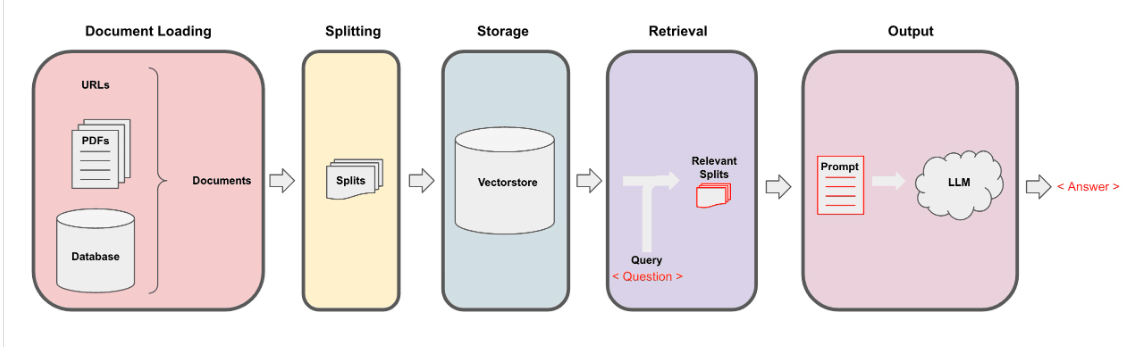
Imagine staring at a blank screen, the cursor blinking impatiently. You know you have a story to tell, but the words just won’t flow. You’ve brainstormed, outlined, and even consumed endless cups of coffee, but inspiration remains elusive. This was often the reality for writers, especially in the fast-paced world of blog writing.

In this struggle, enter chatbots as potential saviors, promising to spark ideas with ease. But their responses often felt generic, trapped in a one-size-fits-all format that stifled creativity. It was like trying to create a masterpiece with a paint-by-numbers kit.
Then comes Dynamic Few-Shot Prompting into the scene. This revolutionary technique is a game-changer in the creative realm, empowering language models to craft more accurate, engaging content that resonates with readers.
It addresses the challenges by dynamically selecting a relevant subset of examples for prompts, allowing for a tailored and diverse set of creative responses specific to user needs. Think of it as having access to a versatile team of writers, each specializing in different styles and genres.
Before moving forward, consider exploring our LLM Bootcamp to see how it can help you harness the power of large language models effectively.
Quick Prompting Test For You
To comprehend this exciting technique, let’s first delve into its parent concept: Few-shot prompting.
Few-Shot Prompting
Few-shot prompting is a technique in natural language processing that involves providing a language model with a limited set of task-specific examples, often referred to as “shots,” to guide its responses in a desired way. This means you can “teach” the model how to respond on the fly simply by showing it a few examples of what you want it to do.
In this approach, the user collects examples representing the desired output or behavior. These examples are then integrated into a prompt instructing the Large Language Model (LLM) on how to generate the intended responses.
The prompt, including the task-specific examples, is then fed into the LLM, allowing it to leverage the provided context to produce new and contextually relevant outputs.
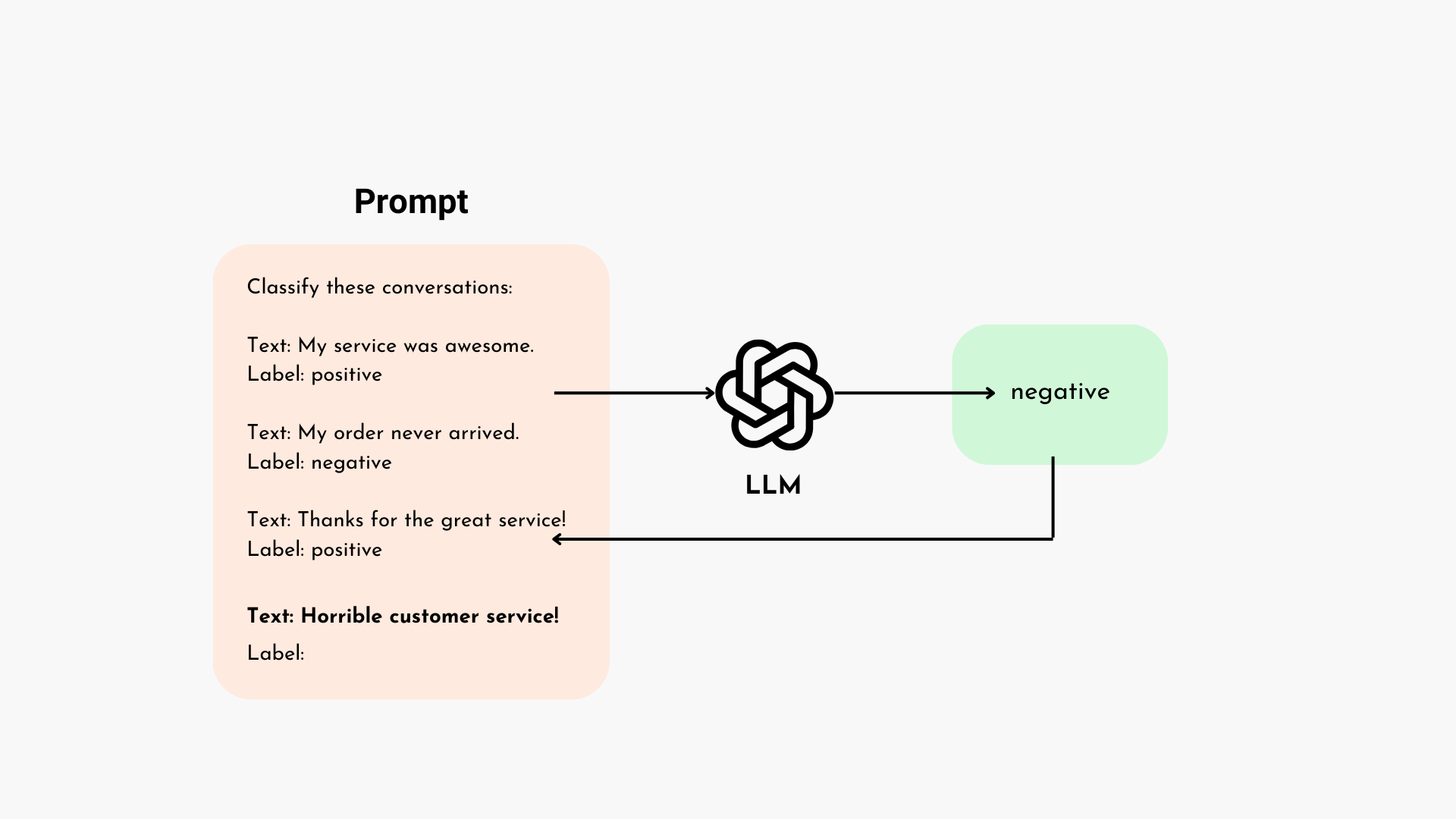
Unlike zero-shot prompting, where the model relies solely on its pre-existing knowledge, few-shot prompting enables the model to benefit from in-context learning by incorporating specific task-related examples within the prompt.
Dynamic Few-Shot Prompting: Taking It to the Next Level
Dynamic Few-Shot Prompting takes this adaptability a step further by dynamically selecting the most relevant examples based on the specific context of a user’s query. This means the model can tailor its responses even more precisely, resulting in more relevant and engaging content.
To choose relevant examples, various methods can be employed. In this blog, we’ll explore the semantic example selector, which retrieves the most relevant examples through semantic matching.
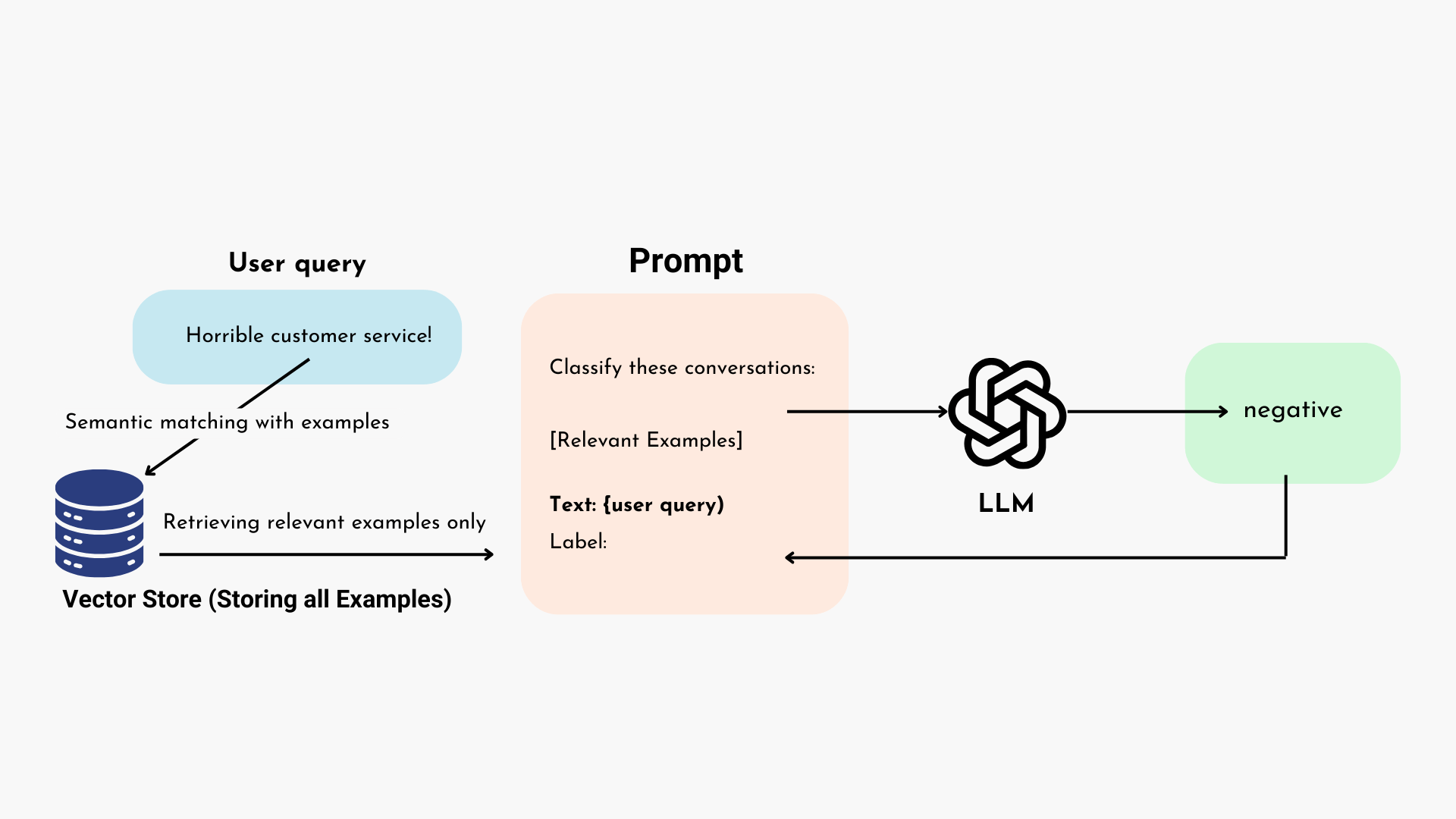
What Is the Importance of Dynamic Few-Shot Prompting?
The significance of Dynamic Few-Shot Prompting lies in its ability to address critical challenges faced by modern Large Language Models (LLMs). With limited context lengths in LLMs, processing longer prompts becomes challenging, requiring increased computational resources and incurring higher financial costs.
You can also create engaging videos using prompts—learn how
Dynamic Few-Shot Prompting optimizes efficiency by strategically utilizing a subset of training data, effectively managing resources. This adaptability allows the model to dynamically select relevant examples, catering precisely to user queries, resulting in more precise, engaging, and cost-effective responses.
A Closer Look (With Code!)
It’s time to get technical! Let’s delve into the workings of Dynamic Few-Shot Prompting using the LangChain Framework.
Importing necessary modules and libraries.
In the .env file, I have my OpenAI API key and base URL stored for secure access.
This code defines an example prompt template with input variables “user_query” and “blog_format” to be utilized in the FewShotPromptTemplate of LangChain.
| user_query_1 = “Write a technical blog on topic [user topic]”
blog_format_1 = “”” **Title:** [Compelling and informative title related to user topic]
**Introduction:** * Introduce the topic in a clear and concise way. * State the problem or question that the blog will address. * Briefly outline the key points that will be covered.
**Body:** * Break down the topic into well-organized sections with clear headings. * Use bullet points, numbered lists, and diagrams to enhance readability. * Provide code examples or screenshots where applicable. * Explain complex concepts in a simple and approachable manner. * Use technical terms accurately, but avoid jargon that might alienate readers.
**Conclusion:** * Summarize the main takeaways of the blog. * Offer a call to action, such as inviting readers to learn more or try a new technique.
**Additional tips for technical blogs:** * Use visuals to illustrate concepts and break up text. * Link to relevant resources for further reading. * Proofread carefully for accuracy and clarity. “””
|
user_query_2 = “Write a humorous blog on topic [user topic]”
blog_format_2 = “”” **Title:** [Witty and attention-grabbing title that makes readers laugh before they even start reading]
**Introduction:** * Set the tone with a funny anecdote or observation. * Introduce the topic with a playful twist. * Tease the hilarious insights to come.
**Body:** * Use puns, wordplay, exaggeration, and unexpected twists to keep readers entertained. * Share relatable stories and experiences that poke fun at everyday life. * Incorporate pop culture references or current events for added relevance. * Break the fourth wall and address the reader directly to create a sense of connection.
**Conclusion:** * End on a high note with a punchline or final joke that leaves readers wanting more. * Encourage readers to share their own funny stories or experiences related to the topic.
**Additional tips for humorous blogs:** * Keep it light and avoid sensitive topics. * Use visual humor like memes or GIFs. * Read your blog aloud to ensure the jokes land. “”” |
user_query_3 = “Write an adventure blog about a trip to [location]”
blog_format_3 = “”” **Title:** [Evocative and exciting title that captures the spirit of adventure]
**Introduction:** * Set the scene with vivid descriptions of the location and its atmosphere. * Introduce the protagonist (you or a character) and their motivations for the adventure. * Hint at the challenges and obstacles that await.
**Body:** * Chronicle the journey in chronological order, using sensory details to bring it to life. * Describe the sights, sounds, smells, and tastes of the location. * Share personal anecdotes and reflections on the experience. * Build suspense with cliffhangers and unexpected twists. * Capture the emotions of excitement, fear, wonder, and accomplishment.
**Conclusion:** * Reflect on the lessons learned and the personal growth experienced during the adventure. * Inspire readers to seek out their own adventures.
**Additional tips for adventure blogs:** * Use high-quality photos and videos to showcase the location. * Incorporate maps or interactive elements to enhance the experience. * Write in a conversational style that draws readers in. “”” |
These examples showcase different blog formats, each tailored to a specific genre. The three dummy examples include a technical blog template with a focus on clarity and code, a humorous blog template designed for entertainment with humor elements, and an adventure blog template emphasizing vivid storytelling and immersive details about a location.
While these are just three examples for simplicity, more formats can be added, to cater to diverse writing styles and topics. Instead of examples showcasing formats, original blogs can also be utilized as examples.
Next, we’ll compile a list from the crafted examples. This list will be passed to the example selector to store them in the vector store with vector embeddings. This arrangement enables semantic matching to these examples at a later stage.
Now initialize AzureOpenAIEmbeddings() for creating embeddings used in semantic similarity.
Now comes the example selector that stores the provided examples in a vector store. When a user asks a question, it retrieves the most relevant example based on semantic similarity. In this case, k=1 ensures only one relevant example is retrieved.
This code sets up a FewShotPromptTemplate for dynamic few-shot prompting in LangChain. The ExampleSelector is used to fetch relevant examples based on semantic similarity, and these examples are incorporated into the prompt along with the user query. The resulting template is then ready for generating dynamic and tailored responses.
Output

This output gives an understanding of the final prompt that our LLM will use for generating responses. When the user query is “I’m writing a blog on Machine Learning. What topics should I cover?”, the ExampleSelector employs semantic similarity to fetch the most relevant example, specifically a template for a technical blog.
Hence the resulting prompt integrates instructions, the retrieved example, and the user query, offering a customized structure for crafting engaging content related to Machine Learning. With k=1, only one example is retrieved to shape the response.
As our prompt is ready, now we will initialize an Azure ChatGPT model to generate a tailored blog structure response based on a user query using dynamic few-shot prompting.

Output

The LLM efficiently generates a blog structure tailored to the user’s query, adhering to the format of technical blogs, and showcasing how dynamic few-shot prompting can provide relevant and formatted content based on user input.
Conclusion
To conclude, Dynamic Few-Shot Prompting takes the best of two worlds (few-shot prompts and zero-shot prompts) and makes language models even better. It helps them understand your goals using smart examples, focusing only on relevant things according to the user’s query. This saves resources and opens the door for innovative use.
Dynamic Few-Shot Prompting adapts well to the token limitations of Large Language Models (LLMs) giving efficient results. As this technology advances, it will revolutionize the way Large Language Models respond, making them more efficient in various applications.