
A list of top machine learning algorithms for marketers that can help to understand trends in user behavior, which further assist with SEO and marketing-based decisions on big data.

The way to advertise and manage your SEO is changing. The tools of the trade for marketers, product managers, and SMBS are ever-evolving. This next wave of MarTech has been ramping up and might put some of us out of business.
We should keep an eye on the cutting-edge machine learning algorithms in marketing and SEO and neural network (AI) technologies being used to make our market assessments more accurate, campaigns more successful, and our customers ultimately more satisfied. However, don’t get too lost in how the algorithms work. Just remember their purpose:
“Is the end-user getting the result they want based on how they’ve communicated their search query?”
Understanding how machine learning algorithms work is critical to maximizing ROI. Here are the top 9 machine learning algorithms that work to influence keyword ranking, ad design, content construction, and campaign direction:
1. Support Vector Machines (SVM)
Classification is the process that facilitates segmentation. Simply put, SVMs are predictive algorithms used to classify customer data by feature, leading to segmentation. Features include anything from age and gender to purchase history and channels used.
SVM works by taking a set of features, plotting them in ‘n’ space ̶ ̶ ‘n’ being the number of features ̶, and trying to find a clear line of separation in the data. This creates classifications.
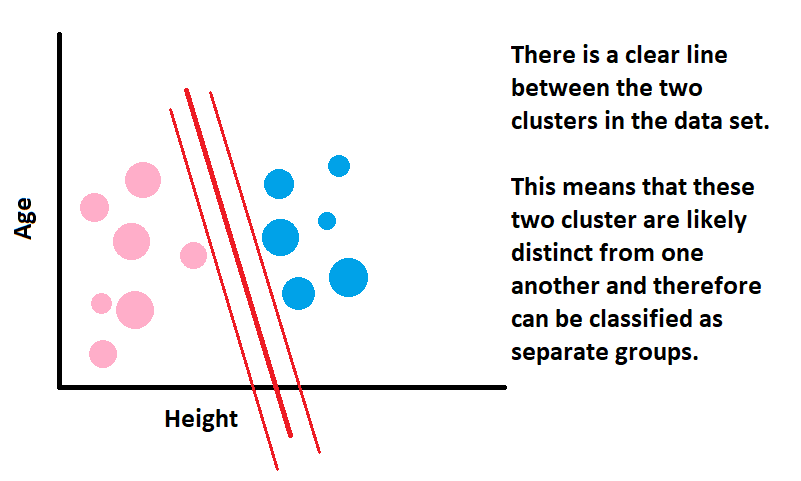
For example, Mailchimp is a popular customer relationship management (CMR) tool that uses its own proprietary algorithm to predict user behavior. This allows them to forecast which segments are likely to have high Customer Lifetime Values (LTV) and Costs Per Acquisition (CPA).
2. Information retrieval
Keywords, keywords, keywords…Sometimes the simplest solutions are the most powerful ones. A lot of machine learning algorithms designed to assess the market can be difficult to comprehend.
Information Retrieval algorithms — like the one that powers Google’s “Relevance Score” metric — use keywords to determine the accuracy of user queries. These types of machine learning algorithms are elegant, powerful, and to the point. This is part of the reason why SEO software such as SE Ranking uses a version of it called Elasticsearch to provide marketers with a list of keywords built using input from the user. The RL algorithm’s basic process follows a 4-step process:
-
Get the user query
-
Break up the keywords
-
Pull a preliminary list of relevant documents
-
Apply a Relevance Score and rank each document
In step 4, The Relevance Score algorithm takes the sum of specific criteria:
-
Keyword Frequency (number of times the keyword appears in the document)
-
Inverse Document Frequency (if the keyword appears too often, it actually demotes the ranking)
-
Coordination (how many keywords from the original query appear in the document)
The machine learning algorithm then attaches a score that gets used to rank all of the documents retrieved in the preliminary pull.
3. K-Nearest neighbors algorithm
The K-Nearest Neighbors (K-NN) machine learning algorithm is one of the most basic of its kind. Also known as a “lazy learner algorithm,” K-NN classifies new data based on how similar it is to existing data points. Here’s how it works:
Say you have an image of some kind of fruit that resembles either a pear or an apple, and you want to know which of the two categories it belongs to. A KNN model will compare the features of the new fruit image to the datasets for pear images and the datasets of apple images and based on which category the new fruit’s features are most similar to, the model will sort the image into the respective category.
In a nutshell, that’s how the KNN algorithm works. It’s best used in instances where data need to be classified based on preset categories and defining characteristics.
For example, KNN machine learning algorithms come in handy for recommendation systems such as the one you might find on an online video streaming platform, where suggestions are made based on what similar users are watching.
If you want to learn further how to implement a K-NN algorithm in Python, sign up for a training program to get you started with Python.
4. Learning to Rank (LTR)
The Learning to Rank class of machine learning algorithms is used to solve keyword search relevancy problems. Users expect their search results to populate a page and be ranked in order of relevancy. Companies like Wayfair and Slack use LTRs as part of their search query solutions.
The LTR can be separated into three methods — Pointwise, Pairwise, and Listwise.
Pointwise assesses the relevance score of one document against the keywords. Pairwise compares each document against the keywords and includes another document into the calculation for a more accurate score.
It’s like getting an ‘A’ on a test, but then you notice that the kid sitting next to you got one more correct question than you, and suddenly your ‘A’ isn’t so impressive. Listwise uses a more complicated machine learning algorithm based on probabilities to rank based on search result relevance.
5. Decision trees
Decision trees are machine learning algorithms that are used for predictive modeling. For a marketing analogy, as a user moves through a sales funnel, they’re likely to apply a few criteria:
-
Behavior-based triggers – the user clicks or opens a link or field;
-
Trait-based values – demographic, location, and affiliation information about the user;
-
Numerical Thresholds – having now spent X dollars, the user is more likely to spend ‘X+’ in the future.
The simplicity of decision trees makes them valuable for:
-
Classifications and regressions — plotting binary and floating values in the same model (ex. Gender vs. annual income);
-
Handling many parameters at once — each ‘node’ in a tree can represent a single parameter without the entire model being overwhelmed;
-
Visual and interpretive diagnostics — it’s easy to see patterns and relationships between values.
Word of caution: the more nodes you add to a decision tree, the less interpretive it becomes. You eventually start losing sight of the forest for the trees.
6. K-means clustering algorithms
K-means clustering algorithms are a part of unsupervised learning partitioning methods. In Layman’s terms, this means it’s a type of machine learning algorithm that can be used to break down unlabeled data into meaningful categories.
So, for example, if you owned a supermarket and wanted to divide your entire set of customers into smaller segments, you could use K-means clustering to identify different customer groups. This would then allow you to create specific marketing campaigns and promotions targeted to each of your customer segments, which would translate into more efficient use of your marketing budget.
What makes K-means clustering unique is that it allows you to predefine how many categories or “clusters” you’d like the machine learning algorithm to produce from the data.
7. Convolutional neural networks
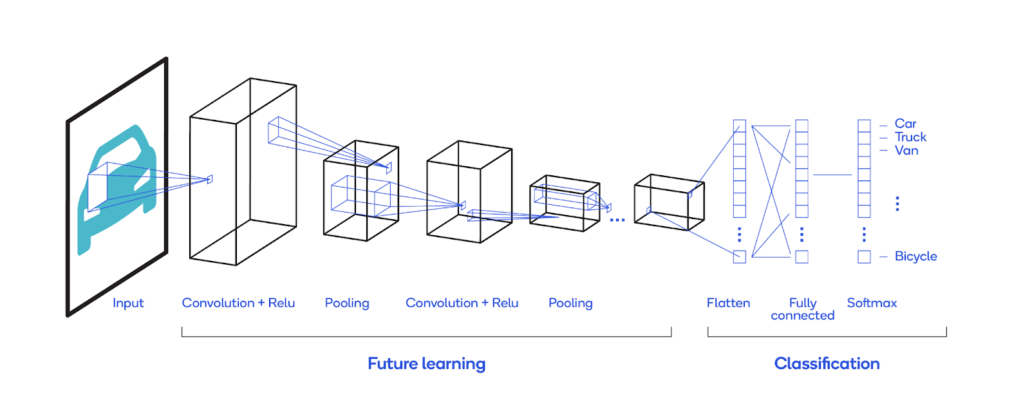
Convolutional Neural Networks, or CNN for short, are machine learning algorithms used to help computers look at images the way humans do.
Whereas a human can readily identify an apple when shown an image of an apple, computers merely see another set of numbers and identify an object based on the pattern of numbers that make up the object.
CNN works by training a computer to recognize those number patterns of an object by feeding it millions of images of the same object. With each new image, the computer improves its ability to spot the object.
Now that almost anyone can pull out their phone and take a picture wherever they are, it’s easy to imagine how powerful CNN can be for any kind of application that involves picking out objects from images.
For example, companies like Google leverage CNN machine learning algorithms for facial recognition, where a face can be matched with a name by observing the unique features of each face in an image. Similarly, the CNN machine learning algorithm is being tested for use in document and handwriting analysis, as CNN can rapidly scan and compare an individual’s writing with results from big data.
8. Naïve Bayes
The Naive Bayes (NB) machine learning algorithm is built on Bayes’ famous theorem that determines the probability of two outcomes — the probability of A, given B. What makes this algorithm so ‘Naive’ is that it is based on the assumption that the predictor variables are independent.
For marketers, this can be retooled to determine the possibility of a successful lead magnet, campaign, advertisement, segmentation, or keyword, given that you know the relevant features like height, age, purchase history, or big data concerning your customer base.
If you want to get into math, Great Learning gives a wonderful introduction here. Suffice it to say, that the NB machine learning algorithm answers two questions,
-
“Is this the type of person to perform X behavior?”
-
“Is this the type of content to achieve X outcome?”
NB is mighty when dealing with large amounts of text-based behavior data like customer chatter online.
Feeding customer dialogue through an NB machine learning algorithm helps predict product and service reviews, measure social media & influencer marketing sentiment for trends, and predict direct marketing response rates.
9. Principal component analysis
Classification leads to evolved segmentations. Principal Component Analysis is used to find strong or weak correlations between two components by plotting them on a graph and finding a trend line.
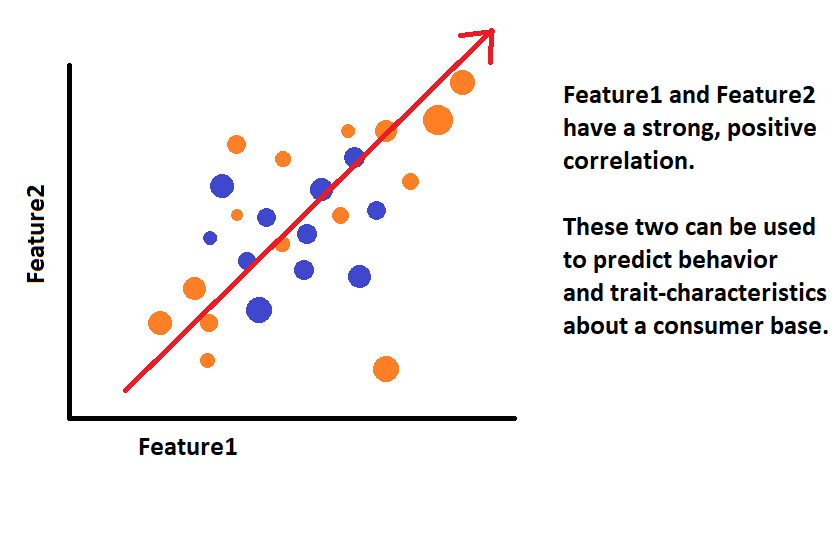
But what happens when the target market comes with 30+ features? This is where the process of PCA in combination with a machine learning algorithm becomes incredibly powerful for analyzing multivariate big data sets.
Instead of having two groups that correlate, you start to get clusters correlating with one another, where the distance between clusters now suggests strong or weak relationships.
For marketers, the component axes are no longer single features you choose but are determined by the PCA machine learning algorithm.
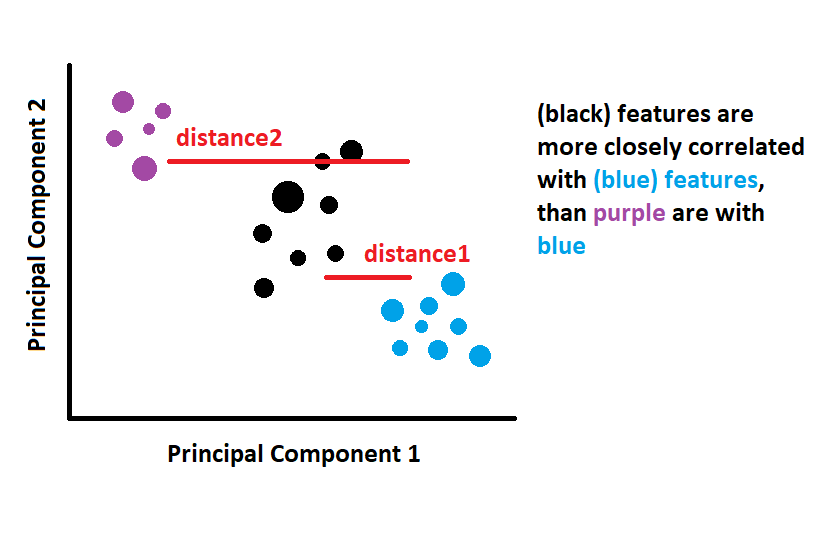
All of this helps to answer the question: “Which features are strongly correlated and can therefore be used for better segmentation targeting?”
Begin your journey to understand machine learning algorithms
Marketers, agencies, and SMBs will never stop asking for better tools to assess consumer sentiment and behavior.
Machine learning and neural network tools are never going to stop analyzing consumer markets and uncovering new insights. Marketers, agencies, and SMBs will always use these insights to ask for better tools to assess consumer sentiment and behavior.
It’s a feedback loop that you need to plug into if you’re going to be successful in the future ̶ ̶ especially with the rise in online purchasing activity influenced by geopolitical factors.
Knowing how machine learning algorithms work and learning practical skills via our data science bootcamp will provide you with marketing insights and make you better at communicating ads, content, and campaign strategies to your staff, clients, and customers. This will ultimately lead you to better ROI.
Written by Luna Bell
