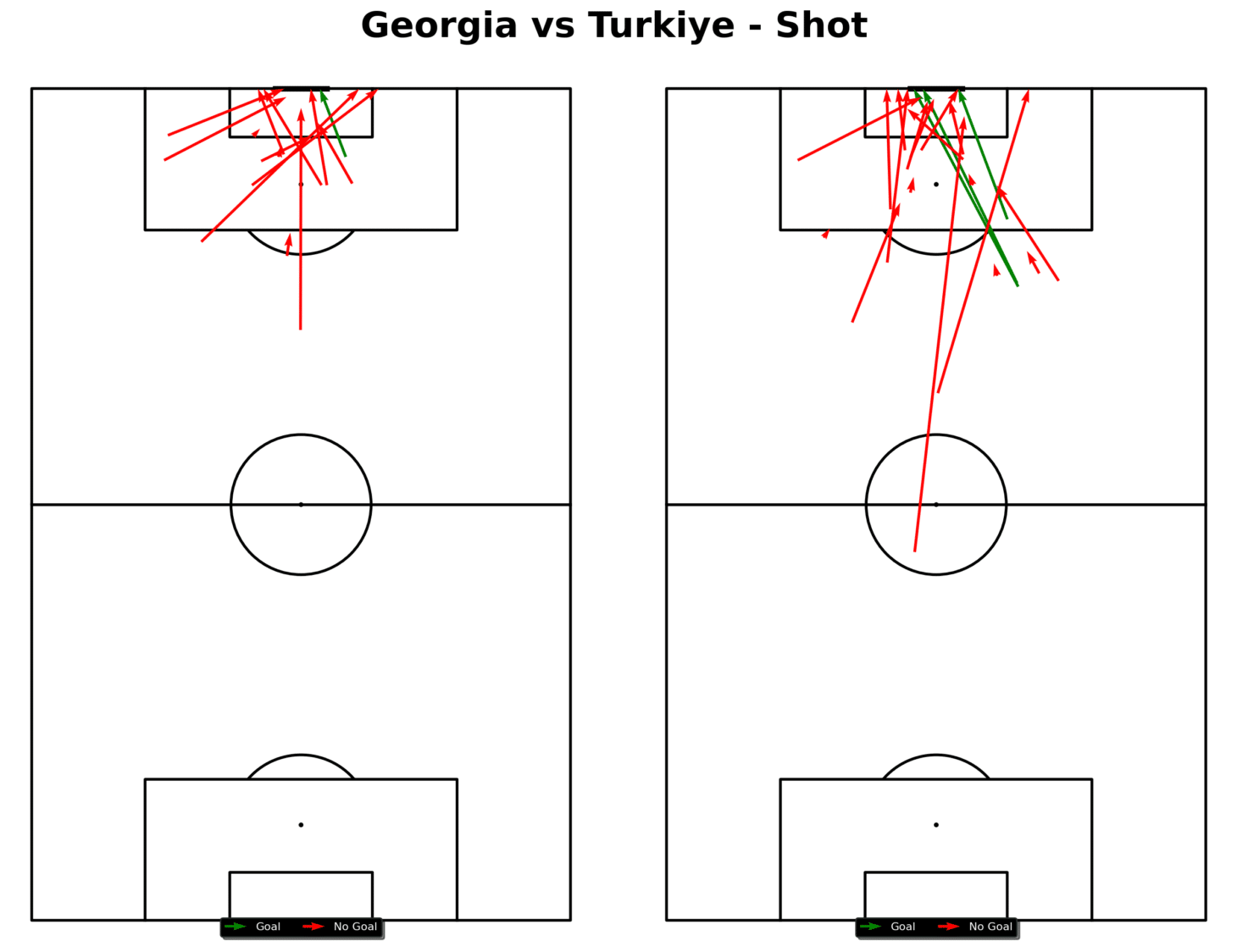
Data Visualization: Create shot maps using Python or Power BI to visualize where shots are taken and their success rates.
Shot map from Georgia vs Turkiye (Euros 2024)
A simple way to plot a shot map, like the one above, would be as follows:
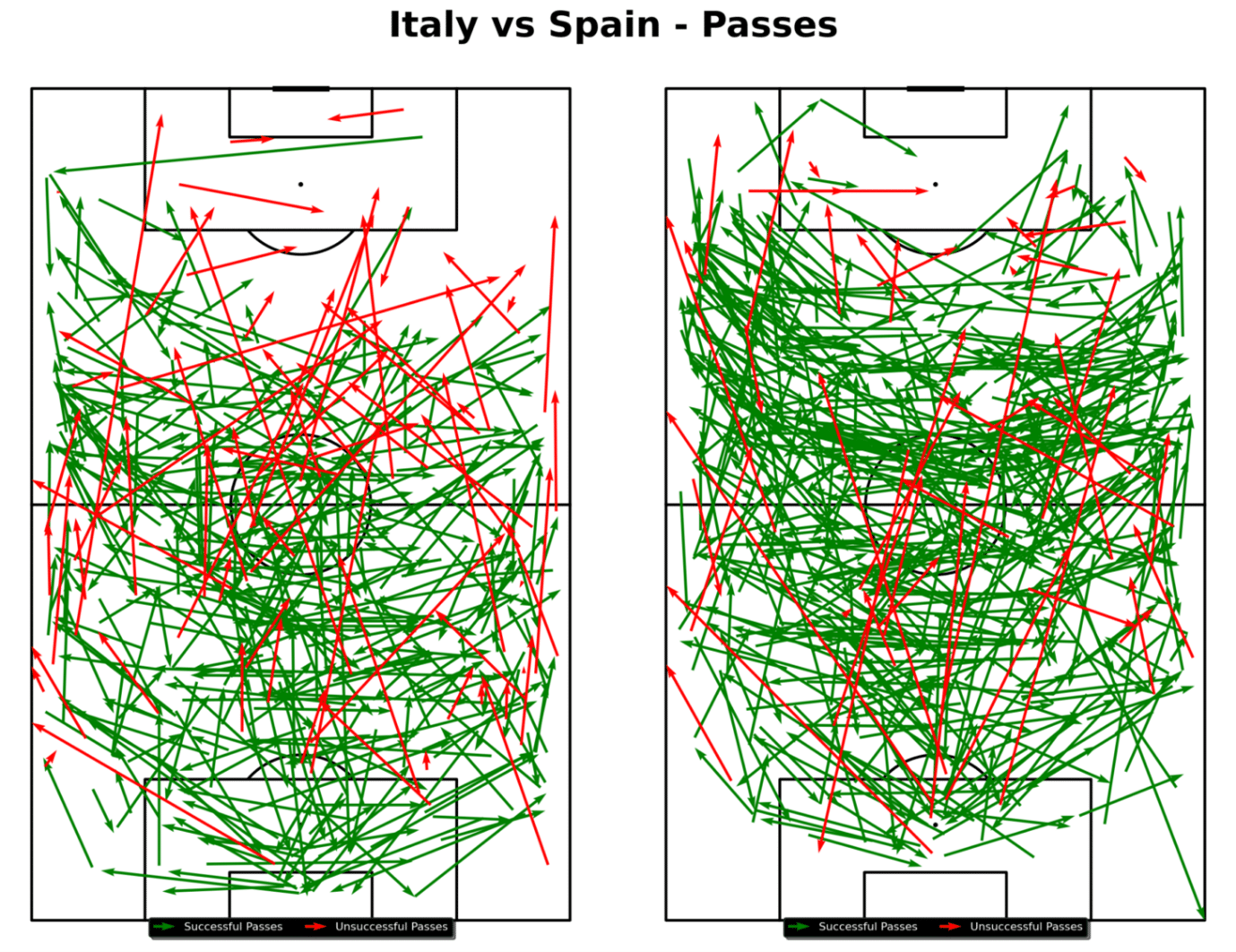
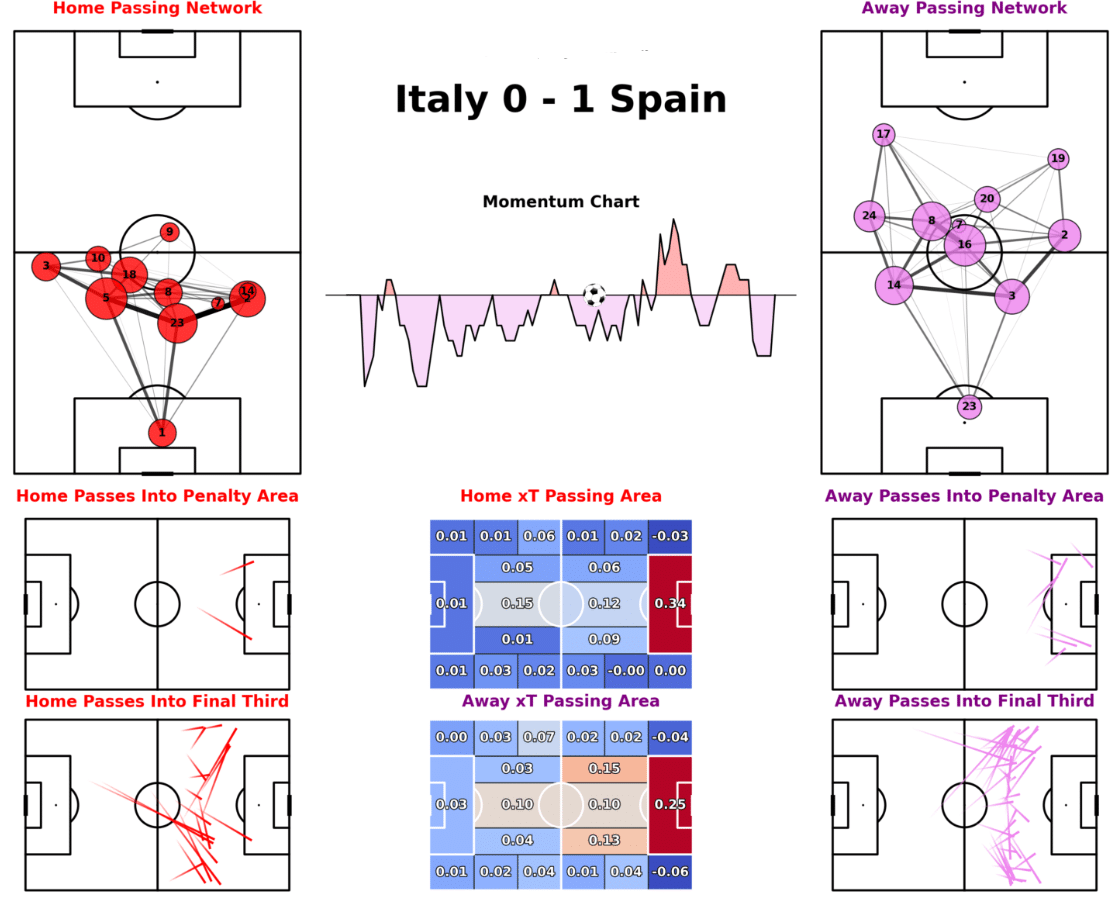
Passing Networks and Maps:Analyze passing networks and pass maps to see the build-up to shots and goals.
Pass map for Italy vs Spain (Euros 2024)
For this specific pass map, which shows both teams from a certain game, you could utilize the following Python code:
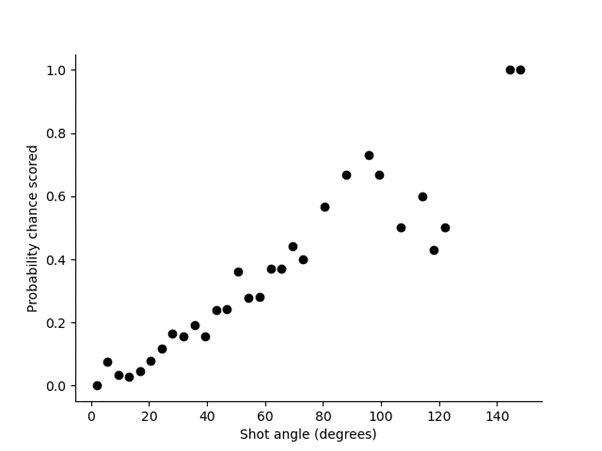
Visualizations created in Python or Power BI might show that most shots are coming from low-percentage areas, such as outside the penalty box. This visualization suggests that to improve shot conversion, the team should focus on creating chances in higher-percentage areas inside the box.
EDA provides key insights into trends that directly affect the team’s shot conversion rate, allowing you to identify specific areas for improvement.
Do not be afraid to dive deep and explore other techniques. This is the part where analysts should embrace their curiosity and learn new approaches along the way.
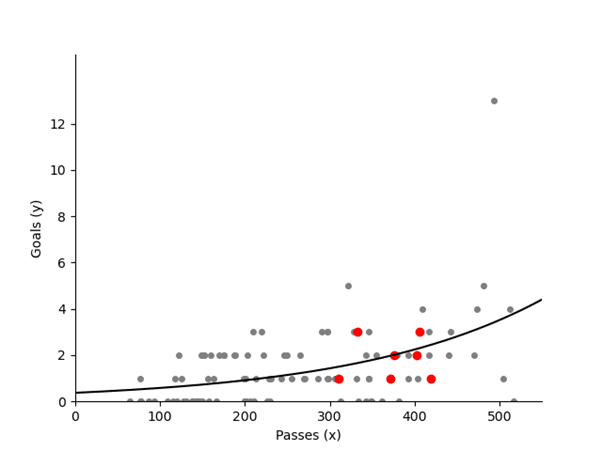
5. Statistical Modelling
Statistical modelling can provide deeper insights into football data, though it’s not always necessary. Different types of models can help analyze different aspects and predict outcomes.
Poisson Regression: Useful for predicting the number of goals a team is likely to score based on shot attempts, passes, and other factors.
Predicting Goals Based on Passes
Below you’ll find a lesson fromDr. David Sumpter, a professor and author, who dives deep into statistical models and their application in football.
While statistical models aren’t required for every analysis, they can offer a tactical edge by providing detailed predictions and insights that inform decision-making.
6. Insights and Visualizations
Once the data has been analyzed, the final step is telling the story. Football coaches and management may not be familiar with technical data terms, so presenting the data clearly is crucial.
Football Insights Techniques
Power BI Dashboards: Power BI dashboards provide an intuitive way to present key insights like shot maps, player metrics, and overall conversion rates. Coaches can use these dashboards to monitor performance in real time and adjust strategies accordingly.
Static Reports: Making a static report could be another option. Reports can provide you with a comprehensive view of data and are suitable for in-depth analysis. To make reports, you could combine visualizations made in Power BI or Python and display them in a PowerPoint presentation or a document assembled in Canva.
Example from a Match Report with Simple Visualizations
So, from this example match report, you can understand how a certain team might have played or dominated throughout this game. For instance, the momentum chart is heavily favouring Spain which means they dominated throughout the game. Furthermore, the passing networks show which side the teams favoured more and how they were set up to play.
For visualizations like the one above, you can access the GitHub repository from which this code was referenced here.
Clear communication of data-driven insights allows teams to act on the analysis, completing the data workflow and directly impacting performance on the pitch.
A structured data workflow is essential for modern football teams looking to improve their performance. By following each phase – from problem definition to data cleaning, analysis, and visualization – teams can turn raw data into actionable insights that directly enhance on-field outcomes.
Imagine relying on an LLM-powered chatbot for important information, only to find out later that it gave you a misleading answer. This is exactly what happened with Air Canada when a grieving passenger used its chatbot to inquire about bereavement fares. The chatbot provided inaccurate information, leading to a small claims court case and a fine for the airline.
Incidents like this highlight that even after thorough testing and deployment, AI systems can fail in production, causing real-world issues. This is why LLM Observability & Monitoring is crucial. By tracking LLMs in real time, businesses can detect problems such as hallucinations or performance degradation early, preventing major failures.
This blog dives into the importance of LLM observability and monitoring for building reliable, secure, and high-performing LLM applications. You will learn how monitoring and observability can improve performance, enhance security, and optimize costs.
What is LLM Observability and Monitoring?
When you launch an LLM application, you need to make sure it keeps working properly over time. That is where LLM observability and monitoring come in. Monitoring tracks the model’s behavior and performance, while observability digs deeper to explain why things are going wrong by analyzing logs, metrics, and traces.
Since LLMs deal with unpredictable inputs and complex outputs, even the best models can fail unexpectedly in production. These failures can lead to poor user experiences, security risks, and higher costs. Thus, if you want your AI system to stay reliable and trustworthy, observability and monitoring are critical.
LLM Monitoring: Is Everything Working as Expected?
LLM monitoring tracks critical metrics to identify if the model is functioning as expected. It focuses on the performance of the LLM application by analysing user prompts, responses, and key performance indicators. Good monitoring means you spot problems early and keep your system reliable.
However, monitoring only shows you what is wrong, not why. If users suddenly get irrelevant answers or the system slows down, monitoring will highlight the symptoms, but you will still need a way to figure out the real cause. That is exactly where observability steps in.
LLM Observability: Why Is This Happening?
LLM observability goes beyond monitoring by answering the “why” behind the detected issues, providing deeper diagnostics and root cause analysis. It brings together logs, metrics, and traces to give you the full picture of what went wrong during a user’s interaction.
This makes it easier to track issues back to specific prompts, model behaviors, or system bottlenecks. For instance, if monitoring shows increased latency or inaccurate responses, observability tools can trace the request flow, identifying the root cause and enabling more efficient troubleshooting.
What to Monitor and How to Achieve Observability?
By tracking key metrics and leveraging observability techniques, organizations can detect failures, optimize costs, and enhance the user experience. Let’s explore the critical factors that need to be monitored and how to achieve LLM observability.
Key Metrics to Monitor
Monitoring core performance indicators and assessing the quality of responses ensures LLM efficiency and user satisfaction.
Response Time: Measures the time taken to generate a response, allowing you to detect when the LLM is taking longer than usual to respond.
Token Usage: Tokens are the currency of LLM operations. Monitoring them helps optimize resource use and control costs.
Throughput: Measures requests per second, ensuring the system handles varying workloads while maintaining performance.
Accuracy: Compares LLM outputs against ground truth data. It can help detect performance drift. For example, in critical services, monitoring accuracy helps detect and correct inaccurate customer support responses in real time.
Relevance: Evaluates how well responses align with user queries, ensuring meaningful and useful outputs.
User Feedback: Collecting user feedback allows for continuous refinement of the model’s responses, ensuring they better meet user needs over time.
Other metrics: These include application-specific metrics, such as faithfulness, which is crucial for RAG-based applications.
Observability goes beyond monitoring by providing deep insights into why and where the issue occurs. It relies on three main components:
1. Logs:
Logs provide granular records of input-output pairs, errors, warnings, and metadata related to each request. They are crucial for debugging and tracking failed responses and help maintain audit trails for compliance and security.
For example, if an LLM generates an inaccurate response, logs can be used to identify the exact input that caused the issue, along with the model’s output and any related errors.
2. Tracing:
Tracing maps the entire request flow, from prompt preprocessing to model execution, helping identify latency issues, pipeline bottlenecks, and system dependencies.
For instance, if response times are slow, tracing can determine which step causes the delay.
3. Metrics:
Metrics can be sampled, correlated, summarized, and aggregated in a variety of ways, providing actionable insights into model efficiency and performance. These metrics could include:
Monitoring user interactions and key metrics helps detect anomalies, while correlating them with logs and traces enables real-time issue diagnosis through observability tools.
Why Monitoring and Observability Matter for LLMs?
LLMs come with inherent risks. Without robust monitoring and observability, these risks can lead to unreliable or harmful outputs.
Prompt Injection Attacks
Prompt injection attacks manipulate LLMs into generating unintended outputs by disguising harmful inputs as legitimate prompts. A notable example is DPD’s chatbot, which was tricked into using profanity and insulting the company, causing public embarrassment.
By actively tracking and analysing user interactions, suspicious patterns can be flagged and prevented in real-time.
Source: mustsharenews
Hallucinations
LLMs can generate misleading or incorrect responses, which can be particularly harmful in high-stakes fields like healthcare and legal services.
By monitoring responses for factual correctness, hallucination can be detected early, while observability identifies the root cause, whether a dataset issue or model misconfiguration.
Sensitive Data Disclosure
LLMs trained on sensitive data may unintentionally reveal confidential information, leading to privacy breaches and compliance risks.
Monitoring helps flag leaks in real-time, while observability traces the source to refine sensitive data-handling strategies and ensure regulatory compliance.
Performance and Latency Issues
Slow or inefficient LLMs can frustrate users and disrupt operations.
Monitoring response times, API latency, and token usage helps identify performance bottlenecks, while observability provides insights for debugging and optimizing efficiency.
Concept Drift
Over time, LLMs may become less accurate as user behaviour, language patterns, and real-world data evolve.
Example: A customer service chatbot generating outdated responses due to new product features and evolved customer concerns.
Continuous monitoring of responses and user feedback helps detect gradual shifts in user satisfaction and accuracy, allowing for timely updates and retraining.
You can also learn about LangChain and its importance in LLMs
Using Langfuse for LLM Monitoring & Observability
Let’s explore a practical example using DeepSeek LLM and Langfuse to demonstrate monitoring and observability.
Create a virtual environment and install the required modules.
py -3.12 -m venv langfuse_venv
Create a virtual environment and install required modules:
Set up a .env file with Langfuse API keys (found under Settings → Setup → API Keys)
Develop an LLM-powered Python app for content generation using the code below and integrate Langfuse for monitoring. After running the code, you’ll see traces of your interactions in the Langfuse project.
Step 3: Experience LLM Observability and Monitoring with Langfuse
Navigate to the Langfuse interactive dashboard to monitor quality, cost, and latency.
Track traces of user requests to analyse LLM calls and workflows.
You can create custom evaluators or use existing ones to assess traces based on relevant metrics. Start by creating a new template from an existing one. Go to Evaluations → Templates → New Template
It requires an LLM API key to set up the evaluator. In our case, we have utilized Azure GPT3.5 Turbo.
After setting up the evaluator, as per the use case, you can create templates for evaluation, like we are using relevance metrics for this project.
After creating a template, we will create a new evaluator. Go to EvaluationsàNew Evaluator and select the created template.
Select traces and mark new traces. This way, we will run an evaluation on the newtraces. You can also evaluate on a custom dataset. In the next steps, we will see the evaluations for the new traces.
Debug each trace and track its execution flow.
It is a great feature to perform LLM Observability and trace through the entire execution flow of user request.
You can also see the relevance score that is calculated as a result of the evaluator we defined in the previous step and the user feedback for this trace.
To see the scores for all the traces, you can navigate to the Scores tab. In this example, traces are evaluated based on:
User feedback, collected via the LLM application.
Relevancy score determined using a relevance evaluator to assess content alignment with user requests.
These scores help track model performance and provide qualitative insights for the continuous improvement of LLMs.
Sessions track multi-step conversations and agentic workflows by grouping multiple traces into a single, seamless replay. This simplifies analysis, debugging, and monitoring by consolidating the entire interaction in one place.
This tutorial demonstrates how to easily set up monitoring for any LLM application. A variety of open-source and paid tools are available, allowing you to choose the best fit based on your application requirements.Langfuse also provides a free demo to explore LLM monitoring and observability (Link)
Key Benefits of LLM Monitoring & Observability
Implementing LLM monitoring and observability is not just a technical upgrade, but a strategic move. Beyond keeping systems stable, it helps boost performance, strengthen security, and create better user experiences. Let’s dive into some of the biggest benefits.
Improved Performance
LLM monitoring keeps a close eye on key performance indicators like latency, accuracy, and throughput, helping teams quickly spot and resolve any inefficiencies. If a model’s response time slows down or its accuracy drops, you will catch it early before users even notice.
By consistently evaluating and tuning your models, you maintain a high standard of service, even as traffic patterns change. Plus, fine-tuning based on real-world data leads to faster response times, better user satisfaction, and lower operational costs over time.
When something breaks in an LLM application, every second counts. Monitoring ensures early detection of glitches or anomalies, while observability tools like logs, traces, and metrics make it much easier to diagnose what is going wrong and where.
Instead of spending hours digging blindly into systems, teams can pinpoint issues in minutes, understand root causes, and apply targeted fixes. This means less downtime, faster recoveries, and a smoother experience for your users.
Enhanced Security and Compliance
Large language models are attractive targets for security threats like prompt injection attacks and accidental data leaks. Robust monitoring constantly analyzes interactions for unusual behavior, while observability tracks back the activity to pinpoint vulnerabilities.
This dual approach helps organizations quickly flag and block suspicious actions, enforce internal security policies, and meet strict regulatory requirements. It is an essential layer of defense for building trust with users and protecting sensitive information.
Better User Experience
An AI tool is only as good as the experience it offers its users. By monitoring user interactions, feedback, and response quality, you can continuously refine how your LLM responds to different prompts.
Observability plays a huge role here as it helps uncover why certain replies miss the mark, allowing for smarter tuning. It results in faster, more accurate, and more contextually relevant conversations that keep users engaged and satisfied over time.
Cost Optimization and Resource Management
Without monitoring, LLM infrastructure costs can quietly spiral out of control. Token usage, API calls, and computational overhead need constant tracking to ensure you are getting maximum value without waste.
Observability offers deep insights into how resources are consumed across workflows, helping teams optimize token usage, adjust scaling strategies, and improve efficiency. Ultimately, this keeps operations cost-effective and prepares businesses to handle growth sustainably.
Thus, LLM monitoring and observability are must-haves for any serious deployment as they safeguard performance and security. Moreover, they also empower teams to improve user experiences and manage resources wisely. By investing in these practices, businesses can build more reliable, scalable, and trusted AI systems.
Future of LLM Monitoring & Observability – Agentic AI?
At the end of the day, LLM monitoring and observability are the foundation for building high-performing, secure, and reliable AI applications. By continuously tracking key metrics, catching issues early, and maintaining compliance, businesses can create LLM systems that users can truly trust.
Hence, observability and monitoring are crucial to building reliable AI agents, especially as we move towards a more agentic AI infrastructure. Systems where AI agents are expected to reason, plan, and act independently, making real-time tracking, diagnostics, and optimization even more critical.
Without solid observability, even the smartest AI can spiral into unreliable or unsafe behavior. So, as you build a chatbot, an analytics tool, or an enterprise-grade autonomous agent, investing in strong monitoring and observability practices is the key to ensuring long-term success.
It is what separates AI systems that simply work from those that truly excel and evolve over time. Moreover, if you want to learn about this evolution of AI systems towards agentic AI, join us at Data Science Dojo’s Future of Data and AI: Agentic AI conference for an in-depth discussion!