
In the rapidly evolving world of artificial intelligence, Large Language Models (LLMs) have become a cornerstone of innovation, driving advancements in natural language processing, machine learning, and beyond. As these models continue to grow in complexity and capability, the need for a structured way to evaluate and compare their performance has become increasingly important.
Enter the LLM Leaderboards—a dynamic platform that ranks these models based on various performance metrics, offering insights into their strengths and weaknesses.
Understanding LLM Leaderboards
LLM Leaderboards serve as a comprehensive benchmarking tool, providing a transparent and standardized way to assess the performance of different language models. These leaderboards evaluate models on a range of tasks, from text generation and translation to sentiment analysis and question answering. By doing so, they offer a clear picture of how each model stacks up against its peers in terms of accuracy, efficiency, and versatility.
LLM Leaderboards are platforms that rank large language models based on their performance across a variety of tasks. These tasks are designed to test the models’ capabilities in understanding and generating human language. The leaderboards provide a transparent and standardized way to compare different models, fostering a competitive environment that drives innovation and improvement.

Why Are They Important?
Transparency and Trust: LLM leaderboards provide clear insights into model capabilities and limitations, promoting transparency in AI development. This transparency helps build trust in AI technologies by ensuring advancements are made in an open and accountable manner.
Comparison and Model Selection: Leaderboards enable users to select models tailored to their specific needs by offering a clear comparison based on specific tasks and metrics. This guidance is invaluable for businesses and organizations looking to integrate AI for tasks like automating customer service, generating content, or analyzing data.
Innovation and Advancement: By fostering a competitive environment, leaderboards drive developers to enhance models for better rankings. This competition encourages researchers and developers to push the boundaries of language models, leading to rapid advancements in model architecture, training techniques, and optimization strategies.
Know more about 7 Large Language Models (LLMs) in 2024
Key Components of LLM Leaderboards
Understanding the key components of LLM leaderboards is essential for evaluating and comparing language models effectively. These components ensure that models are assessed comprehensively across various tasks and metrics, providing valuable insights for researchers and developers. Let’s explore each component in detail:
Explore Guide to LLM chatbots: Real-life applications, building techniques and LangChain’s finetuning
Task Variety
LLM leaderboards evaluate models on a diverse range of tasks to ensure comprehensive assessment. This variety helps in understanding the model’s capabilities across different applications.
Text Generation: This task assesses the model’s ability to produce coherent and contextually relevant text. It evaluates how well the model can generate human-like responses or creative content. Text generation is crucial for applications like content creation, storytelling, and chatbots, where engaging and relevant text is needed.
Translation: Translation tasks evaluate the accuracy and fluency of translations between languages. It measures how effectively a model can convert text from one language to another while maintaining meaning. Accurate translation is vital for global communication, enabling businesses and individuals to interact across language barriers.
Sentiment Analysis: This task determines the sentiment expressed in a piece of text, categorizing it as positive, negative, or neutral. It assesses the model’s ability to understand emotions and opinions. Sentiment analysis is widely used in market research, customer feedback analysis, and social media monitoring to gauge public opinion.
Read more on Sentiment Analysis: Marketing with Large Language Models (LLMs)
Question Answering: Question-answering tasks test the model’s ability to understand and respond to questions accurately. It evaluates comprehension and information retrieval skills. Effective question-answering is essential for applications like virtual assistants, educational tools, and customer support systems.

Performance Metrics
Leaderboards use several metrics to evaluate model performance, providing a standardized way to compare different models.
- BLEU Score: The BLEU (Bilingual Evaluation Understudy) score is commonly used for evaluating the quality of text translations. It measures how closely a model’s output matches a reference translation. A high BLEU score indicates accurate and fluent translations, which is crucial for language translation tasks.
- F1 Score: The F1 score balances precision and recall, often used in classification tasks. It provides a single metric that considers both false positives and false negatives. The F1 score is important for tasks like sentiment analysis and question answering, where both precision and recall are critical.
- Perplexity: Perplexity measures how well a probability model predicts a sample, with lower values indicating better performance. It is often used in language modeling tasks. Low perplexity suggests that the model can generate more predictable and coherent text, which is essential for text-generation tasks.
Benchmark Datasets
Leaderboards rely on standardized datasets to ensure fair and consistent evaluation. These datasets are carefully curated to cover a wide range of linguistic phenomena and real-world scenarios.
Benchmark datasets provide a common ground for evaluating models, ensuring that comparisons are meaningful and reliable. They help in identifying strengths and weaknesses across different models and tasks.
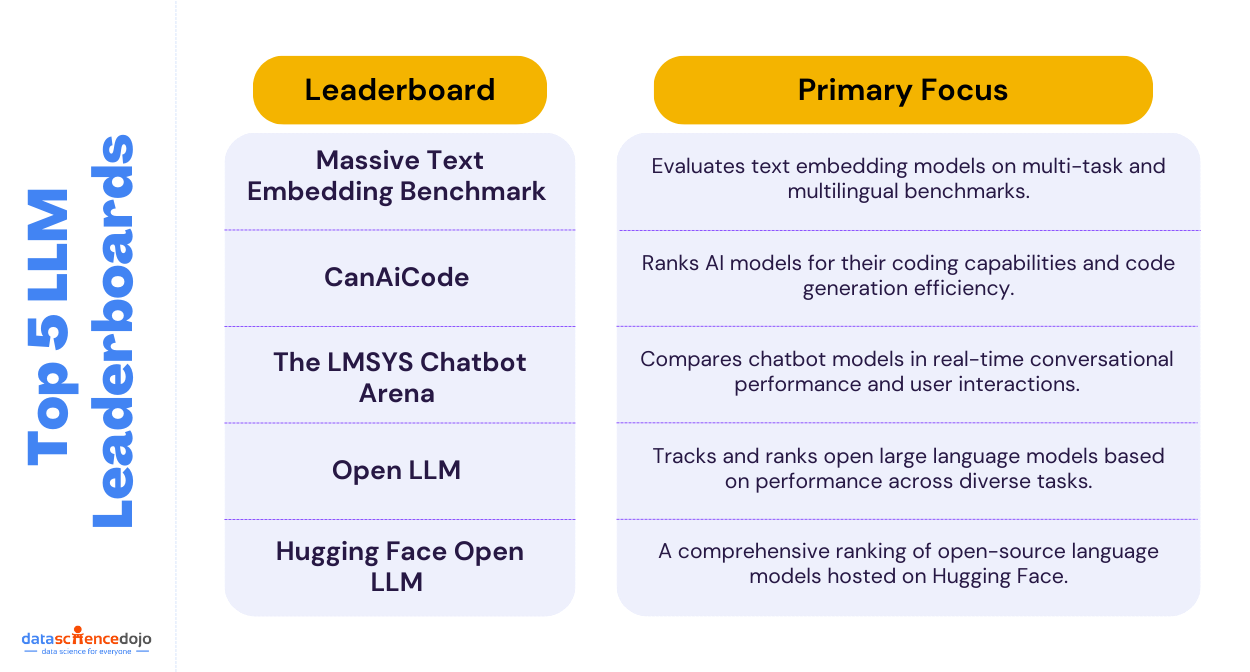
Top 5 LLM Leaderboard Platforms
LM leaderboard platforms have become essential for benchmarking and evaluating the performance of large language models. These platforms provide valuable insights into model capabilities, guiding researchers and developers in their quest for innovation.
1. Massive Text Embedding Benchmark (MTEB) Leaderboard
The MTEB Leaderboard evaluates models based on their text embedding capabilities, crucial for tasks like semantic search and recommendation systems.
Know more about 7 NLP Techniques and Tasks to Implement Using Python
2. CanAiCode Leaderboard
The CanAiCode Leaderboard is essential for evaluating AI models’ coding capabilities. It provides a platform for assessing how well models can understand and generate code, aiding developers in integrating AI into software development.
3. The LMSYS Chatbot Arena Leaderboard
The LMSYS Chatbot Arena Leaderboard evaluates chatbot models, focusing on their ability to engage in natural and coherent conversations.
4. Open LLM Leaderboard
The Open LLM Leaderboard is a vital resource for evaluating open-source large language models (LLMs). It provides a platform for assessing models, helping researchers and developers understand their capabilities and limitations.
Explore the Impact of AI-driven technology on the casual gaming industry
Key Features: This leaderboard focuses on benchmarks that test code understanding and generation, offering insights into models’ practical applications in coding tasks.
Limitations: While it provides valuable insights, it may not cover all programming languages or specific coding challenges, potentially missing niche applications.
Who Should Use: Developers and researchers interested in AI-driven coding solutions will find this leaderboard useful for comparing model performance and selecting the best fit for their needs.
5. Hugging Face Open LLM Leaderboard
The Hugging Face Open LLM Leaderboard offers a platform for evaluating open-source language models, providing standardized benchmarks for language processing.
Discover the Hugging Face Open LLM Leaderboard on Hugging Face.

The top LLM leaderboard platforms play a crucial role in advancing AI research by offering standardized evaluations. By leveraging these platforms, stakeholders can make informed decisions, driving the development of more robust and efficient language models.
Bonus Addition!
While we have explored the top 5 LLM leaderboards you must consider when evaluating your LLMs, here are 2 additional options to explore. You can look into these as well if the top 5 are not suitable choices for you.
1. Berkeley Function-Calling Leaderboard
The Berkeley Function-Calling Leaderboard evaluates models based on their ability to understand and execute function calls, essential for programming and automation.
2. Open Multilingual LLM Evaluation Leaderboard
The Open Multilingual LLM Evaluation Leaderboard assesses language models across multiple languages, crucial for global applications.
Leaderboard Metrics for LLM Evaluation

Understanding the key metrics in LLM evaluations is crucial for selecting the right model for specific applications. These metrics help in assessing the performance, efficiency, and ethical considerations of language models. Let’s delve into each category:
Read in detail about Evaluating large language models (LLMs)
Performance Metrics
Accuracy, fluency, and robustness are essential metrics for evaluating language models. Accuracy assesses how well a model provides correct responses, crucial for precision-demanding tasks like medical diagnosis. Fluency measures the naturalness and coherence of the output, important for content creation and conversational agents.
Robustness evaluates the model’s ability to handle diverse inputs without performance loss, vital for applications like customer service chatbots. Together, these metrics ensure models are precise, engaging, and adaptable.
Efficiency Metrics
Efficiency metrics like inference speed and resource usage are crucial for evaluating model performance. Inference speed measures how quickly a model generates responses, essential for real-time applications like live chat support and interactive gaming.
Resource usage assesses the computational cost, including memory and processing power, which is vital for deploying models on devices with limited capabilities, such as mobile phones or IoT devices. Efficient resource usage allows for broader accessibility and scalability, enabling models to function effectively across various platforms without compromising performance.
Ethical Metrics
Ethical metrics focus on bias, fairness, and toxicity. Bias and fairness ensure that models treat all demographic groups equitably, crucial in sensitive areas like hiring and healthcare. Toxicity measures the safety of outputs, checking for harmful or inappropriate content.
Reducing toxicity is vital for maintaining user trust and ensuring AI systems are safe for public use, particularly in social media and educational tools. By focusing on these ethical metrics, developers can create AI systems that are both responsible and reliable
Applications of LLM Leaderboards

LLM leaderboards serve as a crucial resource for businesses and organizations seeking to integrate AI into their operations. By offering a clear comparison of available models, they assist decision-makers in selecting the most suitable model for their specific needs, whether for customer service automation, content creation, or data analysis.
Explore 2023 emerging AI and Machine Learning trends
- Enterprise Use: Companies utilize leaderboards to select models that best fit their needs for customer service, content generation, and data analysis. By comparing models based on performance and efficiency metrics, businesses can choose solutions that enhance productivity and customer satisfaction.
- Academic Research: Researchers rely on standardized metrics provided by leaderboards to test new model architectures. This helps in advancing the field of AI by identifying strengths and weaknesses in current models and guiding future research directions.
- Product Development: Developers use leaderboards to choose models that align with their application needs. By understanding the performance and efficiency of different models, developers can integrate the most suitable AI solutions into their products, ensuring optimal functionality and user experience.
These applications highlight the importance of LLM leaderboards in guiding the development and deployment of AI technologies. By providing a comprehensive evaluation framework, leaderboards help stakeholders make informed decisions, ensuring that AI systems are effective, efficient, and ethical.
Challenges and Future Directions

As the landscape of AI technologies rapidly advances, the role of LLM Leaderboards becomes increasingly critical in shaping the future of language models. These leaderboards not only drive innovation but also set the stage for addressing emerging challenges and guiding future directions in AI development.
Know about NLP Techniques and Tasks to Implement Using Python
- Evolving Evaluation Criteria: As AI technologies continue to evolve, so too must the evaluation criteria used by leaderboards. This evolution is necessary to ensure that models are assessed on their real-world applicability and not just their ability to perform well on specific tasks.
- Addressing Ethical Concerns: Future leaderboards will likely incorporate ethical considerations, such as bias and fairness, into their evaluation criteria. This shift will help ensure that AI technologies are developed and deployed in a responsible and equitable manner.
- Incorporating Real-World Scenarios: To better reflect real-world applications, leaderboards may begin to include more complex and nuanced tasks that require models to understand context, intent, and cultural nuances.
Looking ahead, the future of LLM Leaderboards will likely involve more nuanced evaluation criteria that consider ethical considerations, such as bias and fairness, alongside traditional performance metrics. This evolution will ensure that as AI continues to advance, it does so in a way that is both effective and responsible.
