As the artificial intelligence landscape keeps rapidly changing, boosting algorithms have presented us with an advanced way of predictive modelling by allowing us to change how we approach complex data problems across numerous sectors.
These algorithms excel at creating powerful predictive models by combining multiple weak learners. These algorithms significantly enhance accuracy, reduce bias, and effectively handle complex data patterns.
Their ability to uncover feature importance makes them valuable tools for various ML tasks, including classification, regression, and ranking problems. As a result, they have become a staple in the machine learning toolkit.

In this article, we will explore the fundamentals of boosting algorithms and their applications in machine learning.
Understanding Boosting Algorithms Applications
Boosting algorithm applications are a subset of ensemble learning methods in machine learning that operate by combining multiple weak learners to construct robust predictive models. This approach can be likened to assembling a team of average performers who, through collaboration, achieve exceptional results.
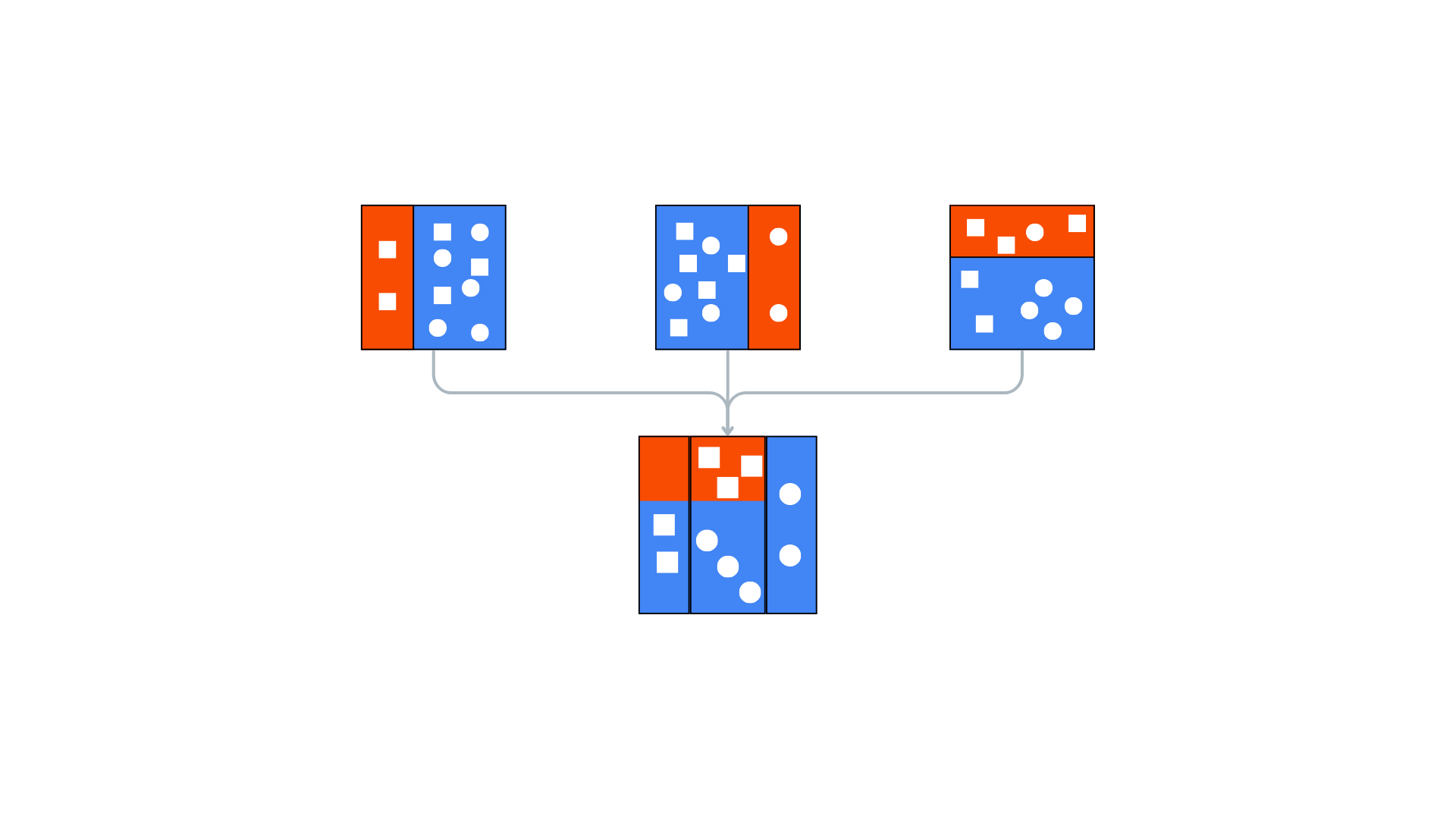
Key Components of Boosting Algorithms
To accurately understand how boosting algorithms work, it’s important to examine their key elements:
- Weak Learners: Simple models that perform marginally better than random assumptions.
- Sequential Learning: Models are trained consecutively, each focusing on the mistakes of the previous weak learner.
- Weighted Samples: Misclassified data points receive increased attention in subsequent rounds.
- Ensemble Prediction: The final prediction integrates the outputs of all weak learners.
Boosting algorithms work with these components to enhance ML functionality and accuracy. While we understand the basics of boosting algorithm applications, let’s take a closer look into the boosting process.
Key Steps of the Boosting Process
Boosting algorithms applications typically follow this sequence:
- Initialization: Assign equal weights to all data points.
- Weak Learner Training: Train a weak learner on the weighted data.
- Error Calculation: Calculate the error rate of the current weak learner.
- Weight Adjustment: Increase the importance of misclassified points.
- Iteration: Repeat steps 2-4 for an already predetermined number of cycles.
- Ensemble Creation: Combine all weak learners into a robust final predictive model.
This iterative approach allows boosting algorithms to concentrate on the most challenging aspects of the data, resulting in highly accurate predictions.
Read more about different ensemble methods for ML predictions
Prominent Boosting Algorithms and Their Applications
Certain boosting algorithms have gained prominence in the machine-learning community:
-
AdaBoost (Adaptive Boosting)
AdaBoost, one of the pioneering boosting algorithms applications, is particularly effective for binary classification problems. It’s widely used in face detection and image recognition tasks.
-
Gradient Boosting
Gradient Boosting focuses on minimizing the loss function of the previous model. Its applications include predicting customer churn and sales forecasting in various industries.
-
XGBoost (Extreme Gradient Boosting)
XGBoost represents an advanced implementation of Gradient Boosting, offering enhanced speed and efficiency. It’s a popular choice in data science competitions and is used in fraud detection systems.
Also explore Gini Index and Entropy
| Aspect | AdaBoost | Gradient Boosting | XGBoost |
| Methodology | Focuses on misclassified samples | Minimizes error of the previous model | Minimizes error of the previous model |
| Regularization | No built-in regularization | No built-in regularization | Includes L1 and L2 regularization |
| Speed | Generally slower | Faster than AdaBoost | Fastest, includes optimization techniques |
| Handling Missing Values | Requires explicit imputation | Requires explicit imputation | Built-in functionality |
| Multi-Class Classification | Requires One-vs-All approach | Requires One-vs-All approach | Handles natively |
Real-World Applications of Boosting Algorithms
Boosting algorithms have transformed machine learning, offering robust solutions to complex challenges across diverse fields. Here are some key applications that demonstrate their versatility and impact:
-
Image Recognition and Computer Vision
Boosting algorithms significantly improve image recognition and computer vision by combining weak learners to achieve high accuracy. They are used in security surveillance for facial recognition and wildlife monitoring for species identification.
-
Natural Language Processing (NLP)
Boosting algorithms enhance NLP tasks such as sentiment analysis, language translation, and text summarization. They improve the accuracy of text sentiment classification, enhance the quality of machine translation, and generate concise summaries of large texts.
-
Finance
In finance, boosting algorithms improve stock price prediction, fraud detection, and credit risk assessment. They analyse large datasets to forecast market trends, identify unusual patterns to prevent fraud, and evaluate borrowers’ risk profiles to mitigate defaults.
Top 8 Data Science use-cases in Finance
-
Medical Diagnoses
In healthcare, boosting algorithms enhance predictive models for early disease detection, personalized treatment plans, and outcome predictions. They excel at identifying diseases from medical images and patient data, tailoring treatments to individual needs
Also read about 10 AI Healthcare Startups
-
Recommendation Systems
Boosting algorithms are used in e-commerce and streaming services to improve recommendation systems. By analysing user behaviour, they provide accurate, personalized content and handle large data volumes efficiently.
Key Advantages of Boosting
Some common benefits of boosting in ML include:
- Implementation Ease: Boosting methods are user-friendly, particularly with tools like Python’s scikit-learn library, which includes popular algorithms like AdaBoost and XGBoost. These methods handle missing data with built-in routines and require minimal data preprocessing.
- Bias Reduction: Boosting algorithms sequentially combine multiple weak learners, improving predictions iteratively. This process helps mitigate the high bias often seen in shallow decision trees and logistic regression models.
- Increased Computational Efficiency: Boosting can enhance predictive performance during training, potentially reducing dimensionality and improving computational efficiency.
Learn more about algorithmic bias and skewed decision-making
Challenges of Boosting
While boosting is a useful practice to enhance ML accuracy, it comes with its own set of hurdles. Some key challenges of the process are as follows:
- Risk of Overfitting: The impact of boosting on overfitting is debated. When overfitting does occur, the model’s predictions may not generalize well to new datasets.
- High Computational Demand: The sequential nature of boosting, where each estimator builds on its predecessors, can be computationally intensive. Although methods like XGBoost address some scalability concerns, boosting can still be slower than bagging due to its numerous parameters.
- Sensitivity to Outliers: Boosting models are prone to being influenced by outliers. Each model attempts to correct the errors of the previous ones, making results susceptible to significant skewing in the presence of outlier data.
- Challenges in Real-Time Applications: Boosting can be complex for real-time implementation. Its adaptability, with various model parameters affecting performance, adds to the difficulty of deploying boosting methods in real-time scenarios.
Value of Boosting Algorithms in ML
Boosting algorithm applications has significantly advanced the field of machine learning by enhancing model accuracy and tackling complex prediction tasks. Their ability to combine weak learners into powerful predictive models has made them invaluable across various industries.
As AI continues to evolve, these techniques will likely play an increasingly crucial role in developing sophisticated predictive models. By understanding and leveraging boosting algorithms applications, data scientists and machine learning practitioners can unlock new levels of performance in their predictive modelling endeavours.