

The race of big tech and startups to create the top language model has us eager to see how things change.
Different companies are training new models to achieve better accuracy, enhanced understanding of context, and more nuanced generation capabilities, pushing the boundaries of what AI can achieve in terms of natural language understanding and generation.
A standout approach in this field is employed by Mistral AI through its development of the Mixtral of Experts model.

Distinctive for its use of the Sparse Mixture of Experts (SMoE) technique, Mixtral amalgamates the expertise of various specialized models. Each of these models excels in different areas of data processing, enabling Mixtral to navigate the complexities of language with notable precision.
This article aims to provide an in-depth examination of Mixtral, including its operational framework, unique attributes, and performance metrics. We will explore how Mixtral differentiates itself from other models in the market and the advantages it offers.
How Does Mixtral of Experts Work?
The Mixtral of Experts’ 8x7B model is a smart tool that’s built to be really good at a bunch of different tasks. It does this by not using all its tools at once, but just a few at a time for each piece of information it looks at.
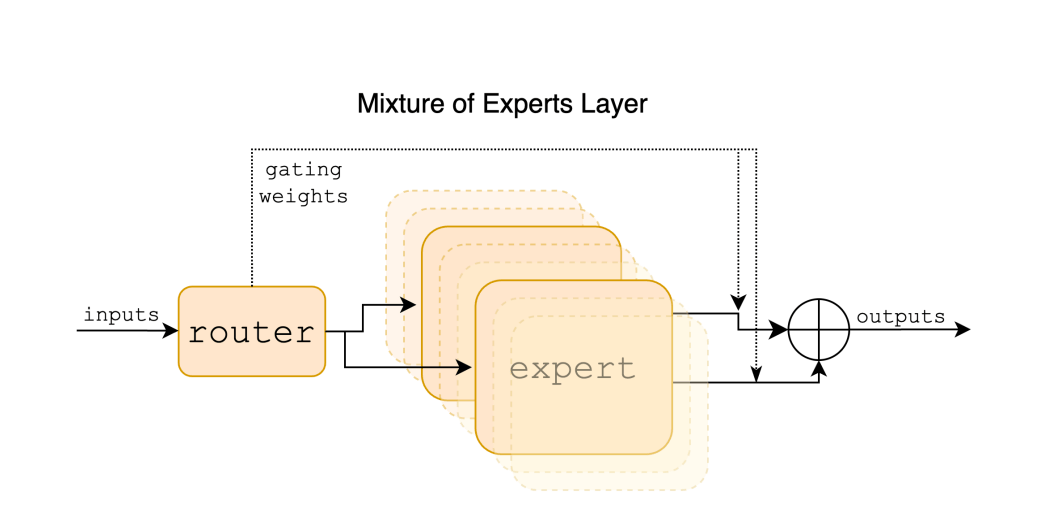
Think of it like a toolbox where, out of 8 tools, it picks the best 2 for the job at hand. Each layer of this model has these 8 special tools or “experts,” and it chooses which ones to use based on what it’s working on. This way, it can be really efficient and do its job well without needing to use everything it has all at once.
The process from the input through the router to the expert and the resulting output works as follows:
Input: A given input vector, representing a token from a sequence, enters the model. Each token is processed individually by going through the layers of the model. The input is part of a larger context, which can be a span of up to 32k tokens. Read how embeddings work here.
Router: After the initial input, the router within the Mixture of Experts layer determines which experts to engage for processing the token. Specifically, the router selects 2 out of the 8 available experts based on the token’s characteristics. This selection is done using a gating network that assigns weights to the experts, guiding which experts are to be used.
Also learn about Mistral AI’s Large model
Experts: Once the experts are selected by the router, the input token is processed by these experts. Each expert consists of a standard feedforward block as found in a transformer architecture. The outputs of the two chosen experts are then combined through a weighted sum, where the weights are determined by the gating network’s output.
Output: The final output for the token is the combined result from the two experts it was routed to. Essentially, the output of the MoE layer is the weighted sum of the outputs of the expert networks.
This process is repeated for each token within the sequence, allowing the Mixtral model to effectively process and generate the response or continuation based on the input it receives.
Unique Attributes of Mixtral’s Approach
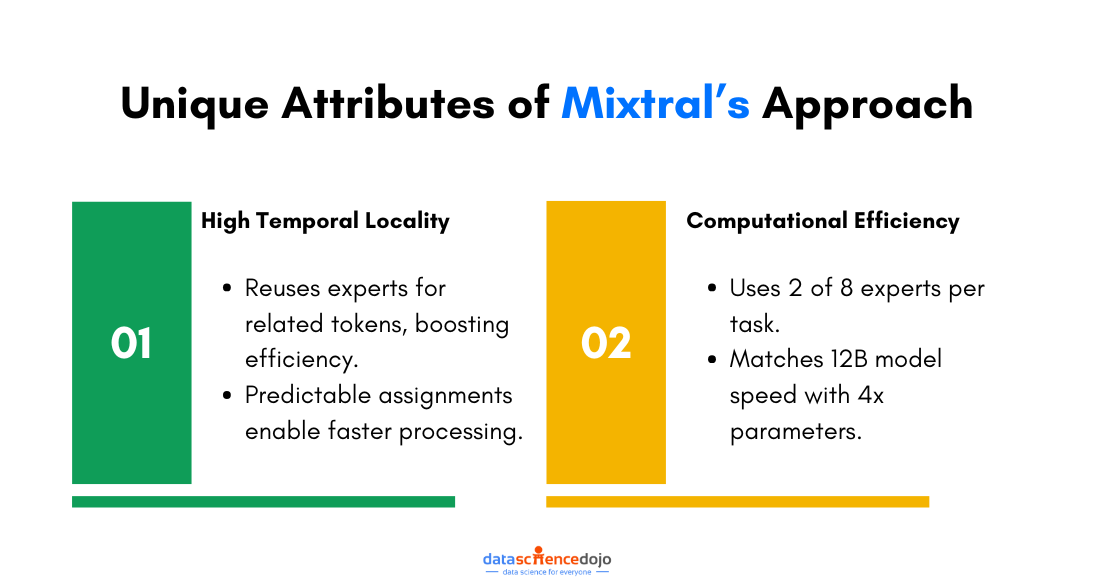
- High Temporal Locality
The interesting part is that Mixtral tends to pick the same expert or group of experts for words that are close together or related in some way i.e. the model possesses “high temporal locality”.
It’s like noticing that a certain part of your game has a lot of jumping, so you stick with the character who’s best at jumping for that whole section.
Another interesting read: Mistral 7B: A Breakthrough in LLMs
The implications of such high temporal locality are substantial for both training and inference efficiency. It suggests that expert assignments can be somewhat predicted over time, providing opportunities to optimize the model’s training and runtime performance.
For instance, the predictability in expert utilization can lead to more efficient caching strategies, wherein the outputs of frequently used experts are temporarily stored, thus speeding up computations for consecutive tokens that are routed to the same experts.
- Computational Efficiency via Dual Expert Strategy
Mixtral uses only two out of eight experts to handle each piece of data it processes. This selective engagement is key for its computational efficiency, allowing it to work as fast as a model with 12 billion parameters, even though it has four times as many parameters in total.
Performance of Mixtral
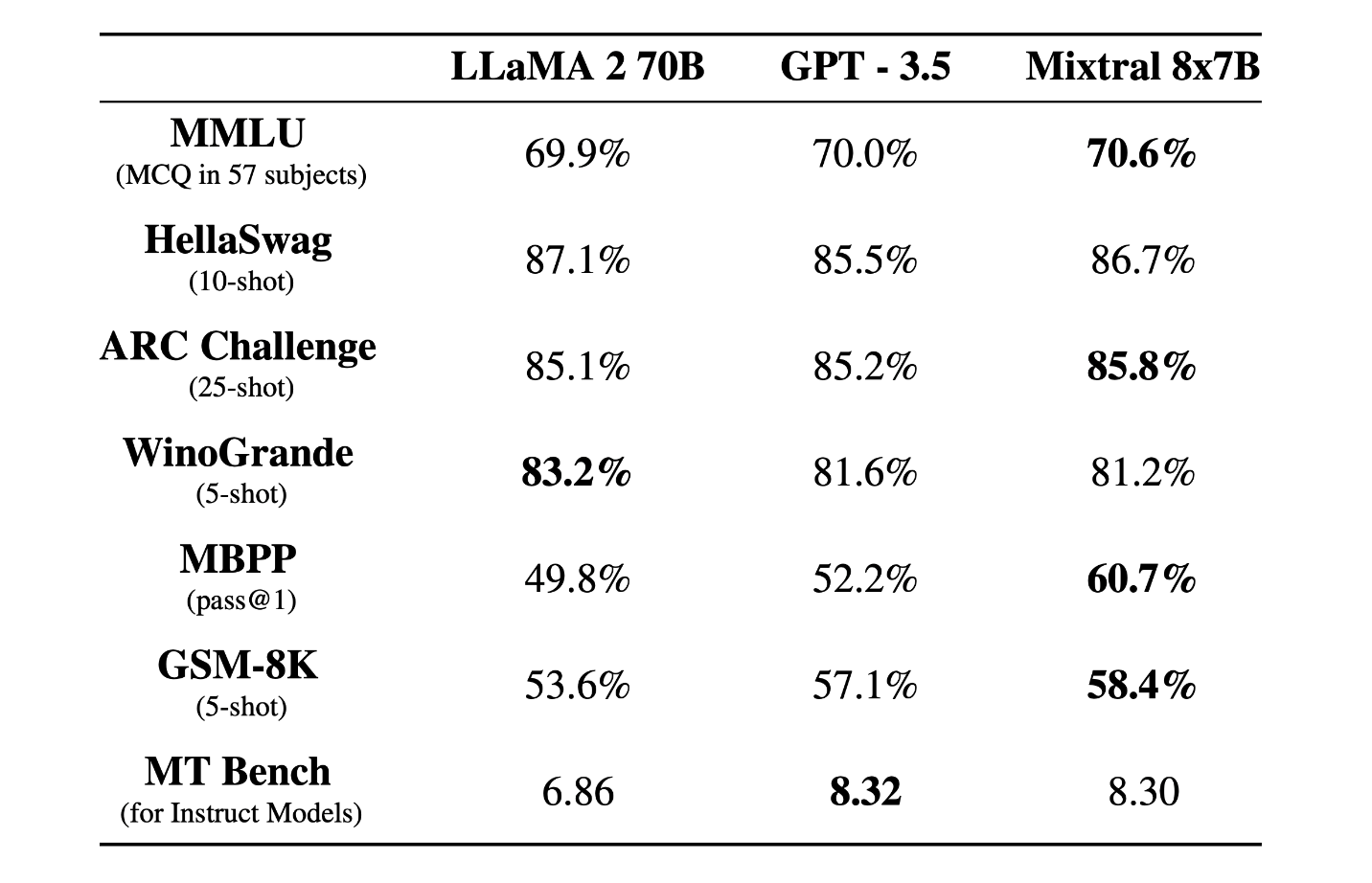
Mixtral 8x7B is compared directly with Llama 2 70B and GPT-3.5 and is found to perform similarly or above these models in benchmarks. Specifically, it scores higher on MMLU and does exceptionally well on MT-Bench.
Hallucinations and Bias
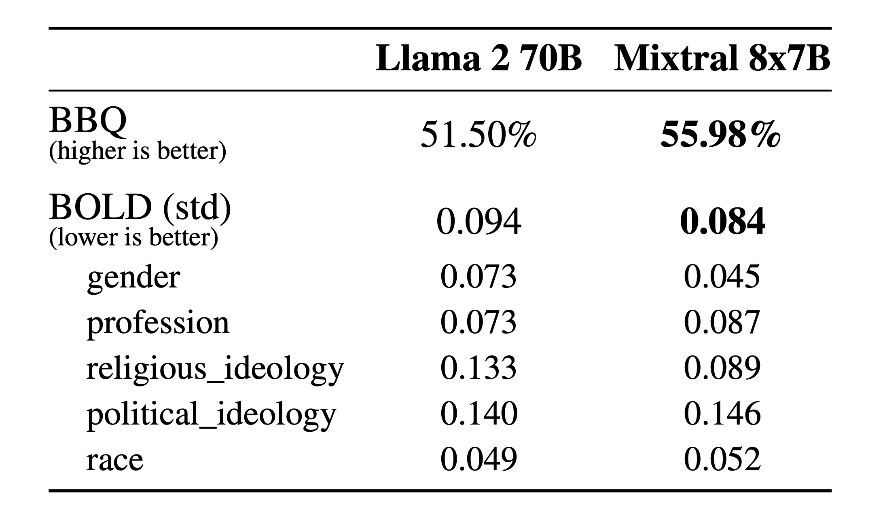
In comparison with Llama 2, Mixtral of Experts exhibits reduced bias in the BBQ benchmark. Furthermore, it tends to show a more favorable outlook than Llama 2 in the BOLD benchmark, while maintaining comparable variations across different aspects.
Read more about algorithmic bias and skewed decision making
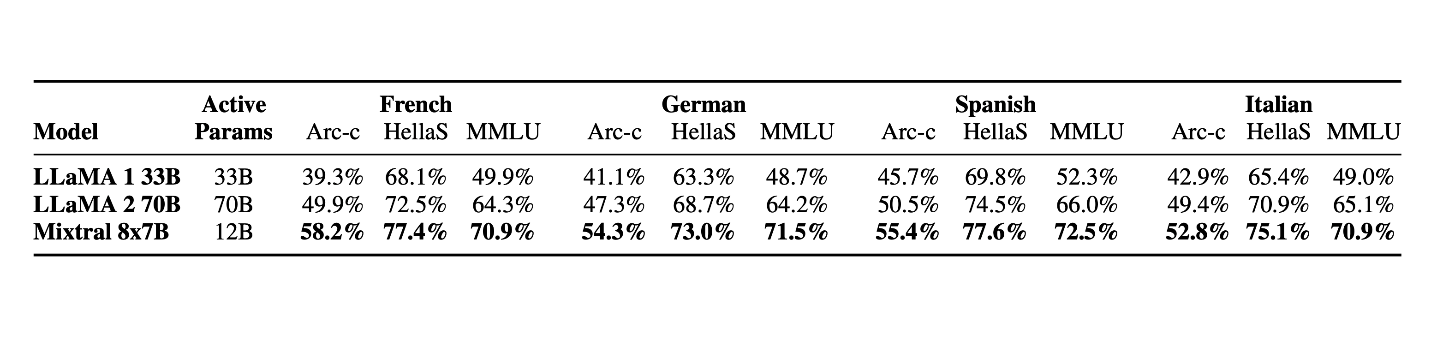
Multilingualism
Mixtral vastly outperforms Llama 2 70B on multilingual benchmarks, demonstrating its strength in understanding and generating text across different languages
Mixtral: Revolutionizing AI Efficiency and Multilinguality
Mistral AI’s Mixtral model has carved out a niche for itself, showcasing the power and precision of the Sparse Mixture of Experts approach. As we’ve navigated through the intricacies of Mixtral, from its unique architecture to its standout performances on various benchmarks, it’s clear that this model is not just another entrant in the race to AI supremacy. It’s a harbinger of a nuanced, efficient future in large language models.

By strategically deploying only two of its eight available experts for each input token, the model achieves a balance between computational efficiency and deep, nuanced understanding that few others can claim. This approach not only enhances processing speed but also reduces bias and improves performance across languages, setting a new standard for what AI can achieve.
You might also like: The 7B Showdown of LLMS
As we conclude our exploration of the genius of the Sparse Mixture of Experts by Mistral AI, it’s evident that this model represents a significant leap forward. Through its adept handling of complex language tasks, it stands as a testament to the potential of combining specialized expertise with smart, scalable architecture. The future of AI looks brighter with Mistral AI paving the way, promising models that are not only more efficient and versatile but also more understanding of the vast tapestry of human language.
