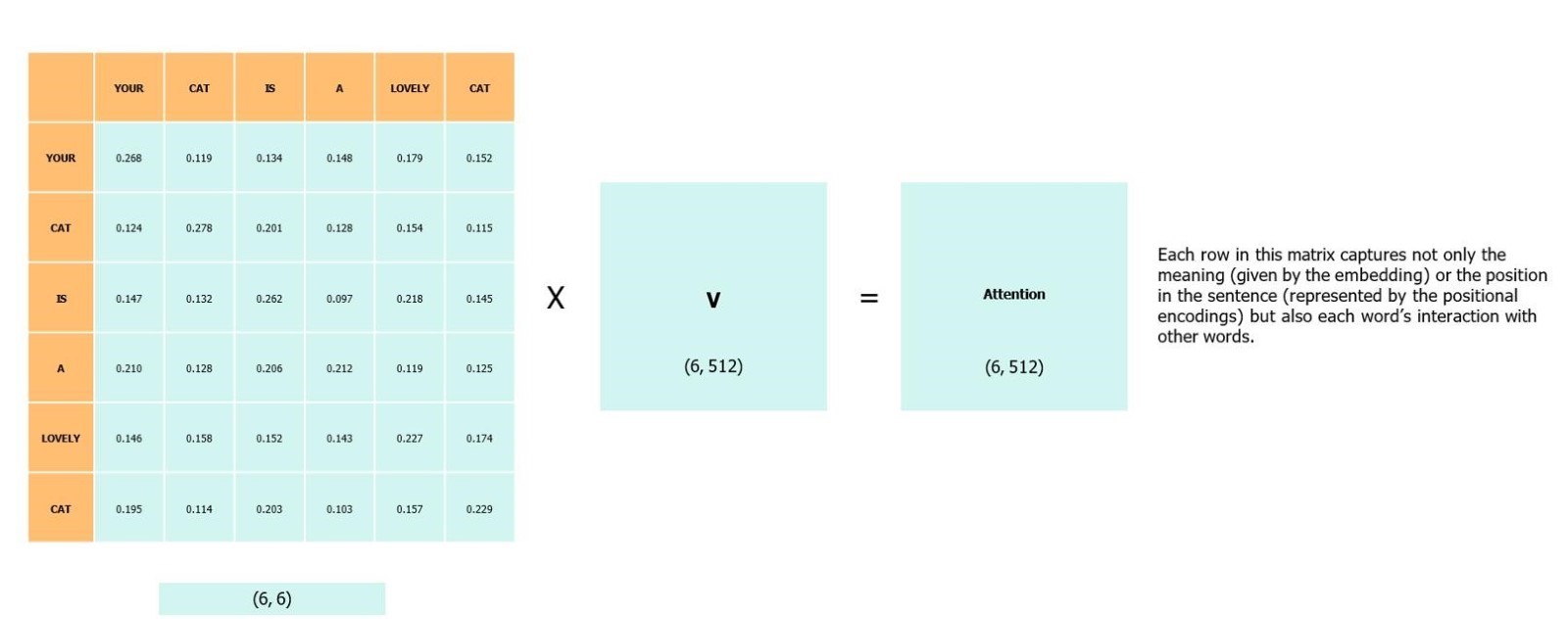
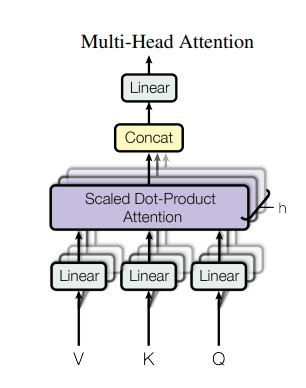
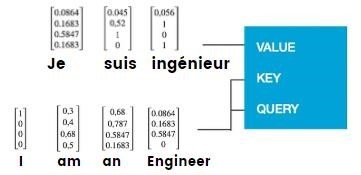
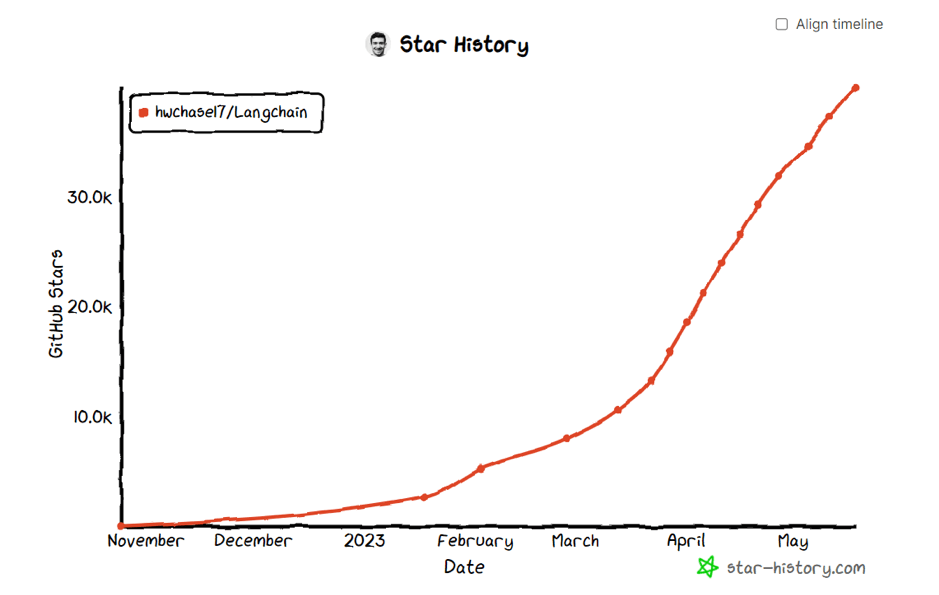
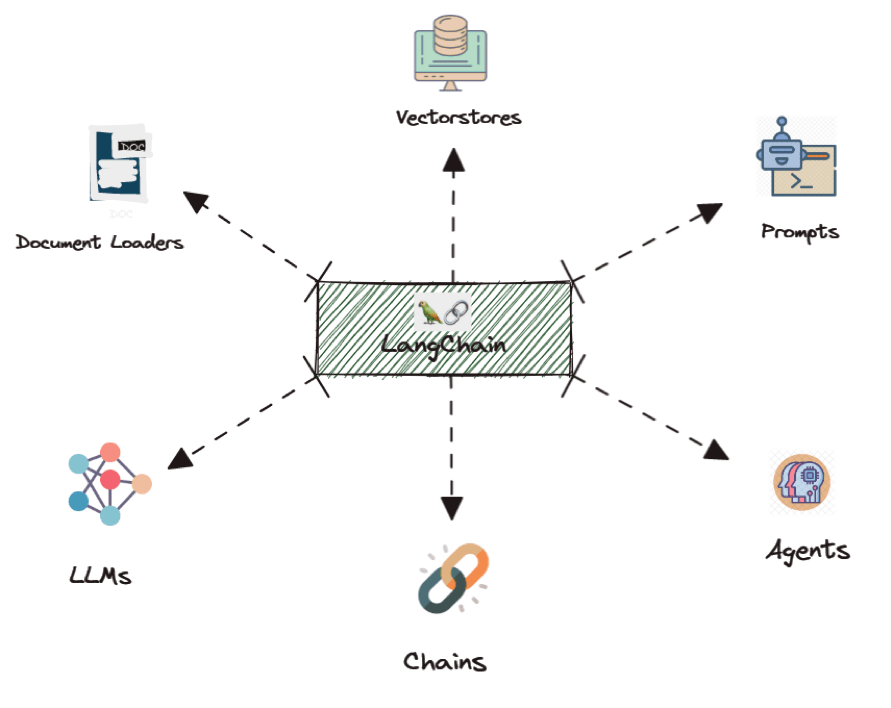
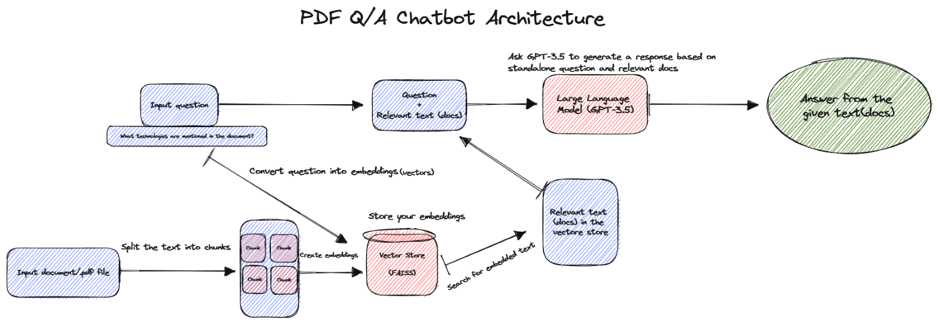
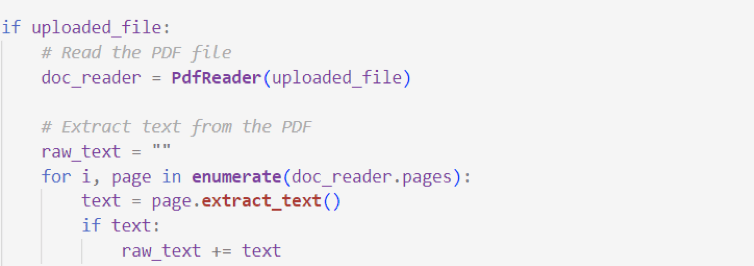
In the rapidly evolving world of artificial intelligence and large language models (LLMs), developers are constantly seeking ways to create more flexible, powerful, and intuitive AI agents.
While LangChain has been a game-changer in this space, allowing for the creation of complex chains and agents, there’s been a growing need for even more sophisticated control over agent runtimes.
Enter LangGraph, a cutting-edge module built on top of LangChain that’s set to revolutionize how we design and implement AI workflows.
In this blog, we present a detailed LangGraph tutorial on building a chatbot and revolutionizing AI agent workflows.

Understanding LangGraph
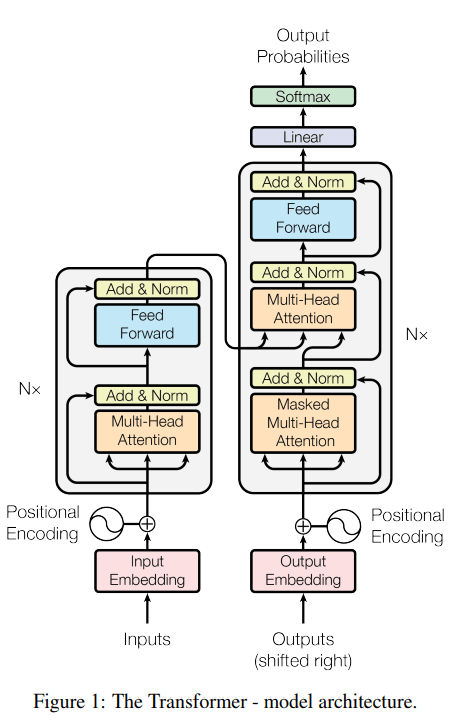
LangGraph is an extension of the LangChain ecosystem that introduces a novel approach to creating AI agent runtimes. At its core, LangGraph allows developers to represent complex workflows as cyclical graphs, providing a more intuitive and flexible way to design agent behaviors.
The primary motivation behind LangGraph is to address the limitations of traditional directed acyclic graphs (DAGs) in representing AI workflows. While DAGs are excellent for linear processes, they fall short when it comes to implementing the kind of iterative, decision-based flows that advanced AI agents often require.
Explore the difference between LangChain and LlamaIndex
LangGraph solves this by enabling the creation of workflows with cycles, where an AI can revisit previous steps, make decisions, and adapt its behavior based on intermediate results. This is particularly useful in scenarios where an agent might need to refine its approach or gather additional information before proceeding.
Key Components of LangGraph
To effectively use LangGraph, it’s crucial to understand its fundamental components:
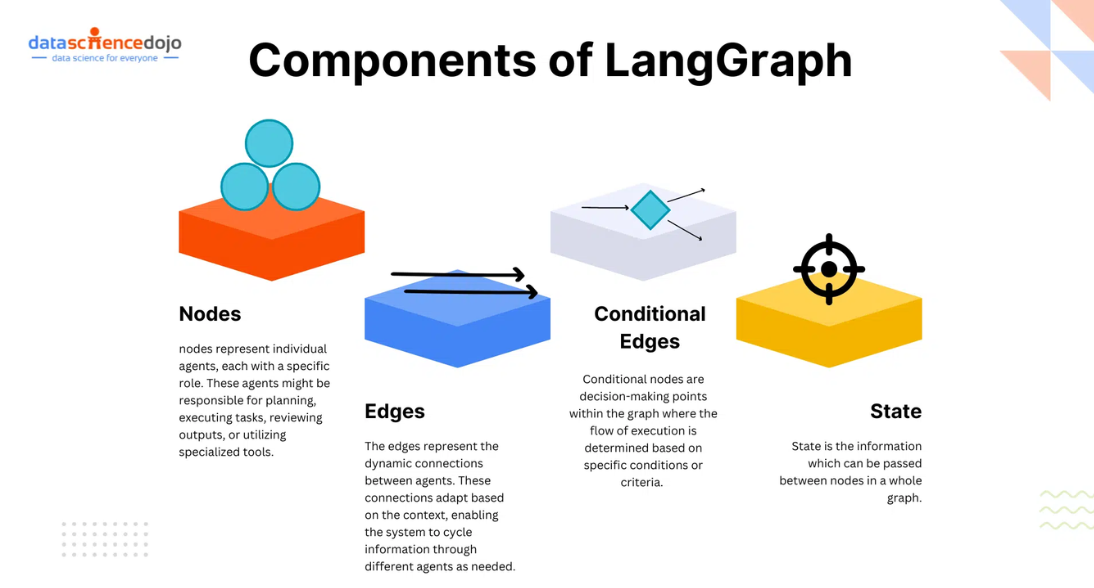
Nodes
Nodes in LangGraph represent individual functions or tools that your AI agent can use. These can be anything from API calls to complex reasoning tasks performed by language models. Each node is a discrete step in your workflow that processes input and produces output.
Edges
Edges connect the nodes in your graph, defining the flow of information and control. LangGraph supports two types of edges:
- Simple Edges: These are straightforward connections between nodes, indicating that the output of one node should be passed as input to the next.
- Conditional Edges: These are more complex connections that allow for dynamic routing based on the output of a node. This is where LangGraph truly shines, enabling adaptive workflows.
Read about LangChain agents and their use for time series analysis
State
State is the information that can be passed between nodes in a whole graph. If you want to keep track of specific information during the workflow then you can use state.
There are 2 types of graphs which you can make in LangGraph:
- Basic Graph: The basic graph will only pass the output of the first node to the next node because it can’t contain states.
- Stateful Graph: This graph can contain a state which will be passed between nodes and you can access this state at any node.

LangGraph Tutorial Using a Simple Example: Build a Basic Chatbot
We’ll create a simple chatbot using LangGraph. This chatbot will respond directly to user messages. Though simple, it will illustrate the core concepts of building with LangGraph. By the end of this section, you will have a built rudimentary chatbot.
Start by creating a StateGraph. A StateGraph object defines the structure of our chatbot as a state machine. We’ll add nodes to represent the LLM and functions our chatbot can call and edges to specify how the bot should transition between these functions.
Explore this guide to building LLM chatbots
So now our graph knows two things:
- Every node we define will receive the current State as input and return a value that updates that state.
- messages will be appended to the current list, rather than directly overwritten. This is communicated via the prebuilt add_messages function in the Annotated syntax.
Next, add a chatbot node. Nodes represent units of work. They are typically regular Python functions.
Notice how the chatbot node function takes the current State as input and returns a dictionary containing an updated messages list under the key “messages”. This is the basic pattern for all LangGraph node functions.
The add_messages function in our State will append the LLM’s response messages to whatever messages are already in the state.
Next, add an entry point. This tells our graph where to start its work each time we run it.
Similarly, set a finish point. This instructs the graph “Any time this node is run, you can exit.”
Finally, we’ll want to be able to run our graph. To do so, call “compile()” on the graph builder. This creates a “CompiledGraph” we can use invoke on our state.
You can visualize the graph using the get_graph method and one of the “draw” methods, like draw_ascii or draw_png. The draw methods each require additional dependencies.
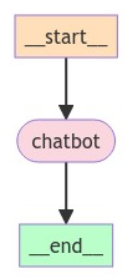
Now let’s run the chatbot!
Tip: You can exit the chat loop at any time by typing “quit”, “exit”, or “q”.
Advanced LangGraph Techniques
LangGraph’s true potential is realized when dealing with more complex scenarios. Here are some advanced techniques:
- Multi-step reasoning: Create graphs where the AI can make multiple decisions, backtrack, or explore different paths based on intermediate results.
- Tool integration: Seamlessly incorporate various external tools and APIs into your workflow, allowing the AI to gather and process diverse information.
- Human-in-the-loop workflows: Design graphs that can pause execution and wait for human input at critical decision points.
- Dynamic graph modification: Alter the structure of the graph at runtime based on the AI’s decisions or external factors.
You can also deepen your knowledge with our webinar on building multi-agent AI applications with LangGraph.
Learn how to build custom Q&A chatbots
Real-World Applications
LangGraph’s flexibility makes it suitable for a wide range of applications:
- Customer Service Bots: Create intelligent chatbots that can handle complex queries, access multiple knowledge bases, and escalate to human operators when necessary.
- Research Assistants: Develop AI agents that can perform literature reviews, synthesize information from multiple sources, and generate comprehensive reports.
- Automated Troubleshooting: Build expert systems that can diagnose and solve technical problems by following complex decision trees and accessing various diagnostic tools.
- Content Creation Pipelines: Design workflows for AI-assisted content creation, including research, writing, editing, and publishing steps.
Explore the list of top AI content generators
Conclusion
LangGraph represents a significant leap forward in the design and implementation of AI agent workflows. Enabling cyclical, state-aware graphs, opens up new possibilities for creating more intelligent, adaptive, and powerful AI systems.
As the field of AI continues to evolve, tools like LangGraph will play a crucial role in shaping the next generation of AI applications.

Whether you’re building simple chatbots or complex AI-powered systems, LangGraph provides the flexibility and power to bring your ideas to life. As we continue to explore the potential of this tool, we can expect to see even more innovative and sophisticated AI applications emerging in the near future.
Are you curious to learn more about the role of LangGraph in the LLM ecosystem? To boost your knowledge further, join our LLM Bootcamp today!