

In the dynamic field of artificial intelligence, Large Language Models (LLMs) are groundbreaking innovations shaping how we interact with digital environments. These sophisticated models, trained on vast collections of text, have the extraordinary ability to comprehend and generate text that mirrors human language, powering a variety of applications from virtual assistants to automated content creation.
The essence of LLMs lies not only in their initial training but significantly in fine-tuning, a crucial step to refine these models for specialized tasks and ensure their outputs align with human expectations.
Introduction to Finetuning
Finetuning LLMs involves adjusting pre-trained models to perform specific functions more effectively, enhancing their utility across different applications. This process is essential because, despite the broad knowledge base acquired through initial training, LLMs often require customization to excel in particular domains or tasks.
Explore the concept of finetuning in detail here
For instance, a model trained on a general dataset might need fine-tuning to understand the nuances of medical language or legal jargon, making it more relevant and effective in those contexts.
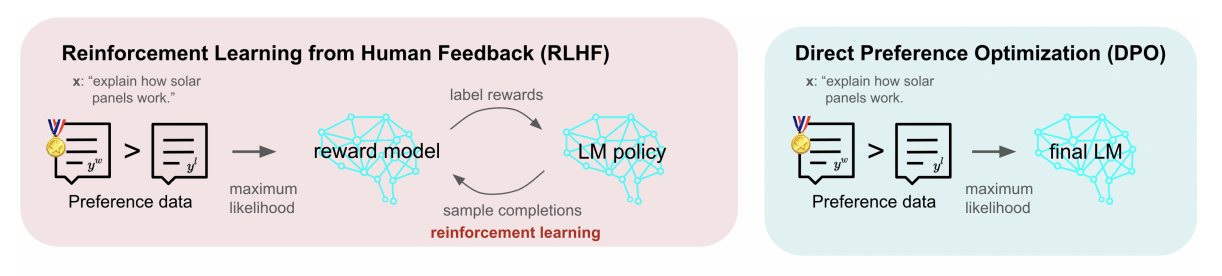
Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are two leading methodologies for finetuning LLMs. RLHF utilizes a sophisticated feedback loop, incorporating human evaluations and a reward model to guide the AI’s learning process.
On the other hand, DPO adopts a more straightforward approach, directly applying human preferences to influence the model’s adjustments. Both strategies aim to enhance model performance and ensure the outputs are in tune with user needs, yet they operate on distinct principles and methodologies.

This blog post aims to unfold the layers of RLHF and DPO, drawing a comparative analysis to elucidate their mechanisms, strengths, and optimal use cases.
Understanding these fine-tuning methods paves the path to deploying LLMs that not only boast high performance but also resonate deeply with human intent and preferences, marking a significant step towards achieving more intuitive and effective AI-driven solutions.
Examples of How Finetuning Improves Performance in Practical Applications
- Customer Service Chatbots: Fine-tuning an LLM on customer service transcripts can enhance its ability to understand and respond to user queries accurately, improving customer satisfaction.
- Legal Document Analysis: By fine-tuning legal texts, LLMs can become adept at navigating complex legal language, aiding in tasks like contract review or legal research.
- Medical Diagnosis Support: LLMs fine-tuned with medical data can assist healthcare professionals by providing more accurate information retrieval and patient interaction, thus enhancing diagnostic processes.
Explore the use of vector databases in precision medicine
Explore Reinforcement Learning from Human Feedback (RLHF)
Explanation of RLHF and its Components
Reinforcement Learning from Human Feedback (RLHF) is a technique used to fine-tune AI models, particularly language models, to enhance their performance based on human feedback.
The core components of RLHF include the fine-tuned language model, the reward model that evaluates the language model’s outputs, and the human feedback that informs the reward model. This process ensures that the language model produces outputs that are more aligned with human preferences.
Here’s a detailed guide to LLM evaluation for you
Theoretical Foundations of RLHF
RLHF is grounded in reinforcement learning, where the model learns from actions rather than from a static dataset.
Unlike supervised learning, where models learn from labeled data, or unsupervised learning, where models identify patterns in data, reinforcement learning models learn from the consequences of their actions, guided by rewards. In RLHF, the “reward” is determined by human feedback, which signifies the model’s success in generating desirable outputs.
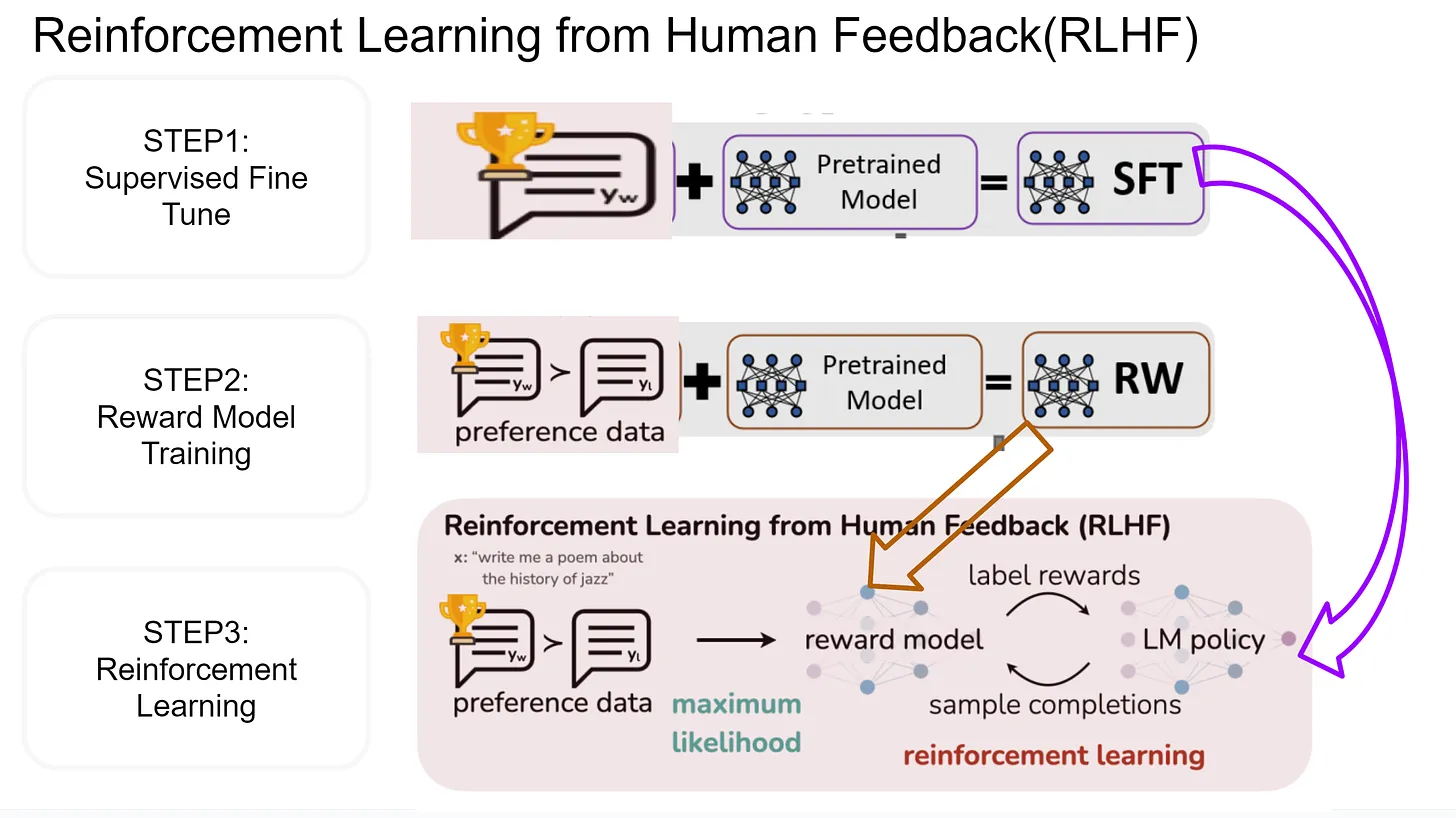
Four-Step Process of RLHF
1. Pretraining the Language Model with Self-Supervision
- Data Gathering: The process begins by collecting a vast and diverse dataset, typically encompassing a wide range of topics, languages, and writing styles. This dataset serves as the initial training ground for the language model.
- Self-Supervised Learning: Using this dataset, the model undergoes self-supervised learning. Here, the model is trained to predict parts of the text given other parts. For instance, it might predict the next word in a sentence based on the previous words. This phase helps the model grasp the basics of language, including grammar, syntax, and some level of contextual understanding.
- Foundation Building: The outcome of this stage is a foundational model that has a general understanding of language. It can generate text and understand some context but lacks specialization or fine-tuning for specific tasks or preferences.
2. Ranking Model’s Outputs Based on Human Feedback
- Generation and Evaluation: Once pretraining is complete, the model starts generating text outputs, which are then evaluated by humans. This could involve tasks like completing sentences, answering questions, or engaging in dialogue.
- Scoring System: Human evaluators use a scoring system to rate each output. They consider factors like how relevant, coherent, or engaging the text is. This feedback is crucial as it introduces the model to human preferences and standards.
- Adjustment for Bias and Diversity: Care is taken to ensure the diversity of evaluators and mitigate biases in feedback. This helps in creating a balanced and fair assessment criterion for the model’s outputs.
Here’s your guide to understanding LLMs
3. Training a Reward Model to Mimic Human Ratings
- Modeling Human Judgment: The scores and feedback from human evaluators are then used to train a separate model, known as the reward model. This model aims to understand and predict the scores human evaluators would give to any piece of text generated by the language model.
- Feedback Loop: The reward model effectively creates a feedback loop. It learns to distinguish between high-quality and low-quality outputs based on human ratings, encapsulating the criteria humans use to judge the text.
- Iteration for Improvement: This step might involve several iterations of feedback collection and reward model adjustment to accurately capture human preferences.
Learn in detail about the use of RLHF for AI applications
4. Finetuning the Language Model Using Feedback from the Reward Model
- Integration of Feedback: The insights gained from the reward model are used to fine-tune the language model. This involves adjusting the model’s parameters to increase the likelihood of generating text that aligns with the rewarded behaviors.
- Reinforcement Learning Techniques: Techniques such as Proximal Policy Optimization (PPO) are employed to methodically adjust the model. The model is encouraged to “explore” different ways of generating text but is “rewarded” more when it produces outputs that are likely to receive higher scores from the reward model.
- Continuous Improvement: This fine-tuning process is iterative and can be repeated with new sets of human feedback and reward model adjustments, continuously improving the language model’s alignment with human preferences.
The iterative process of RLHF allows for continuous improvement of the language model’s outputs. Through repeated cycles of feedback and adjustment, the model refines its approach to generating text, becoming better at producing outputs that meet human standards of quality and relevance.
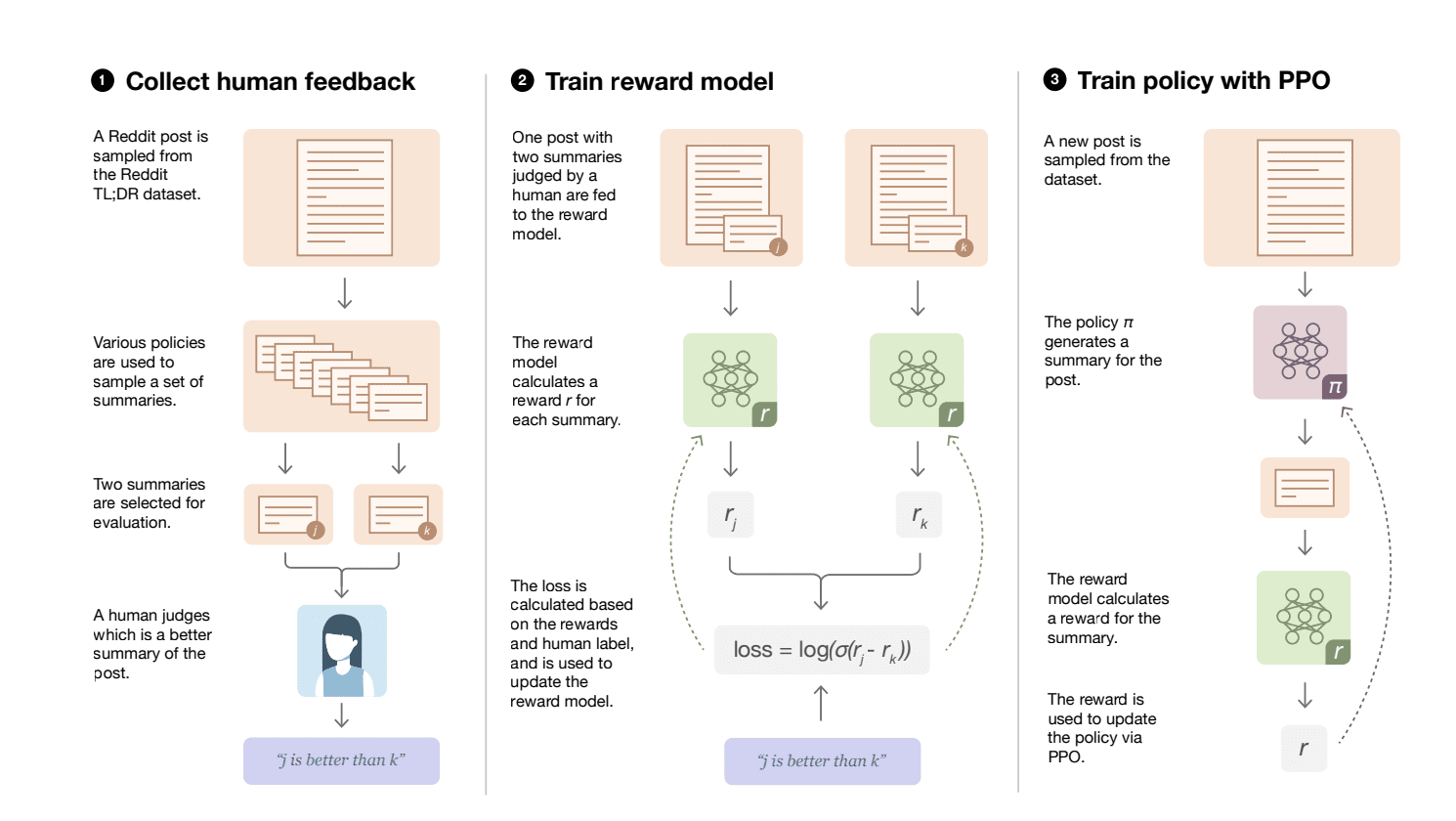
Exploring Direct Preference Optimization (DPO)
Concept of DPO as a Direct Approach
Direct Preference Optimization (DPO) represents a streamlined method for fine-tuning large language models (LLMs) by directly incorporating human preferences into the training process.
This technique simplifies the adaptation of AI systems to better meet user needs, bypassing the complexities associated with constructing and utilizing reward models.
Theoretical Foundations of DPO
DPO is predicated on the principle that direct human feedback can effectively guide the development of AI behavior.
By directly using human preferences as a training signal, DPO simplifies the alignment process, framing it as a direct learning task. This method proves to be both efficient and effective, offering advantages over traditional reinforcement learning approaches like RLHF.
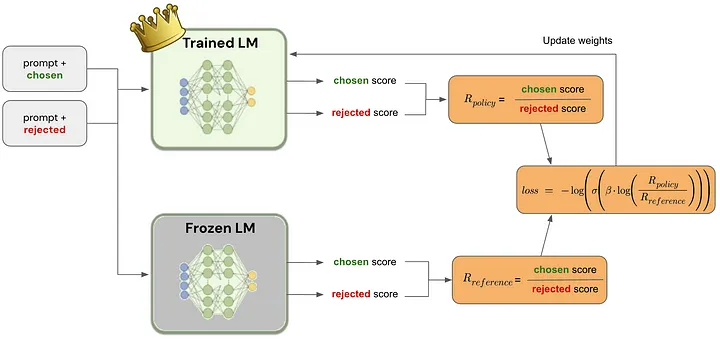
Steps Involved in the DPO process
1. Training the Language Model through Self-Supervision
- Data Preparation: The model starts with self-supervised learning, where it is exposed to a wide array of text data. This could include everything from books and articles to websites, encompassing a variety of topics, styles, and contexts.
- Learning Mechanism: During this phase, the model learns to predict text sequences, essentially filling in blanks or predicting subsequent words based on the preceding context. This method helps the model grasp the fundamentals of language structure, syntax, and semantics without explicit task-oriented instructions.
- Outcome: The result is a baseline language model capable of understanding and generating coherent text, ready for further specialization based on specific human preferences.
2. Collecting Pairs of Examples and Obtaining Human Ratings
- Generation of Comparative Outputs: The model generates pairs of text outputs, which might vary in tone, style, or content focus. These pairs are then presented to human evaluators in a comparative format, asking which of the two better meets certain criteria such as clarity, relevance, or engagement.
- Human Interaction: Evaluators provide their preferences, which are recorded as direct feedback. This step is crucial for capturing nuanced human judgments that might not be apparent from purely quantitative data.
- Feedback Incorporation: The preferences gathered from this comparison form the foundational data for the next phase of optimization. This approach ensures that the model’s tuning is directly influenced by human evaluations, making it more aligned with actual user expectations and preferences.
3. Training the Model Using a Cross-Entropy-Based Loss Function
- Optimization Technique: Armed with pairs of examples and corresponding human preferences, the model undergoes fine-tuning using a binary cross-entropy loss function. This statistical method compares the model’s output against the preferred outcomes, quantifying how well the model’s predictions match the chosen preferences.
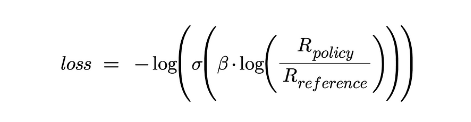
- Adjustment Process: The model’s parameters are adjusted to minimize the loss function, effectively making the preferred outputs more likely in future generations. This process iteratively improves the model’s alignment with human preferences, refining its ability to generate text that resonates with users.
4. Constraining the Model to Maintain its Generativity
- Balancing Act: While the model is being fine-tuned to align closely with human preferences, it’s vital to ensure that it doesn’t lose its generative diversity. The process involves carefully adjusting the model to incorporate feedback without overfitting specific examples or restricting its creative capacity.
- Ensuring Flexibility: Techniques and safeguards are put in place to ensure the model remains capable of generating a wide range of responses. This includes regular evaluations of the model’s output diversity and implementing mechanisms to prevent the narrowing of its generative abilities.
- Outcome: The final model retains its ability to produce varied and innovative text while being significantly more aligned with human preferences, demonstrating an enhanced capability to engage users in a meaningful way.
DPO eliminates the need for a separate reward model by treating the language model’s adjustment as a direct optimization problem based on human feedback. This simplification reduces the layers of complexity typically involved in model training, making the process more efficient and directly focused on aligning AI outputs with user preferences.
Comparative Analysis: RLHF vs. DPO
After exploring both Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), we’re now at a point where we can compare these two key methods used to fine-tune Large Language Models (LLMs).

This side-by-side look aims to clarify the differences and help decide which method might be better for certain situations.
Direct Comparison
Training Efficiency
RLHF involves several steps, including pre-training, collecting feedback, training a reward model, and then fine-tuning. This process is detailed and requires a lot of computer power and setup time. On the other hand, DPO is simpler and more straightforward because it optimizes the model directly based on what people prefer, often leading to quicker results.
Data Requirements
RLHF uses a variety of feedback, such as scores or written comments, which means it needs a wide range of input to train well. DPO, however, focuses on comparing pairs of options to see which one people like more, making it easier to collect the needed data.
Model Performance
RLHF is very flexible and can be fine-tuned to perform well in complex situations by understanding detailed feedback. DPO is great for making quick adjustments to align with what users want, although it might not handle varied feedback as well as RLHF.
Scalability
RLHF’s detailed process can make it hard to scale up due to its high computer resource needs. DPO’s simpler approach means it can be scaled more easily, which is particularly beneficial for projects with limited resources.

Pros and Cons
- Advantages of RLHF: Its ability to work with many kinds of feedback gives RLHF an edge in tasks that need detailed customization. This makes it well-suited for projects that require a deep understanding and nuanced adjustments.
- Disadvantages of RLHF: The main drawback is its complexity and the need for a reward model, which makes it more demanding in terms of computational resources and setup. Also, the quality and variety of feedback can significantly influence how well the fine-tuning works.
- Advantages of DPO: DPO’s more straightforward process means faster adjustments and less demand on computational resources. It integrates human preferences directly, leading to a tight alignment with what users expect.
- Disadvantages of DPO: The main issue with DPO is that it might not do as well with tasks needing more nuanced feedback, as it relies on binary choices. Also, gathering a large amount of human-annotated data might be challenging.
Scenarios of Application
- Ideal Use Cases for RLHF: RLHF excels in scenarios requiring customized outputs, like developing chatbots or systems that need to understand the context deeply. Its ability to process complex feedback makes it highly effective for these uses.
- Ideal Use Cases for DPO: When you need quick AI model adjustments and have limited computational resources, DPO is the way to go. It’s especially useful for tasks like adjusting sentiments in text or decisions that boil down to yes/no choices, where its direct approach to optimization can be fully utilized.
Summarizing Key Insights and Applications
As we wrap up our journey through the comparative analysis of Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) for fine-tuning Large Language Models (LLMs), a few key insights stand out.
Both methods offer unique advantages and cater to different needs in the realm of AI development. Here’s a recap and some guidance on choosing the right approach for your project.
Recap of Fundamental Takeaways
- RLHF is a detailed, multi-step process that provides deep customization potential through the use of a reward model. It’s particularly suited for complex tasks where nuanced feedback is crucial.
- DPO simplifies the fine-tuning process by directly applying human preferences, offering a quicker and less resource-intensive path to model optimization.
Explore LLM optimization further with the use of vector databases
Choosing the Right Finetuning Method
The decision between RLHF and DPO should be guided by several factors:
- Task Complexity: If your project involves complex interactions or requires understanding nuanced human feedback, RLHF might be the better choice. For more straightforward tasks or when quick adjustments are needed, DPO could be more effective.
- Available Resources: Consider your computational resources and the availability of human annotators. DPO is generally less demanding in terms of computational power and can be more straightforward in gathering the necessary data.
- Desired Control Level: RLHF offers more granular control over the fine-tuning process, while DPO provides a direct route to aligning model outputs with user preferences. Evaluate how much control and precision you need in the fine-tuning process.

The Future of Finetuning LLMs
Looking ahead, the field of LLM fine-tuning is ripe for innovation. We can anticipate advancements that further streamline these processes, reduce computational demands, and enhance the ability to capture and apply complex human feedback.
Additionally, the integration of AI ethics into fine-tuning methods is becoming increasingly important, ensuring that models not only perform well but also operate fairly and without bias. As we continue to push the boundaries of what AI can achieve, the evolution of fine-tuning methods like RLHF and DPO will play a crucial role in making AI more adaptable, efficient, and aligned with human values.
By carefully considering the specific needs of each project and staying informed about advancements in the field, developers can leverage these powerful tools to create AI systems that are not only technologically advanced but also deeply attuned to the complexities of human communication and preferences.