This is the second blog in the series of RAG and finetuning, highlighting a detailed comparison of the two approaches.
You can read the first blog of the series here – A guide to understanding RAG and finetuning
While we provided a detailed guideline on understanding RAG and finetuning, a comparative analysis of the two provides a deeper insight. Let’s explore and address the RAG vs finetuning debate to determine the best tool to optimize LLM performance.
RAG vs Finetuning LLM – A Detailed Comparison
It’s crucial to grasp that these methodologies while targeting the enhancement of large language models (LLMs), operate under distinct paradigms. Recognizing their strengths and limitations is essential for effectively leveraging them in various AI applications.
This understanding allows developers and researchers to make informed decisions about which technique to employ based on the specific needs of their projects. Whether it’s adapting to dynamic information, customizing linguistic styles, managing data requirements, or ensuring domain-specific performance, each approach has its unique advantages.
By comprehensively understanding these differences, you’ll be equipped to choose the most suitable method—or a blend of both—to achieve your objectives in developing sophisticated, responsive, and accurate AI models.
Team RAG or team Fine-Tuning? Tune in to this podcast now to find out their specific benefits, trade-offs, use cases, enterprise adoption, and more!
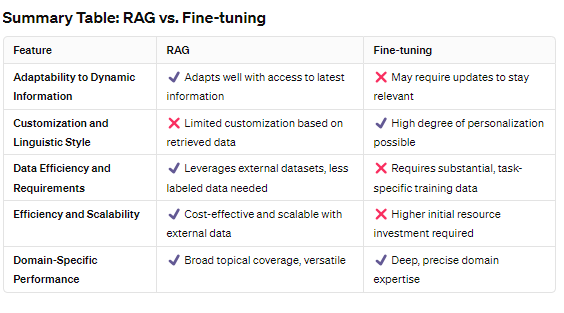
Adaptability to Dynamic Information
RAG shines in environments where information is constantly updated. By design, RAG leverages external data sources to fetch the latest information, making it inherently adaptable to changes.
This quality ensures that responses generated by RAG-powered models remain accurate and relevant, a crucial advantage for applications like real-time news summarization or updating factual content.
Fine-tuning, in contrast, optimizes a model’s performance for specific tasks through targeted training on a curated dataset.
While it significantly enhances the model’s expertise in the chosen domain, its adaptability to new or evolving information is constrained. The model’s knowledge remains as current as its last training session, necessitating regular updates to maintain accuracy in rapidly changing fields.
Learn about the 12 RAG challenges in building LLM applications
Customization and Linguistic Style
RAG‘s primary focus is on enriching responses with accurate, up-to-date information retrieved from external databases.
This process, though excellent for fact-based accuracy, means RAG models might not tailor their linguistic style as closely to specific user preferences or nuanced domain-specific terminologies without integrating additional customization techniques.
Fine-tuning excels in personalizing the model to a high degree, allowing it to mimic specific linguistic styles, adhere to unique domain terminologies, and align with particular content tones.
This is achieved by training the model on a dataset meticulously prepared to reflect the desired characteristics, enabling the fine-tuned model to produce outputs that closely match the specified requirements.

Data Efficiency and Requirements
RAG operates by leveraging external datasets for retrieval, thus requiring a sophisticated setup to manage and query these vast data repositories efficiently.
The model’s effectiveness is directly tied to the quality and breadth of its connected databases, demanding rigorous data management but not necessarily a large volume of labeled training data.
Fine-tuning, however, depends on a substantial, well-curated dataset specific to the task at hand.
It requires less external data infrastructure compared to RAG but relies heavily on the availability of high-quality, domain-specific training data. This makes fine-tuning particularly effective in scenarios where detailed, task-specific performance is paramount and suitable training data is accessible.
Efficiency and Scalability
RAG is generally considered cost-effective and efficient for a wide range of applications, particularly because it can dynamically access and utilize information from external sources without the need for continuous retraining.
This efficiency makes RAG a scalable solution for applications requiring access to the latest information or coverage across diverse topics.
Fine-tuning demands a significant investment in time and resources for the initial training phase, especially in preparing the domain-specific dataset and computational costs.
However, once fine-tuned, the model can operate with high efficiency within its specialized domain. The scalability of fine-tuning is more nuanced, as extending the model’s expertise to new domains requires additional rounds of fine-tuning with respective datasets.
Explore further how to tune LLMs for optimal performance
Domain-Specific Performance
RAG demonstrates exceptional versatility in handling queries across a wide range of domains by fetching relevant information from its external databases.
Its performance is notably robust in scenarios where access to wide-ranging or continuously updated information is critical for generating accurate responses.
Fine-tuning is the go-to approach for achieving unparalleled depth and precision within a specific domain.
By intensively training the model on targeted datasets, fine-tuning ensures the model’s outputs are not only accurate but deeply aligned with the domain’s subtleties, making it ideal for specialized applications requiring high expertise.

Hybrid Approach: Enhancing LLMs with RAG and Finetuning
The concept of a hybrid model that integrates Retrieval-Augmented Generation (RAG) with fine-tuning presents an interesting advancement. This approach allows for the contextual enrichment of LLM responses with up-to-date information while ensuring that outputs are tailored to the nuanced requirements of specific tasks.
Such a model can operate flexibly, serving as either a versatile, all-encompassing system or as an ensemble of specialized models, each optimized for particular use cases.
In practical applications, this could range from customer service chatbots that pull the latest policy details to enrich responses and then tailor these responses to individual user queries, to medical research assistants that retrieve the latest clinical data for accurate information dissemination, adjusted for layman understanding.
Here’s a 40-hour LLM application roadmap for you
The hybrid model thus promises not only improved accuracy by grounding responses in factual, relevant data but also ensures that these responses are closely aligned with specific domain languages and terminologies.
However, this integration introduces complexities in model management, potentially higher computational demands, and the need for effective data strategies to harness the full benefits of both RAG and fine-tuning.
Despite these challenges, the hybrid approach marks a significant step forward in AI, offering models that combine broad knowledge access with deep domain expertise, paving the way for more sophisticated and adaptable AI solutions.
Choosing the Best Approach: Finetuning, RAG, or Hybrid
Choosing between fine-tuning, Retrieval Augmented Generation (RAG), or a hybrid approach for enhancing a Large Language Model should consider specific project needs, data accessibility, and the desired outcome alongside computational resources and scalability.
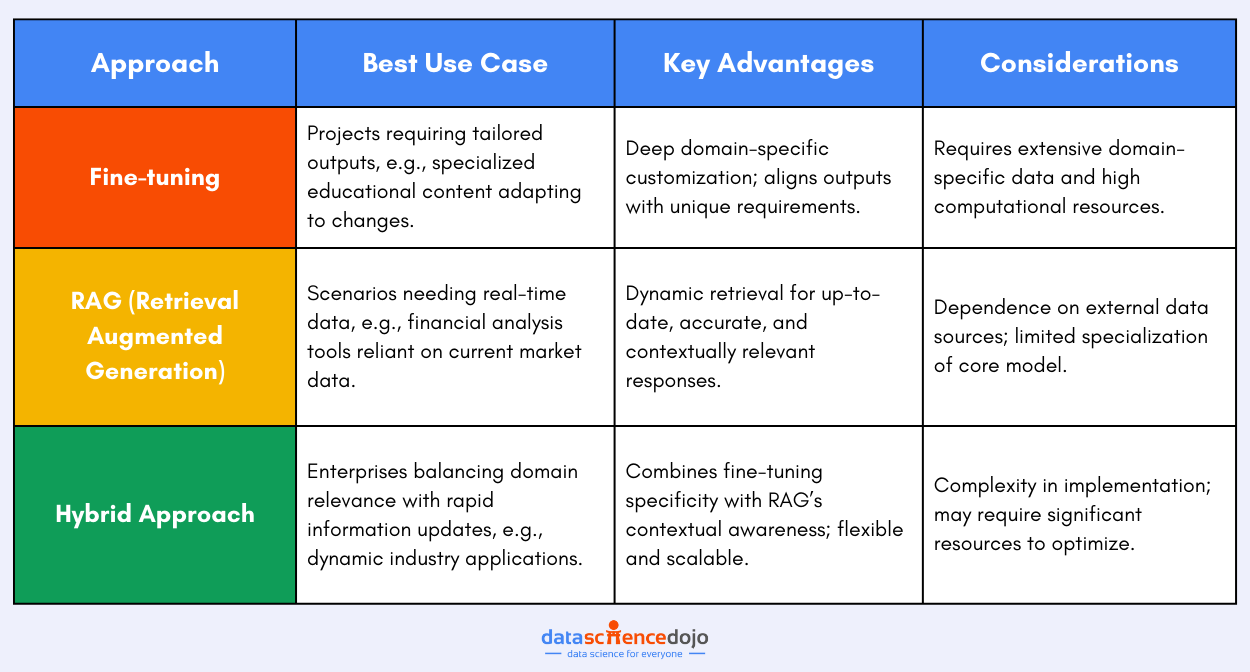
Fine-tuning is best when you have extensive domain-specific data and seek to tailor the LLM’s outputs closely to specific requirements, making it a perfect fit for projects like creating specialized educational content that adapts to curriculum changes. RAG, with its dynamic retrieval capability, suits scenarios where responses must be informed by the latest information, ideal for financial analysis tools that rely on current market data.
A hybrid approach merges these advantages, offering the specificity of fine-tuning with the contextual awareness of RAG, suitable for enterprises needing to keep pace with rapid information changes while maintaining deep domain relevance. As technology evolves, a hybrid model might offer the flexibility to adapt, providing a comprehensive solution that encompasses the strengths of both fine-tuning and RAG.
Explore how Llama 2 can used for finetuning LLMs
Evolution and Future Directions
As the landscape of artificial intelligence continues to evolve, so too do the methodologies and technologies at its core. Among these, Retrieval-Augmented Generation (RAG) and fine-tuning are experiencing significant advancements, propelling them toward new horizons of AI capabilities.
Advanced Enhancements in RAG
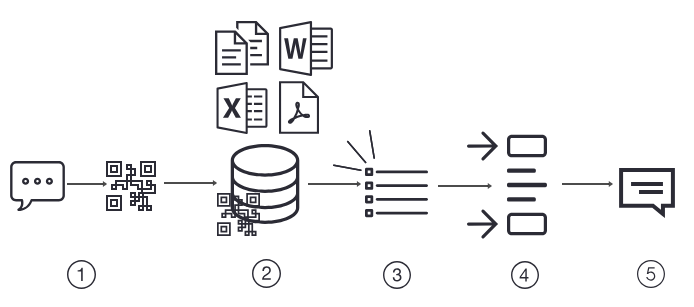
Enhancing the Retrieval Augmented Generation Pipeline
RAG has undergone significant transformations and advancements in each step of its pipeline. Each research paper on RAG introduces advanced methods to boost accuracy and relevance at every stage.
Let’s use the same query example from the basic RAG explanation: “What’s the latest breakthrough in renewable energy?”, to better understand these advanced techniques.
Pre-Retrieval Optimizations
Before the system begins to search, it optimizes the query for better outcomes. For our example, Query Transformations and Routing might break down the query into sub-queries like “latest renewable energy breakthroughs” and “new technology in renewable energy.”
This ensures the search mechanism is fine-tuned to retrieve the most accurate and relevant information.
Enhanced Retrieval Techniques
During the retrieval phase, Hybrid Search combines keyword and semantic searches, ensuring a comprehensive scan for information related to our query.
Moreover, by Chunking and Vectorization, the system breaks down extensive documents into digestible pieces, which are then vectorized. This means our query doesn’t just pull up general information but seeks out the precise segments of texts discussing recent innovations in renewable energy.
Post-Retrieval Refinements
After retrieval, the Reranking and Filtering processes evaluate the gathered information chunks. Instead of simply using the top ‘k’ matches, these techniques rigorously assess the relevance of each piece of retrieved data.
For our query, this could mean prioritizing a segment discussing a groundbreaking solar panel efficiency breakthrough over a more generic update on solar energy. This step ensures that the information used in generating the response directly answers the query with the most relevant and recent breakthroughs in renewable energy.
Read in detail about retrieval augmented generation
Through these advanced RAG enhancements, the system not only finds and utilizes information more effectively but also ensures that the final response to the query about renewable energy breakthroughs is as accurate, relevant, and up-to-date as possible.
Towards Multimodal Integration
RAG, traditionally focused on enhancing text-based language models by incorporating external data, is now also expanding its horizons towards a multimodal future.
Multimodal RAG integrates various types of data, such as images, audio, and video, alongside text, allowing AI models to generate responses that are not only informed by a vast array of textual information but also enriched by visual and auditory contexts.
This evolution signifies a move towards AI systems capable of understanding and interacting with the world more holistically, mimicking human-like comprehension across different sensory inputs.
Read about GPT-4 Vision and its role in LLM multimodality
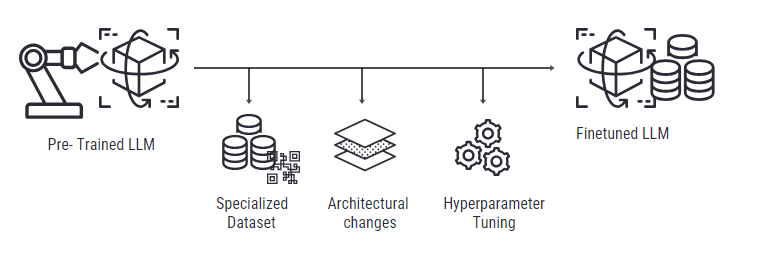
Advanced Enhancements in Finetuning
Parameter Efficiency and LoRA
In parallel, fine-tuning is transforming more parameter-efficient methods. Fine-tuning large language models (LLMs) presents a unique challenge for AI practitioners aiming to adapt these models to specific tasks without the overwhelming computational costs typically involved.
One such innovative technique is Parameter-Efficient Fine-Tuning (PEFT), which offers a cost-effective and efficient method for fine-tuning such a model.
Techniques like Low-Rank Adaptation (LoRA) are at the forefront of this change, enabling fine-tuning to be accomplished with significantly less computational overhead. LoRA and similar approaches adjust only a small subset of the model’s parameters, making fine-tuning not only more accessible but also more sustainable.
Specifically, it introduces a low-dimensional matrix that captures the essence of the downstream task, allowing for fine-tuning with minimal adjustments to the original model’s weights.
This method exemplifies how cutting-edge research is making it feasible to tailor LLMs for specialized applications without the prohibitive computational cost typically associated.
The Emergence of Long-Context LLMs
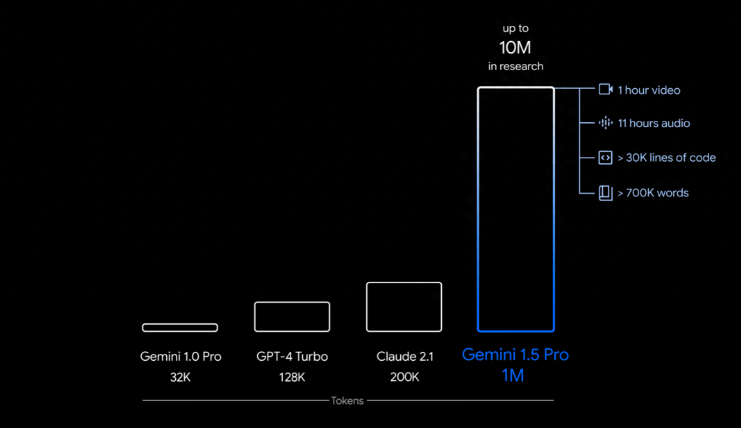
As we embrace these advancements in RAG and fine-tuning, the recent introduction of Long Context LLMs, like Gemini 1.5 Pro, poses an intriguing question about the future necessity of these technologies. Gemini 1.5 Pro, for instance, showcases a remarkable capability with its 1 million token context window, setting a new standard for AI’s ability to process and utilize extensive amounts of information in one go.
The big deal here is how this changes the game for technologies like RAG and advanced fine-tuning. RAG was a breakthrough because it helped AI models to look beyond their training, fetching information from outside when needed, to answer questions more accurately.
But now, with Long Context LLMs’ ability to hold so much information in memory, the question arises: Do we still need RAG anymore?
Learn more about the context window paradox in LLMs
This doesn’t mean RAG and fine-tuning are becoming obsolete. Instead, it hints at an exciting future where AI can be both deeply knowledgeable, thanks to its vast memory, and incredibly adaptable, using technologies like RAG to fill in any gaps with the most current information.
In essence, Long Context LLMs could make AI more powerful by ensuring it has a broad base of knowledge to draw from, while RAG and fine-tuning techniques ensure that the AI remains up-to-date and precise in its answers. So the emergence of Long Context LLMs like Gemini 1.5 Pro does not diminish the value of RAG and fine-tuning but rather complements it.
Concluding Thoughts
The trajectory of AI, through the advancements in RAG, fine-tuning, and the emergence of long-context LLMs, reveals a future rich with potential. As these technologies mature, their combined interaction will make systems more adaptable, efficient, and capable of understanding and interacting with the world in ways that are increasingly nuanced and human-like.

The evolution of AI is not just a testament to technological advancement but a reflection of our continuous quest to create machines that can truly understand, learn from, and respond to the complex landscape of human knowledge and experience.