
In today’s dynamic digital world, handling vast amounts of data across the organization is challenging. It takes a lot of time and effort to set up different resources for each task and duplicate data repeatedly. Picture a world where you don’t have to juggle multiple copies of data or struggle with integration issues.
Microsoft Fabric makes this possible by introducing a unified approach to data management. Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method.
What is Microsoft Fabric?
Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. It is based on a SaaS model that provides a unified platform for all tasks like ingesting, storing, processing, analyzing, and monitoring data.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data.

Fabric features a lake-centric architecture, with a central repository known as OneLake. OneLake, being built on Azure Data Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON. OneLake offers a unified data environment for each of Microsoft Fabric’s experiences.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Microsoft Fabric’s experiences include:
- Synapse Data Engineering
- Synapse Data Warehouse
- Synapse Data Science
- Synapse Real-Time Intelligence
- Data Factory
- Data Activator
- Power BI

Exploring Microsoft Fabric Components: Sales Use Case
Microsoft Fabric offers a set of analytics components that are designed to perform specific tasks and work together seamlessly. Let’s explore each of these components and its application in the sales domain:
Synapse Data Engineering:
Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse.
In the sales use case, it facilitates the creation of automated data pipelines that handle data ingestion and transformation, ensuring that sales data is consistently updated and ready for analysis without manual intervention.
Synapse Data Warehouse:
Synapse Data Warehouse represents the next generation of data warehousing, supporting an open data format. The data is stored in Parquet format and published as Delta Lake Logs, supporting ACID transactions and enabling interoperability across Microsoft Fabric workloads.
In the sales context, this ensures that sales data remains consistent, accurate, and easily accessible for analysis and reporting.
Synapse Data Science:
Synapse Data Science empowers data scientists to work directly with secured and governed sales data prepared by engineering teams, allowing for the efficient development of predictive models.
By forecasting sales performance, businesses can identify anomalies or trends, which are crucial for directing future sales strategies and making informed decisions.

Synapse Real-Time Intelligence:
Real-Time Intelligence in Synapse provides a robust solution to gain insights and visualize event-driven scenarios and streaming data logs. In the sales domain, this enables real-time monitoring of live sales activities, offering immediate insights into performance and rapid response to emerging trends or issues.
Data Factory:
Data Factory enhances the data integration experience by offering support for over 200 native connectors to both on-premises and cloud data sources. For the sales use case, this means professionals can create pipelines that automate the process of data ingestion, and transformation, ensuring that sales data is always updated and ready for analysis.
Data Activator:
Data Activator is a no-code experience in Microsoft Fabric that enables users to automatically perform actions on changing data on the detection of specific patterns or conditions. In the sales context, this helps monitor sales data in Power BI reports and trigger alerts or actions based on real-time changes, ensuring that sales teams can respond quickly to critical events.
Power BI:
Power BI, integrated within Microsoft Fabric, is a leading Business Intelligence tool that facilitates advanced data visualization and reporting. For sales teams, it offers interactive dashboards that display key metrics, trends, and performance indicators. This enables a deep analysis of sales data, helping to identify what drives demand and what affects sales performance.
Learn how to use Power BI for data exploration and visualization
Hands-on Practice on Microsoft Fabric:
Let’s get started with sales data analysis by leveraging the power of Microsoft Fabric:
1. Sample Data
The dataset utilized for this example is the sample sales data (sales.csv).
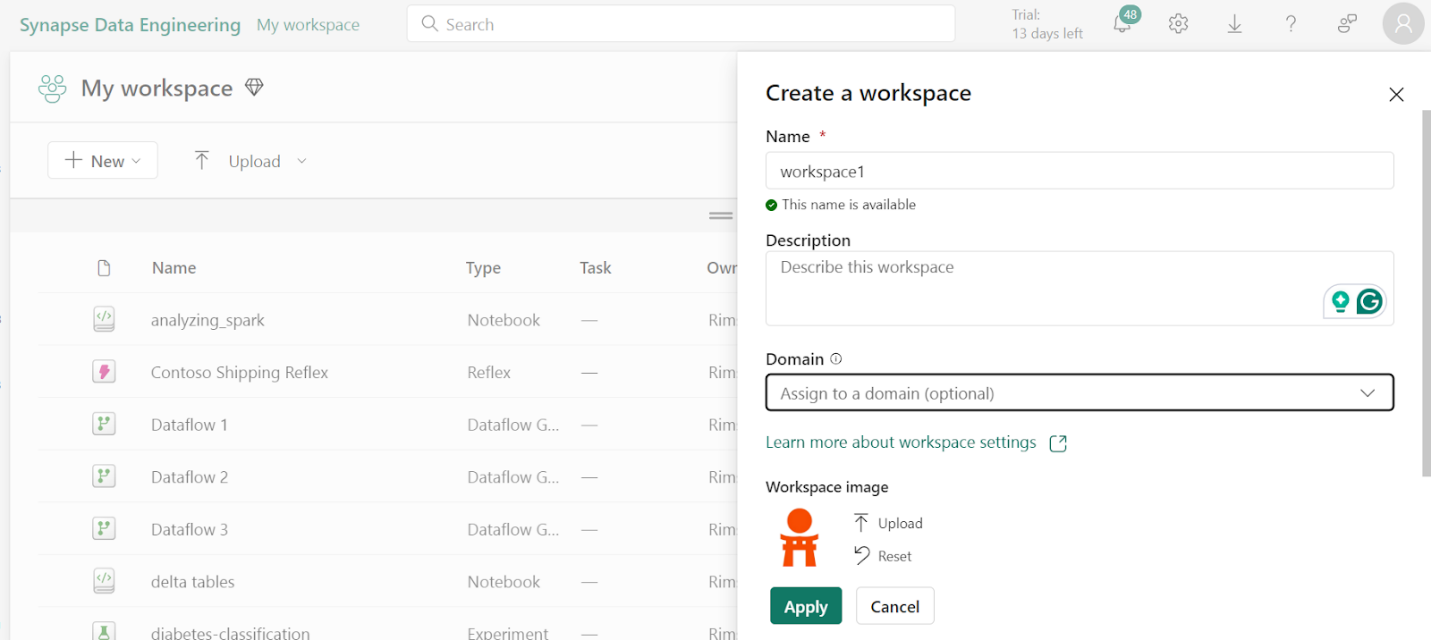
2. Create Workspace
To work with data in Fabric, first create a workspace with the Fabric trial enabled.
- On the home page, select Synapse Data Engineering.
- In the menu bar on the left, select Workspaces.
- Create a new workspace with any name and select a licensing mode. When a new workspace opens, it should be empty.
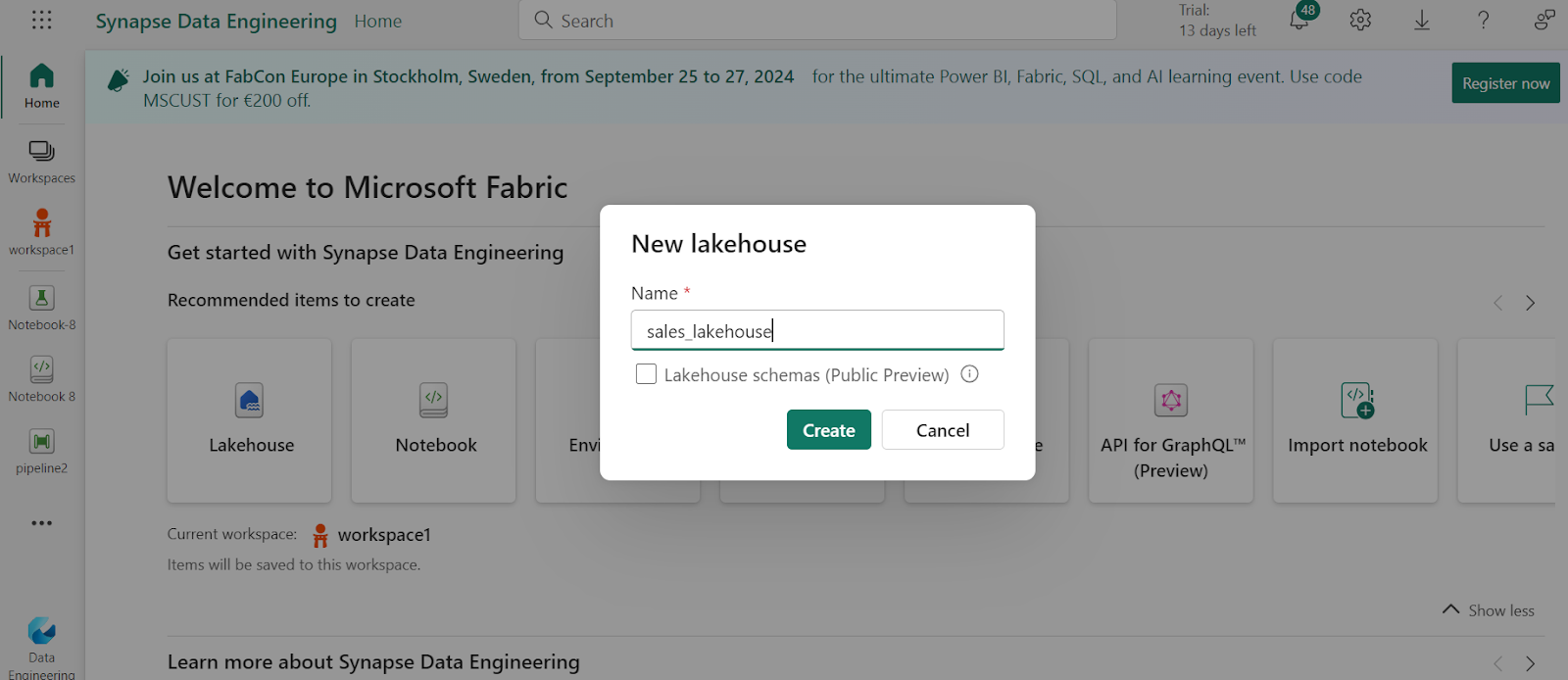
3. Create Lakehouse
Now, let’s create a lakehouse to store the data.
- In the bottom left corner select Synapse Data Engineering and create a new Lakehouse with any name.
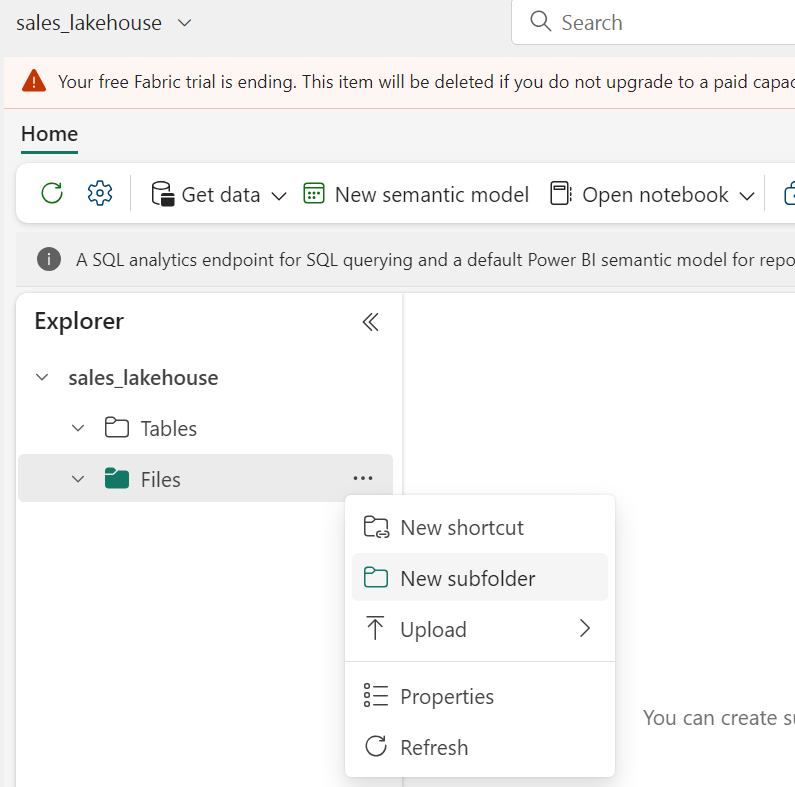
- On the Lake View tab in the pane on the left, create a new subfolder.
4. Create Pipeline
To ingest data, we’ll make use of a Copy Data activity in a pipeline. This will enable us to extract the data from a source and copy it to a file in the already-created lakehouse.
- On the Home page of Lakehouse, select Get Data and then select New Data Pipeline to create a new data pipeline named Ingest Sales Data.
- The Copy Data wizard will open automatically, if not select Copy Data > Use Copy Assistant in the pipeline editor page.
- In the Copy Data wizard, on the Choose a data source page select HTTP in the New sources section.
- Enter the settings in the connect to data source pane as shown:
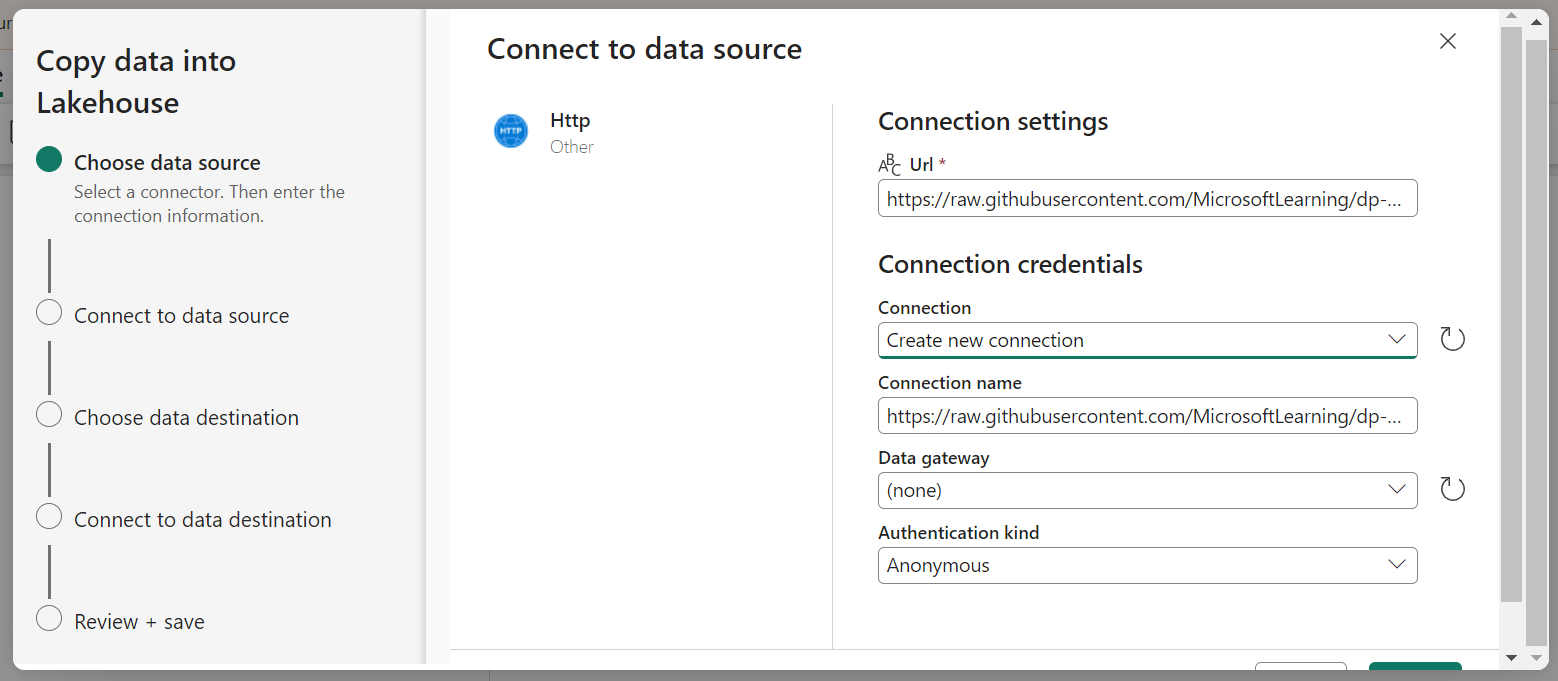
- Click Next. Then on the next page select Request method as GET and leave other fields blank. Select Next.
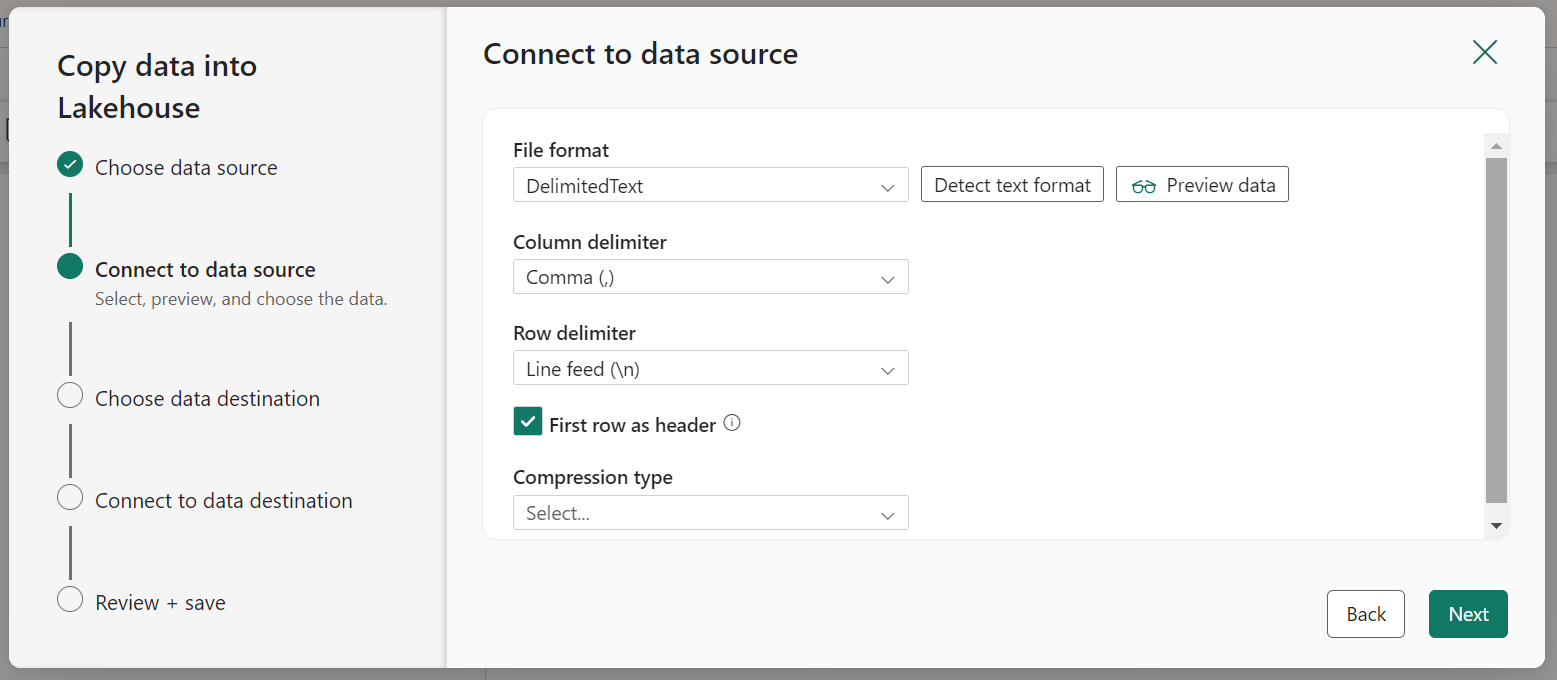
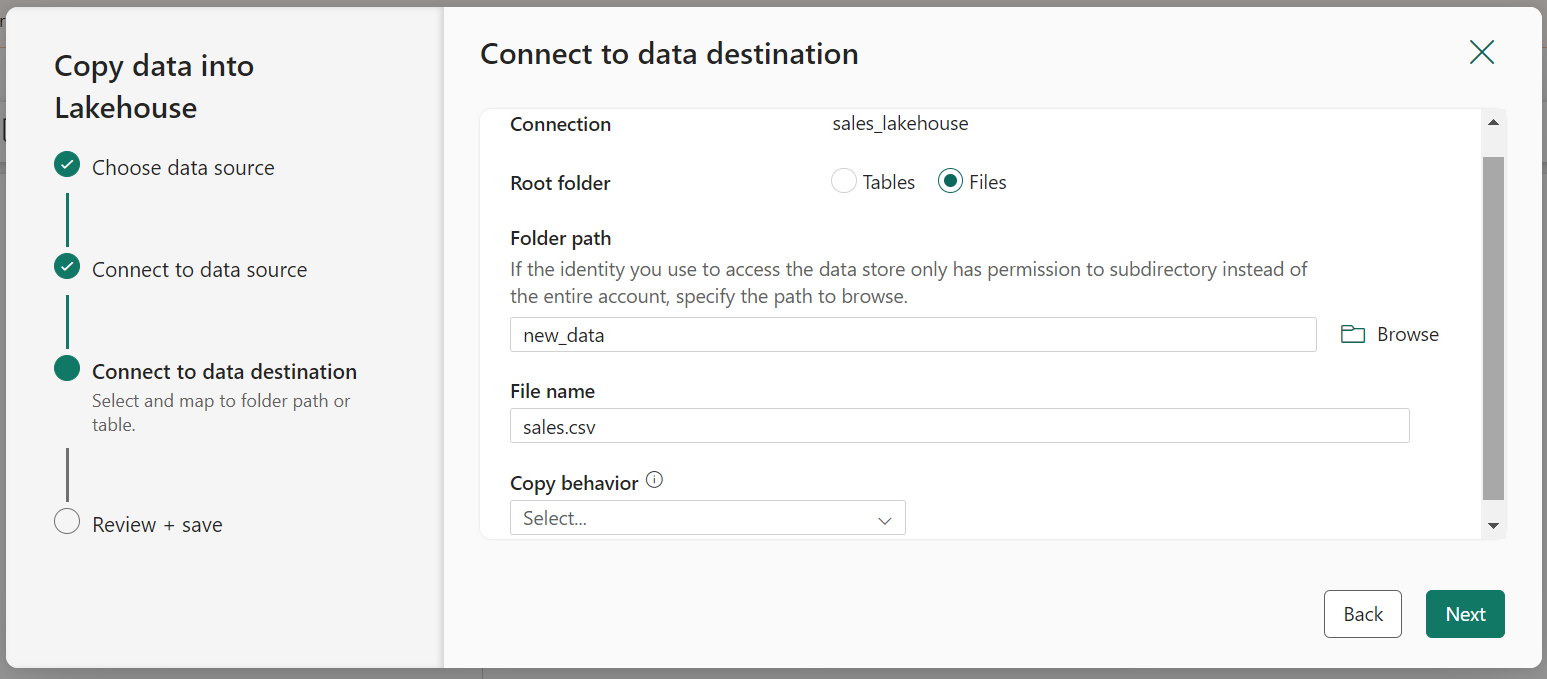
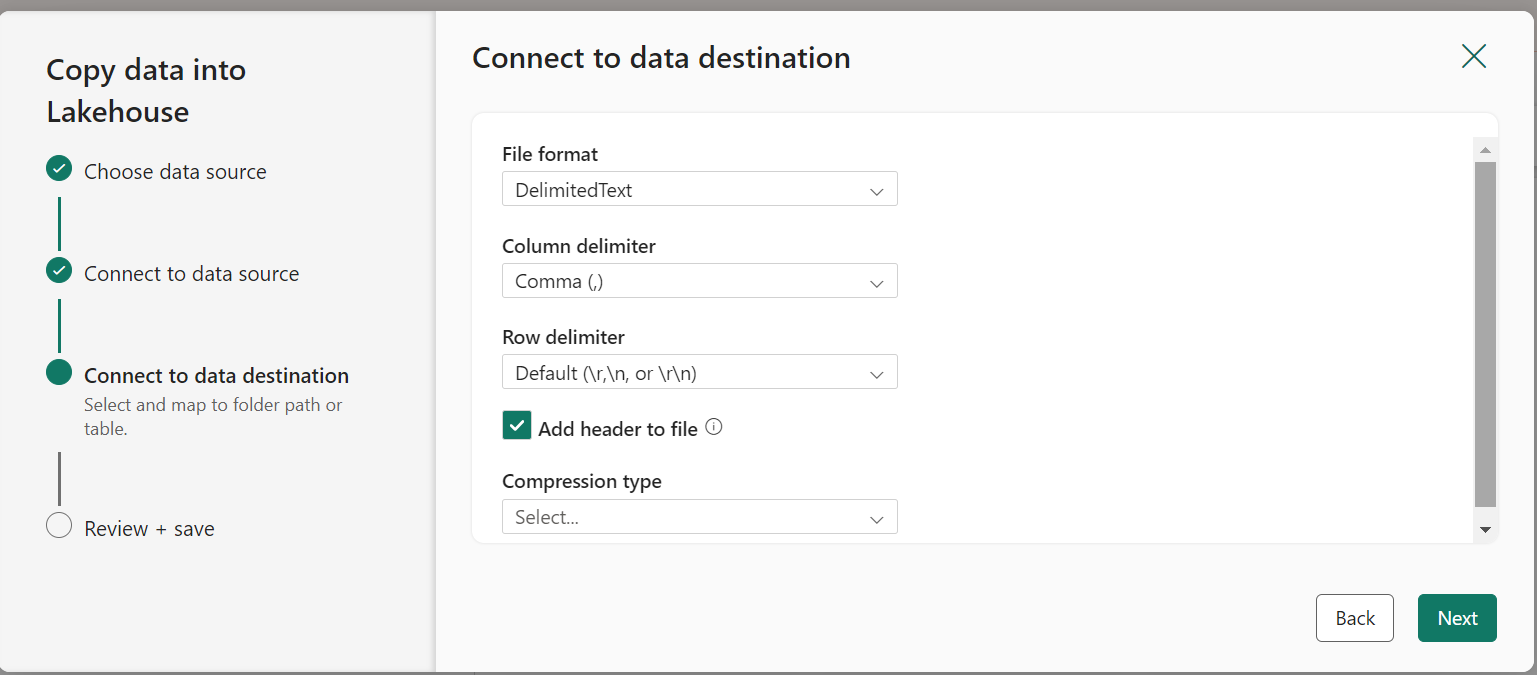
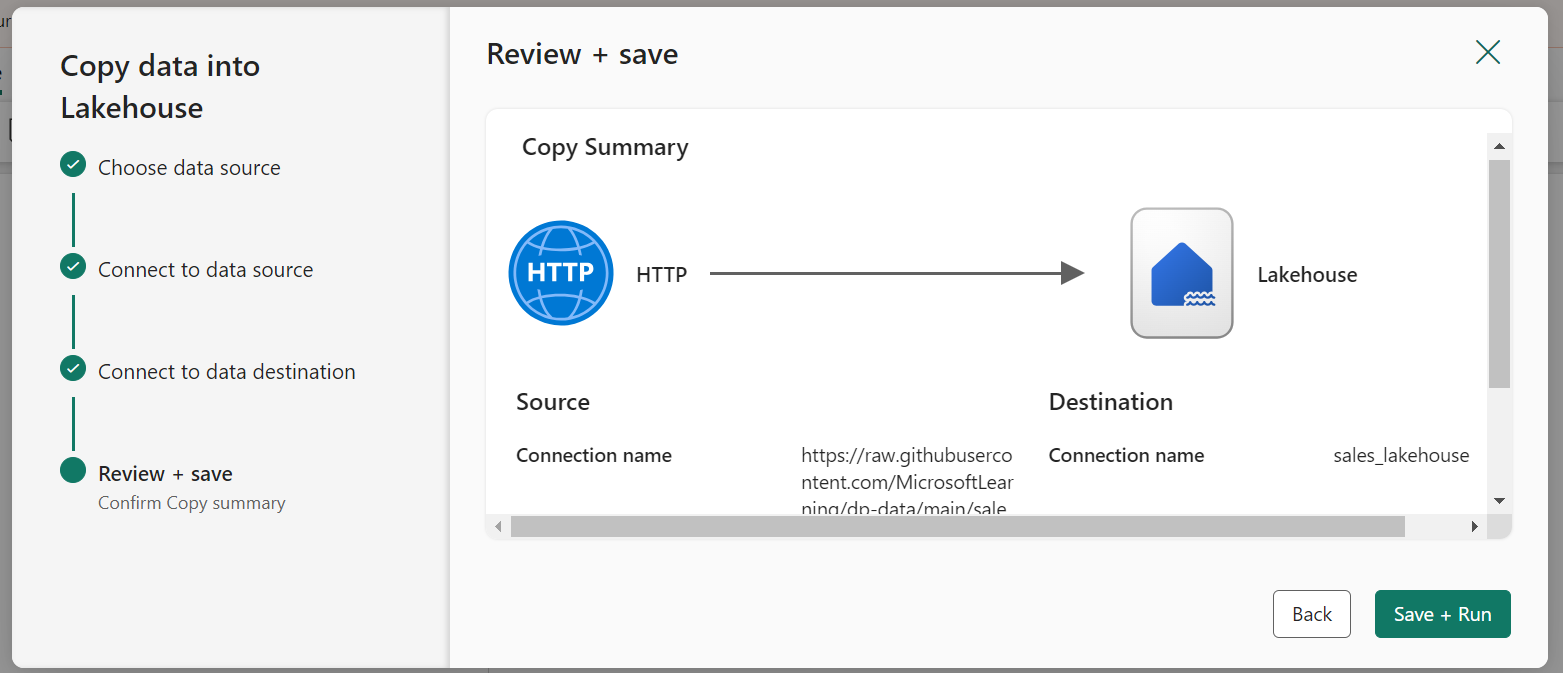
- When the pipeline starts to run, its status can be monitored in the Output pane.
- Now, in the created Lakehouse check if the sales.csv file has been copied.
5. Create Notebook
On the Home page for your lakehouse, in the Open Notebook menu, select New Notebook.
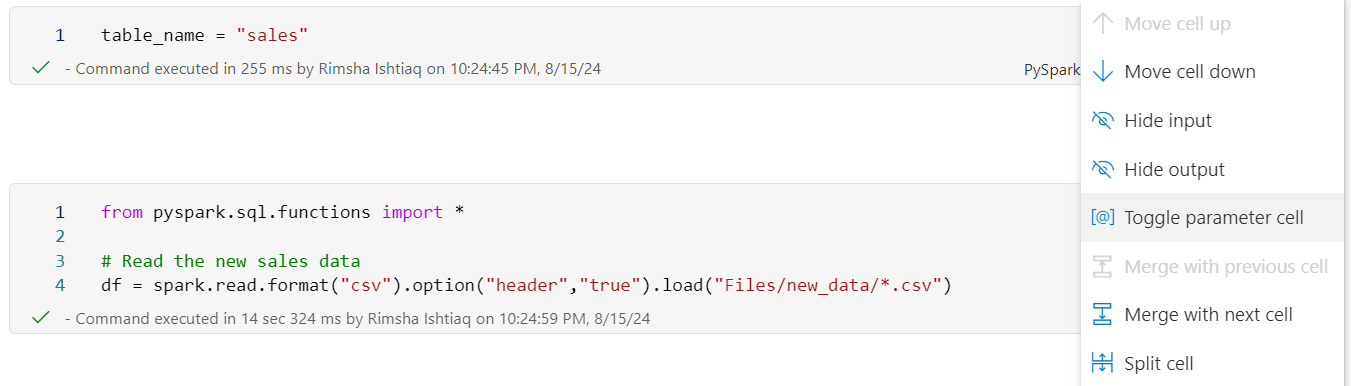
- In the notebook, configure one of the cells as a Toggle parameter cell and declare a variable for the table name.
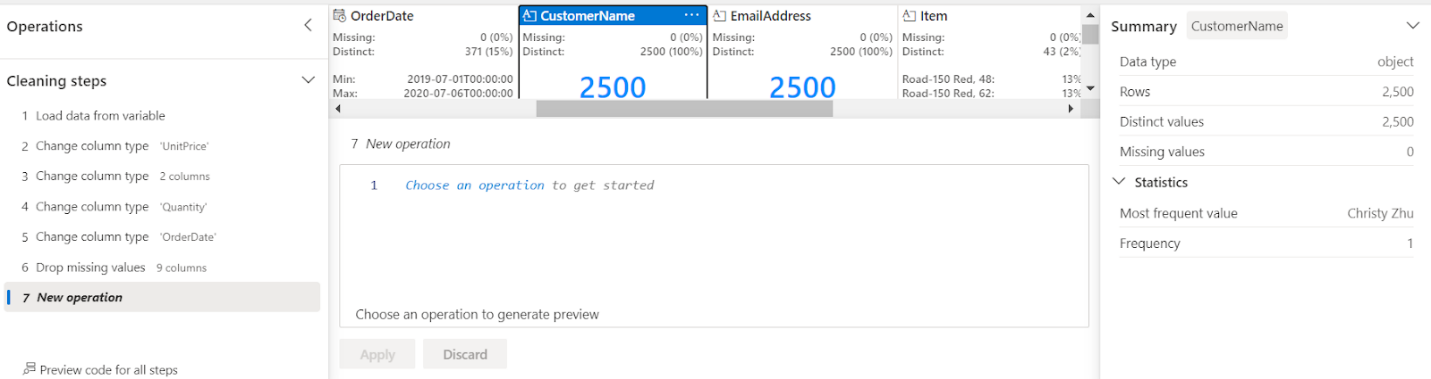
- Select Data Wrangler in the notebook ribbon, and then select the data frame that we just created using the data file from the copy data pipeline. Here, we changed the data types of columns and dealt with missing values.
Data Wrangler generates a descriptive overview of the data frame, allowing you to transform, and process your sales data as required. It is a great tool especially when performing data preprocessing for data science tasks.
- Now, we can save the data as delta tables to use later for sales analytics. Delta tables are schema abstractions for data files that are stored in Delta format.

- Let’s use SQL operations on this delta table to see if the table is stored.


6. Run and Schedule Pipeline
Go to the already created pipeline page, add Notebook Activity to the completion of the copy data pipeline, and follow these configurations. So, the table_name parameter will override the default value of the table_name variable in the parameters cell of the notebook.
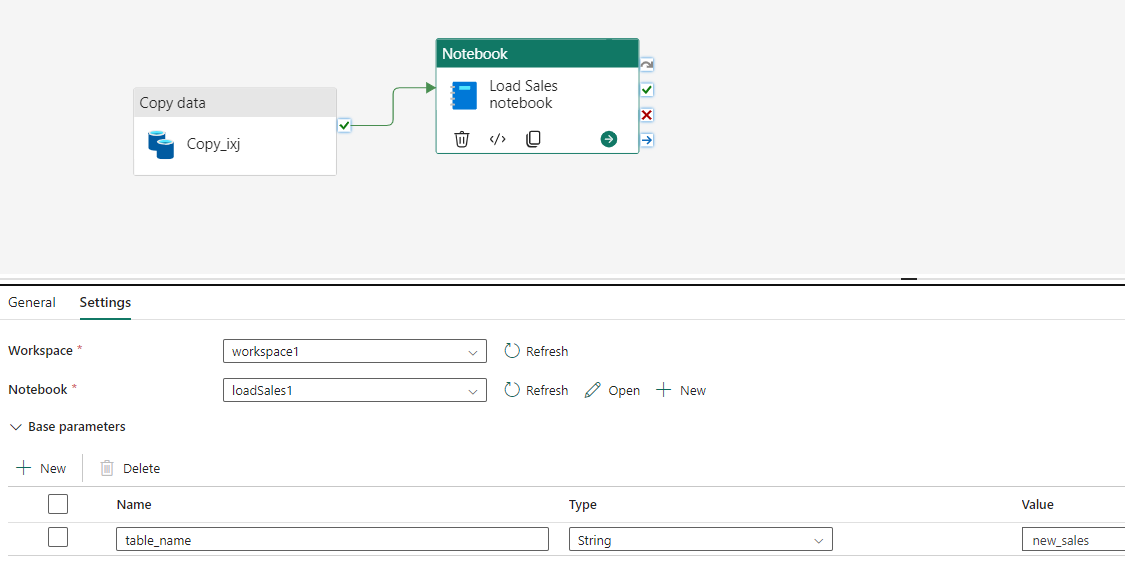
In the Notebook, select the notebook you just created.
7. Schedule and Monitor Pipeline
Now, we can schedule the pipeline.
- On the Home tab of the pipeline editor window, select Schedule and enter the scheduling requirements.
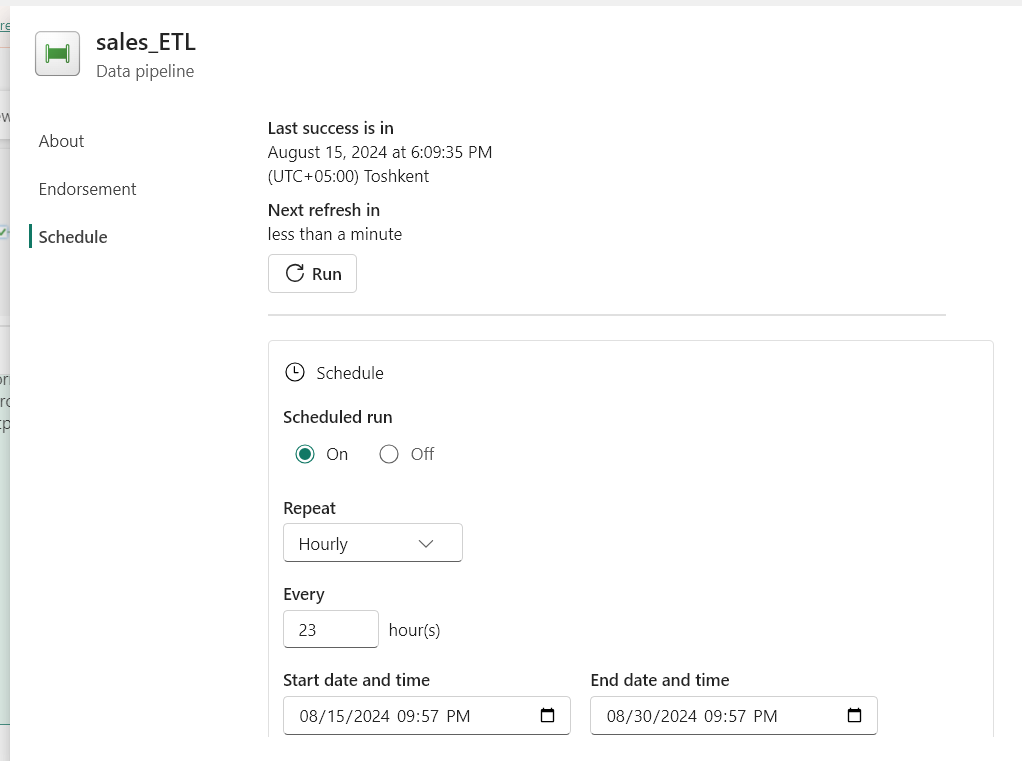
- To keep track of pipeline runs, add the Office Outlook activity after the pipeline.
- In the settings of activity, authenticate with the sender account (use your account in ‘To’).
- For the Subject and Body, select the Add dynamic content option to display the pipeline expression builder canvas and add the expressions as follows. (select your activity name in ‘activity ()’)
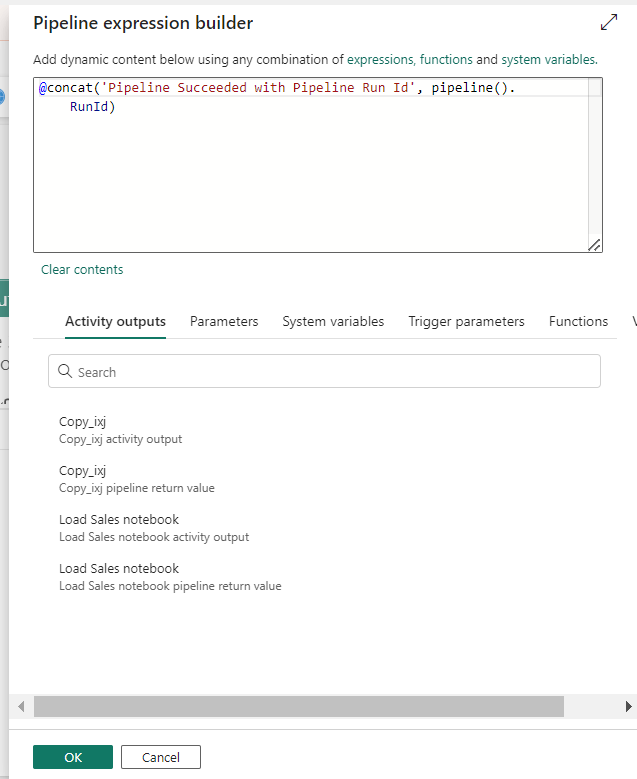
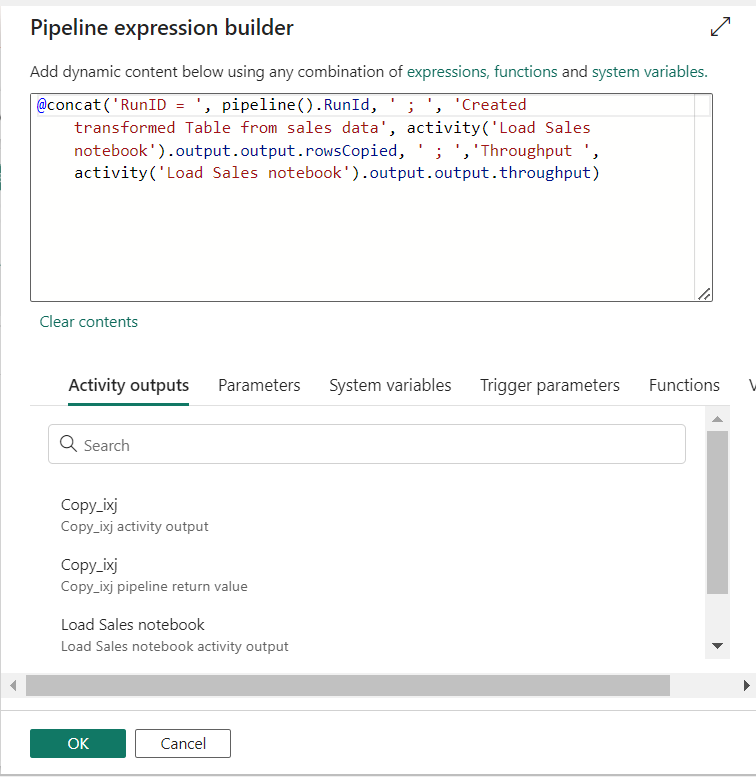
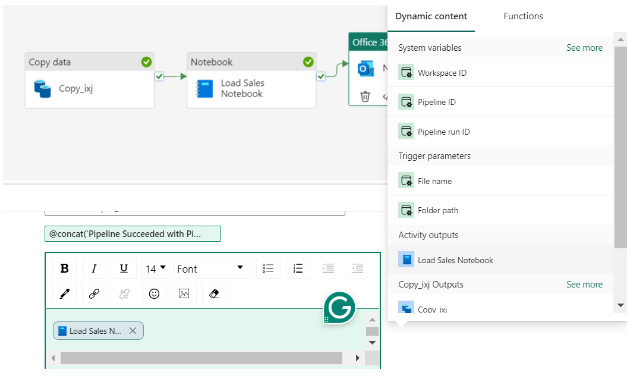
8. Use Data from Pipeline in PowerBI
- In the lakehouse, click on the delta table just created by the pipeline and create a New Semantic Model.
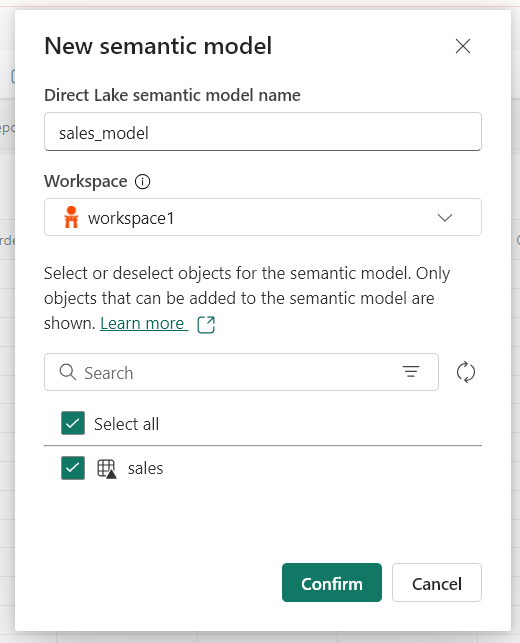
- As the model is created, the model view opens click on Create New Report.
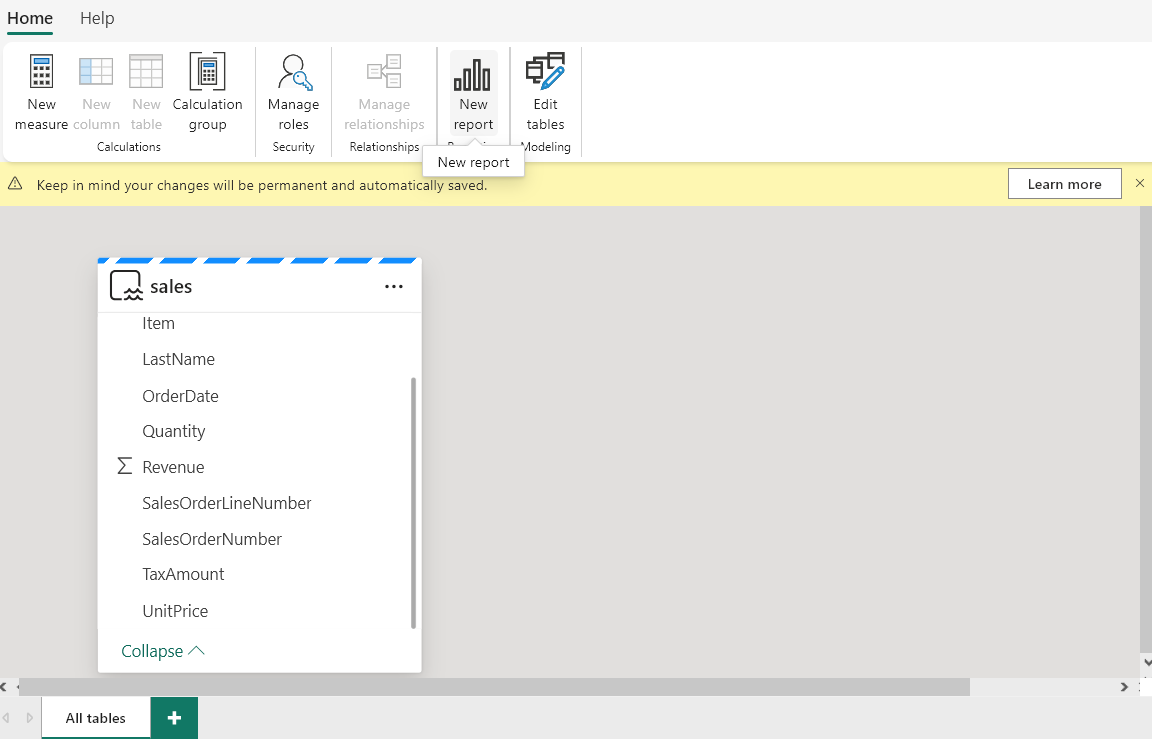
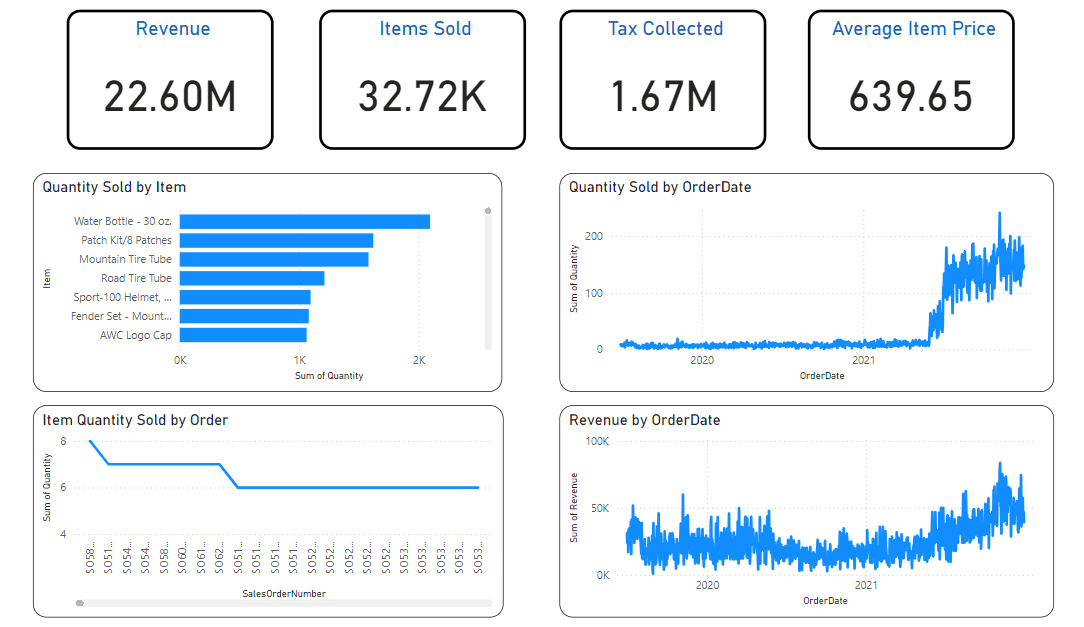
- This opens another tab of PowerBI, where you can visualize the sales data and create interactive dashboards.
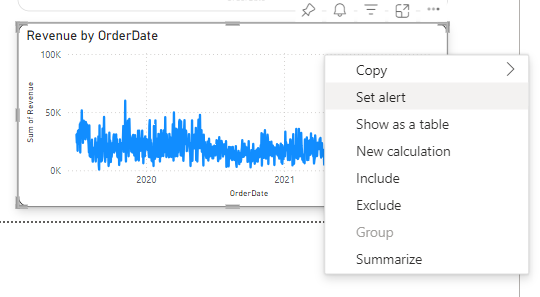
Choose a visual of interest. Right-click it and select Set Alert. Set Alert button in the Power BI toolbar can also be used.
- Next, define trigger conditions to create a trigger in the following way:
This way, sales professionals can seamlessly use their data across the platform by transforming and storing it in the appropriate format. They can perform analysis, make informed decisions, and set up triggers, allowing them to monitor sales performance and react quickly to any uncertainty.

Conclusion
In conclusion, Microsoft Fabric as a revolutionary all-in-one analytics platform simplifies data management for enterprises. Providing a unified environment eliminates the complexities of handling multiple services just by being a haven where data moves in and out all within the same environment for ease of ingestion, processing, or analysis.
With Microsoft Fabric, businesses can streamline data workflows, from data ingestion to real-time analytics, and can respond quickly to market dynamics.
Want to learn more about Microsoft Fabric? Here’s a tutorial to get you started today for a comprehensive understanding!