Given the impact of ML models on society and the economy, ML professionals need to understand their social responsibility to communicate insights about covid-19.
COVID-19-related data sources are fairly easy to find. Libraries in R and Python make it super easy to come up with pretty visualizations, models, forecasts, insights, and recommendations. I have seen recommendations in areas like economics, public policy, and healthcare policy from individuals who apparently have no background in any of these fields. All of us have seen these ‘data-driven’ insights.
Some close friends have asked if I have been analyzing the COVID-19 datasets.
Yes, I have been looking at these datasets. However, my analysis has been just out of curiosity and not with the intent of publishing my forecast or recommendations. I am not planning to make any of my analyses on the COVID-19 dataset public because I sincerely believe that I am not qualified to do so.
Allow me to digress a bit. I promise that I will come back and connect the dots.
Pittsburgh, 1995: Two men rob a bank in broad daylight without wearing a mask or disguise of any sort – even smiling at surveillance cameras on their way out. Later that night, police arrests one of the robbers. The man and his accomplice believed that rubbing lemon juice on their skin would render them invisible to surveillance cameras, as long as they do not go close to a heat source. One might think that it was mental health or high on drugs case. It was, however, not the case. It was a case of inflated self-assessment of competence.
Motivated by the Pittsburgh robbery, Kruger and Dunning at Cornell University decided to conduct a study of how people mistakenly hold favorable views of their abilities and skills. The study was eventually published in 1999 as ‘Unskilled and Unaware of It: How Difficulties in Recognizing One’s Own Incompetence Lead to Inflated Self-Assessments’.
Dunning-Kruger effect is a cognitive bias that leads to inflated self-assessments. People who are less experienced (less skilled, less competent, or less self-aware) not only make mistakes but also fail to realize their mistakes. On the other hand, experts(people with more knowledge and experience) tend to be more self-critical and aware of their shortcomings.
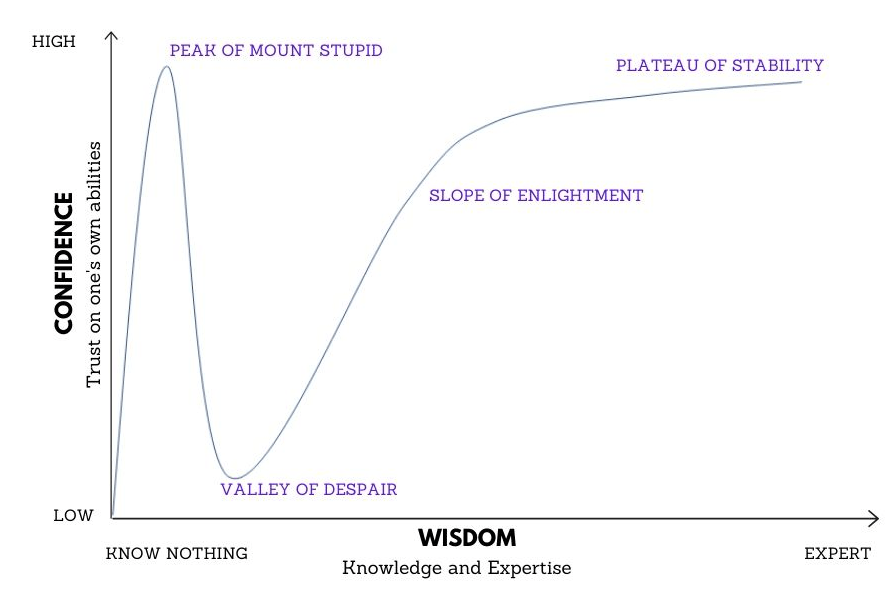
The power of modern machine learning libraries is amazing. Within a few lines of code, one can get amazing visualizations or models without having to worry about the complexities of implementation. I call these libraries a blessing and a curse at the same time. A blessing to those who are either knowledgeable or ‘know what they don’t know and a curse to those who ‘don’t know that they don’t know. During our Data Science and Data Engineering Bootcamp – about halfway into the Bootcamp, our trainees reach the peak of their confidence. Why shouldn’t they? With all the powerful R and Python libraries and toy data sets anyone would think that way. Most of them are amazed at how easy data science, AI and machine learning is.
About two-thirds into the Bootcamp, when asked to improve the models by using more feature engineering and parameter tuning, the recently acquired confidence starts tapering off. One of the frustrated attendees once exclaimed, and I quote here:
‘How is this machine learning? Why do I have to do all the feature engineering, data cleaning, and parameter tuning myself? Why can’t we automate this?’
It is time to discuss the Dunning-Kruger effect in class. (This has always been taken in good humor, except when one attendee actually got offended by the ‘peak of mount stupid’ (I have not stopped giving this example). I tell them that data science and machine learning are much more than just libraries, techniques, and tools. Domain knowledge and context of the problem are critical. Garbage in, garbage out. Let me end the digression now.
With the COVID-19 outbreak, a lot of people have started sharing their work on available data sources. I love the creativity and effort put into the work. I have seen cool visualizations in every possible tool available. I have seen models, including forecasts on how many cases will emerge in a country the next day/week/month. In most cases, I find these insights and conclusions, not just disturbing, but also downright irresponsible.
Domain knowledge and context of the problem is a necessary conditions for solving difficult modeling problems. If you are not familiar with at least the basic principles of epidemiology, economics, public policy, and healthcare policy, please stop drawing conclusions that mislead and scare – or for that matter give a false sense of comfort to people.
I created an infographic called ‘Hippocratic oath of a data scientist’ a few months ago inspired by mathematical modelers’ Hippocratic oath.

Questions to ask amid the Covid-19 outbreak:
Next time you decide to share any insights and make recommendations on economic, public, or healthcare policy in response to the COVID-19 outbreak, ask yourself these questions:
- Do you understand that machine learning is about correlations (inference) whereas policy recommendations are about causal inference?
- Do you think that publicly available data sources even contain any signal for what you are trying to predict?
- Are you familiar with the ideas of bias and variance? I mean practically, not just mathematically.
- Are you aware of something called a ‘confounding variable’?
- Does population density impact the spread of the virus?
- Have you considered the GDP, HDI, and other economic indicators in your model?
- Do social norms influence the spread of disease? For instance, all cultures greet in their own unique way. Bowing, kissing one’s cheek, hugging, shaking hands, or just nodding are some of the ways people from different cultures greet each other.
- China and Singapore did an amazing job at containing COVID-19 by locking down. Can a western democracy impose a lockdown similar to China and Singapore?
- Singapore recently introduced fines for one’s inability to maintain social distance. How many other countries would this work in?
- If you lived from paycheck to paycheck or possibly work on daily wages, would your conclusions be the same? Do you think that a government has to worry about its citizens who have months worth of savings in their bank accounts and those who live paycheck to paycheck? What would you do if you were the policy maker?
- Put a small business owner and an expert in infectious diseases in the same room. Will they agree on what is the right course of action? Lockdown or not?
- If we put a few experts in epidemiology, economics, healthcare policy, public policy, and psychology in the same room, will they agree on what measures should be taken?
Exploratory analysis and cool visualizations are great. I have actually enjoyed some analyses (shared as reports and not as forecasts) that caught my attention. However, when it comes to COVID-19 predictions, forecasts and conclusions, please understand that our models impact lives, society, and the economy. Know your social responsibility when you convincingly tell others that the number of infections in certain countries will double (triple or quadruple) tomorrow.
If you are that good, more power to you. I, for one, will not share any forecasts or public policy recommendations on the COVID-19 outbreak. I accept that there are certain things I do not completely understand and it is completely fine with me.
The peak of Mount Stupid is very crowded.