

This blog post will provide you with a comprehensive data science roadmap that can aid your learning, helping you succeed in a world loaded with data.
As of 2020, the average salary that a data scientist makes in the US is over $113,000. With that stated, it can be affirmed that data scientists are in high demand.
You can think of data science as a way to earn money but then you will never have the actual motivation to learn it. Instead, you should identify a problem; be it marketing-related or a research problem, and then start learning data science & its tools accordingly, because you cannot excel at every tool or a data science skill set.
Stay updated with Artificial Intelligence and learn more about Large Language Models:

First & foremost, you need to motivate yourself to love the data, with no drive you will probably leave your learning journey at some point. Furthermore, you need to work on real projects.
Just acquiring the fundamental knowledge or skills won’t make you an expert data scientist, likewise, to increase your expertise, you need to increase the level of difficulty every time you undertake a data science project.
While being at work or by joining a top-rated Data Science Bootcamp, learn from your instructors & peers, and check how they are executing the data science projects. Last but not least, present your insights & analysis to others.
But you might be wondering what skills do you exactly require for being a successful data scientist & how to Learn Data Science? What steps do you need to follow to leap into the field of data science?
Before we get started with the actual data science career path, which of the following expertise/skills do you have?
Insight of a Data Science Roadmap
Since you now know what skills you already possess, the roadmap below can help you understand where you stand & what effort is needed for you to reach the endpoint.
Read more about Data Science Career
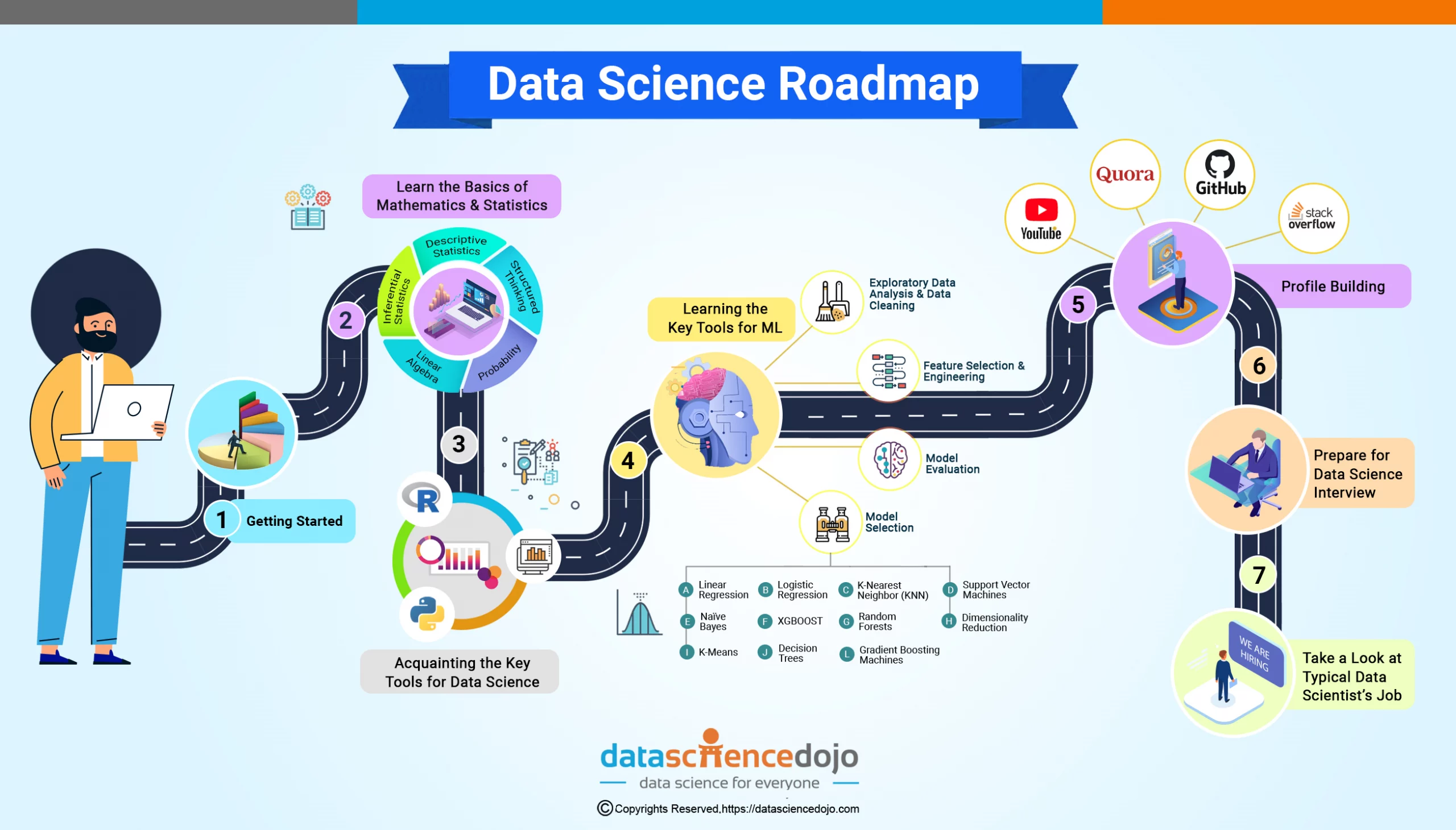
Step 1: Getting Started
Before you move on to learning & adapting to new skills, it is important for you to understand what data science is & whether you are a great fit for it or not.
To further assess, check what type of data scientist you are with the below short quiz:
Step 2: Learn the Basics of Mathematics & Statistics
The next checkpoint in the data science career path is to learn the fundamentals of mathematics & statistics. The topics listed below should be your area of focus:
- Descriptive Statistics
- Probability
- Inferential Statistics
- Linear Algebra
- Structured Thinking
You can further enrich your concepts with these 5 free statistics books, along with these amazing resources to learn math for data science. If you are wondering why math is needed, then you need to take a quick look at this blog post by Dave Langer from Data Science Dojo that explains why math is important in data science.
Step 3: Acquainting with the Key Tools for Data Science
1. Python
It is one of the most popular & widely used programming languages. Learning this language can help you with creating web applications, handling big data, rapid prototyping, and much more.
Learn all the fundamentals of Python for Data Science with our upcoming training!
2. R
Another popular language for programming in R. It provides a free software environment for statistical computing. These few blog posts can definitely add value to your knowledge of R programming:
- Logistic Regression in R
- R language programming for Excel Users
- Natural language Processing with R programming books
You might be stuck with the same traditional argument between R Versus Python; if you are wondering which one of them you should opt for, then I suggest you begin with R and transition to Python gradually. Then use them as per the needs of your organization.
3. Data Exploration & Visualization
If you are into the analytical side of the data, i.e. data analysis, then you must learn data exploration & visualization. Data exploration is the initial step of data analysis, while, data visualization is the graphical representation of the data itself. Both Python & R can be used for exploring & visualizing the data.
Step 4: Learning the Key Tools for ML
There are some basic and advanced machine learning tools that you need to learn & adapt yourself to. Some of the most important ones are listed below. These skills can be of immense value in your overall data science roadmap:
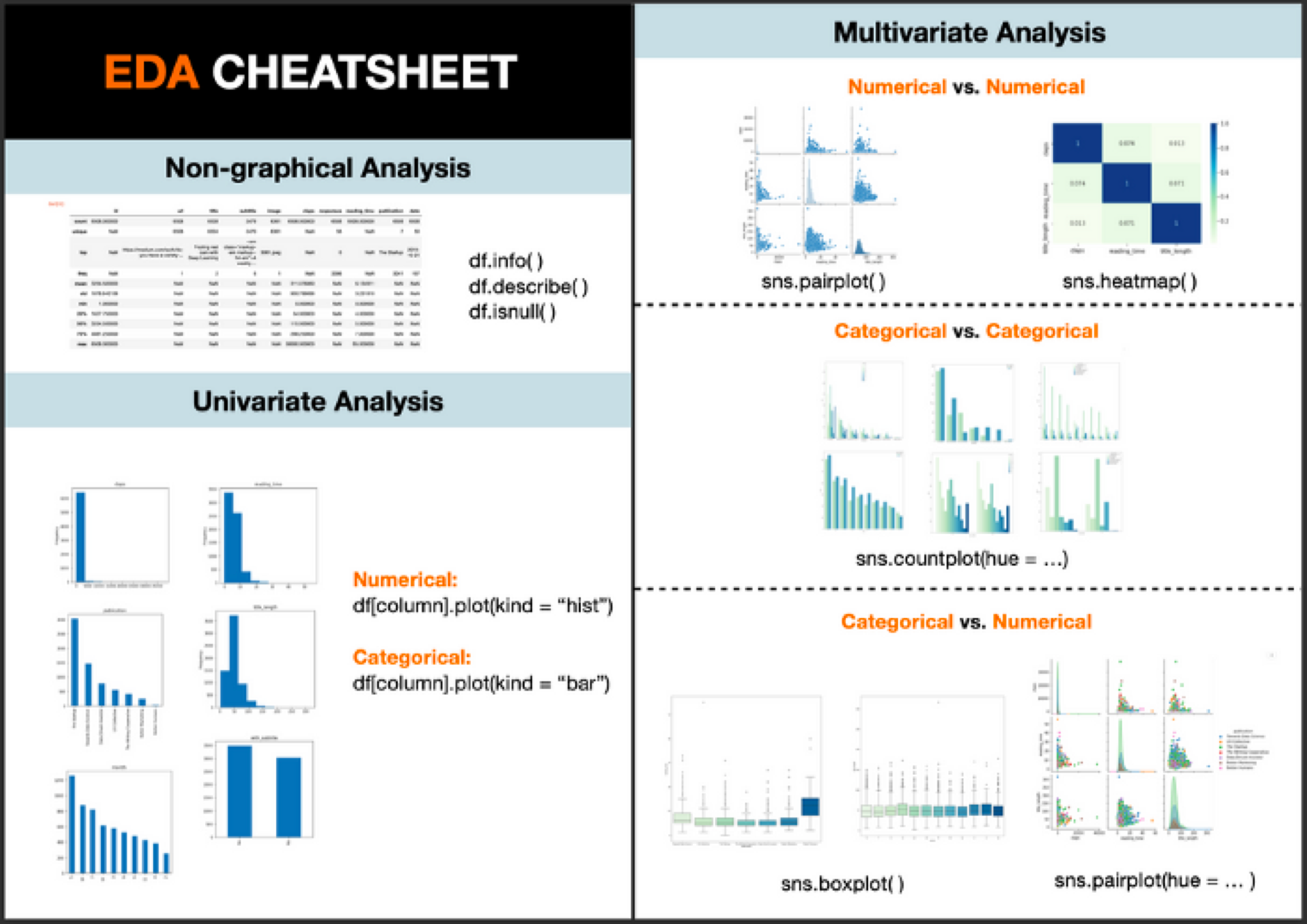
1. Exploratory Data Analysis & Data Cleaning
Before moving on to the ML tools, you need to be well-versed in what EDA & data cleaning is. EDA or exploratory data analysis, is a way of studying the datasets to summarize them into a visual format. Data cleaning is the process of detecting & correcting errors and ensuring that the data is free of errors.
The cheat sheet below can help you get started with EDA now.
2. Feature Selection & Engineering
This should typically be your next step in learning ML. This uses domain knowledge to obtain the features from the data, which in turn helps with improving the performance of ML algorithms. So, if you are willing to gain expertise in the ML domain, you need to learn about feature selection & engineering.
3. Model Selection
Out of all the statistical models, you will need to select one model that is well-suited for your problem. These are some of the statistical models that you can go with:
Linear Regression – It is an algorithm of supervised machine learning, where the slope is constant & the predicted output is continuous. To get started with linear regression.
Logistic Regression – It is an algorithm for supervised learning classification that is used to predict the probability of a target variable. It is typically used for classification purposes.
Decision Trees – This uses a decision tree to form assumptions & conclusions about the target values. It is one of the most common approaches of predictive modeling used in statistics & machine learning.
To build your understanding of a decision tree, review this comprehensive tutorial
K-Nearest Neighbor (KNN) – It is one of the simplest supervised machine learning algorithms that can help with resolving regression & classification problems. It is quite easy to comprehend and learn. But it has a few drawbacks.
K-Means – This is an unsupervised learning algorithm that units the unlabeled sets into diverse clusters. Where K represents the numeral of the troid. This cheat sheet from Stanford university can help you learn about K-means.
Naïve Bayes – It is one of the algorithms for supervised learning that helps in solving classification problems. It is considered one of the most successful algorithms because of its ability to create fast ML models that can help with making predictions.
Dimensionality Reduction – A process of transforming the high-dimension space to a low-dimension space to maintain the meaningful properties of data. Learning dimensionality reduction is an important skill that every data scientist must possess. Break the curse of dimensionality with Python.
Learn more about data science at our Data Science Bootcamp!

Random Forests – It is an ensemble learning method for classification, regression, and other task purposes. It includes drawing multiple decision trees at a time & outputting the class that is the mode of all. Dive deep with this amazing guide by Berkley University.
Gradient Boosting Machines – One of the leading techniques to build predictive models. It helps to deal with regression & classification problems and creates a prediction model in the form of an ensemble of weak prediction models.
XGBOOST – This tool specifically helps with executing the gradient boosted decision trees devised for speed and performance.
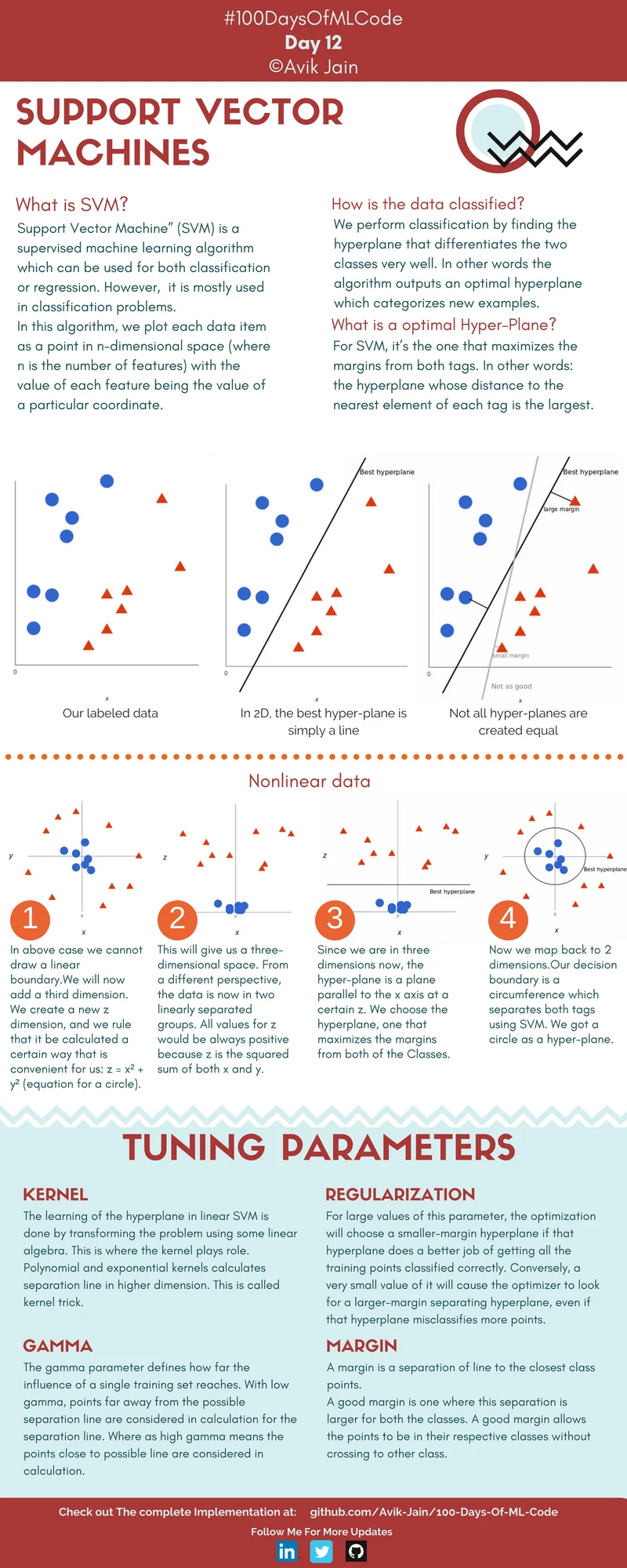
Support Vector Machines – These are supervised learning models that are coupled with associated learning, they aid in evaluating the data for regression & classification analysis.
The below graphic by Avik Jain can be a great help for you to get started with SVMs:
4. Model Evaluation
Moving towards the last step of machine learning, model evaluation, generalizes the accuracy of the model based on future data. It typically uses two methods, holdout & cross-validation.
Step 5: Profile Building
Building a profile on GitHub is an important task that every data scientist must complete. It is one of the most effective ways for a data scientist to gather all the code of the projects they have undertaken. It showcases your code and projects undertaken and shows how long you have been practicing data science.
Moving on, you need to be part of some discussion forums. These will help you find an answer to the questions you are stuck at. Here are some of the discussion forums you can be part of:
To gain more knowledge in the data science domain, start following different YouTube channels.
Our YouTube channel can surely be a good start for you.
Step 6: Prepare for a Data Science Interview
You need to know all those key data science concepts that can help you ace your interviews. With these 101 Data Science Interview Questions. Answers, and Key Concepts you can prepare yourself for the interviews.
Step 7: Take a Look at a Typical Data Scientist’s Job
Reaching the end of your data science roadmap, you might want to get an idea of a typical data scientist’s job. It is always helpful to look at some job descriptions, showcase your skills, and stand out as the best candidate. If you think you are a good fit for it, you must get started right away!
Before I end this post, let me repeat it again, instead of trying to learn all the skills required to be a data scientist endlessly, pick up a problem that inspires you or bees relevant to your domain.
Try to solve that problem using the data science skills, only pick up the skills necessary to solve that problem. As you solve more problems, you will learn more skills along the way.
If you hated probability in high school or university, it is because every example of probability has to do with coin tosses and dice. But if you happen to come across interesting problems, such as the Birthday Paradox, you might have ended up loving probability.
Additional Support
Want to learn more about data science roadmap? The following blog posts have been a great support to me, and likewise, I believe it can be a great help to you as well:
B. Best Places to Work as a Data Scientist Around the World
So, what have you decided? Are planning to get started with Data Science? Take a look at our Data Science Bootcamp, a great way to start your data science journey.