

In the debate of LlamaIndex vs LangChain, developers can align their needs with the capabilities of both tools, resulting in an efficient application.
LLMs have become indispensable in various industries for tasks such as generating human-like text, translating languages, and providing answers to questions. At times, the LLM responses amaze you, as they are more prompt and accurate than humans. This demonstrates their significant impact on the technology landscape today.
As we delve into the arena of artificial intelligence, two tools emerge as pivotal enablers: LLamaIndex and LangChain. LLamaIndex offers a distinctive approach, focusing on data indexing and enhancing the performance of LLMs, while LangChain provides a more general-purpose framework, flexible enough to pave the way for a broad spectrum of LLM-powered applications.

Although both LlamaIndex and LangChain are capable of developing comprehensive generative AI applications, each focuses on different aspects of the application development process.
The figure below illustrates how LlamaIndex is more concerned with the initial stages of data handling—like loading, ingesting, and indexing to form a base of knowledge. In contrast, LangChain focuses on the latter stages, particularly on facilitating interactions between the AI (large language models, or LLMs) and users through multi-agent systems.
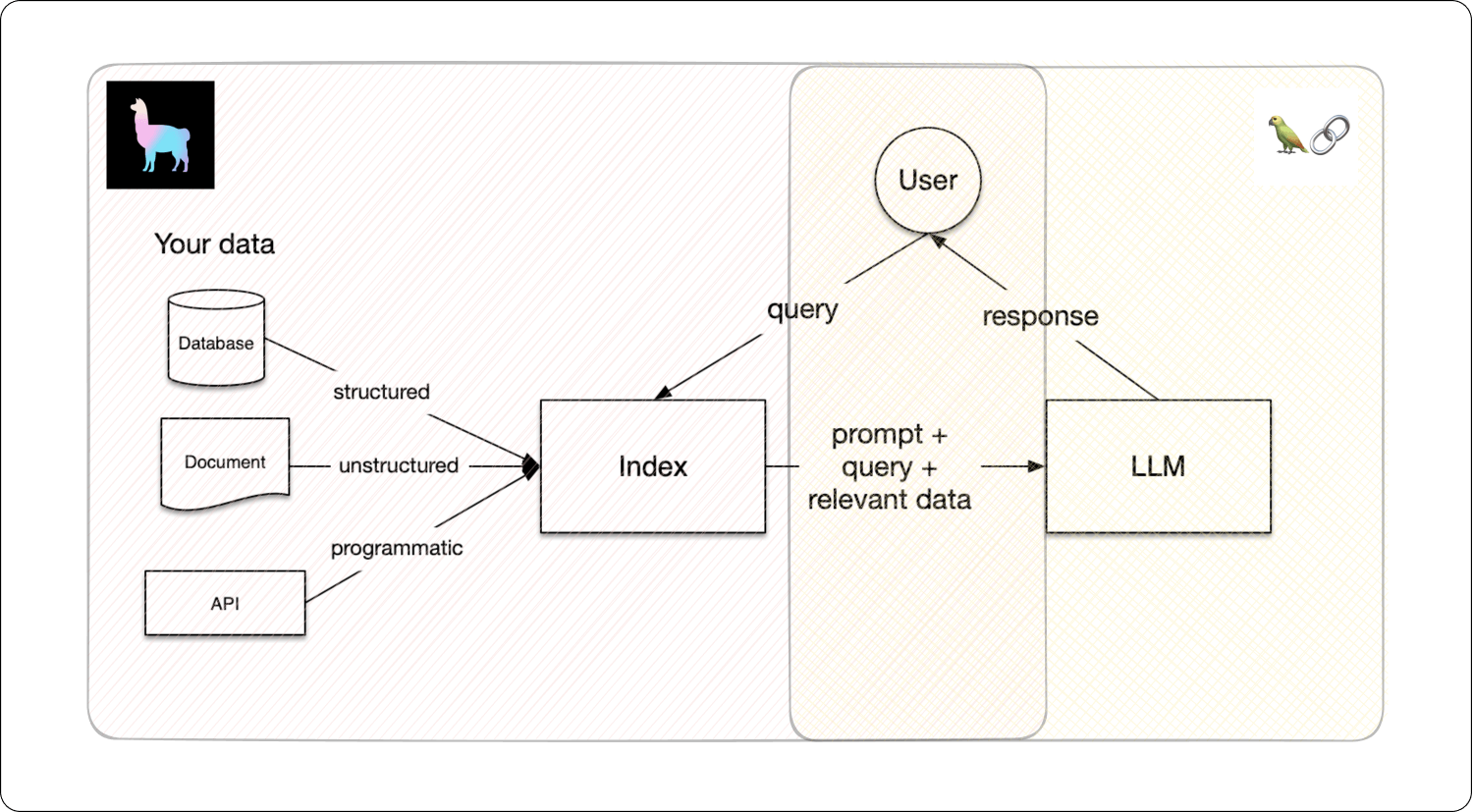
Essentially, the combination of LlamaIndex’s data management capabilities with LangChain’s user interaction enhancement can lead to more powerful and efficient generative AI applications. Let’s begin by understanding each of the two framework’s roles in building LLMs.
LLamaIndex: The Bridge between Data and LLM Power
LLamaIndex steps forward as an essential tool, allowing users to build structured data indexes, use multiple LLMs for diverse applications, and improve data queries using natural language.
It stands out for its data connectors and index-building prowess, which streamline data integration by ensuring direct data ingestion from native sources, fostering efficient data retrieval, and enhancing the quality and performance of data used with LLMs.
LLamaIndex distinguishes itself with its engines, which create a symbiotic relationship between data sources and LLMs through a flexible framework. This remarkable synergy paves the way for applications like semantic search and context-aware query engines that consider user intent and context, delivering tailored and insightful responses.
Learn all about LlamaIndex from its Co-founder and CEO, Jerry Liu, himself!
LlamaIndex Features
LlamaIndex is an innovative tool designed to enhance the utilization of large language models (LLMs) by seamlessly connecting your data with the powerful computational capabilities of these models. It possesses a suite of features that streamline data tasks and amplify the performance of LLMs for a variety of applications, including:
Data Connectors:
- Data connectors simplify the integration of data from various sources into the data repository, bypassing manual and error-prone extraction, transformation, and loading (ETL) processes.
- These connectors enable direct data ingestion from native formats and sources, eliminating the need for time-consuming data conversions.
- Advantages of using data connectors include automated enhancement of data quality, data security via encryption, improved data performance through caching, and reduced maintenance for data integration solutions.
Engines:
- LLamaIndex Engines are the driving force that bridges LLMs and data sources, ensuring straightforward access to real-world information.
- The engines are equipped with smart search systems that comprehend natural language queries, allowing for smooth interactions with data.
- They are not only capable of organizing data for expeditious access but also enriching LLM-powered applications by adding supplementary information and aiding in LLM selection for specific tasks.
Data Agents:
- Data agents are intelligent, LLM-powered components within LLamaIndex that perform data management effortlessly by dealing with various data structures and interacting with external service APIs.
- These agents go beyond static query engines by dynamically ingesting and modifying data, adjusting to ever-changing data landscapes.
- Building a data agent involves defining a decision-making loop and establishing tool abstractions for a uniform interaction interface across different tools.
- LLamaIndex supports OpenAI Function agents as well as ReAct agents, both of which harness the strength of LLMs in conjunction with tool abstractions for a new level of automation and intelligence in data workflows.
Read this blog on LlamaIndex to learn more in detail
Application Integrations:
- The real strength of LLamaIndex is revealed through its wide array of integrations with other tools and services, allowing the creation of powerful, versatile LLM-powered applications.
- Integrations with vector stores like Pinecone and Milvus facilitate efficient document search and retrieval.
- LLamaIndex can also merge with tracing tools such as Graphsignal for insights into LLM-powered application operations and integrate with application frameworks such as Langchain and Streamlit for easier building and deployment.
- Integrations extend to data loaders, agent tools, and observability tools, thus enhancing the capabilities of data agents and offering various structured output formats to facilitate the consumption of application results.
An interesting read for you: Roadmap Of LlamaIndex To Creating Personalized Q&A Chatbots
LangChain: The Flexible Architect for LLM-Infused Applications
In contrast, LangChain emerges as a master of versatility. It’s a comprehensive, modular framework that empowers developers to combine LLMs with various data sources and services.
LangChain thrives on its extensibility, wherein developers can orchestrate operations such as retrieval augmented generation (RAG), crafting steps that use external data in the generative processes of LLMs. With RAG, LangChain acts as a conduit, transporting personalized data during creation, embodying the magic of tailoring output to meet specific requirements.
Features of LangChain
Key components of LangChain include Model I/O, retrieval systems, and chains.
Model I/O:
- LangChain’s Module Model I/O facilitates interactions with LLMs, providing a standardized and simplified process for developers to integrate LLM capabilities into their applications.
- It includes prompts that guide LLMs in executing tasks, such as generating text, translating languages, or answering queries.
- Multiple LLMs, including popular ones like the OpenAI API, Bard, and Bloom, are supported, ensuring developers have access to the right tools for varied tasks.
- The input parsers component transforms user input into a structured format that LLMs can understand, enhancing the applications’ ability to interact with users.
Here’s a detailed guide to learn about Retrieval Augmented Generation
Retrieval Systems:
- One of the standout features of LangChain is the Retrieval Augmented Generation (RAG), which enables LLMs to access external data during the generative phase, providing personalized outputs.
- Another core component is the Document Loaders, which provide access to a vast array of documents from different sources and formats, supporting the LLM’s ability to draw from a rich knowledge base.
- Text embedding models are used to create text embeddings that capture the semantic meaning of texts, improving related content discovery.
- Vector Stores are vital for efficient storage and retrieval of embeddings, with over 50 different storage options available.
- Different retrievers are included, offering a range of retrieval algorithms from basic semantic searches to advanced techniques that refine performance.
A comprehensive guide to understand what is LangChain
Chains:
- LangChain introduces Chains, a powerful component for building more complex applications that require the sequential execution of multiple steps or tasks.
- Chains can either involve LLMs working in tandem with other components, offer a traditional chain interface, or utilize the LangChain Expression Language (LCEL) for chain composition.
- Both pre-built and custom chains are supported, indicating a system designed for versatility and expansion based on the developer’s needs.
- The Async API is featured within LangChain for running chains asynchronously, reinforcing the usability of elaborate applications involving multiple steps.
- Custom Chain creation allows developers to forge unique workflows and add memory (state) augmentation to Chains, enabling a memory of past interactions for conversation maintenance or progress tracking.

Comparing LLamaIndex and LangChain
When we compare LLamaIndex with LangChain, we see complementary visions that aim to maximize the capabilities of LLMs. LLamaIndex is the superhero of tasks that revolve around data indexing and LLM augmentation, like document search and content generation.
On the other hand, LangChain boasts its prowess in building robust, adaptable applications across a plethora of domains, including text generation, translation, and summarization.
As developers and innovators seek tools to expand the reach of LLMs, delving into the offerings of LLamaIndex and LangChain can guide them toward creating standout applications that resonate with efficiency, accuracy, and creativity.
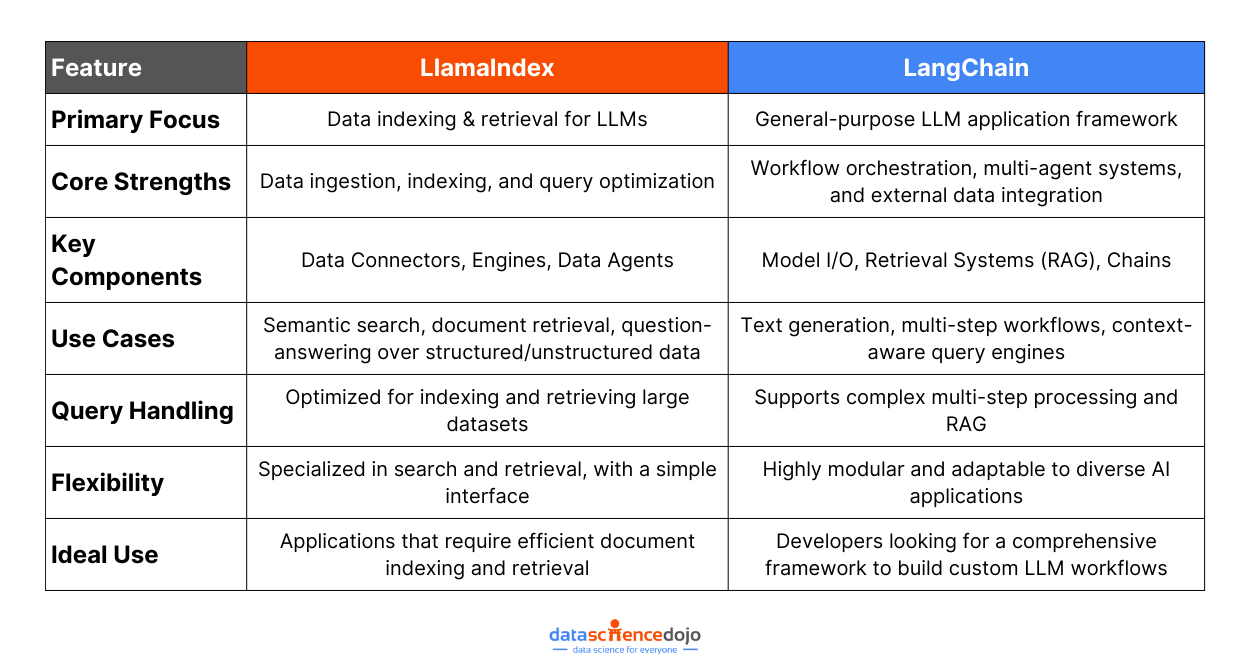
Focused Approach vs Flexibility
- LlamaIndex:
- Purposefully crafted for search and retrieval applications, giving it an edge in efficient indexing and organizing data for swift access.
- Features a simplified interface that allows querying LLMs straightforwardly, leading to pertinent document retrieval.
- Optimized explicitly for indexing and retrieval, leading to higher accuracy and speed in search and summarization tasks.
- Specialized in handling large amounts of data efficiently, making it highly suitable for dedicated search and retrieval tasks that demand robust performance.
- Offers a simple interface designed primarily for constructing search and retrieval applications, facilitating straightforward interactions with LLMs for efficient document retrieval.
- Specializes in the indexing and retrieval process, thus optimizing search and summarization capabilities to manage large amounts of data effectively.
- Allows for creating organized data indexes, with user-friendly features that streamline data tasks and enhance LLM performance.
Explore which is the best tool to optimize LLM performance
- LangChain:
- Presents a comprehensive and modular framework adept at building diverse LLM-powered applications with general-purpose functionalities.
- Provides a flexible and extensible structure that supports a variety of data sources and services, which can be artfully assembled to create complex applications.
- Includes tools like Model I/O, retrieval systems, chains, and memory systems, offering control over the LLM integration to tailor solutions for specific requirements.
- Presents a comprehensive and modular framework adept at building diverse LLM-powered applications with general-purpose functionalities.
- Provides a flexible and extensible structure that supports a variety of data sources and services, which can be artfully assembled to create complex applications.
- Includes tools like Model I/O, retrieval systems, chains, and memory systems, offering control over the LLM integration to tailor solutions for specific requirements.
Use Cases and Case Studies
LlamaIndex is engineered to harness the strengths of large language models for practical applications, with a primary focus on streamlining search and retrieval tasks. Below are detailed use cases for LlamaIndex, specifically centered around semantic search, and case studies that highlight its indexing capabilities:
Semantic Search with LlamaIndex:
- Tailored to understand the intent and contextual meaning behind search queries, it provides users with relevant and actionable search results.
- Utilizes indexing capabilities that lead to increased speed and accuracy, making it an efficient tool for semantic search applications.
- Empower developers to refine the search experience by optimizing indexing performance and adhering to best practices that suit their application needs.
Read in depth about the mystery of indexing
Case Studies Showcasing Indexing Capabilities:
- Data Indexes: LlamaIndex’s data indexes are akin to a super-speedy assistant’ for data searches, enabling users to interact with their data through question-answering and chat functions efficiently.
- Engines: At the heart of indexing and retrieval, LlamaIndex engines provide a flexible structure that connects multiple data sources with LLMs, thereby enhancing data interaction and accessibility.
- Data Agents: LlamaIndex also includes data agents, which are designed to manage both “read” and “write” operations. They interact with external service APIs and handle unstructured or structured data, further boosting automation in data management.
Due to its granular control and adaptability, LangChain’s framework is specifically designed to build complex applications, including context-aware query engines. Here’s how LangChain facilitates the development of such sophisticated applications:
- Context-Aware Query Engines: LangChain allows the creation of context-aware query engines that consider the context in which a query is made, providing more precise and personalized search results.
- Flexibility and Customization: Developers can utilize LangChain’s granular control to craft custom query processing pipelines, which is crucial when developing applications that require understanding the nuanced context of user queries.
- Integration of Data Connectors: LangChain enables the integration of data connectors for effortless data ingestion, which is beneficial for building query engines that pull contextually relevant data from diverse sources.
- Optimization for Specific Needs: With LangChain, developers can optimize performance and fine-tune components, allowing them to construct context-aware query engines that cater to specific needs and provide customized results, thus ensuring the most optimal search experience for users.

Which Framework Should I Choose? LlamaIndex vs LangChain
Understanding these unique aspects empowers developers to choose the right framework for their specific project needs:
- Opt for LlamaIndex if you are building an application with a keen focus on search and retrieval efficiency and simplicity, where high throughput and processing of large datasets are essential.
- Choose LangChain if you aim to construct more complex, flexible LLM applications that might include custom query processing pipelines, multimodal integration, and a need for highly adaptable performance tuning.
In conclusion, by recognizing the unique features and differences between LlamaIndex and LangChain, developers can more effectively align their needs with the capabilities of these tools, resulting in the construction of more efficient, powerful, and accurate search and retrieval applications powered by large language models.