

Artificial intelligence (AI) has transformed industries, but its large and complex models often require significant computational resources. Traditionally, AI models have relied on cloud-based infrastructure, but this approach often comes with challenges such as latency, privacy concerns, and reliance on a stable internet connection.
Enter Edge AI, a revolutionary shift that brings AI computations directly to devices like smartphones, IoT gadgets, and embedded systems. By enabling real-time data processing on local devices, Edge AI enhances user privacy, reduces latency, and minimizes dependence on cloud servers.
However, edge devices face significant challenges, such as limited memory, lower processing power, and restricted battery life, making it challenging to deploy large, complex AI models directly on these systems.
This is where knowledge distillation becomes critical. It addresses this issue by enabling a smaller, efficient model to learn from a larger, complex model, maintaining similar performance with reduced size and speed.

This blog provides a beginner-friendly explanation of knowledge distillation, its benefits, real-world applications, challenges, and a step-by-step implementation using Python.
What Is Knowledge Distillation?
Knowledge Distillation is a machine learning technique where a teacher model (a large, complex model) transfers its knowledge to a student model (a smaller, efficient model).
- Purpose: Maintain the performance of large models while reducing computational requirements.
- Core Idea: Train the student model using two types of information from the teacher model:
- Hard Labels: These are the traditional outputs from a classification model that identify the correct class for an input. For example, in an image classification task, if the input is an image of a cat, the hard label would be ‘cat’.
- Soft Probabilities: Unlike hard labels, soft probabilities represent the likelihood of an input belonging to each class. They reflect the model’s confidence in its predictions and the relationship between classes.
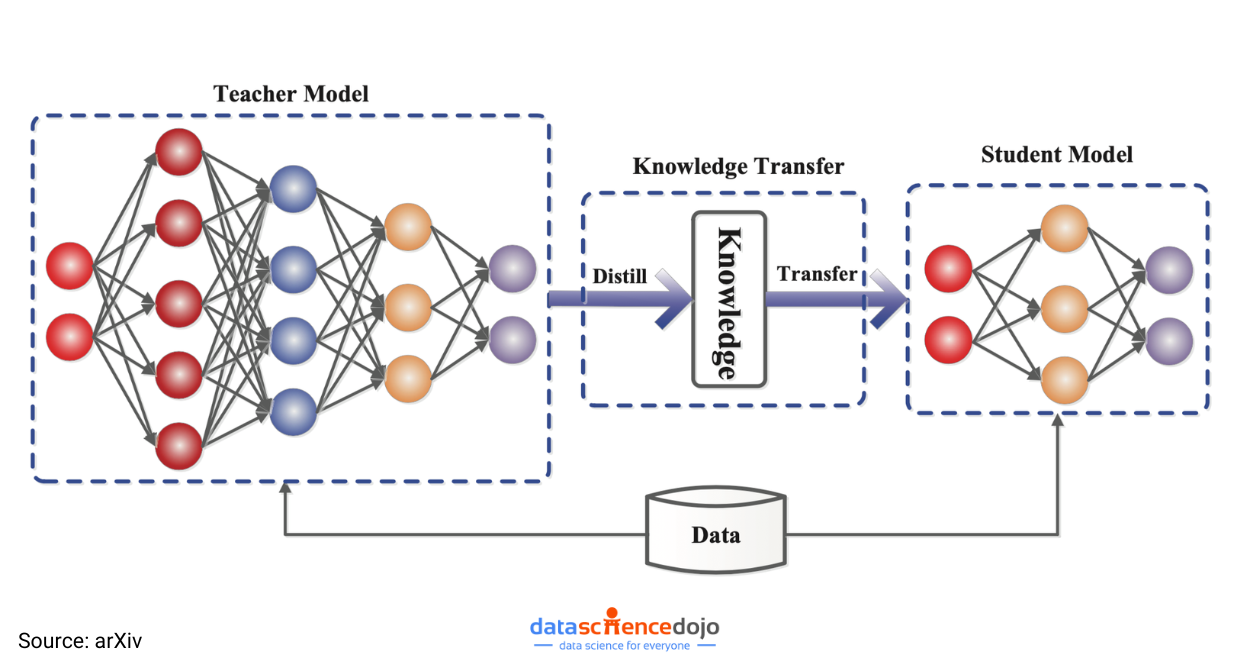
A teacher model might predict the probability of an animal in an image belonging to different categories:
- “Cat” as 85%, “Dog” as 10%, and “Rabbit” as 5%
In this case, the teacher is confident the image is of a cat, but also acknowledges some similarities to a dog and a rabbit.
Here’s a list of 9 key probability distributions in data science
Instead of only learning from the label “Cat,” the student also learns the relationships between different categories. For example, it might recognize that the animal in the image has features like pointed ears, which are common to both cats and rabbits, or fur texture, which cats and dogs often share. These probabilities help the student generalize better by understanding subtle patterns in the data.
How Does Knowledge Distillation Work?
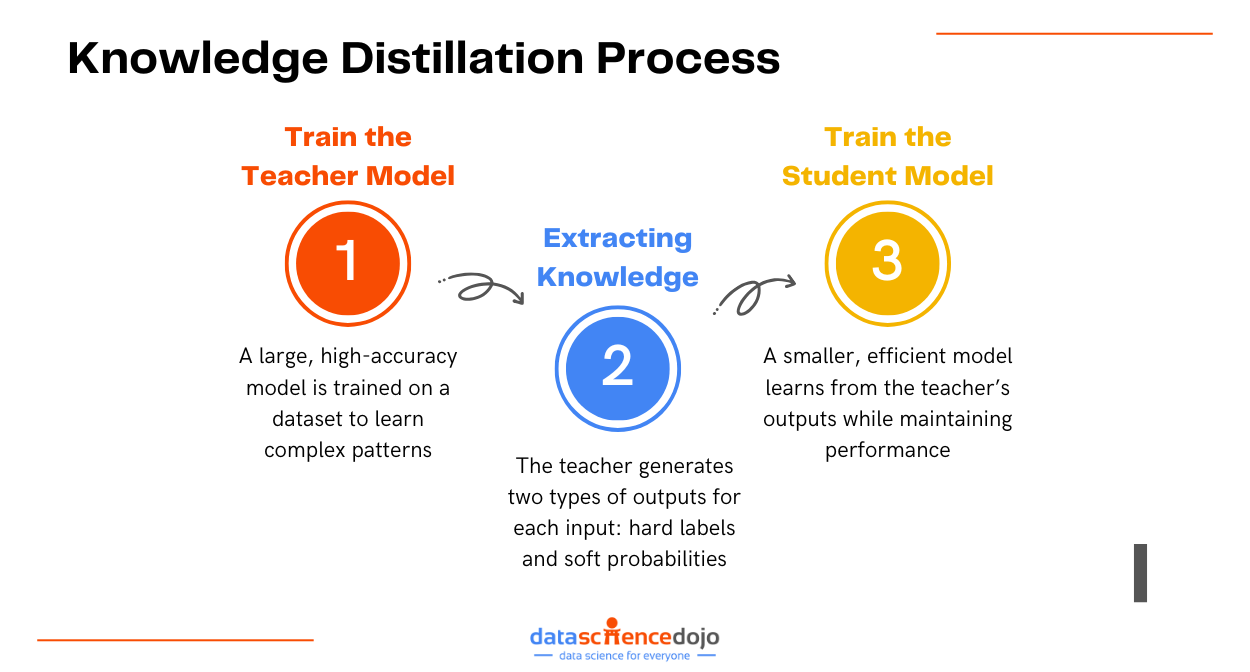
The process of Knowledge Distillation involves three primary steps:
1. Train the Teacher Model
- The teacher is a large, resource-intensive model trained on a dataset to achieve high accuracy.
- For instance, state-of-the-art models like ResNet or BERT often act as teacher models. These models require extensive computational resources to learn intricate data patterns.
2. Extracting Knowledge
- Once the teacher is trained, it generates two outputs for each input:
- Hard Labels: The correct classification for each input (e.g., “Cat”).
- Soft Probabilities: A probability distribution over all possible classes, reflecting the teacher’s confidence in its predictions.
- Temperature Scaling:
- Soft probabilities are adjusted using a temperature parameter.
- A higher temperature makes the predictions smoother, highlighting subtle relationships between classes, which aids the student’s learning, but can dilute the certainty of the most likely class
- A lower temperature makes the predictions sharper, emphasizing the confidence in the top class, but reducing the information about relationships between other classes
3. Student Model
The student model, which is smaller and more efficient, is trained to replicate the behavior of the teacher. The training combines:
- Hard Label Loss: Guides the student to predict the correct class.
- Soft Label Loss: Helps the student align its predictions with the teacher’s soft probabilities.
The combined objective is for the student to minimize a loss function that balances:
- Accuracy on hard labels (e.g., correctly predicting “Cat”).
- Matching the teacher’s insights (e.g., understanding why “Dog” is also likely).

Why is Knowledge Distillation Important?
Some key aspects that make knowledge distillation important are:
Efficiency
- Model Compression: Knowledge Distillation reduces the size of large models by transferring their knowledge to smaller models. The smaller model is designed with fewer layers and parameters, significantly reducing memory requirements while retaining performance.
- Faster Inference: Smaller models process data faster due to reduced computational complexity, enabling real-time applications like voice assistants and augmented reality.
Cost Savings
- Energy Efficiency: Compact models consume less power during inference. For instance, a lightweight model on a mobile device processes tasks with minimal energy drain compared to its larger counterpart.
- Reduced Hardware Costs: Smaller models eliminate the need for expensive hardware such as GPUs or high-end servers, making AI deployment more affordable.
Accessibility
- Knowledge Distillation allows high-performance AI to be deployed on resource-constrained devices, such as IoT systems or embedded systems. For instance, healthcare diagnostic tools powered by distilled models can operate effectively in rural areas with limited infrastructure.
Step-by-Step Implementation with Python
First, import the necessary libraries for data handling, model building, and training.
Then, define the Teacher Model. The teacher model is a larger neural network trained to achieve high accuracy on the MNIST dataset.
Now, we can define the Student Model. The student model is a smaller neural network designed to mimic the behavior of the teacher model while being more efficient.
Load the MNIST dataset and apply transformations such as normalization.
We need to then define a function that combines soft label loss (teacher’s predictions) and hard label loss (ground truth) to train the student model.
Now, it is time to train the teacher model on the dataset using standard supervised learning.
The following function trains the student model using the teacher’s outputs (soft labels) and ground truth labels (hard labels).
Finally, we can evaluate the models on the test dataset and print their accuracy.
Running the code will print the accuracy of both the teacher and student models.
Additionally, a visualized version of the example loss curves and accuracy comparison from this implementation is shown below:
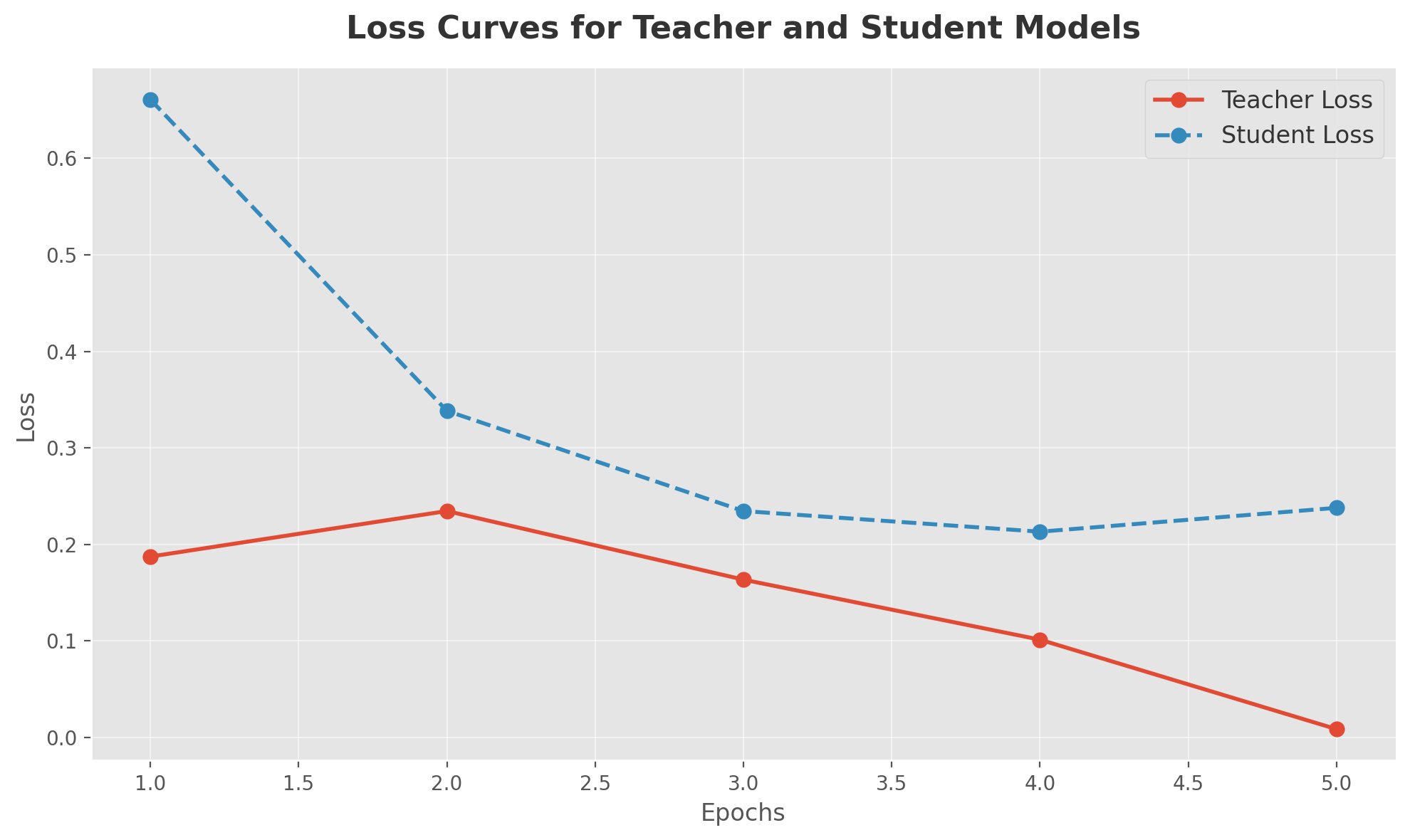
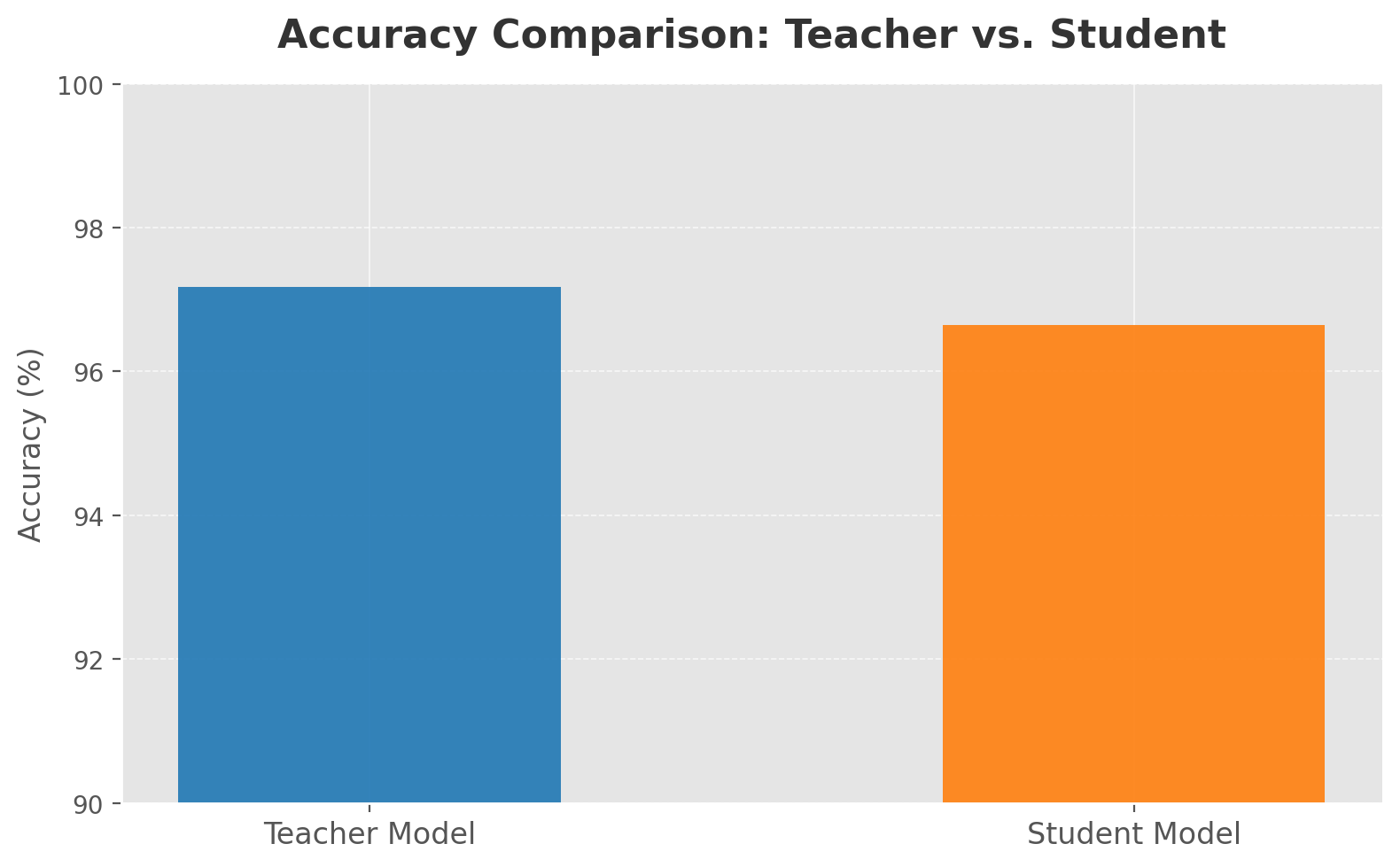
Applications of Knowledge Distillation
Knowledge distillation is quietly powering some of the most essential AI-driven innovations we rely on every day. It allows lightweight AI to operate efficiently on everyday devices. This means we get the benefits of advanced AI without the heavy computational costs, making technology more practical and responsive in real-world scenarios.
Let’s take a look at some key applications of knowledge distillation.
Mobile Applications
Ever wondered how your voice assistant responds so quickly or how your phone instantly translates text? It is the result of knowledge distillation working with your mobile applications. Shrinking large AI models into compact versions allows apps to deliver fast and efficient results without draining your device’s power.
For example, DistilBERT is a streamlined version of the powerful BERT model. It is designed to handle natural language processing (NLP) tasks like chatbots and search engines with lower computational costs. This means you get smarter AI experiences on your phone without sacrificing speed or battery life!
Explore the pros and cons of mobile app development with Open AI
Autonomous Vehicles
Self-driving cars need to make split-second decisions to stay safe on the road. Using knowledge distillation enables these vehicles to process real-time data from cameras, LiDAR, and sensors with lightning-fast speed.
This reduced latency means the car can react instantly to obstacles, traffic signals, and pedestrians while using less power. Hence, it ensures the creation of smarter, safer self-driving technology that doesn’t rely on massive, energy-hungry hardware to navigate the world.
Healthcare Diagnostics
AI is revolutionizing healthcare diagnostics by making medical imaging faster and more accessible. Compact AI models power the analysis of X-rays, MRIs, and ECGs, helping doctors detect conditions with speed and accuracy. These distilled models retain the intelligence of larger AI systems while operating efficiently on smaller devices.
This is particularly valuable in rural or low-resource settings, where access to advanced medical equipment is limited. With AI-powered diagnostics, healthcare providers can deliver accurate assessments in real time, improving patient outcomes and expanding access to quality care worldwide.
Natural Language Processing (NLP)
NLP has become faster and more efficient thanks to compact models like DistilGPT and DistilRoBERTa. These lightweight versions of larger AI models power chatbots, virtual assistants, and search engines to deliver quick and accurate responses while using fewer resources.
The reduced inference time enables these models to ensure seamless user interactions without compromising performance. Whether it’s improving customer support, enhancing search results, or making virtual assistants more responsive, distilled NLP models bring the best of AI while maintaining speed and efficiency.
Read in detail about natural language processing
Thus, knowledge distillation is making powerful AI models more efficient and adaptable. It has the power to shape a future where intelligent systems are faster, cheaper, and more widely available.
Challenges in Knowledge Distillation
Accuracy Trade-Off – Smaller models may lose some accuracy compared to their larger teacher models. This trade-off can be mitigated by careful hyperparameter tuning, which involves adjusting key parameters that influence training processes such as:
- Learning Rate: It determines how quickly the model updates its parameters during training
- Temperature: Controls the smoothness of the teacher’s probabilities
Dependency on Teacher Quality – The student model’s performance heavily depends on the teacher. A poorly trained teacher can result in a weak student model. Thus, the teacher must be trained to high standards before the distillation process.
Complex Training Process – The distillation process involves tuning multiple hyperparameters, such as temperature and loss weights, to achieve the best balance between hard and soft label learning.
Task-Specific Customization – Knowledge Distillation often requires customization depending on the task (e.g., image classification or NLP). This is because different tasks have unique requirements: for example, image classification involves learning spatial relationships, while NLP tasks focus on understanding context and semantic relationships in text. Developing task-specific techniques can be time-consuming.
Advanced Techniques of Knowledge Distillation
In addition to standard knowledge distillation, there are advanced techniques that help push the boundaries of model optimization and applicability.
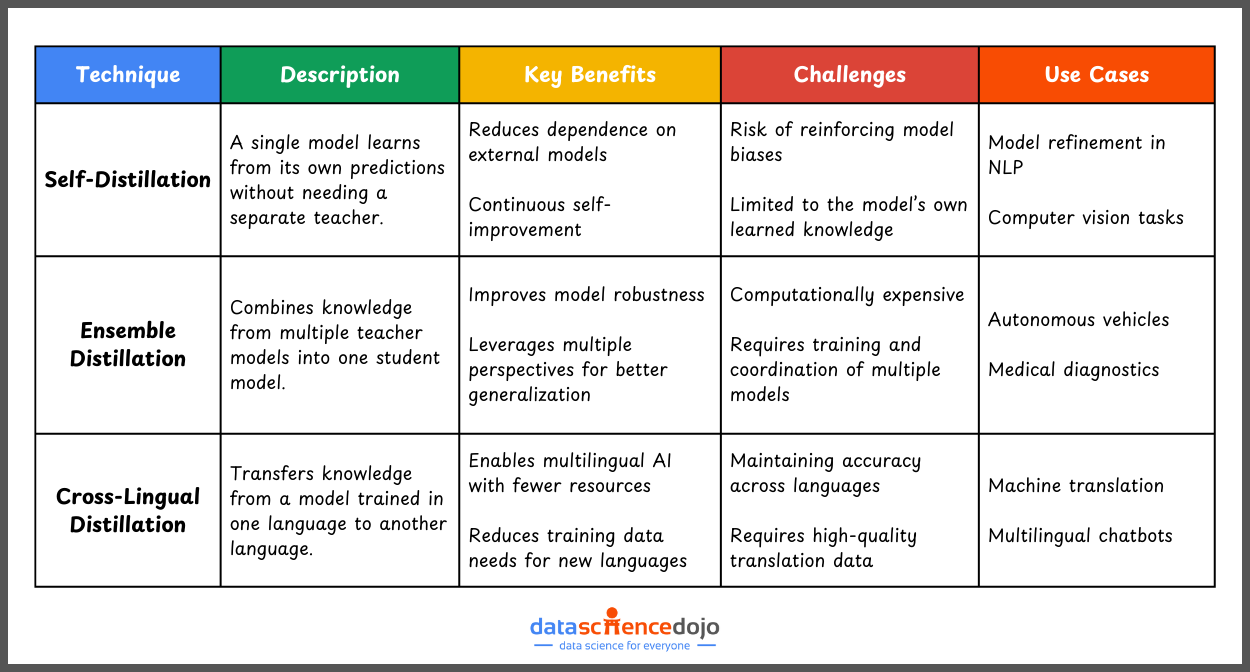
Self-Distillation: A single model improves itself by learning from its own predictions during training, eliminating the need for a separate teacher.
Ensemble Distillation: Combines insights from multiple teacher models to train a robust student model. This approach is widely used in safety-critical domains like autonomous vehicles.
Cross-Lingual Distillation: Transfers knowledge across languages. For example, a model trained in English can distill its knowledge to a student model operating in another language.
Conclusion
Knowledge Distillation simplifies the deployment of AI models by enabling smaller, efficient models to achieve performance comparable to larger ones. Its benefits, including model compression, faster inference, and cost efficiency, make it invaluable for real-world applications like mobile apps, autonomous vehicles, and healthcare diagnostics.
While there are challenges, advancements like self-distillation and cross-lingual distillation are expanding its potential. By implementing the Python example provided, you can see the process in action and gain deeper insights into this transformative technique.

Whether you’re an AI enthusiast or a practitioner, mastering knowledge distillation equips you to create smarter, faster, and more accessible AI systems.