

Large Language Models (LLMs) are growing smarter, transforming how we interact with technology. Yet, they stumble over a significant quality i.e. accuracy. Often, they provide unreliable information or guess answers to questions they don’t understand—guesses that can be completely wrong. It is called hallucination.
This issue is a major concern for enterprises looking to leverage LLMs. How do we tackle this problem? Retrieval Augmented Generation (RAG) offers a viable solution, enabling LLMs to access up-to-date, relevant information, and significantly improving their responses.
However, there are RAG framework challenges associated with the process. In this blog, we will explore the key RAG challenges in building LLM applications.
Tune in to our podcast and dive deep into RAG, fine-tuning, LlamaIndex, and LangChain in detail!
You can learn more about LangChain and its use cases
Understanding Retrieval Augmented Generation (RAG)
RAG is a framework that retrieves data from external sources and incorporates it into the LLM’s decision-making process. This allows the model to access real-time information and address knowledge gaps. The retrieved data is synthesized with the LLM’s internal training data to generate a response.
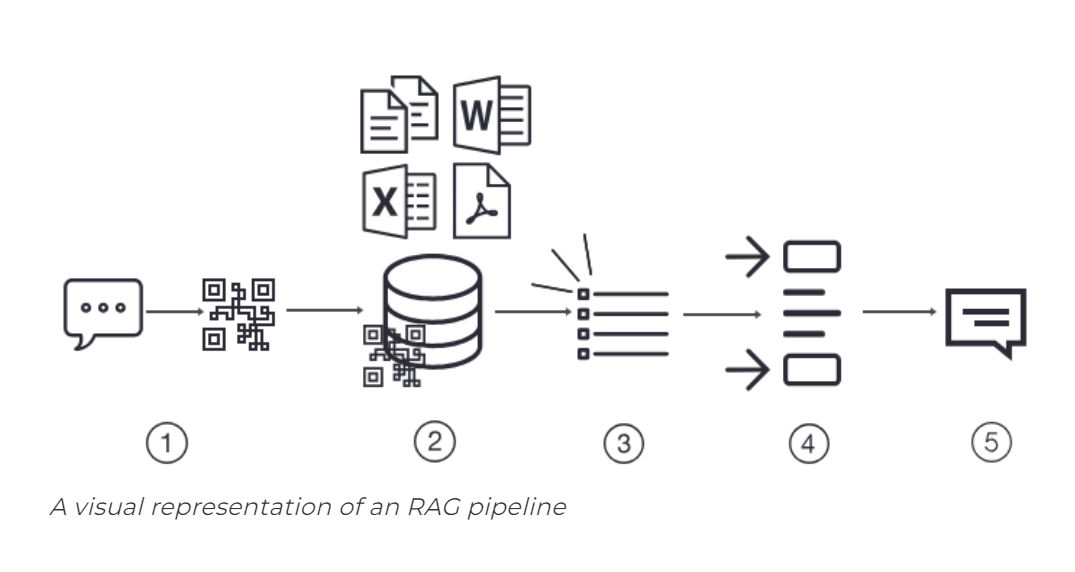
Read more: RAG and finetuning: A comprehensive guide to understanding the two approaches
RAG Challenges when Bringing LLM Applications to Production
Prototyping a RAG application is easy, but making it performant, robust, and scalable to a large knowledge corpus is hard.
There are three important steps in a RAG framework i.e. Data Ingestion, Retrieval, and Generation. In this blog, we will be dissecting the challenges encountered based on each stage of the RAG pipeline specifically from the perspective of production, and then propose relevant solutions.
Let’s dig in!
Stage 1: Data Ingestion Pipeline and its Common Pain Points
The ingestion stage is a preparation step for building a RAG pipeline, similar to the data cleaning and preprocessing steps in a machine learning pipeline. Usually, the ingestion stage consists of the following steps:
- Collect data
- Chunk data
- Generate vector embeddings of chunks
- Store vector embeddings and chunks in a vector database
The efficiency and effectiveness of the data ingestion phase significantly influence the overall performance of the system.
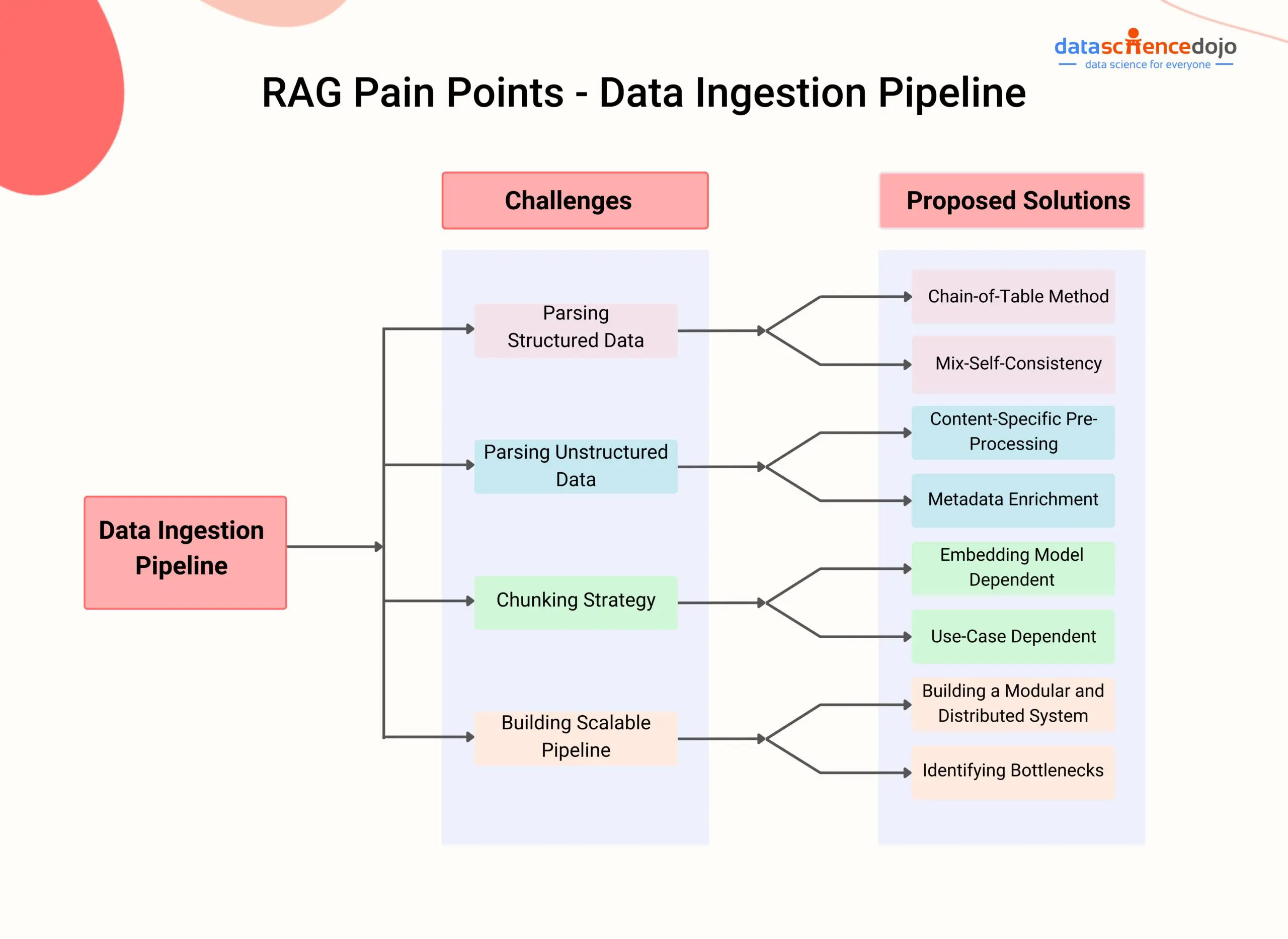
Challenge 1: Data Extraction
- Parsing complex data structures: Extracting data from various types of documents, such as PDFs with embedded tables or images, can be challenging. These complex structures require specialized techniques to extract the relevant information accurately.
- Handling unstructured data: Dealing with unstructured data, such as free-flowing text or natural language, can be difficult.
Proposed Solutions
Better parsing techniques: Enhancing parsing techniques is key to solving the data extraction challenge in RAG-based LLM applications, enabling more accurate and efficient information extraction from complex data structures like PDFs with embedded tables or images.
Llama Parse is a great tool by LlamaIndex that significantly improves data extraction for RAG systems by adeptly parsing complex documents into structured markdowns.
Chain-of-the-table approach: The chain-of-table approach, as detailed by Wang et al., merges table analysis with step-by-step information extraction strategies. This technique aids in dissecting complex tables to pinpoint and extract specific data segments, enhancing tabular question-answering capabilities in RAG systems.
Mix-self-consistency: Large Language Models (LLMs) can analyze tabular data through two primary methods:
- Direct prompting for textual reasoning
- Program synthesis for symbolic reasoning, utilizing languages like Python or SQL
Explore the SQL vs NoSQL debate in detail
According to the study “Rethinking Tabular Data Understanding with Large Language Models” by Liu and colleagues, LlamaIndex introduced the MixSelfConsistencyQueryEngine. This engine combines outcomes from both textual and symbolic analysis using a self-consistency approach, such as majority voting, to attain state-of-the-art (SoTA) results. Below is an example code snippet. For further information, visit LlamaIndex’s complete notebook.

Challenge 2: Picking the Right Chunk Size and Chunking Strategy
- Determining the right chunk size: Finding the optimal chunk size for dividing documents into manageable parts is a challenge. Larger chunks may contain more relevant information but can reduce retrieval efficiency and increase processing time. Finding the optimal balance is crucial.
- Defining chunking strategy: Deciding how to partition the data into chunks requires careful consideration. Depending on the use case, different strategies may be necessary, such as sentence-based or paragraph-based chunking.
Proposed Solutions
Fine-tuning embedding models
Fine-tuning embedding models plays a pivotal role in solving the chunking challenge in RAG pipelines, enhancing both the quality and relevance of contexts retrieved during ingestion. By incorporating domain-specific knowledge and training on pertinent data, these models excel in preserving context, ensuring chunks maintain their original meaning.
This fine-tuning process aids in identifying the optimal chunk size, striking a balance between comprehensive context capture and efficiency, thus minimizing noise. Additionally, it significantly curtails hallucinations—erroneous or irrelevant information generation—by honing the model’s ability to accurately identify and extract relevant chunks.
According to experiments conducted by LlamaIndex, fine-tuning your embedding model can lead to a 5–10% performance increase in retrieval evaluation metrics.
Read in detail about embeddings and their role in LLMs
Use Case-Dependent Chunking
Use case-dependent chunking tailors the segmentation process to the specific needs and characteristics of the application. Different use cases may require different granularity in data segmentation:
- Detailed analysis: Some applications might benefit from very fine-grained chunks to extract detailed information from the data.
- Broad overview: Others might need larger chunks that provide a broader context, which is important for understanding general themes or summaries.
Embedding Model-Dependent Chunking
Embedding model-dependent chunking aligns the segmentation strategy with the characteristics of the underlying embedding model used in the RAG framework. Embedding models convert text into numerical representations, and their capacity to capture semantic information varies:
- Model capacity: Some models are better at understanding broader contexts, while others excel at capturing specific details. Chunk sizes can be adjusted to match what the model handles best.
- Semantic sensitivity: If the embedding model is highly sensitive to semantic nuances, smaller chunks may be beneficial to capture detailed semantics. Conversely, for models that excel at capturing broader contexts, larger chunks might be more appropriate.
Learn more about retrieval augmented generation
Challenge 3: Creating a Robust and Scalable Pipeline
One of the critical challenges in implementing RAG is creating a robust and scalable pipeline that can effectively handle a large volume of data and continuously index and store it in a vector database. This challenge is of utmost importance as it directly impacts the system’s ability to accommodate user demands and provide accurate, up-to-date information.
Proposed Solutions
Building a modular and distributed system
To build a scalable pipeline for managing billions of text embeddings, a modular and distributed system is crucial. This system separates the pipeline into scalable units for targeted optimization and employs distributed processing for parallel operation efficiency.
Horizontal scaling allows the system to expand with demand, supported by an optimized data ingestion process and a capable vector database for large-scale data storage and indexing. This approach ensures scalability and technical robustness in handling vast amounts of text embeddings.
Navigate text generation with Google AI
Stage 2: Retrieval and its Pain Points
Retrieval in RAG involves the process of accessing and extracting information from authoritative external knowledge sources, such as databases, documents, and knowledge graphs. If the information is retrieved correctly in the right format, then the answers generated will be correct as well.
However, you know the catch. Effective retrieval is a pain, and you can encounter several issues during this important stage.
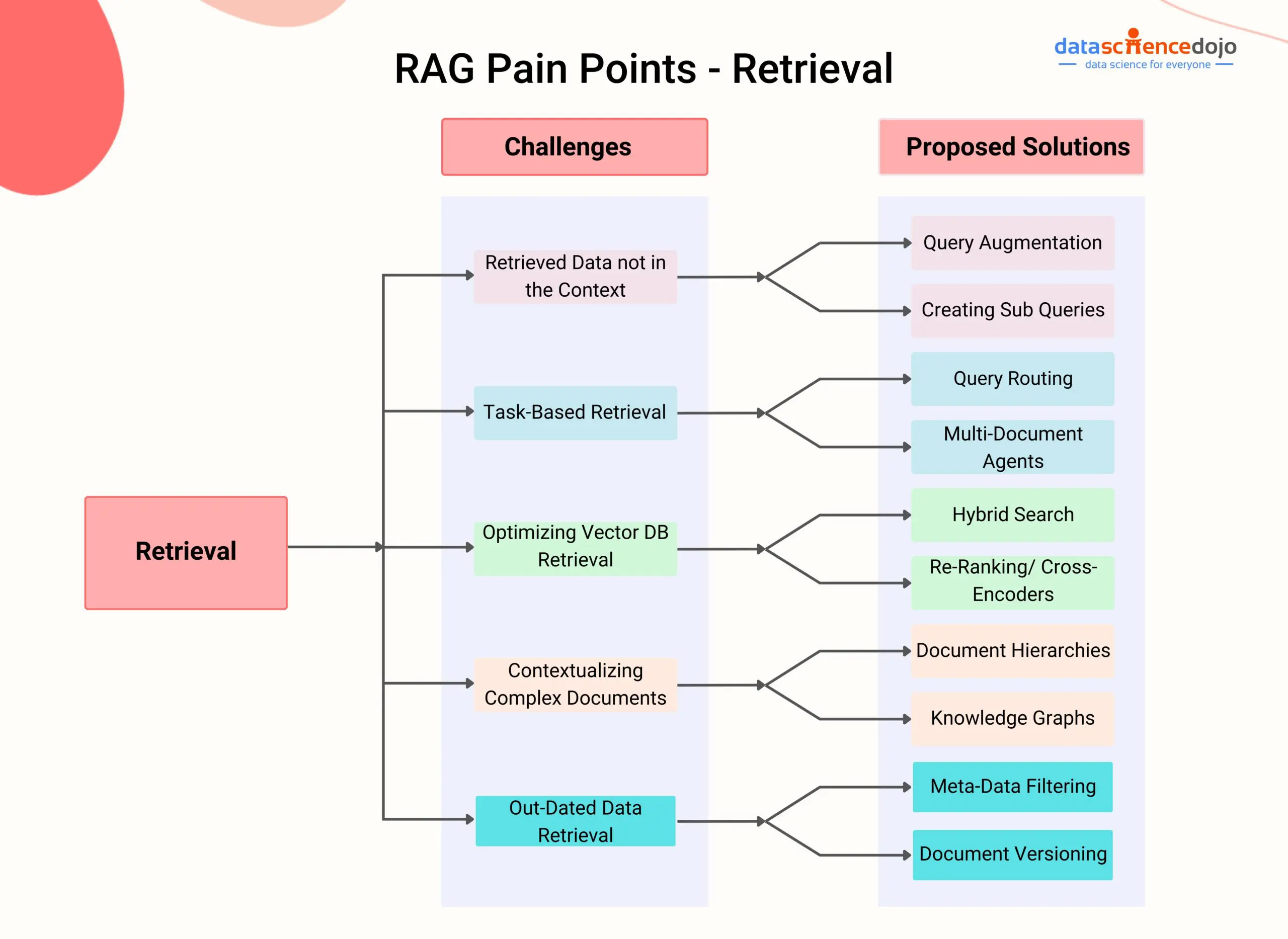
Challenge 1: Retrieved Data Not in Context
The RAG system can retrieve data that doesn’t qualify to bring relevant context to generate an accurate response. There can be several reasons for this.
- Missed top rank documents: The system sometimes doesn’t include essential documents that contain the answer in the top results returned by the system’s retrieval component.
- Incorrect specificity: Responses may not provide precise information or adequately address the specific context of the user’s query
- Losing relevant context during reranking: This occurs when documents containing the answer are retrieved from the database but fail to make it into the context for generating an answer.
Proposed Solutions
Query augmentation: Query augmentation enables RAG to retrieve information that is in context by enhancing the user queries with additional contextual details or modifying them to maximize relevancy. This involves improving the phrasing, adding company-specific context, and generating sub-questions that help contextualize and generate accurate responses
- Rephrasing
- Hypothetical document embeddings
- Sub-queries
Tweak retrieval strategies: LlamaIndex offers a range of retrieval strategies, from basic to advanced, to ensure accurate retrieval in RAG pipelines. By exploring these strategies, developers can improve the system’s ability to incorporate relevant information into the context for generating accurate responses.
- Small-to-big sentence window retrieval
- Recursive retrieval
- Semantic similarity scoring
Hyperparameter tuning for chunk size and similarity_top_k: This solution involves adjusting the parameters of the retrieval process in RAG models. More specifically, we can tune the parameters related to chunk size and similarity_top_k.
The chunk_size parameter determines the size of the text chunks used for retrieval, while similarity_top_k controls the number of similar chunks retrieved. By experimenting with different values for these parameters, developers can find the optimal balance between computational efficiency and the quality of retrieved information.
Reranking: Reranking retrieval results before they are sent to the language model has proven to improve RAG systems’ performance significantly.
By retrieving more documents and using techniques like CohereRerank, which leverages a reranker to improve the ranking order of the retrieved documents, developers can ensure that the most relevant and accurate documents are considered for generating responses.
This reranking process can be implemented by incorporating the reranker as a postprocessor in the RAG pipeline.
Challenge 2: Task-Based Retrieval
If you deploy a RAG-based service, you should expect anything from the users and you should not just limit your RAG in production applications to only be highly performant for question-answering tasks. Users can ask a wide variety of questions.
Explore the roadmap of creating a Q&A chatbot using LlamaIndex
Naive RAG stacks can address queries about specific facts, such as details on a company’s Diversity & Inclusion efforts in 2023 or the narrator’s activities at Google. However, questions may also seek summaries (“Provide a high-level overview of this document”) or comparisons (“Compare X and Y”). Different retrieval methods may be necessary for these diverse use cases.
Proposed Solutions
Query routing: This technique involves retaining the initial user query while identifying the appropriate subset of tools or sources that pertain to the query. By routing the query to the suitable options, routing ensures that the retrieval process is fine-tuned to the specific tools or sources that are most likely to yield accurate and relevant information.
Challenge 3: Optimize the Vector DB to Look for Correct Documents
The problem in the retrieval stage of RAG is about ensuring the lookup to a vector database effectively retrieves accurate documents that are relevant to the user’s query.
Hereby, we must address the challenge of semantic matching by seeking documents and information that are not just keyword matches, but also conceptually aligned with the meaning embedded within the user query.
Proposed Solutions
Hybrid search: Hybrid search tackles the challenge of optimal document lookup in vector databases. It combines semantic and keyword searches, ensuring retrieval of the most relevant documents.
Semantic search: Goes beyond keywords, considering document meaning and context for accurate results.
Keyword search: Excellent for queries with specific terms like product codes, jargon, or dates.
Hybrid search strikes a balance, offering a comprehensive and optimized retrieval process. Developers can further refine results by adjusting weighting between semantic and keyword searches. This empowers vector databases to deliver highly relevant documents, streamlining document lookup.

Challenge 4: Chunking Large Datasets
When we put large amounts of data into a RAG-based product we eventually have to parse and then chunk the data because when we retrieve info – we can’t really retrieve a whole pdf – but different chunks of it. However, this can present several pain points.
Loss of context: One primary issue is the potential loss of context when breaking down large documents into smaller chunks. When documents are divided into smaller pieces, the nuances and connections between different sections of the document may be lost, leading to incomplete representations of the content.
Optimal chunk size: Determining the optimal chunk size becomes essential to balance capturing essential information without sacrificing speed. While larger chunks could capture more context, they introduce more noise and require additional processing time and computational costs. On the other hand, smaller chunks have less noise but may not fully capture the necessary context.
Read more: Optimize RAG efficiency with LlamaIndex: The perfect chunk size
Proposed Solutions
- Document hierarchies: This is a pre-processing step where you can organize data in a structured manner to improve information retrieval by locating the most relevant chunks of text.
- Knowledge graphs: Representing related data through graphs, enabling easy and quick retrieval of related information and reducing hallucinations in RAG systems.
- Sub-document summary: Breaking down documents into smaller chunks and injecting summaries to improve RAG retrieval performance by providing global context awareness.
- Parent document retrieval: Retrieving summaries and parent documents in a recursive manner to improve information retrieval and response generation in RAG systems.
- RAPTOR: RAPTOR recursively embeds, clusters, and summarizes text chunks to construct a tree structure with varying summarization levels. Read more
- Recursive retrieval: Retrieval of summaries and parent documents in multiple iterations to improve performance and provide context-specific information in RAG systems.
Challenge 5: Retrieving Outdated Content from the Database
Imagine a RAG app working perfectly for 100 documents. But what if a document gets updated? The app might still use the old info (stored as an “embedding”) and give you answers based on that, even though it’s wrong.
Proposed Solutions
Meta-data filtering: It’s like a label that tells the app if a document is new or changed. This way, the app can always use the latest and greatest information.
Stage 3: Generation and its Pain Points
While the quality of the response generated largely depends on how good the retrieval of information was, there still are tons of aspects you must consider. After all, the quality of the response and the time it takes to generate the response directly impacts the satisfaction of your user.
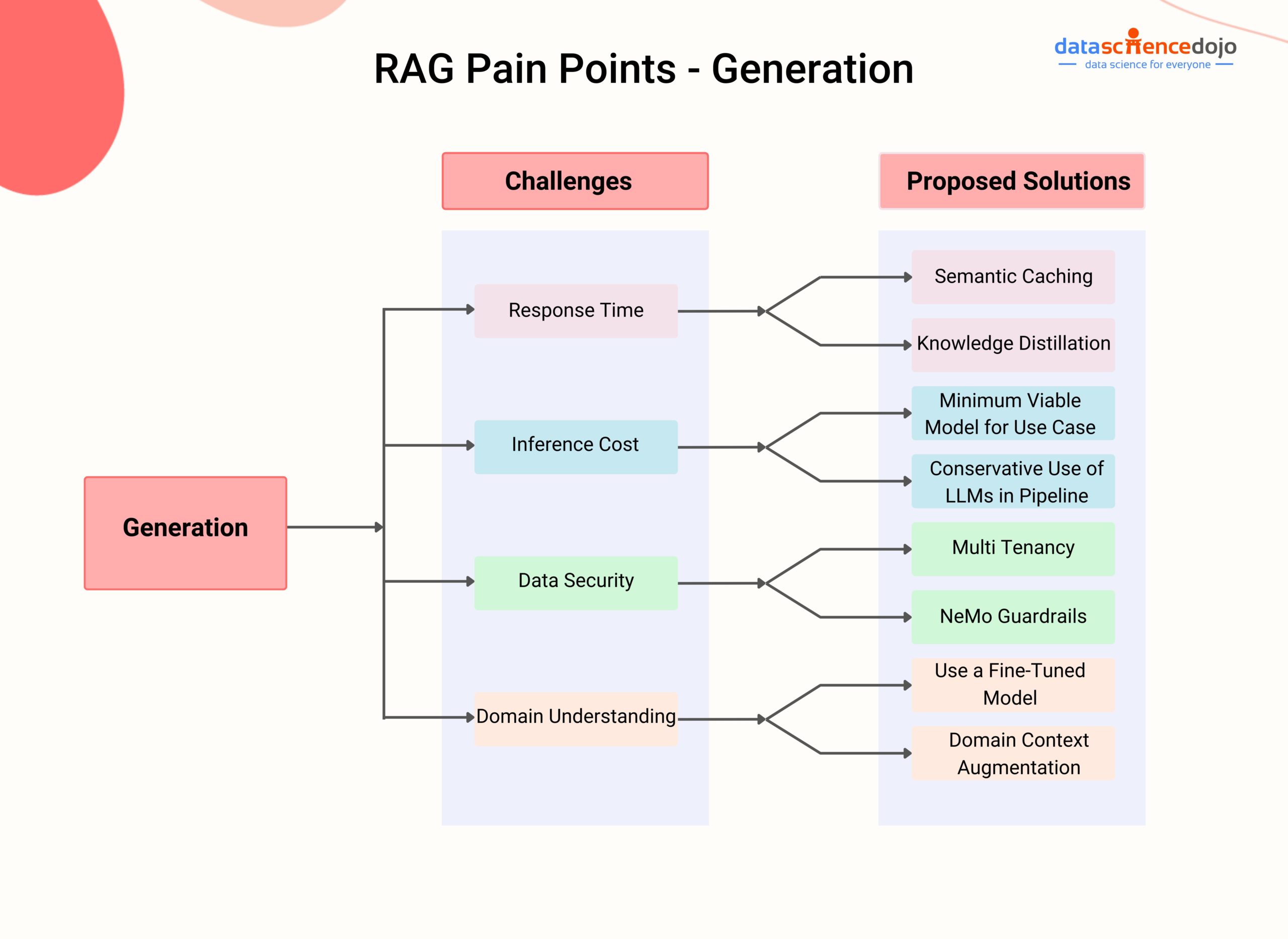
Challenge 1: Optimized Response Time for User
The prompt response to user queries is vital for maintaining user engagement and satisfaction.
Proposed Solutions
Semantic caching: Semantic caching addresses the challenge of optimizing response time by implementing a cache system to store and quickly retrieve pre-processed data and responses. It can be implemented at two key points in an RAG system to enhance speed:
- Retrieval of information: The first point where semantic caching can be implemented is in retrieving the information needed to construct the enriched prompt. This involves pre-processing and storing relevant data and knowledge sources that are frequently accessed by the RAG system.
- Calling the LLM: By implementing a semantic cache system, the pre-processed data and responses from previous interactions can be stored. When similar queries are encountered, the system can quickly access these cached responses, leading to faster response generation.
Challenge 2: Inference Costs
The cost of inference for large language models (LLMs) is a major concern, especially when considering enterprise applications. Some of the factors that contribute to the inference cost of LLMs include context window size, model size, and training data.
Uncover the LLM context window paradox in LLMs
Proposed Solutions
Minimum viable model for your use case: Not all LLMs are created equal. There are models specifically designed for tasks like question answering, code generation, or text summarization. Choosing an LLM with expertise in your desired area can lead to better results and potentially lower inference costs because the model is already optimized for that type of work.
Conservative use of LLMs in the pipeline: By strategically deploying LLMs only in critical parts of the pipeline where their advanced capabilities are essential, you can minimize unnecessary computational expenditure. This selective use ensures that LLMs contribute value where they’re most needed, optimizing the balance between performance and cost.
Challenge 3: Data Security
The problem of data security in RAG systems refers to the concerns and challenges associated with ensuring the security and integrity of LLMs used in RAG applications.
As LLMs become more powerful and widely used, there are ethical and privacy considerations that need to be addressed to protect sensitive information and prevent potential abuses. These include:
- Prompt injection
- Sensitive information disclosure
- Insecure outputs
Proposed Solutions
Multi-tenancy: Multi-tenancy is like having separate, secure rooms for each user or group within a large language model system, ensuring that everyone’s data is private and safe. It makes sure that each user’s data is kept apart from others, protecting sensitive information from being seen or accessed by those who shouldn’t.
By setting up specific permissions, it controls who can see or use certain data, keeping the wrong hands off of it. This setup not only keeps user information private and safe from misuse but also helps the LLM follow strict rules and guidelines about handling and protecting data.
NeMo guardrails: NeMo Guardrails is an open-source security toolset designed specifically for language models, including large language models. It offers a wide range of programmable guardrails that can be customized to control and guide LLM inputs and outputs, ensuring secure and responsible usage in RAG systems.

Ensuring the Practical Success of the RAG Framework
This article explored key pain points associated with RAG systems, ranging from missing content and incomplete responses to data ingestion scalability and LLM security. For each pain point, we discussed potential solutions, highlighting various techniques and tools that developers can leverage to optimize RAG system performance and ensure accurate, reliable, and secure responses.
By addressing these challenges, RAG systems can unlock their full potential and become a powerful tool for enhancing the accuracy and effectiveness of LLMs across various applications. To explore the role of RAG within the world of LLMs, check out our LLM bootcamp!