
Process Mining is a critical skill needed by every data scientist and analyst for mining rich and varied data contained in event logs.
Event logs are everywhere and represent a prime source of big data. Event log sources run the gamut from e-commerce web servers to devices participating in globally distributed Internet of Things (IoT) architectures.
Even Enterprise Resource Planning (ERP) systems produce event logs! Given the rich and varied data contained in event logs, process mining these assets is a critical skill needed by every data scientist, business/data analyst, and program/product manager.
At the meetup for this topic, presenter David Langer showed how easy it is to get started process mining your event logs using the OSS tools of R and ProM.
David began the talk by defining which features of a dataset are important for event log mining:
Activity: A well-defined step in some workflow/process.
Timestamp: The date and time at which something worthy of note happened.
Resource: Staff and/or other assets used/consumed in the execution of an activity.
Event: At a minimum, the combination of an activity and a timestamp. Optionally, events may have associated resources, life cycle, and other data.
Case: A related set of events denoted, and connected, by a unique identifier where the events can be ordered.
Event Log: A list of cases and associated events.
Trace: A distinct pattern of case activities within an event log where each activity is present at most once per trace. Event log typically contain many traces.
Below is an example of IIS Web Server data that may be used for process mining:
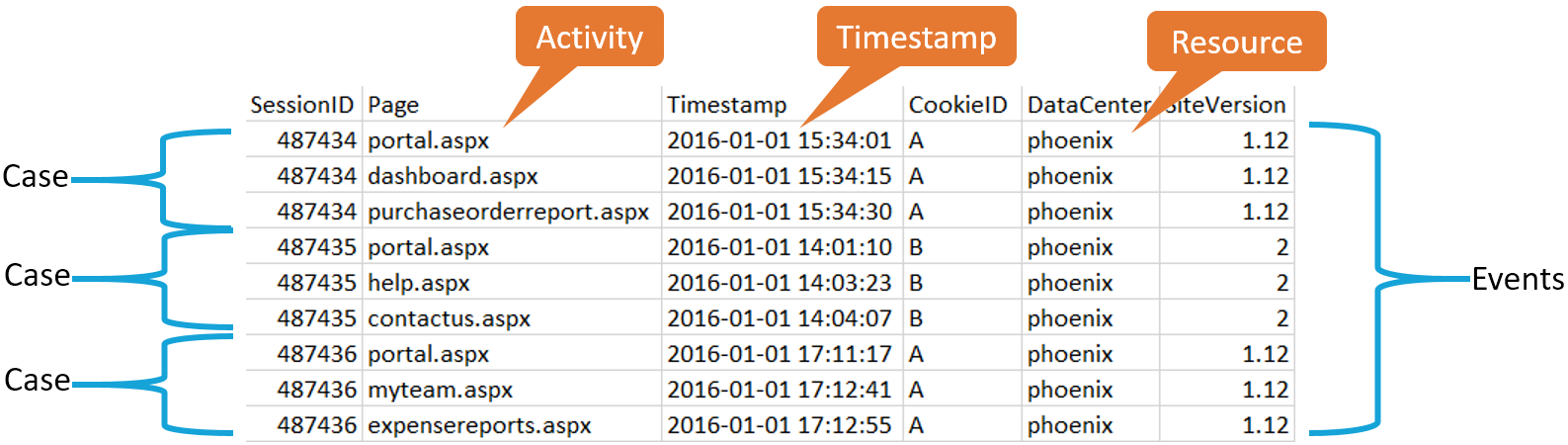
In this example, the traces for this event log are:
- portal, dashboard, purchase order report
- portal, help, contact us
- portal, my team, expense reports
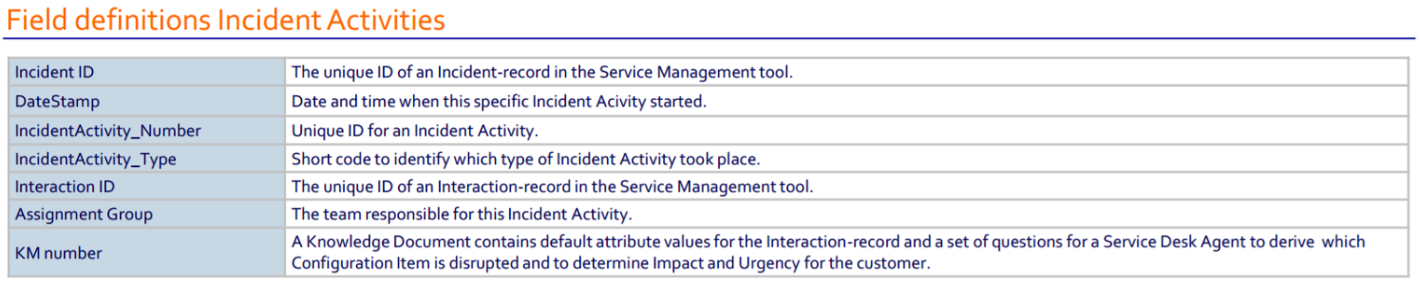
David proceeded his talk with a live demo using the Incident Activity Records dataset from the 2014 Business Processing Intelligence Challenge (BPIC).
About the meetup
In this presentation hosted by Data Science Dojo:• The scenarios and benefits of event log mining• The minimum data required for event log mining• Ingesting and analyzing event log data using R• Process Mining with ProM• Event log mining techniques to create features suitable for Machine Learning models• Where you can learn more about this very handy set of tools and techniques for process mining.
Process mining source code
David’s source code can be viewed and cloned here, at his GitHub repository for this meetup. To clean and process the dataset, he ran through his R script step-by-step. David installed the R package, edeaR, which was specifically used to analyze and the dataset.
After cleaning the dataset, he loaded the new .csv file into the process mining workbench tool, ProM, for visualization. The visualization created helped gain insights about the flow of incident activities from open to close.
Speaker: David Langer
Written by Dave Langer
